
假3D场景逼真到火爆外网!超1亿像素无死角,被赞AI渲染新高度
萧箫 杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
先来看一段“视频”,有没有看出什么不对劲的地方?

其实,这仅仅是由一组照片渲染出来的(右下角为拍摄照片)!

生成的也不仅仅是一段视频,更是一个3D场景模型,不仅能任意角度随意切换、高清无死角,还能调节曝光、白平衡等参数,生成船新的照片:

在完全不同的场景下,例如一个坦克厂中,同样能用一组照片渲染出逼真3D场景,相同角度与真实拍摄图像几乎“完全一致”:

要知道,之前苹果虽然也做过一组照片生成目标物体3D模型的功能,但最多就是一件物体,例如一只箱子:

这次可是整个3D场景!

这是德国埃尔朗根-纽伦堡大学的几位研究人员做的项目,效果一出就火得不行,在国外社交媒体上赞数超过5k,阅读量达到36w+。
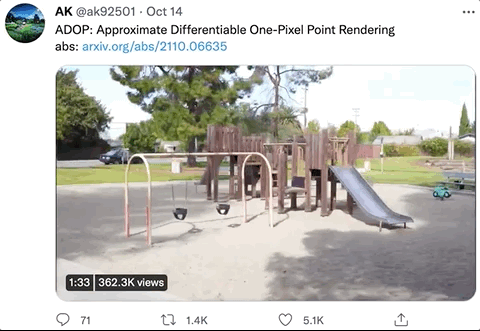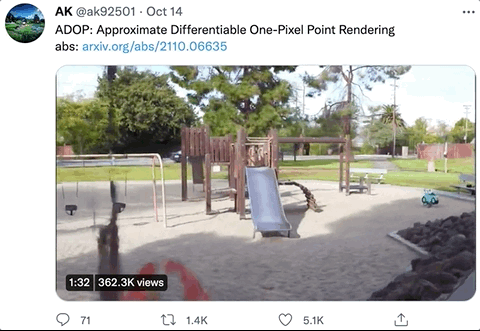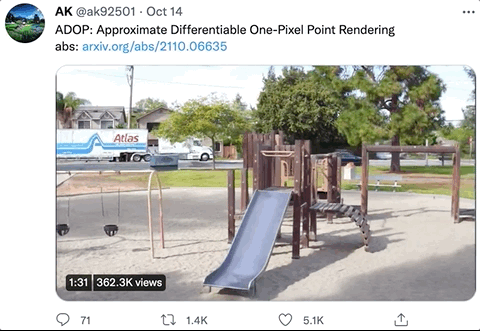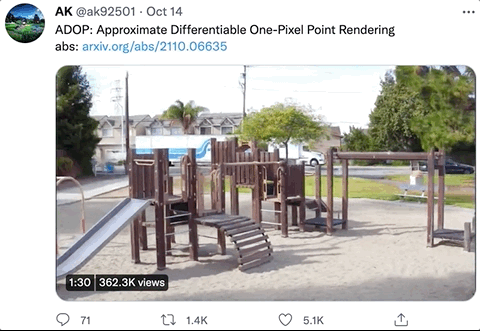
那么,这样神奇的效果,究竟是怎么生成的呢?
用照片还原整个3D场景图
整体来说,这篇论文提出了一种基于点的可微神经渲染流水线ADOP(Approximate Differentiable One-Pixel Point Rendering),用AI分析输入图像,并输出新角度的新图像。
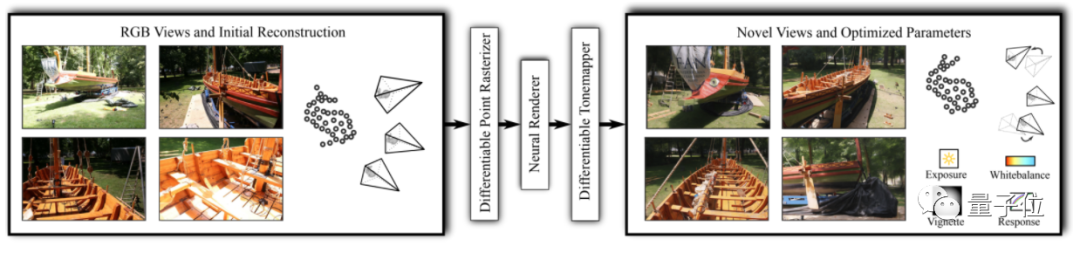
在输入时,由于需要建模3D场景,因此这里的照片需要经过严格拍摄,来获取整个场景的稀疏点云数据。
具体来说,作者在从照片获取点云数据时,采用了COLMAP。
先从多个不同的角度拍摄场景中的照片,其中每张照片的视角都会经过严格控制。
然后采用SfM(Structure From Motion,运动恢复结构)方法,来获取相机内外参数,得到整个场景的3D重建数据,也就是表示场景结构的稀疏点云:

然后,包含点云等信息的场景数据会被输入到流水线中,进行进一步的处理。
流水线(pipeline)主要分为三个部分:可微光栅化器、神经渲染器和可微色调映射器。

首先,利用多分辨率的单像素点栅格化可微渲染器(可微光栅化器),将输入的相机参数、重建的点云数据转换成稀疏神经图像。
其中,模型里关于图像和点云对齐的部分,采用了NavVis数据集来训练。
然后,利用神经渲染器,对稀疏神经图像进行阴影计算和孔洞填充,生成HDR图片。

最后,由于不是每个设备都支持HDR画面,因此在显示到LDR设备之前,还需要利用基于物理的可微色调映射器改变动态范围,将HDR图像变成LDR图像。
每个场景300+图像训练
这个新模型的优势在哪里?
由于模型的所有阶段都可微,因此这个模型能够优化场景所有参数(相机模型、相机姿势、点位置、点颜色、环境图、渲染网络权重、渐晕、相机响应函数、每张图像的曝光和每张图像的白平衡),并用来生成质量更高的图像。
具体到训练上,作者先是采用了688张图片(包含73M个点)来训练这个神经渲染流水线(pipeline)。
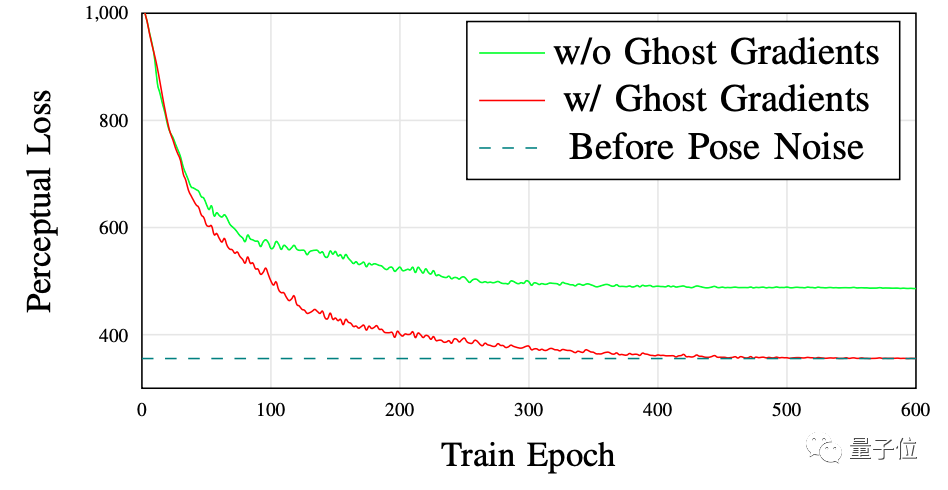
针对demo中的几个场景(火车、灯塔、游乐园、操场等),作者们分别用高端摄像机拍摄了300~350张全高清图像,每个场景生成的像素点数量分别为10M、8M、12M和11M,其中5%的图像用作测试。
也就是说,制作这样一个3D场景,大约需要几百张图像,同时每张图像的拍摄需要经过严格的角度控制。
不过仍然有读者表示,拍几百张图像就能用AI做个场景出来,这个速度比当前人工渲染是要快多了。
功能上,模型既能生成可以调节参数的新角度照片,还能自动插值生成全场景的3D渲染视频,可以说是挺有潜力的。
那么,这个模型的效果与当前其他模型的渲染效果相比如何呢?
实时显示1亿+像素点场景
据作者表示,论文中采用的高效单像素点栅格化方法,使得ADOP能够使用任意的相机模型,并实时显示超过1亿个像素点的场景。
肉眼分辨生成结果来看,采用同行几个最新模型生成的图片,或多或少会出现一些伪影或是不真实的情况,相比之下ADOP在细节上处理得都非常不错:

从数据来看,无论是火车、操场、坦克还是灯塔场景,在ADOP模型的渲染下,在VGG、LPIPS和PSNR上几乎都能取得最优秀的结果(除了坦克的数据)。

不过,研究本身也还具有一些局限性,例如单像素点渲染仍然存在点云稀疏时,渲染出现孔洞等问题。
但整体来看,实时显示3D场景的效果还是非常出类拔萃的,不少业内人士表示“达到了AI渲染新高度”。
已经有不少网友开始想象这项研究的用途,例如给电影制片厂省去一大波时间和精力:
(甚至有电影系的学生想直接用到毕设上)

对游戏行业影响也非常不错:
在家就能搞3A大作的场景,是不是也要实现了?简直让人迫不及待。

还有人想象,要是能在iPhone上实现就好了(甚至已经给iPhone 15预定上了):
对于研究本身,有网友从行外人视角看来,感觉更像是插帧模型(也有网友回应说差不多是这样):
也有网友表示,由于需要的图像比较多,效果没有宣传中那么好,对研究潜力持保留态度:

虽然目前作者们已经建立了GitHub项目,但代码还没有放出来,感兴趣的同学们可以先蹲一波。
至于具体的开源时间,作者们表示“会在中了顶会后再放出来”。(祝这篇论文成功被顶会收录~)
论文地址:
https://arxiv.org/abs/2110.06635
项目地址(代码还没po出来):
https://github.com/darglein/ADOP
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/q9phnq/r_adop_approximate_differentiable_onepixel_point/
[2]https://twitter.com/ak92501/status/1448489762990563331
[3]https://developer.apple.com/augmented-reality/object-capture/
— 完 —