
海到无边天作岸——万字长文Go接口辛秘
Go接口
接口为Go语言提供了解释世界的强大抽象。通过接口,我们能够更好的以模块化的设计构建起复杂、庞大、可维护的系统.从而对方便每一个模块进行构造,更换和调试(想象对一辆汽车的零件进行构造,更换和调试的过程)
通过构建适当隐藏细节的抽象来控制系统复杂性,决不是计算机编程中独有的设计,而是所有工程设计所共用的技巧。
鉴于接口的重要性,在本节中,笔者将详细介绍接口使用的方法、技巧、陷阱、效率和最佳实践。同时深入探讨接口底层的设计原理
Go语言中的接口遵循
duck test的设计哲学,duck test通俗的的解释是:"如果它看起来像鸭子,游起来像鸭子,叫起来像鸭子,那么它就是一只鸭子"
在计算机编程中,其指的是对象的适用性取决于对象的属性与行为,而与对象本身的类型无关。(一个人可以通过观察某个对象的习惯特征来识别该对象,同样的,我们可以通过接口来表明某种对象的特征)。
在Go语言中,接口是类型可以实现的方法签名的集合.方法签名仅仅包含了方法名、输入参数和返回值。
因此,接口定义了对象的一组行为。例如手机可以打电话与发短信。如果我们定义了包含打电话与发短信方法签名的手机接口,那么不管是安卓手机还是苹果手机,只要实现了打电话与发短信的方法,我们就说安卓手机与苹果手机实现了手机的接口。
另外,和其他语言不同的是,在Go语言中接口的实现是隐式的。即我们不用去明确的指出某一个类型实现了某一个接口.只要某一类型的方法中实现了接口中的全部方法签名,就意味着此类型实现了这一接口。
接口的用法
接口的定义
要使用接口,需要首先对接口进行定义。接口的定义需要使用到interface关键字。如下我们定义了一个手机接口,具有两个方法签名call()以及SendMsg(msg string) bool
type Phone interface {
call()
SendMsg(msg string) bool
}
接口的声明
接口的声明与其他类型类似,例如
var phone Phone
如果只是对接口进行了声明,则当前接口变量为nil。可以通过一个简单的程序来验证:
func main() {
var phone Phone
fmt.Println("phone value:",phone)
}
输出为:
phone value:
接口实现
要实现一个接口很简单,只需要实现其内部所有的方法签名.例如我们可以新建一个AndroidPhone类型,并实现接口对应的方法签名。
type AndroidPhone struct {
}
func (a AndroidPhone) call() {
fmt.Println("AndroidPhone calling")
}
func (a AndroidPhone) SendMsg(msg string) bool {
fmt.Println("AndroidPhone sending msg")
return true
}
当前,类型AndroidPhone实现了接口Phone中所有的方法签名时。因此,类型AndroidPhone就已经隐式的的实现了接口0CPhone.
接口动态类型
当类型实现了接口,接着我们就可以将类型变量赋值给接口变量。由于接口变量可以存储不同实现了此接口的类型.
因此在本文中,我们将存储在接口中的类型称为接口的动态类型。而将接口本身的类型称作接口的静态类型.
var phone Phone
phone = AndroidPhone{}
如果将AndroidPhone类型的SendMsg方法删除掉,那么程序将不能通过编译。
cannot use AndroidPhone literal (type AndroidPhone) as type Phone in assignment:
AndroidPhone does not implement Phone (missing SendMsg method)
这表明要实现接口,类型必须实现程序的所有方法。
接口变量可以替换为其他动态类型,例如,我们可以新建一个新的类型IPhone
type IPhone struct {
}
func (a IPhone) call() {
fmt.Println("IPhone calling")
}
func (a IPhone) SendMsg(msg string) bool {
return true
}
可以将phone接口替换为一个新的动态类型,如下所示:
var phone Phone = AndroidPhone{}
phone = IPhone{}
接口的动态调用
当接口中存储了具体的动态类型,即可以调用接口中所有的方法。
func main() {
var phone Phone = AndroidPhone{}
phone.call()
}
输出为:
"AndroidPhone calling"
接口动态调用的过程实质上是调用当前接口动态类型中具体方法的过程。
例如上例接口phone中存储的动态类型为AndroidPhone,因此接口调用phone.call()与直接调用AndroidPhone{}.call()类似。
随着接口变量存储了不同的动态类型,接口动态调用表现出不同动态类型的行为。例如
func main() {
var phone Phone = AndroidPhone{}
phone.call()
phone = IPhone{}
phone.call()
}
输出为:
"AndroidPhone calling"
"IPhone calling"
多接口
一个类型可能同时实现了多个接口,例如现在添加一个游戏机的接口。
type gameConsole interface {
Play()
}
接着我们可以让AndroidPhone类型在实现Phone接口的同时,实现gameConsole接口中的方法签名。
func (a AndroidPhone) Play() {
fmt.Println("playing game")
}
func (a AndroidPhone) call() {
fmt.Println("AndroidPhone calling")
}
func (a AndroidPhone) SendMsg(msg string) bool {
fmt.Println("AndroidPhone sending msg")
return true
}
下例可以看到,phone与game作为不同的接口可以存储相同的动态类型。
func main() {
ap := AndroidPhone{}
var phone Phone = ap
var game gameConsole = ap
phone.call()
game.Play()
}
接口调用后,其输出为:
AndroidPhone calling
playing game
接口的组合
定义接口时,接口可以是其他接口的组合,例如在前面的例子中,如果希望把游戏机与手机接口组合起来,变成多功能接口AllInOne,可以使用如下定义方式:
type AllInOne interface {
gameConsole
Phone
}
在上例中,AllInOne类似于父接口,gameConsole,Phone类似于子接口。
如果一个类型实现了父接口,那么其一定实现了所有的子接口。
同理,要继承父接口,必须继承其内部的所有子接口。
接口的组合帮助开发者构建起更强大的抽象,在Go语言的源码中应用广泛。
例如go语言io package中的ReadWriter接口,其结合了Reader 与 Writer:
type ReadWriter interface {
Reader
Writer
}
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
当类型实现了ReadWriter,意味着此类型即可"读" 又可"写"。
接口类型断言
可以使用语法i.(Type)在运行时获取存储在接口中的类型。其中i代表接口,Type代表实现此接口的动态类型。在编译时即会保证类型Type一定是实现了接口i的类型,否则编译不会通过。
但是Go在运行时还会再次检查存储在接口中的类型是否与Type相同。我们可以将之前的案例改写如下:
func main() {
ap := AndroidPhone{}
var phone Phone = ap
apNew := phone.(AndroidPhone)
apNew.Play()
}
在上例中,phone接口存储了动态类型AndroidPhone。因此,我们可以使用phone.(AndroidPhone) 获取到此值。
此时可以使用apNew变量直接调用call方法。因为现在apNew是实现了call方法的AndroidPhone结构体变量。
为什么Go语言在运行时还需要再判断一次呢,这是由于在类型断言方法m = i.(Type)中,如果Type实现了接口i,但是此时接口内部并没有任何动态类型(此时为nil),这时在运行时会直接panic.
