开局一张图 对策略感兴趣的朋友们好~今天古牧君将首先介绍下策略产品经理的岗位职责,解释下它跟炒菜的相似性;然后再通过2个具体实战案例,手把手教你怎么“炒菜”。希望通过本文,帮数据分析方向的从业者们,更全面的认知到自己未来的多种可能~
对策略感兴趣的朋友们好~今天古牧君将首先介绍下策略产品经理的岗位职责,解释下它跟炒菜的相似性;然后再通过2个具体实战案例,手把手教你怎么“炒菜”。希望通过本文,帮数据分析方向的从业者们,更全面的认知到自己未来的多种可能~
首先,咱们必须得说清楚,策略产品经理这个title下,其实干什么的都有,有做增长的、有做营销的、有做交易的、有做推荐的......这种情况就跟数据产品经理一样,同样顶着这个title,有做底层数仓的、有做数据中台的、有做数据应用的......总之,你要是只看“策略”俩字就选了个岗位报了个培训班,那么大概率你会一脸懵逼一头雾水为啥会出现这种情况呢?大概因为这类岗位比较面向应用,且比较新吧。一般面向应用的岗位,会随着实际应用场景的变化而快速演化,有哪些新的场景出来,就有哪些对应的新岗位顶上来。好比近两年宏观上的流量红利吃的差不多了,没法再像之前那样光靠砸钱野蛮增长,必须精打细算、科学量化指导用户增长了,就逐渐接受了增长黑客、增长策略产品经理、用户增长产品经理这类岗位。同时,一个相对新的岗位,自身也还在不断的发展和重新定义,所以内部难免会“丰富多样”一些
