
【论文解读】CVPR 2020 SEPC论文解析:使用尺度均衡金字塔卷积做目标检测
导读
只说重要的,计算量基本不变,涨AP,3.5个点!

论文:https://arxiv.org/abs/2005.03101
代码:https://github.com/jshilong/SEPC
在做目标检测的时候,利用不同level的特征进行预测已经是标准操作了,所以,如何进行不同特征层之间的融合有很多不同的方法,但是基本上都是先进行缩放,缩放到相同的分辨率,然后进行相加或者拼接。但是,不同level的特征层是有语义上的差别的,而其实不同层之间相关性是有区别的,距离越近的特征层的相关性越大:
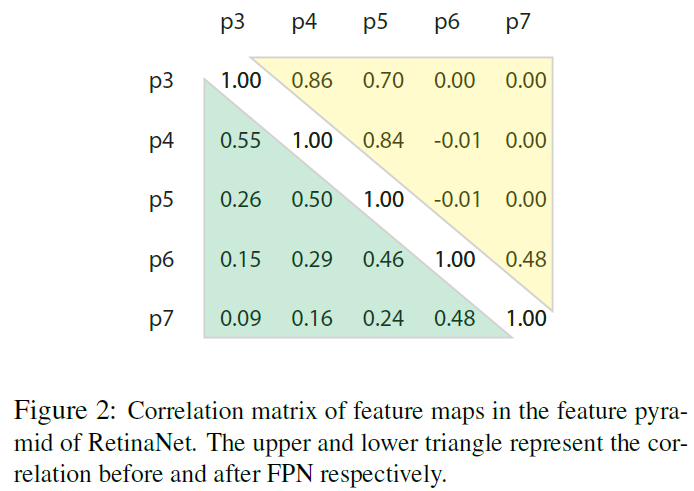
因此,这篇文章提出了一种可以利用不同特征level之间的相关性的方法,而不仅仅是简单的相加或者拼接了。因为如果是相加的话,只是对应的元素的相加,并没有feature map之间的交互,如果是拼接的话,实际上把所有的level的特征层平等对待了。
先介绍几个概念:
1. pyramid convolution (PConv)
这里使用了类似3D卷积的方案,把不同level的特征图看成是视频帧中不同帧的特征图,然后对相邻N帧,比如N=3进行3D卷积,得到中间帧的3D卷积输出,而这个输出是融合了前后两个特征层的信息的,而且融合方式要比简单的相加或者拼接要更灵活,是可以通过3D卷积的参数学习到的。这个操作就叫做金字塔卷积,pyramid convolution (PConv) 。