因为nil无法调用任何的方法。
例如下面的程序中,接口phone并没有赋值,此时接口内部并没有任何动态类型
func main() {
var phone Phone
ap := phone.(AndroidPhone)
ap.Play()
}
在运行时,直接报错为:
panic: interface conversion: main.Phone is nil, not main.AndroidPhone
为了避免运行时报错的尴尬局面,类型转换还具有第二种接口类型断言语法
value, ok := i.(Type)
通过上面的语法,可以通过返回的ok变量判断接口变量i当前是否存储了实现其的动态类型。
var phone Phone
_,ok := phone.(AndroidPhone)
在上面的例子中,由于phone接口变量并未存储任何值,因此ok变量值为false.
空接口
可能有人会想,如果接口中没有任何的方法签名会发生什么情况呢?这是Go语言中一类特殊的接口,叫做空接口。其定义非常简单:
type Empty interface {
}
空接口可以存储结构体、字段串、整数等任何的类型。
var a1 Empty = Cat{"Mimi"}
var a3 Empty = "Learn golang with me!"
var a4 Empty = 100
var a5 Empty = 3.14
空接口提供了强大的抽象,应用非常的广泛。例如,我们平时经常使用的输入输出函数fmt.Println其参数就是一个空接口.
func Println(a ...interface{}) (n int, err error)
Println可以根据空接口中实际传入类型的不同(例如字符串,bool,切片)进行不同的输出。
因此,Go语言中必然提供了一种方式在空接口中获取接口中存储的动态类型。其语法是
i.(type)
其中,i代表接口变量,而type是固定的关键字。不可与带方法接口的断言混淆。同时,此语法仅在switch语句中有效。
例如在Println源码中,使用switch语句嵌套这一语法获取空接口中的动态类型。并根据动态类型的不同,进行不同的格式化输出。
switch f := arg.(type) {
case bool:
p.fmtBool(f, verb)
case float32:
p.fmtFloat(float64(f), 32, verb)
case float64:
p.fmtFloat(f, 64, verb)
...
我们可以根据上面的语法封装实现一个自己的Println函数。
例如下例中当传递的参数是字符串类型,就将字符串转换为大写并输出。
func MyPrintln(arg interface{}){
switch arg.(type) {
case string:
fmt.Println("string:",strings.ToUpper(arg.(string)))
case bool:
fmt.Println("this is bool")
case float32,float64:
fmt.Println("this is float")
...
}
}
接口的比较性
两个接口之间可以通过==或!=进行比较。
var a, b interface{}
fmt.Println( a == b )
例如上例中动态值为nil的a,b变量总是相等的。
如果两个接口不为nil,如果他们具有相同的动态类型与动态类型值,则两个接口是相同的。
如果接口存储的动态类型值是不可比较的,在运行时会报错。
如果只有1个接口为nil,那么比较结果总是false。
深入接口
编译时判断接口实现算法
我们之前介绍过,当具体的类型赋值给接口时,如果此类型并未实现接口中的所有方法,则在编译时即会报错。因此,在本小节中将探究Go语言编译时做出的努力。
通常来说,如果类型的方法与接口的方法是完全无序的状态,并且类型有m个方法,接口声明了n个方法,那么总的时间复杂度最坏情况应该为o(m*n),即我们需要分别遍历类型与接口中的方法。
Go语言在编译时对此做出的优化是首先将类型与接口中的方法进行相同规则的排序。接着再分别对应的进行比较。用一张图来进行说明:
在理想情况下,接口与类型的方法是一一对应的。
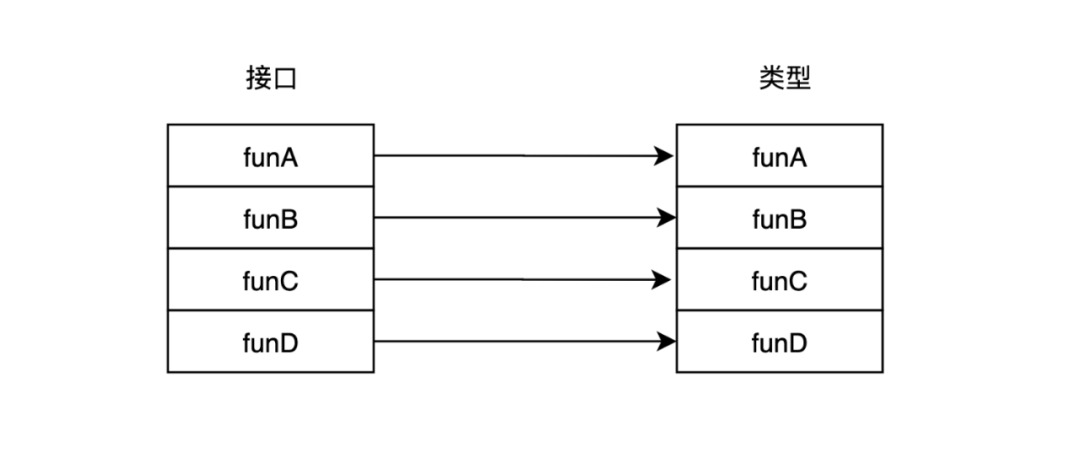
但有时候类型的方法可能会少于或者多于接口的方法。这时,虽然对应方法可能不会位于对应的位置,但是仍然是有序的。
有序规则保证了;如果funB在接口方法列表中序号为 i. 则如果funB也在类型的方法列表中,那么funB的序号必然大于等于i.