继续说下策略产品经理在工作中面临的问题。你说现在这个算法和机器充分发展的时代,什么情况需要人呢?肯定就是遇到了机器都解决不了的复杂场面了。你想啊,现阶段算法和机器能解决的,其实很大程度上都是一些共性的问题,但随时实际业务场景的不断发展,现实的复杂性已经远远超过了系统的扩展性,原本设计的算法+规则已经不能应对纷繁复杂的现实世界了,就需要人工顶上来。说到底,策略做的事儿,就是建立算法与实际应用之间的桥梁,因地制宜的让算法和功能落地发挥更好的作用
从这个角度来看,做策略的,就跟炒菜很像了。尤其是对比算法岗位,如果把算法比作种菜的,他们需要详细的了解食材生长的原理;但策略不那么需要,它只需要基于对食材特性的理解,把它们按照食客的口味进行加工就好。这种加工又可以分为两种,一种是组合,好比西红柿+鸡蛋组合成西红柿炒鸡蛋;一种是精加工,好比就一条鱼,要最后端出一盘松鼠桂鱼
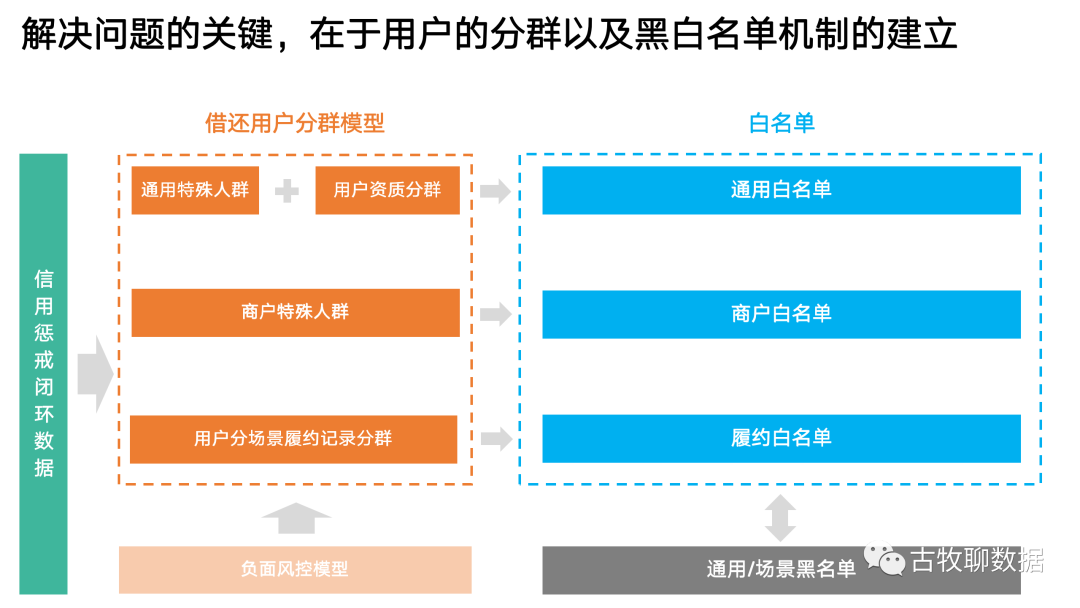
有一种策略的设计,不需要从0到1白手起家,手头已经有不错的半成品了,只需要你依据“食客”的口味,再结合“食材”的特性把它们好好组合在一起,就能发挥不错的效果。下面这个免押金借还充电宝、图书、雨伞等生活用品的场景,就是一个典型示例:原本这个场景就是依靠一套通用的风控模型,但实际运行起来发现有这么3大囧境:
1,在跟政府、商家合作的发布会上演示免押金借还物品的时候,发现一些政府官员、或者商家自己的人,竟然被风控模型挡在门外?