这里有个问题,在做3D卷积的时候,相邻帧的特征图尺度是相同的,而这里不同level的特征图的尺度是不同的,这个也好办,以中间level为基准,尺寸大的降采样,尺寸小的上采样,缩放到一样再进行3D卷积就可以了,因此,这个PConv中第层的操作写成式子是这样:
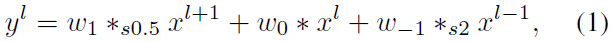
s0.5表示stride-0.5的卷积,s2表示stride=2的卷积,这里,s0.5可以等效为先上采样再做一个卷积。因此,又可以表示为:
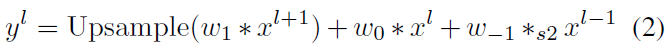
对于最底层,也就是分辨率最大的那层,最后一项没有,对于最上层,也就是分辨率最小的那层,第一项没有。
所以,这篇文章中的第一个重要的概念pyramid convolution (PConv) 现在就很清楚了,这其实就是一个对特征图金字塔进行3D卷积的模块。得到的是相邻的N个特征图进行交互后的结果。
PConv的使用流程如下:
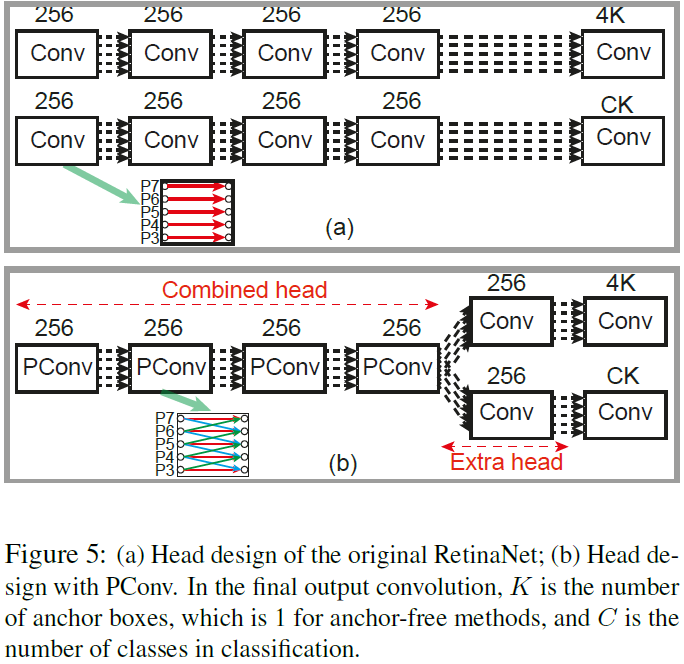
从图中可以看到,我们用4个共享的PConv模块来代替了原来的RetinaNet中的检测head,只是在最后再分出两个分支做分类和定位。这样的设计可以比原始RetinaNet计算量更少。
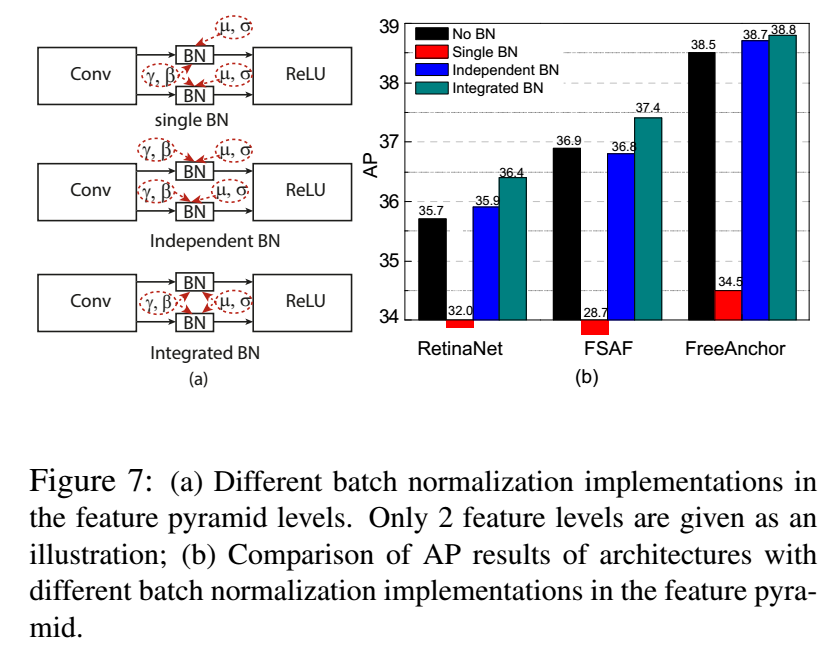
2. Integrated batch normalization (BN)
这个有个要注意的地方,就是BN的使用,由于把PConv看成了一个3D卷积,因此BN的统计量的计算要在3D卷积的所有的特征图上进行,这样会使得统计偏差变小,特别是对于高层中分辨率小的特征图,而且在使用小batch size的时候,比如4的时候,也可以有好的结果。