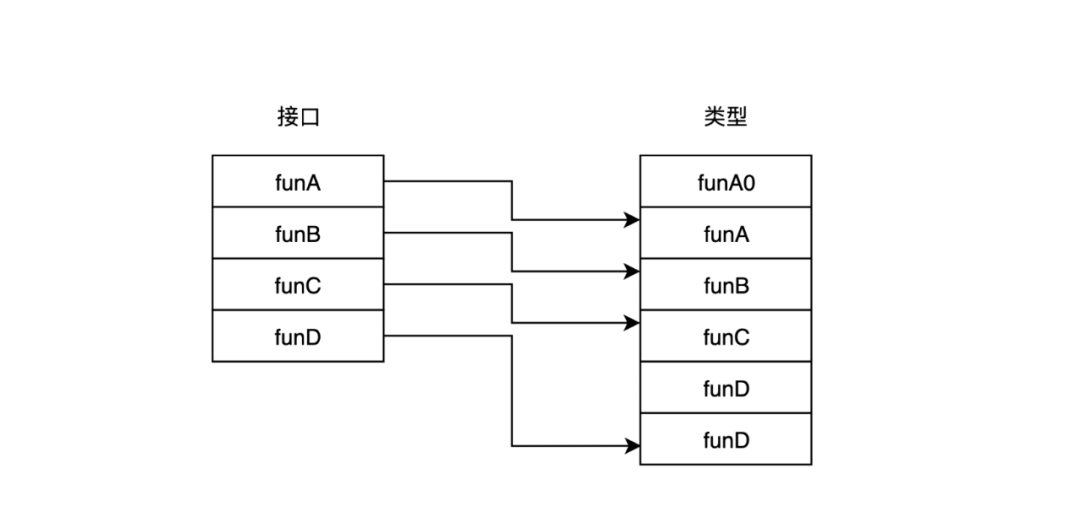
根据接口的有序规则,遍历接口方法列表,并在类型对应方法列表的序号i之后一路查找是否存在相同的方法。如果到最后也查找不到,说明类型对应方法列表中并无此方法,因此在编译时即会报错.
由于同一个类型或接口的排序只会进行一次。如果不考虑时间的消耗,那么最坏的时间复杂度仅为o(m+n)
在编译时,查找类型是否实现了接口的逻辑位于implements.如下为裁剪后包含了核心逻辑函数。通过遍历接口列表,并与类型方法列表中对应位置进行比较。确定是否实现了接口
func implements(t, iface *types.Type, m, samename **types.Field, ptr *int) bool {
i := 0
for _, im := range iface.Fields().Slice() {
for i < len(tms) && tms[i].Sym != im.Sym {
i++
}
if i == len(tms) {
return false
}
tm := tms[i]
if tm.Nointerface() || !types.Identical(tm.Type, im.Type) {
return false
}
}
在比较之前,分别会对接口与类型的方法进行排序,排序使用了Sort函数,其会根据元素数量选择不同的排序方法。
而排序的规则相对简单,即根据代表了函数名和包名的Sym进行排序。因为Go语言根据函数名和包名可以唯一确定命名空间中的函数。
sort.Sort(methcmp(ms))
// methcmp sorts methods by symbol.
type methcmp []*types.Field
func (x methcmp) Len() int { return len(x) }
func (x methcmp) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
func (x methcmp) Less(i, j int) bool { return x[i].Sym.Less(x[j].Sym) }
接口的组成
在之前介绍过接口的基本使用方式,在本小节中,将具体查看接口的实现原理。接口也是Go语言中的一种类型,一般的的接口其在运行时的具体结构由iface构成。
type iface struct {
tab *itab
data unsafe.Pointer
}
iface由两个指针组成,在X64位架构下,一共占据16个字节。
其中itab结构存储了接口的类型以及接口中的动态数据类型
由于存储的数据可能很大也可能很小,难以预料。data字段存储接口中具体值的指针。这表明存在在接口中的值必须能够获取到其地址。所以平时分配在栈中的值一旦赋值给接口之后,会发生内存逃逸现象,在堆区为其开辟内存。
我们可以用一段简单的程序来验证内存溢出问题。
package main
type Mathifier interface{ Add(a, b int32) int32 }
type Math struct{ id int32 }
func (math Math) Add(a, b int32) int32 { return a + b }
func main() {
adder := Math{id: 6754}
m := Mathifier(adder)
m.Add(10,12)
}
这一段简单的程序在12行处多执行了接口的调用,这是因为避免编辑器优化后,会看不出指定的效果。
当查看汇编指令后会看到11行调用了运行时的convT32函数。
(escape.go:11) CALL runtime.convT32(SB)
convT32函数在堆区分配了内存,并将值存储其中,从而完成了内存逃逸。
func convT32(val uint32) (x unsafe.Pointer) {
if val == 0 {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(4, uint32Type, false)
*(*uint32)(x) = val
}
return
}
如果我们查看一些比较老的文章,可能会发现调用的并不是这一函数,这是因为在18年,Go语言在转换为接口时,对基本的类型例如int32、int64、slice、string进行了特殊的优化.减少了运行时的负担。笔者在后面将详细介绍。总之,我们可以通过这一案例,看到接口的内存逃逸现象。
我们甚至可以通过BenchMark测试来可视化堆分配的情况
在escape_test.go中,执行两个benchmark测试,其中BenchmarkDirect使用直接函数调用的方式,BenchmarkInterface中接口包装了adder,使用接口动态调用的方式。
func BenchmarkDirect(b *testing.B) {
adder := Sumer{id: 6754}
for i := 0; i < b.N; i++ {
adder.Add(10, 32)
}
}
func BenchmarkInterface(b *testing.B) {
adder := Sumer{id: 6754}
for i := 0; i < b.N; i++ {
Sumifier(adder).Add(10, 32)
}
}
通过go tool compile工具,仍然可以看到,接口的逃逸过程
escape_test.go:15:11: Sumifier(adder) escapes to heap
接着可以执行Bench指令go test -bench=. -benchmem,输出为:
BenchmarkDirect-12 1000000000 0.495 ns/op 0 B/op 0 allocs/op
BenchmarkInterface-12 92240901 11.7 ns/op 4 B/op 1 allocs/op
通过Benchmark测试我们能够看到接口的动态调用,每个操作比花费了比直接调用更多的时间,这在后面会进行讨论。
同时可以看到,接口方式由于逃逸现象,每一个操作会进行堆分配,大小为4个字节。
组成接口的itab结构如下,itab是接口的核心,其发音为i-table,出处来自于C语言中组成接口的的Itab.