作为一次大型品牌宣传活动,实在有些尴尬......2,有些资质很好的用户,比如余额宝里存款大几十万、常年在淘宝上一掷千金的那种,竟然会因为近期更换了一个手机号,就被底层通用模型判定为有潜在违约风险,必须先交押金才能借充电宝,用户体验很差3,有些用户虽然资产不多,但人家平时诚实守信,后台记录显示借过的东西从来都按时交还并且没有损坏。对这类用户,每次还必须要交一次押金走一次审核,太不人性化你看,这就正好是我们开篇提到过的,单靠系统扩展性无法解决的复杂现实场景问题,需要靠策略出马归纳上述问题,本质上就是一套模型打天下,没有对不同的用户进行分群处理。对一些资质高的用户、习惯好的用户,就应该建立绿色通道。可如果在底层模型上改动,成本会比较大、周期会比较长,效果也不见得会很好,所以直接在策略层面动工解决问题,不失为一个思路如同前面的分析,对待政府官员这类用户,就应该有特殊人群这个划分;对待不同资质水平的用户,也应该有不同的细分;对待商家自己的员工,同样也要单独放行;对待过往履约记录比较好的用户,也应该给予奖励
这些不同的用户群,都可以沉淀形成不同的白名单,以后模型遇见这些用户,就可以不同程度的开绿灯放行,减少不必要的麻烦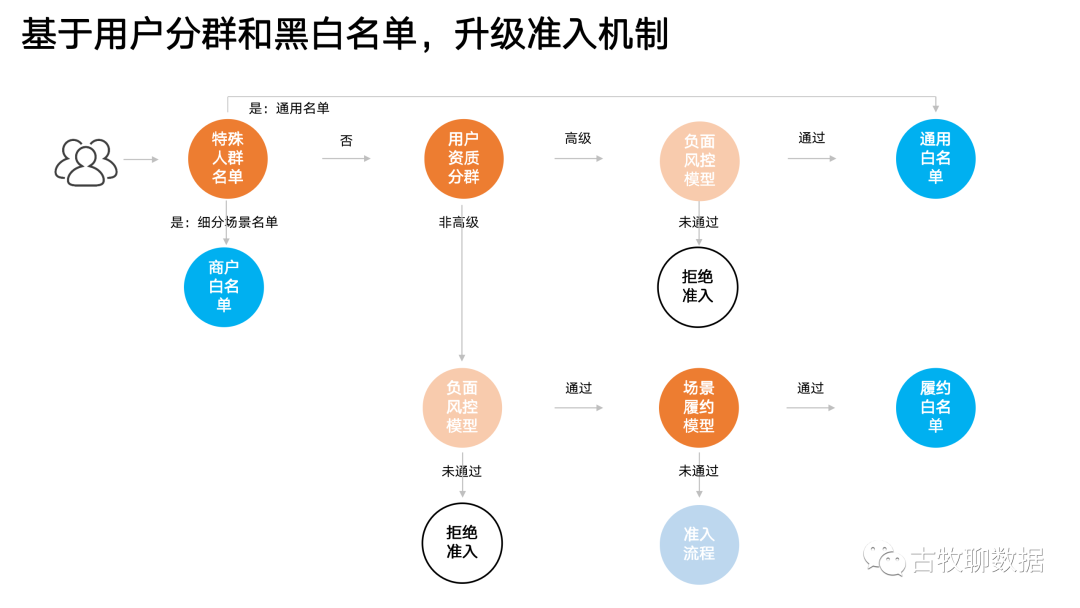
这套策略的原理其实不难,就像上面这个流程图一样,利用一些现成的底层模型组件组合一下就好。比如用户资质分群、负面风控模型、场景履约模型等,就好比是炒菜,把现成的鸡肉、花生米、葱姜配合一些调料炒一炒,就能出来宫保鸡丁了~
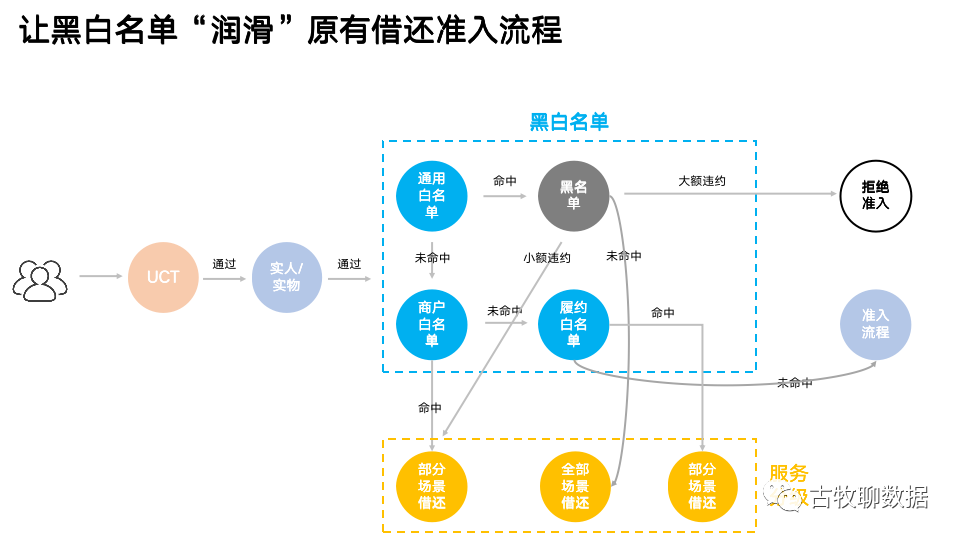
当生成了这些白名单之后,配合原有的风控模型和黑名单库,就可以让原有生涩不近人情的风控准入机制,变得“润滑”很多了,至少开篇提到的3个囧境大幅减少了
还有一种策略的设计,手头的食材种类不多,但需要从0到1做很多精加工才能成品。就好比手头只有一条鱼,要经过一些烹饪设计才能做出一道松鼠桂鱼来。这里我用搜索场景举例,根据用户的一连串搜索关键词,判断出在用户眼中哪些品牌or产品之间是强竞争关系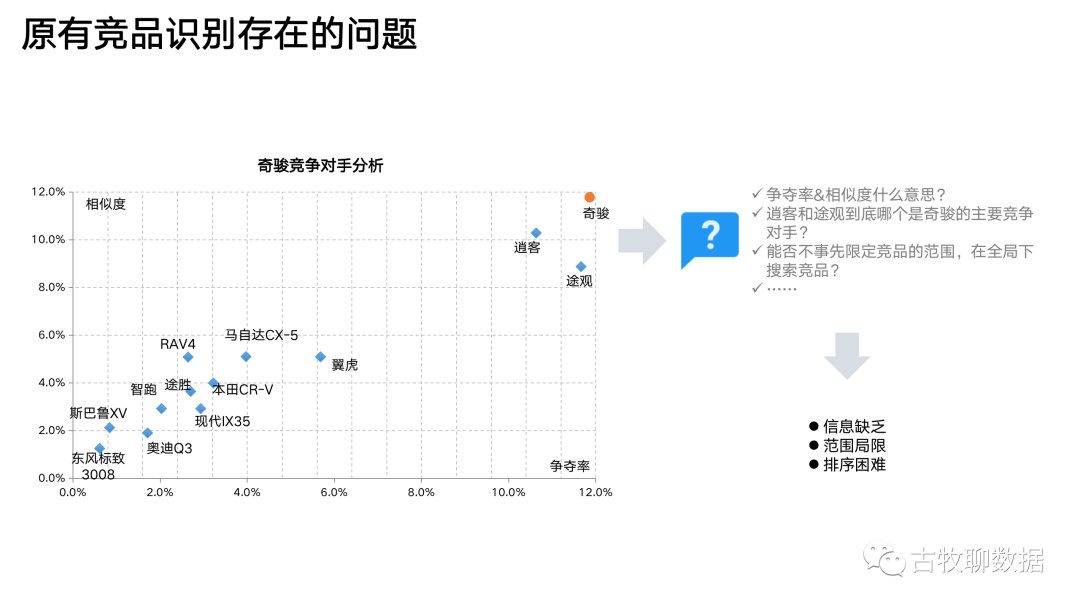
上面这个散点图,是竞品分析的传统做法。以汽车行业举例,右上角的那个奇骏就是广告主爸爸的儿子——本品,剩下的那些都是竞品,哪个离奇骏最近,哪个就是本品的最大竞品。传统做法从相似度和争夺率这2个维度来拆解“竞争”这个概念,试图量化点与点之间的距离。但有问题,因为相似度和争夺率是这么计算的:
问题1:如果我事先不输入任何竞品,这个方法就行不通(相似度和争夺率的核心都是算交集,可你不告诉我跟谁交,我怎么算?)。相当于它无法突破已知的经验范畴,而我们往往就是需要数据告知一些经验以外的东西
问题2:这个方法中,只应用了“重合”这一个特征。然而用户的搜索行为是一个连续的序列,是有前后顺序(先搜A再搜B和先搜B再搜A,不一样)、有次数多寡(搜了10次A和只搜了1次A,不一样)、有距离远近的(刚搜完A就搜B,和搜完A之后又搜了CDE之再搜B,不一样),这些信息在传统方法中,都没有体现出来
问题3:传统方法下,谁是竞品需要看图说话。那么问题来了,就拿图里的逍客和途观来说,看上去跟奇骏都比较近,到底哪个才是最强劲的竞争对手?

我们要做的就是像剥洋葱一样,从表象到本质,从用户的行为、抽象到数据轨迹、最后到轨迹中的核心元素。对一个用户的连续搜索行为来说,它就是一连串的搜索关键词,最底层本质的元素,就是顺序、位置、次数和内容了

当我们掌握了最核心的4个元素之后,就可以依据它们来重新构建模型了。这里有很多种方法,之前跟算法同学沟通时,他们天然想到的就是对时序列向量做相似性计算这类的高大上算法模型。但实际上呢?依据奥卡姆剃刀原则,越简单的、越好解释的,从某种程度上也就是最好的
一切都可以联系到实际场景,以谈恋爱为例打个比方,假设你有过很多个女友,现在也有女友(手动狗头):
1,顺序:如果你现在要分手,想找个新女友,你觉得你现任会觉得新女友威胁更大,还是前任旧女友威胁更大?在搜索场景也是一样,我先搜了一个竞品,再搜本品,那是弃暗投明,这个竞品有一定威胁,但不足为患;可要是我先搜了本品,再搜别的竞品,那就是移情别恋了,这性质可都变了~2,位置:你觉得你现任,是更在乎你前任呢?还是前前前任呢?是对你的下一任新女友难以释怀呢?还是对你的下下任女友在意呢?搜索也一样,离本品越近,竞争关系越强3,次数:这个更刺激了,你要是有个前女友,反反复复分分合合好几次,你说你现任心里膈应不膈应?同理,一个竞品反复搜索过多次,说明真的有在认真考虑啊4,内容:你过往或者未来认识的每一个女性,有些是同事、有些是朋友、有些是女友。定位不同,在你现任女友眼里的待遇也就不同;同时,就算都是前女友,你跟她们分别都谈到什么程度,这也都是不同的待遇。搜索关键词也是,有些搜索内容就没有竞品的事儿,是搜一些八卦娱乐,不足为虑;即便是搜竞品,搜的内容程度也不同,有些就是打听下价格,有些都到了打听哪儿有4S店可以预约试驾的地步了,这竞争强度可就更强了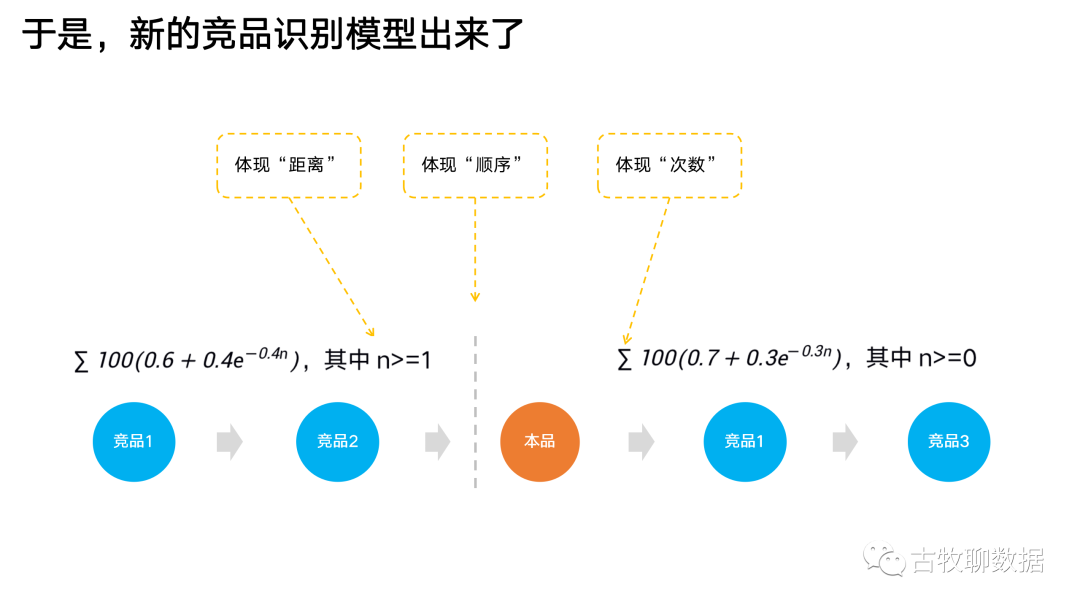
1,如果竞品出现在本品之前,那么竞争强度就减弱一些;如果出现在本品之后,竞争强度就增强一些
3,如果一次连贯的搜索行为序列中,出现的次数越多,竞争强度就越强4,如果搜索内容明确出现了竞品的名称,甚至出现了一些离购买行为很接近的关键词,竞争强度就越强按照这个标准,模型应该是一个分段函数(体现顺序特征),在每段里应该是一个单调递减函数(体现位置/距离特征),应该是可以累加的,应该能根据具体的关键词给每次搜索行为打上本品和竞品的标签,甚至根据关键词赋予不同的权重。符合上述要求的模型其实有很多种,我们可以结合实际经验进行测算尝试,最后择优录用
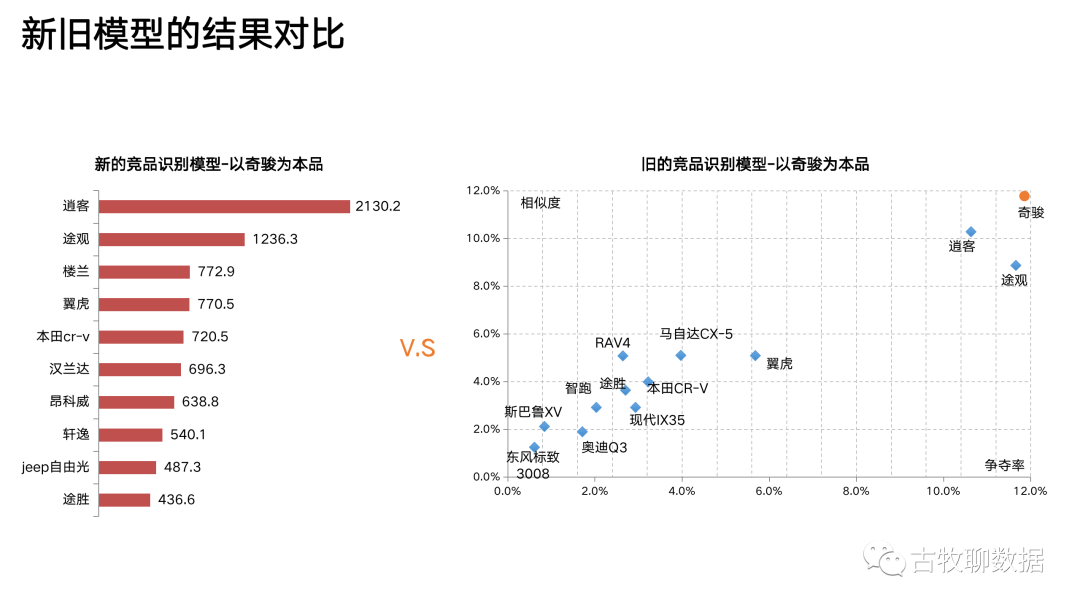
最后对比一下新旧策略的计算结果,可以很明显的发现,新模型把最开始列举的那些问题都解决了。它可以直接量化的给出排名,而且还不限制输入的范围
最后,细心的朋友可能会发现,这个策略没有评价标准啊?!坦白说,是的。它不像其他标准的有监督机器学习算法,有准确率召回率等指标来衡量,它只能靠实践结果来自证:如果针对某个品牌or产品,策略算出来的top10竞品中,80%+是符合大众/专家感知(比如宝马就是跟奔驰奥迪凑一起,不会被拿来跟比亚迪吉利等竞争),同时又能有20%左右的结果是意料之外情理之中的,那就是一个比较好的效果了。这就跟大数据的价值一样,符合常识的同时,又能带来惊喜
古牧君用炒菜这个比喻,介绍策略产品经理的日常工作,不论是组合还是精加工,都应该是面向“食客”的口味,都应该是基于对“食材”特性的理解。祝大家能结合实例举一反三,早日炒出自己的“拿手菜”!更希望大家在职场不要给自己设限,多了解下其他的可能性和选择-------- 往 期 推 荐 ----------