3. Scale-equalizing pyramid convolution
如果大家还记得SIFT这个非常有名的特征提取算子,大家应该会知道特征金字塔这个概念,不同分辨率的图像堆叠在一起,构成一个金字塔的形状,大分辨率图像在底下,小分辨率图像在上面。构建特征金字塔有两个主要操作,一个是高斯滤波,一个是降采样。在进行高斯滤波时,同一个level中的不同层之前的平滑程度是不一样的,是越来越大的。这其实和CNN中的卷积神经网络非常的相似,只是CNN中的层数会更多,参数可学习,而且中间还会有非线性变换。
这里,文章的附录中证明了一个说法,就是pyramid convolution可以在高斯金字塔中提取出尺度不变性的特征。这个在下面的图a中可以很直观的看出来:
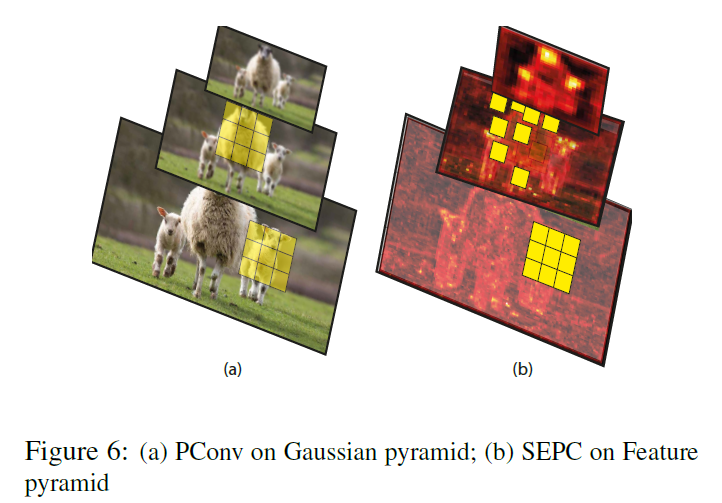
如果我们用N=1的PConv在金字塔中提取特征时,在不同的level上,使用相同的尺寸的卷积核,可以提取出不同尺度的特征。在构造高斯金字塔时,高斯模糊的目的是为了避免下采样时,高频噪声会留下来,影响下一层的特征提取,但是高斯模糊又不能太厉害,否则会伤害细节信息,所以,一般高斯模糊核的尺寸是和降采样率差不多的。
但是,如果我们用PConv来处理由CNN的backbone产生的特征金字塔的时候,这个特征金字塔和高斯金字塔还是很不一样的,不同的level之间的特征经过了很多的卷积和非线性层,如果把这种综合的效果也看成是一种模糊的话,这个模糊操作的模糊kernel是很大的,基本就是感受野的大小。从上图b中可以看到,是模糊的很厉害的。