type itab struct {
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
其中_type字段代表了接口存储的动态类型。Go语言在运行时的类型都使用_type表示。
inter字段代表了接口本身的类型,类型interfacetype是对_type的简单包装
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
除了类型标识_type,还包含了一些接口的元数据。pkgpath代表接口所在的包名,mhdr []imethod表示接口中方法在最终可执行文件中的偏移量。
hash 是接口动态类型的唯一标识,后面会看到,在接口类型断言时,可以使用该字段快速判断接口动态类型与具体类型 _type 是否一致;
一个空的_4字节用于内存对齐
最后的fun字段代表接口动态类型中函数指针列表,用于运行时接口进行动态函数调用。要注意这里虽然在运行时只定义了[1]uintptr,但是其存储的是函数首地址的指针。当有多个函数时,其指针会依次在下方存储。在运行时,可以通过首地址 + 偏移找到任意的函数指针。
接口的动态调用过程
在了解了接口的组成后,接着来介绍接口的动态调用过程,从而理解接口的工作原理。
在这里仍然以之前一个简单的例子探究接口的动态调用过程。
package main
type Mathifier interface{ Add(a, b int32) int32 }
type Math struct{ id int32 }
func (math Math) Add(a, b int32) int32 { return a + b }
func main() {
adder := Math{id: 6754}
m := Mathifier(adder)
m.Add(10,12)
}
执行
go tool compile -S escape.go
查看汇编代码,在这里忽略掉一些垃圾回收,栈初始化、栈扩容等等代码,关注于最核心的细节。
MOVL $6754, (SP)
CALL runtime.convT32(SB)
LEAQ go.itab."".Math,"".Mathifier(SB), AX
TESTB AL, (AX)
MOVQ 8(SP), AX
MOVQ go.itab."".Math,"".Mathifier+24(SB), CX
MOVQ AX, (SP)
MOVQ $51539607562, AX
MOVQ AX, 8(SP)
CALL CX
第一行中,首先将参数6754放入栈顶,作为第二行中运行时convT32函数的参数。
我们在之前已经简单介绍过,如果是int32、int64、字符串、切片等类型会进行特殊的优化,优化的方式是在运行时只生成指针进行内存的逃逸,而编译时会指定在全局变量区存储接口类型。
在编译时,通过convFuncName函数检查要转换类型的大小以及具体类型,从而选择运行时不同的函数。
func convFuncName(from, to *types.Type) (fnname string, needsaddr bool) {
tkind := to.Tie()
switch from.Tie() {
case 'I':
if tkind == 'I' {
return "convI2I", false
}
case 'T':
switch {
case from.Size() == 2 && from.Align == 2:
return "convT16", false
case from.Size() == 4 && from.Align == 4 && !types.Haspointers(from):
return "convT32", false
case from.Size() == 8 && from.Align == types.Types[TUINT64].Align && !types.Haspointers(from):
return "convT64", false
}
if sc := from.SoleComponent(); sc != nil {
switch {
case sc.IsString():
return "convTstring", false
case sc.IsSlice():
return "convTslice", false
}
}
关于Go语言具体优化的过程可以查看golang commit:
https://github.com/golang/go/commit/5848b6c9b854546473814c8752ee117a71bb8b54。
接着第三行,我们看到描述符go.itab."".Math,"".Mathifier(SB),它表明了在全局变量区存储了接口Mathifier,并且其动态类型为Math的区域。
获取其位置指针并执行TESTB指令,用于检查此接口的地址是否为空。
第5行MOVQ 8(SP), AX 用于将runtime.convT32函数返回的地址存储到AX寄存器中
第6行MOVQ go.itab."".Math,"".Mathifier+24(SB), CX 用于获取接口区域第24位偏移的位置,此位置恰好是第一个函数指针所在的位置。
通过接口第一个字段itab的结构即可看出,第24字节所在的位置,从而获取到需要的函数指针。
type itab struct {
inter *interfacetype // 8-byte
_type *_type // 16-byte
hash uint32 // 20-byte
_ [4]byte // 24-byte
fun [1]uintptr
}
第7行MOVQ AX, (SP) 将当前Math结构体的指针放入栈顶。因为方法的调用,第一个参数即是方法的调用者。
第8行MOVQ $51539607562, AX 将参数10和12一起放入栈中
第9行CALL CX 即动态的调用函数。
通过这一个简单的案例,能看出接口动态调用的基本思路。即找到接口的位置,再通过偏移量找到要调用的函数指针。
当然,正如之前介绍过的。在这里Go语言进行了一定的优化。对于一般的结构,例如:
package main
type Mathifier interface{ Add(a, b int32) int32 }
type Math struct{
id int32
name string
}
func (math Math) Add(a, b int32) int32 { return a + b }
func main() {
adder := Math{id: 6754,name:"math"}
m := Mathifier(adder)
m.Add(10,12)
}
汇编的核心代码如下
(escape.go:14) MOVL $6754, ""..autotmp_2+32(SP)
(escape.go:14) LEAQ go.string."math"(SB), AX
(escape.go:14) MOVQ AX, ""..autotmp_2+40(SP)
(escape.go:14) MOVQ $4, ""..autotmp_2+48(SP)
(escape.go:14) LEAQ go.itab."".Math,"".Mathifier(SB), AX
(escape.go:14) MOVQ AX, (SP)
(escape.go:14) LEAQ ""..autotmp_2+32(SP), AX
(escape.go:14) MOVQ AX, 8(SP)
(escape.go:14) CALL runtime.convT2I(SB)
(escape.go:14) MOVQ 24(SP), AX
(escape.go:14) MOVQ 16(SP), CX
(escape.go:15) MOVQ 24(CX), CX
(escape.go:15) MOVQ AX, (SP)
(escape.go:15) MOVQ $51539607562, AX
(escape.go:15) MOVQ AX, 8(SP)
(escape.go:15) CALL CX
其看起来比之前优化过的代码要复杂一些。实质是一样的。
前面几行是简单的参数分配到栈中。关键是现在调用了运行时函数convT2I.在运行时生成iface结构。其中的参数tab*itab 位于全局变量区域。
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
在这里无法优化的原因在于,当结构体的类型无法确定时,其大小也是也无法确定的。
在汇编代码中:16(SP), CX对应于将convT2I函数返回接口的itab字段放入CX寄存器,并通过偏移24(CX)找到要调用的函数指针。24(SP), AX对应于将convT2I函数返回的data字段放入AX寄存器中,接着AX, (SP)即可作为函数调用的第一个参数。
由此可见,对于一般的接口调用场景,仍然是比较非常简单的。
接口动态调用过程的效率评价
抽象必然牺牲运行效率.但是,强大的现实解释性和解耦性换来了开发效率的提升。
接口作为Go语言官方在语言设计时鼓励并推荐的习惯用法,甚至在Go源代码中也经常看到他们的身影。从这一事实出发已经足够让人相信接口动态调用的效率损失是很小的。确实,实际在大部分情况下,接口的成本被视作可以忽略不计的。
从我们之前查看汇编代码的过程,也可以看出如果我们忽略转换为接口的过程(毕竟,在实际中接口转换只会发生一次),而单纯的关注接口调用过程,其消耗可能就在于查找函数指针的位置,并动态调用所带来的消耗。
但是,当我们打算深入谈论"接口动态调用过程的效率"时,却远远没有这么简单,其不仅涉及到编译器的优化、还设置涉及到操作系统和硬件。
比如当我们运行下面的benchmark案例,试图去量化接口的效率损失时,接口可能让人吃惊
type Mathifier interface{ Add(a, b int32) int32 }
type Math struct{
id int32
}
func (math Math) Add(a, b int32) int32 { return a + b }
func BenchmarkDirect(b *testing.B) {
math := &Math{id: 6754}
b.ResetTimer()
for i := 0; i < b.N; i++ {
math.Add(10, 12)
}
}
func BenchmarkInterface(b *testing.B) {
mathifer := Mathifier(&Math{id: 6754})
b.ResetTimer()
for i := 0; i < b.N; i++ {
mathifer.Add(10, 12)
}
}
当我们直接使用benchmark命令:
go test . -bench .
输出为:
goos: darwin
goarch: amd64
pkg: jonsonProject
BenchmarkDirect-12 1000000000 0.254 ns/op
BenchmarkInterface-12 517134637 2.29 ns/op
惊讶的发现普通函数的效率居然是接口调用的10倍。到底发生了什么?其实只要我们简单的把上面的程序转换为汇编代码就能看出其中的端倪:
在汇编代码中,普通的函数调用居然没有发生CALL调用,为什么呢?这里我们列出不使用编译器优化前的代码,因为如果经过了编译器的优化,就完全看不出里面的逻辑了,因为加法操作都不用在运行时执行了.
为go tool compile添加 -N 标识禁止编译器优化,这时生成的汇编代码直接使用了ADDL指令,而并没有进行真实的函数调用。这是由于编译器进行了函数内联的过程。这也是编译器加速代码执行的方式之一.
0x0084 00132 (escape_test.go:17) MOVL $10, "".a+20(SP)
0x008c 00140 (escape_test.go:17) MOVL $12, "".b+16(SP)
0x009c 00156 (escape_test.go:12) MOVL "".a+20(SP), AX
0x00a0 00160 (escape_test.go:12) ADDL "".b+16(SP), AX
在现实场景中,函数一般比较复杂,编译器一般会采取保守的策略,并不会执行函数内联。
因此,如果我们使用上面的案例去说明接口动态调用与直接调用的效率显然是不准确的。
因此,为了消除函数内联的影响,我们可以在函数的上方加上注释:
//go:noinline
func (math Math) Add(a, b int32) int32 { return a + b }
此标识会被编译器识别并采取禁止内联的策略.
当禁止内联后,再次执行benchmark测试时,会发现需要动态调用和直接调用花费的时间都相应提高了。
但是现在二者的时间差距已经没有那么夸张了, 直接调用时间大约是接口动态调用的2倍多.
goos: darwin
goarch: amd64
pkg: jonsonProject
BenchmarkDirect-12 738044662 1.66 ns/op
BenchmarkInterface-12 305086282 3.94 ns/op
但是这可能仍然不符合我们的预期,如果查找一下函数指针就需要花费2倍的时间,显然是不合理的。现在的问题又出在哪呢?
这又涉及到另一个问题。即复制问题。由于我们方法的接收者是结构体值,而不是结构体指针。而接口中的存储的值是逃逸到堆区的指针,
因此,这还涉及到从堆区复制值到栈中的过程。
(escape_test.go:27) MOVQ $51539607562, DX
(escape_test.go:27) MOVQ DX, 8(SP)
(escape_test.go:27) CALL "".(*Math).Add(SB)
在上面的汇编代码中,"".(*Math).Add(SB) 其实是编译器自动生成包装函数,其会多执行将堆中的内存分配到栈中的过程.并最终调用"".Math.Add(SB)函数
"".(*Math).Add STEXT dupok size=120 args=0x18 locals=0x20
0x0030 00048 (<autogenerated>:1) MOVL (AX), AX
0x0032 00050 (<autogenerated>:1) MOVL AX, (SP)
0x0035 00053 (<autogenerated>:1) MOVL "".a+48(SP), AX
0x0039 00057 (<autogenerated>:1) MOVL AX, 4(SP)
0x003d 00061 (<autogenerated>:1) MOVL "".b+52(SP), AX
0x0041 00065 (<autogenerated>:1) MOVL AX, 8(SP)
0x0045 00069 (<autogenerated>:1) CALL "".Math.Add(SB)
其实,只要值已经逃逸到了堆区,那么即便是这里不是接口,通过指针去调用值接受者的方法时,都涉及到从堆区复制值到栈中的过程。
但是在此例中,直接调用时,其值是在栈中的,因此,编译器直接把其转换为了值调用的形式。减少了内存复制的开销。
(escape_test.go:19) MOVQ $51539607562, AX
(escape_test.go:19) MOVQ AX, 4(SP)
(escape_test.go:19) CALL "".Math.Add(SB)
将之前的值接受者改为指针接受者:
//go:noinline
func (math *Math) Add(a, b int32) int32 { return a + b }
func BenchmarkDirect(b *testing.B) {
adder := &Math{id: 6754}
b.ResetTimer()
for i := 0; i < b.N; i++ {
adder.Add(10, 12)
}
}
func BenchmarkInterface(b *testing.B) {
adderifer := Mathifier(&Math{id: 6754})
b.ResetTimer()
for i := 0; i < b.N; i++ {
adderifer.Add(10, 12)
}
}
再次执行benckmark测试后,会发现二者的差别确实是微乎其微。特别是考虑到纳秒 = 千分之一毫秒这一事实的时候。
goos: darwin
goarch: amd64
pkg: jonsonProject
BenchmarkDirect-12 823974543 1.42 ns/op
BenchmarkInterface-12 795988630 1.49 ns/op
因此这启发了我们在现编译器下执行接口的动态调用时,方法尽量使用指针接受者的方式。
对接口效率的另一个担忧,可能涉及到CPU分支预测的问题.
现代CPU会预取、缓存指令和数据甚至预先执行,对指令重新排序、并行化等等。
对于静态函数的调用,CPU会预知程序中即将到来的分支,并相应地预取必要的指令,这加速了程序的执行过程。
但是,使用动态调度时,CPU无法提前知道程序的执行分支,而只有直到运行时才能知道其结果。
为了解决此问题,CPU应用了各种算法和启发式方法来猜测程序下一步将分支到何处(即“分支预测”)
如果处理器猜对了,我们可以预期动态分支的效率几乎与静态分支一样,因为即将执行的指令已经被预取到了处理器的缓存中。
下面用两个经典的程序来说明分支预测问题。如下所示的程序有区别吗?
从表面上看,他们不过都执行了100001000100次,但是在实际运行时的时间差距却可能很大。
func fast(){
for i:=0;i<100;i++{
for j:=0;j<1000;j++{
for k:=0;k<10000;k++{
}
}
}
}
func slow(){
for i:=0;i<10000;i++{
for j:=0;j<1000;j++{
for k:=0;k<100;k++{
}
}
}
}
当我们对其执行简单的性能测试go test . -bench . -benchtime 10s
func BenchmarkCPUfast(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
fast()
}
}
func BenchmarkCPUslow(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
slow()
}
}
从结果的输出可以看出,在10秒钟,fast函数执行了45次,slow函数只能执行34次,fast函数比slow函数慢了35%。
goos: darwin
goarch: amd64
pkg: awesomeProject26/interfa
BenchmarkCPUfast-12 45 255706270 ns/op
BenchmarkCPUslow-12 34 347093008 ns/op
为什么会出现这么大的差别呢?原因就在于slow函数具有更多的分支预测错误次数。
CPU会根据PC寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面直面执行,然后根据指令长度自增、开始从内存中顺序读取下一条指令。
而循环或者`if else`会根据判断条件,产生两个分支。某一个分支成立对应着特殊的跳转指令,从而修改PC寄存器里面的地址,这样下一条要执行的指令就不是从内存里面顺序加载的。而另一个分支是顺序的读取内存中的指令.
分支预测策略最简单的一个方式是"假定跳转不发生"。如果假定CPU执行了这种策略,对应到上面的循环代码,就是循环始终会进行下去。
因此在上面的fast函数中,内层 k 循环每隔10000次,才会发生一次预测上的错误。而同样的错误,外层i、j每一次都会发生。j 的循环发生的次数,是1000次。最外层的 i 的循环是100次。所以一共会发生 100 × 1000 = 10万次预测错误。
而对于slow函数,内部k每100次循环,就会发生一次预测错误。而同样的错误,外层i、j每一次都会发生。第二层j循环发生1000次。最外层i的循环是10000次,所以一共会发生 1000 ×10000 = 1000万次预测错误。
很显然,从上面案例中可以看出,由于动态调用的难以预测性,对于分支预测的担忧不是没有道理的。但是需要强调的是,这种在理论上存在的问题,在现实中却极少成为问题。原因在于,正如循环和 if else 也可能导致分支预测错误一样。现实中不会有如此密集分支预测错误导致性能下降的情况。
另外一个事实是,现代CPU都有缓存。如果一个接口是经常使用的,那么其必然已经存在于L1缓存中,那么即便是分支预测失败,我们仍然能够快速的获取接口的函数指针,而不必再负担从内存中拷贝的开销。
空接口的组成
之前提到Go语言中的有一类特殊的接口——空接口,其没有任何的方法签名,也因此可以容纳任意的数据类型。
和一般的接口相比,我们不再需要interfacetype类型去表示特殊的接口内在类型,也不需要fun方法列表.
对于空接口,Go语言在运行时使用了特殊的eface类型.
type eface struct { // 16 bytes on a 64bit arch
_type *_type
data unsafe.Pointer
}
类型转换为eface时,空接口与一般接口的处理方法是相似的。同样面临着内存逃逸,寻址等问题。在进行内存逃逸时,对于特殊类型,仍然有和一般接口类似的优化函数:
func convT16(val uint16) (x unsafe.Pointer)
func convT32(val uint32) (x unsafe.Pointer)
func convT64(val uint64) (x unsafe.Pointer)
func convTstring(val string) (x unsafe.Pointer)
func convTslice(val []byte) (x unsafe.Pointer)
对于复杂类型,则会调用convT2E方法.
func convT2E(t *_type, elem unsafe.Pointer) (e eface) {
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
e._type = t
e.data = x
return
}
对于一般的接口,虽然知道其转换会有成本,但是在实际中,转换的次数是微不足道。因此我们并没有刻意去评估转换为一般接口的性能。
但是,由于空接口的可以容纳任何类型的特殊性,在实际中经常被使用,因此需要考虑空接口的性能。
下面的bench测试相对简单,对于类型unit32,一个直接复制到uint32变量,而一个赋值给空接口。
var Uint uint32
b.Run("uint32", func(b *testing.B) {
for i := 0; i < b.N; i++ {
Uint = uint32(i)
}
})
var Eface interface{}
b.Run("eface32", func(b *testing.B) {
for i := 0; i < b.N; i++ {
Eface = uint32(i)
}
})
通过bench测试输出结果发现,使用空接口赋值比直接赋值慢了近50倍。
goos: darwin
goarch: amd64
pkg: awesomeProject26/iface
BenchmarkEfaceScalar/uint32-12 1000000000 0.259 ns/op 0 B/op 0 allocs/op
BenchmarkEfaceScalar/eface32-12 100000000 10.5 ns/op 4 B/op 1 allocs/op
不难想出,空接口的笨重,主要在于其内存逃逸的消耗、加上创建eface对象,以及为堆区的的内存设置垃圾回收相关的代码。
因此,如果赋值的对象一开始就已经分配在了堆中,则不会有如此夸张的差别。
可以用一个特殊的案例来说明这一点,将上一个案例中的unit32类型转换为uint8类型
var Uint uint8
b.Run("uint8", func(b *testing.B) {
for i := 0; i < b.N; i++ {
Uint = uint8(i)
}
})
var Eface interface{}
b.Run("eface8", func(b *testing.B) {
for i := 0; i < b.N; i++ {
Eface = uint8(i)
}
})
当再次执行benchmark测试时,会发现空接口比之前的案例快了10倍。
goos: darwin
goarch: amd64
pkg: awesomeProject26/iface
BenchmarkEfaceScalar/uint8-12 1000000000 0.251 ns/op 0 B/op 0 allocs/op
BenchmarkEfaceScalar/eface8-12 1000000000 0.998 ns/op 0 B/op 0 allocs/op
为什么仅仅是替换了数据类型差距就这么大呢?当仔细查看benchmark测试输出的结果时可能会发现端倪,这次空接口并没有消耗在堆区分配任何的内存。
实际上,Go语言对单字节具有特别的优化。其已经在程序一开始全部存储在了内存中。因此在此例中,没有了内存分配的消耗,速度快了不少。
但频繁使用空接口造成的效率损失任然是在某些场景中需要关注的问题。
// staticbytes is used to avoid convT2E for byte-sized values.
var staticbytes = [...]byte{
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f,
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x1a, 0x1b, 0x1c, 0x1d, 0x1e, 0x1f,
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2a, 0x2b, 0x2c, 0x2d, 0x2e, 0x2f,
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3a, 0x3b, 0x3c, 0x3d, 0x3e, 0x3f,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4a, 0x4b, 0x4c, 0x4d, 0x4e, 0x4f,
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x58, 0x59, 0x5a, 0x5b, 0x5c, 0x5d, 0x5e, 0x5f,
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67, 0x68, 0x69, 0x6a, 0x6b, 0x6c, 0x6d, 0x6e, 0x6f,
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78, 0x79, 0x7a, 0x7b, 0x7c, 0x7d, 0x7e, 0x7f,
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89, 0x8a, 0x8b, 0x8c, 0x8d, 0x8e, 0x8f,
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97, 0x98, 0x99, 0x9a, 0x9b, 0x9c, 0x9d, 0x9e, 0x9f,
0xa0, 0xa1, 0xa2, 0xa3, 0xa4, 0xa5, 0xa6, 0xa7, 0xa8, 0xa9, 0xaa, 0xab, 0xac, 0xad, 0xae, 0xaf,
0xb0, 0xb1, 0xb2, 0xb3, 0xb4, 0xb5, 0xb6, 0xb7, 0xb8, 0xb9, 0xba, 0xbb, 0xbc, 0xbd, 0xbe, 0xbf,
0xc0, 0xc1, 0xc2, 0xc3, 0xc4, 0xc5, 0xc6, 0xc7, 0xc8, 0xc9, 0xca, 0xcb, 0xcc, 0xcd, 0xce, 0xcf,
0xd0, 0xd1, 0xd2, 0xd3, 0xd4, 0xd5, 0xd6, 0xd7, 0xd8, 0xd9, 0xda, 0xdb, 0xdc, 0xdd, 0xde, 0xdf,
0xe0, 0xe1, 0xe2, 0xe3, 0xe4, 0xe5, 0xe6, 0xe7, 0xe8, 0xe9, 0xea, 0xeb, 0xec, 0xed, 0xee, 0xef,
0xf0, 0xf1, 0xf2, 0xf3, 0xf4, 0xf5, 0xf6, 0xf7, 0xf8, 0xf9, 0xfa, 0xfb, 0xfc, 0xfd, 0xfe, 0xff,
}
空接口类型switch
正如笔者在介绍fmt.PrintX函数时提到的,和空接口配套的必然是需要判断空接口的实际类型.我们将在这一小节中,尝试着对其进行探讨。
正如将在下面看到的,,对于一个最简单的类型switch语句,其本质上和if else在逻辑上其实并无差别.
var j uint32
var Eface interface{}
func typeSwitch() {
i := uint32(88)
Eface = i
switch Eface.(type) {
case uint16:
j = 99
case uint32:
j = 66
}
}
上面的代码生成汇编代码如下,下面列出了最核心的一段代码。其中,CMPL DX, $-800397251代表将空接口类型的hash与uint32类型的hash值-800397251进行比较。如果类型不相同,JNE 128直接跳转结束switch。如果类型相同,则继续比较CMPQ CX, AX类型的地址是否相同,这是为了防止前面的hash冲突设计的。如果类型确实相同,那么执行case成立后的语句。
0x0050 00080 (main.go:37) MOVQ "".Eface(SB), AX
0x005a 00090 (main.go:37) JEQ 118
0x005c 00092 (main.go:37) MOVL 16(AX), DX
0x005f 00095 (main.go:37) CMPL DX, $-800397251
0x0065 00101 (main.go:37) JNE 128
0x0067 00103 (main.go:37) CMPQ CX, AX
0x006a 00106 (main.go:37) JNE 128
0x006c 00108 (main.go:41) MOVL $66, "".j(SB)
0x0076 00118 () MOVQ 16(SP), BP
0x007b 00123 () ADDQ $24, SP
0x007f 00127 () RET
0x0080 00128 (main.go:37) CMPL DX, $-269349216
0x0086 00134 (main.go:37) JNE 118
0x0088 00136 (main.go:37) LEAQ type.uint16(SB), CX
0x008f 00143 (main.go:37) PCDATA $0, $0
0x008f 00143 (main.go:37) CMPQ CX, AX
0x0092 00146 (main.go:37) JNE 118
0x0094 00148 (main.go:39) MOVL $99, "".j(SB)
0x009e 00158 (main.go:37) JMP 118
在这里,可能读者会有两个疑问。第一个-800397251,-269349216 是如何来的,第二个问题是,为什么在代码中明明先判断uint16,再判断uint32。但是到了汇编代码中却变成了先判断uint32,再判断uint16类型,莫非Go语言对于其做了特殊的优化?
对于第一个问题,如果简单的通过运行时代码,强制打印出类型的hash,会发现他们的值是完全相同的。
type eface struct {
_type *_type
data unsafe.Pointer
}
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
//...
}
var Eface interface{}
func main() {
Eface = uint32(42)
fmt.Printf("eface._type.hash = %d\n" ,
int32((*eface)(unsafe.Pointer(&Eface))._type.hash))
Eface = uint16(42)
fmt.Printf("eface._type.hash = %d\n" ,
int32((*eface)(unsafe.Pointer(&Eface))._type.hash))
}
上面的例子模拟了运行时的eface接口以及type类型结构,从而通过强制转换的方式,打印出hash所在位置的值。
eface<uint32>._type.hash = -800397251
eface<uint16>._type.hash = -269349216
该值通过typehash 函数得出,从中可以看出根据类型生成了一串字符后,使用了MD5函数生成哈希。由于这种hash计算方法没有随机性,因此相同的类型总是具有相同的hash类型。
func typehash(t *types.Type) uint32 {
p := t.LongString()
// Using MD5 is overkill, but reduces accidental collisions.
h := md5.Sum([]byte(p))
return binary.LittleEndian.Uint32(h[:4])
}
对于第二个问题奇怪的问题,其实是在switch 类型判断时,根据类型hash值进行了快速排序。
type caseClauseByType []caseClause
func (x caseClauseByType) Len() int { return len(x) }
func (x caseClauseByType) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
func (x caseClauseByType) Less(i, j int) bool {
c1, c2 := x[i], x[j]
if c1.hash != c2.hash {
return c1.hash < c2.hash
}
return c1.ordinal < c2.ordinal
}
那为什么要进行排序呢?答案就是拍完序之后就可以进行二分查找了。笔者将这个话题留给读者….
总结
接口为Go语言提供了解释世界的强大抽象,是编写出优雅可维护代码至关重要的润滑剂。
在本文中,笔者首先详细介绍了接口基本使用的方法,力求做到全面并且循序渐进。
接着深入探讨了接口内部的实现细节。包括接口与空接口的组成,接口赋值、接口转换、接口动态调用等过程,并对其效率进行了评估。
在本文中,至少有几个点是对于目前已有文章的突破,
第一、深入介绍了接口编译时判断接口实现的算法优化,即根据函数签名进行了排序,将最坏o(m*n)的复杂度缩减到最坏o(m+n)
第二、基于较新的go1.13编译器,介绍了接口编译时对于特殊类型string、int、slice的优化
第三、深入探讨、评价了接口动态调用的效率问题,指出了有很多案例在评价接口动态调用效率时的不合理之处。
第四、介绍了空接口类型switch转换时利用hash值进行二分查找的算法特点。
这篇文章还有几个东西我还没有来得及介绍:
第一、接口的经典错误来不及介绍
第二、接口的复制、接口转接口、还有一些技巧来不及介绍
第三、接口的最佳实践
留待以后吧,see you ~
推荐阅读
站长 polarisxu
自己的原创文章
不限于 Go 技术
职场和创业经验
Go语言中文网
每天为你
分享 Go 知识
Go爱好者值得关注