
抠图只精细到头发丝还不够,Adobe新方法能处理6000×6000的高分辨率图像
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转载自机器之心。
选自arXiv
作者:Haichao Yu等
机器之心编译
编辑:魔王、小舟
很多深度学习方法实现了不错的抠图效果,但它们无法很好地处理高分辨率图像。而现实世界中需要使用抠图技术的图像通常是分辨率为 5000 × 5000 甚至更高的高分辨率图像。如何突破硬件限制,将抠图方法应用于高分辨率图像?来自 UIUC、Adobe 研究院和俄勒冈大学的研究者提出了一种新方法。

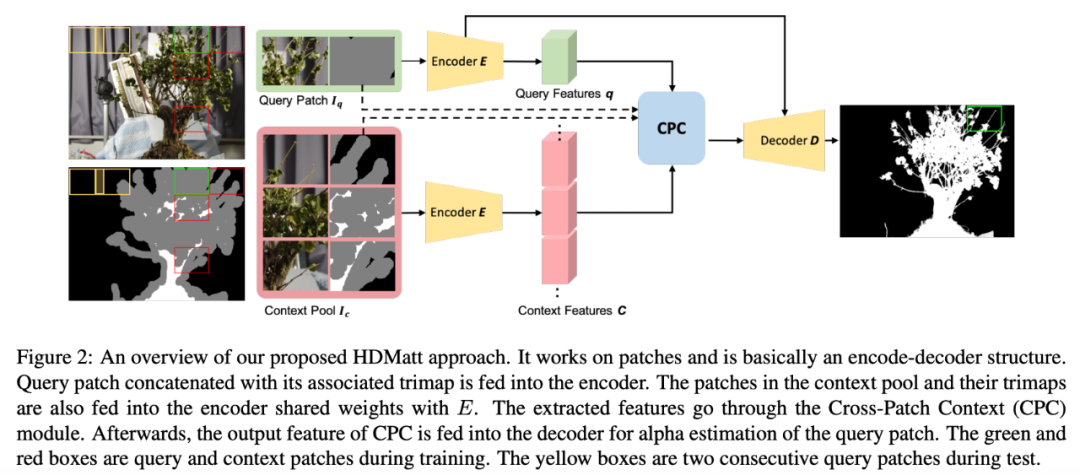
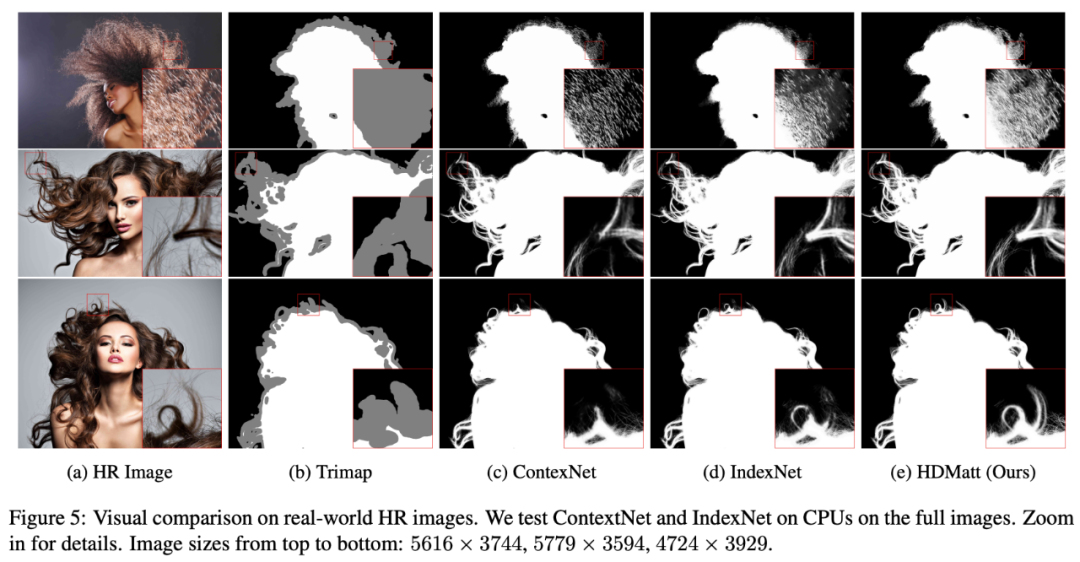
这是首个基于深度学习的高分辨率图像抠图方法,在硬件资源限制下使现实世界中的高质量 HR 抠图成为现实。
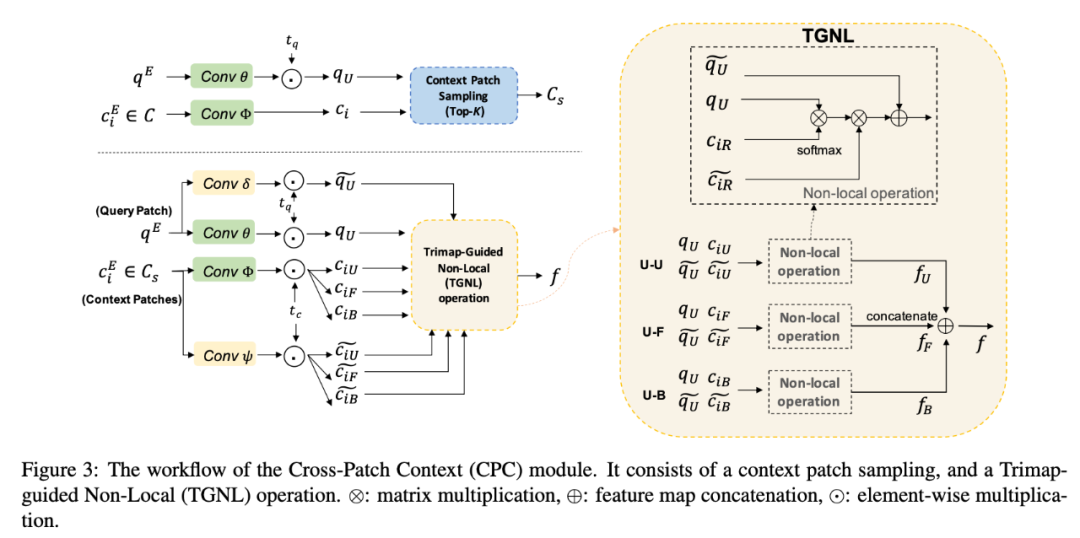
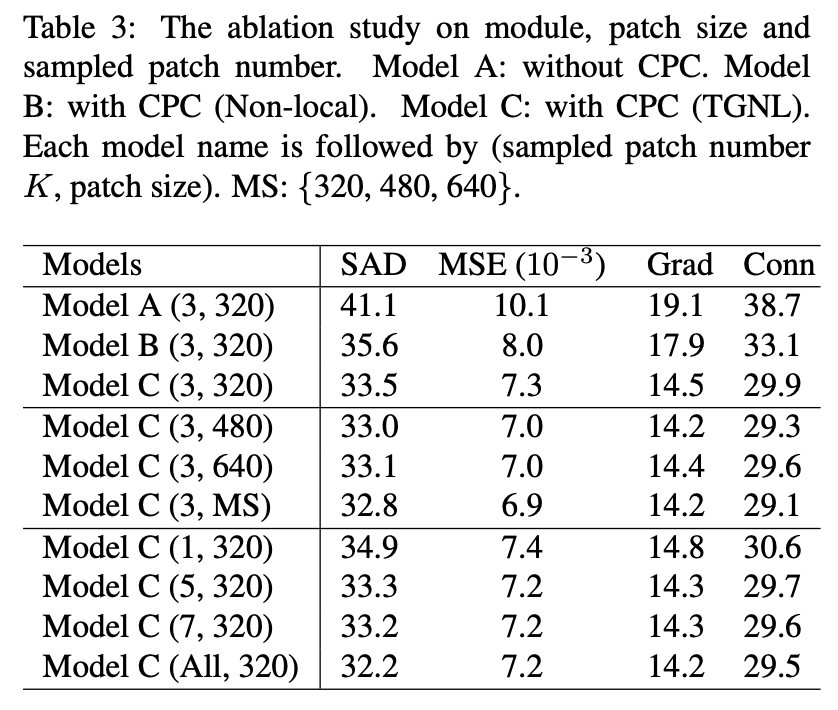
提出一种新型模块 CPC,用来捕获 patch 之间的长程语境依赖性。在 CPC 内部,新提出的 Trimap-Guided Non-Local(TGNL)操作旨在高效传播来自 reference patch 不同区域的信息。
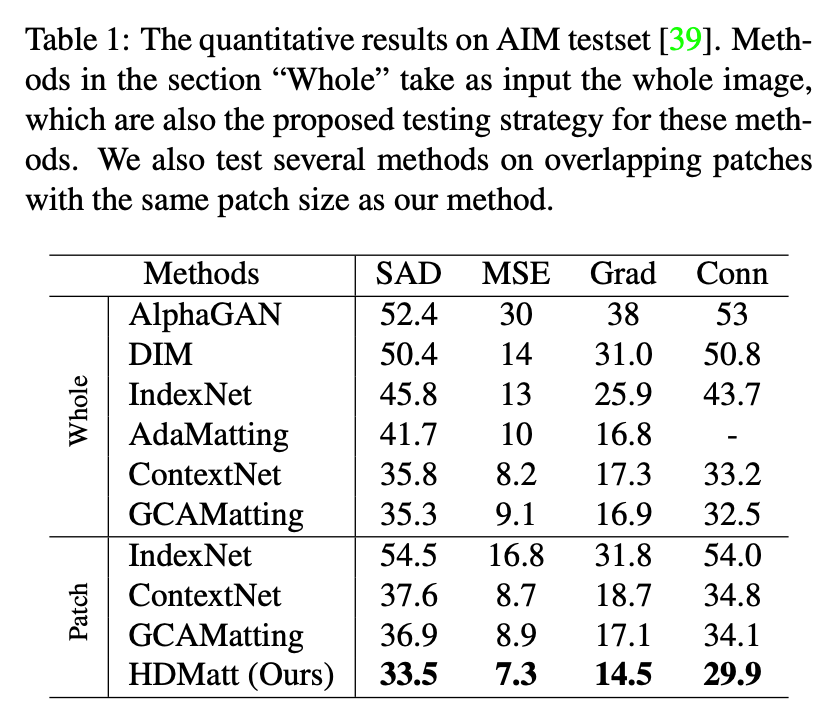
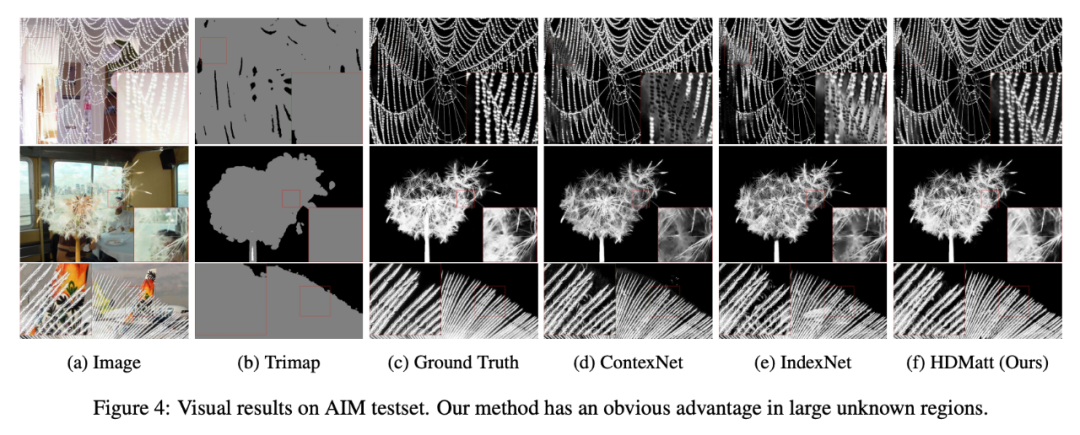
在定量和定性实验方面,HDMatt 方法在 Adobe Image Matting (AIM)、AlphaMatting 基准和真实高分辨率图像数据集上均实现了新的 SOTA 性能。




评论