如果我们要想去提取具有尺度不变性的特征的话,我们希望这个特征图的金字塔和高斯金字塔要比较相似才好,因为已经证明过高斯金字塔是可以用PConv提取尺度不变的特征的,所以如果特征图金字塔和高斯金字塔一样的话,也可以用PConv提取出尺度不变的特征。
而现在特征图金子图和高斯金字塔之间的主要的差别就是不同的level之间做的这个“模糊”效果不一样,特征图的“模糊”效果太厉害了,因此,原来的在不同的level上使用固定尺寸的高斯核就不合适了,高level的特征图使用的卷积核应该要大,而且,由于中间有很多的非线性的操作,导致每个像素之间还会不一样,所以不能只使用一个固定尺寸的卷积核。
于是,这里就很自然的用到了可变形卷积的思想,如上图的b,最底层的特征图用的是固定的3x3的卷积,但是上层的特征图上用的就是可变形的卷积核,这样一来,就可以做到不同level的特征图上提取出尺度一致的特征出来,这个操作就叫做scale-equalizing pyramid convolution (SEPC) 。实际上就是在PConv中,对于高level的特征图使用可变形卷积。
4. 实验
iBN的效果:基本都有效果,不同的方法略有不同。
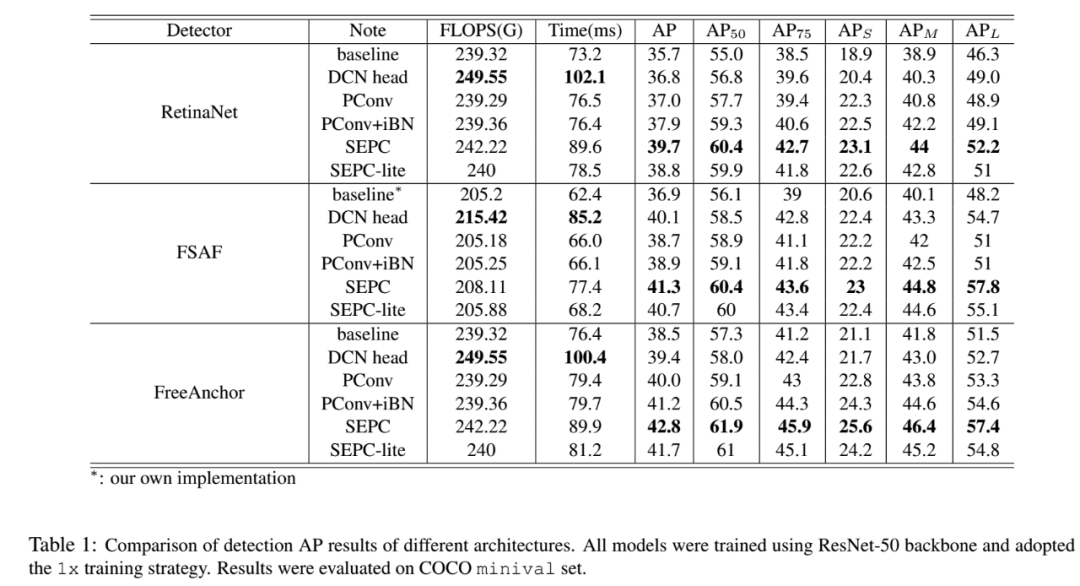
和DCN的对比,也就是把RetinaNet中head中的卷积换成DCN:
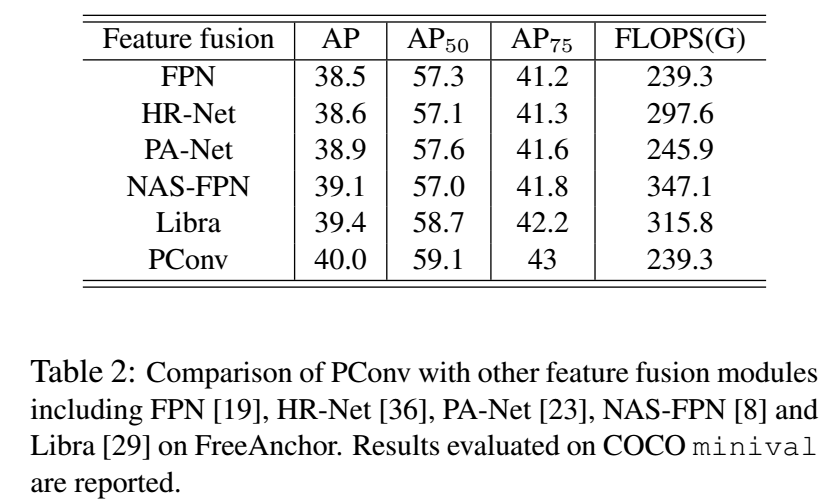
和其他不同的特征融合模块相比:
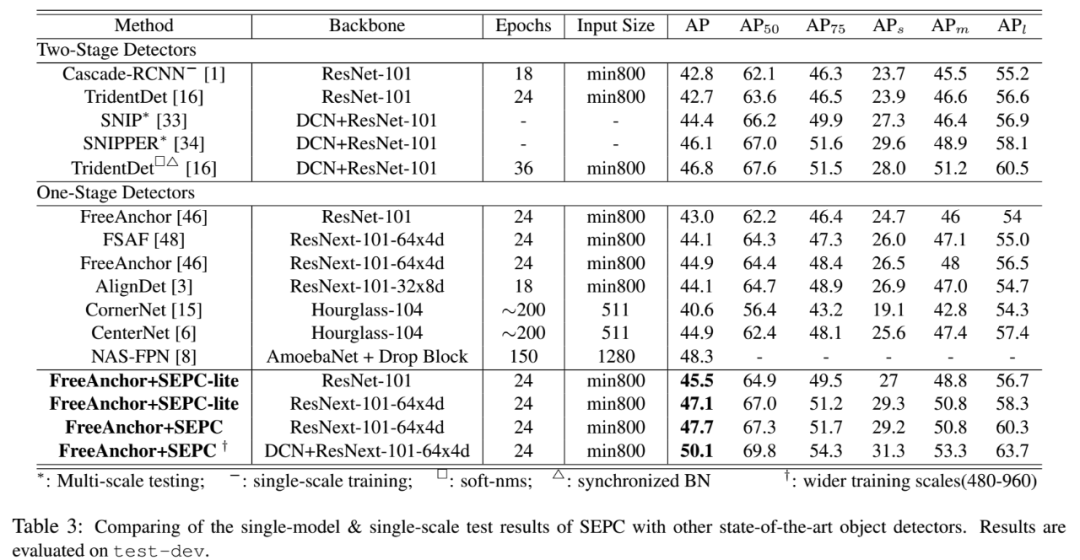
和其他的检测器相比:

论文链接:https://arxiv.org/abs/2005.03101
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: