
MySQL 索引的知识点都在这里了,建议收藏!

Java技术栈
www.javastack.cn
关注阅读更多优质文章
数据库索引,相信大家都不陌生吧。
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。作为辅助查询的工具,合理的设计索引能很大程度上减轻db的查询压力,db我们都知道,是项目最核心也是最薄弱的地方,如果压力太大很容易产生故障,造成难以预计的影响。所以,不管是日常开发还是面试,索引这一块知识体系都是必须掌握的。
当然,虽说是必须掌握,但索引的知识点很多,很多初学者经常会遗漏,这也是我为什么想写这篇知识点总结的原因,既是给读者的分享,也是给自己一次全面的复习,希望对你们有所帮助。
好了,废话不多说,进入正题。
首先声明一下,本文索引的知识点全部是基于MySQL数据库
索引的优缺点
优点:
1.大大加快数据的查询速度
2.唯一索引可以保证数据库表每一行的唯一性
3.加速表连接时间
缺点:
1.创建、维护索引要耗费时间,所以,索引数量不能过多。
2.索引是一种数据结构,会占据磁盘空间。
3.对表进行更新操作时,索引也要动态维护,降低了维护速度
索引的类型
索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,所以这里也就引入了索引模型的概念。这里介绍三种常用于索引的数据结构,分别是哈希表、有序数组和搜索树。
哈希索引
哈希表,也称散列表,主要设计思想是通过一个哈希函数, 把关键码映射的位置去寻找存放值的地方 ,读取的时候也是直接通过关键码来找到位置并存进去,这种数据结构的平均查找复杂度为O(1)。
比如我们维护一张身份证信息和用户姓名的表,需要根据身份证号查询姓名,哈希索引大概是这样的:
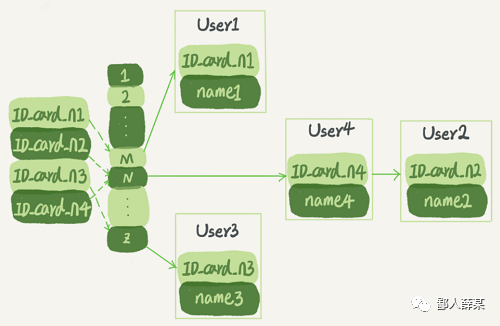
这种索引结构优点在于随机添加或删除单个元素的效率高,缺点在于哈希表中的元素并不一定按顺序排列,所以如果想做区间查询的话是很慢的,
假设我想查找图中身份证号在[ID_card_n1, ID_card_n3]这个区间的所有用户的话,就必须全部扫描一遍了。
所以,哈希表这种结构适用于只有等值查询的场景
有序数组索引
有序数组索引在等值查询和区间查询场景中的效率都很高,还是拿上面的图做例子,用有序数组实现的话是这样子的:
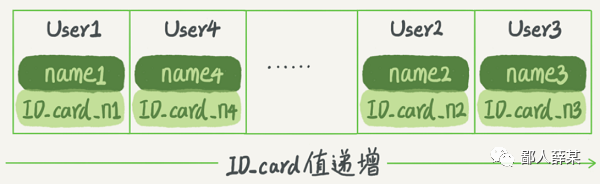
数组的元素按身份证号有序排列,要查询数据的时候,使用二分法就可以快速得到,时间复杂度为O(logN),而且,因为是有序排列,查询某个区间内的数据也是非常的快。
当然,有序数组的缺点也很明显,就跟ArrayList一样,虽然搜索快,但添加删除元素都有可能要移动后面所有的元素,这是数组的天然缺陷。所以,有序数组索引只适用于静态存储引擎,比如你要保存的是2017年某个城市的所有人口信息,这类不会再修改的数据。
搜索树索引
说到搜索树,我们最熟悉的应该就是二叉搜索树了,二叉搜索树的特点是每个结点的左儿子小于父结点,父结点又小于右儿子,并且左右子树也分别为二叉搜索树,平均时间复杂度是O(log2(n))。
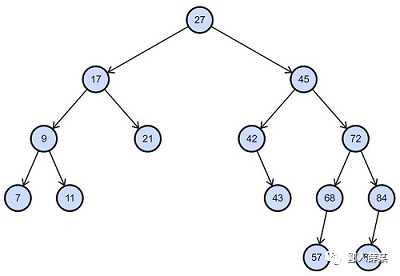
它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势,同时,因为本身二叉搜索树是有序的,所以也支持范围查找
这么说起来,其实二叉搜索树来做索引好像也是个不错的选择,其实不然
首先我们要明确的一点是,这棵树是存在于磁盘中,每次我们都要从磁盘中读取出相应的结点,然而二叉搜索树的结点在文件中是随机存放的,所以可能读取一个结点就需要一个磁盘IO,恰恰二叉搜索树都会比较高,如一棵一百万个元素的平衡二叉树就有十几层高度了,也就是大部分情况下检索一次数据就需要十几次磁盘IO,这个代价太高了,所以一般二叉搜索树也不会被用来作索引。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块,也就是说,尽可能的让树的高度变低,也就是用多路搜索树,而InnoDB存储引擎使用的就是这种多路搜索树,也就是我们常说的B+树。
InnoDB的索引结构
InnoDB是MySQL中最常用的搜索引擎,它的索引底层结构用的就是B+树,所有的数据都是存储在B+树中的。每一个索引在InnoDB中对应一颗B+树。
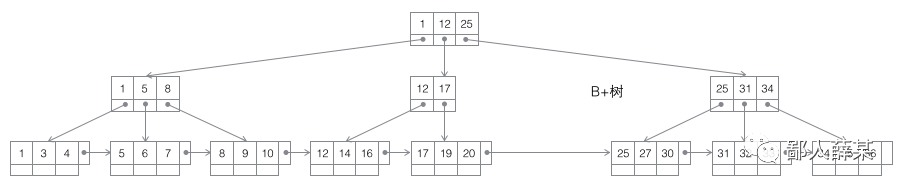
B+树的特点是:
所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。 所有的中间结点元素都同时存在于子结点,在子结点元素中是最大(或最小)元素。
这种结构有两个优点:
可以使得单一结点存储更多的元素,除了叶子结点,其他的结点只是包含了键,没有保存值,这样的话,树的高度就能有效降低,从而减少查询的IO次数; 同时,因为叶子结点包含了下个叶子结点的指针,所以范围查询的时候如果搜索到第一个叶子结点的话,就能根据指针指向查询后面的数据,不用再从根结点遍历了。这也是为什么很多大神建议表的主键设计成自增长的好,因为这样范围查询能提高效率
索引的分类
按照结构来分的话,数据库索引可以分为聚簇索引和非聚簇索引。
聚簇索引,也叫聚集索引,就是按照每张表的主键构造一颗B+树,同时叶子结点中存放的就是整张表的行记录数据,简单点说,就是我们常说的主键索引。在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。
非聚簇索引,也叫非聚集索引,二级索引。这种索引是将数据与索引分开存储,索引结构的叶子结点指向了数据对应的位置。
聚簇索引
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,我们先假设一张用户表,这张表包含了id,name,company几个字段,
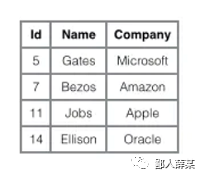
用图片表示InnoDB的索引结构大概是这样:
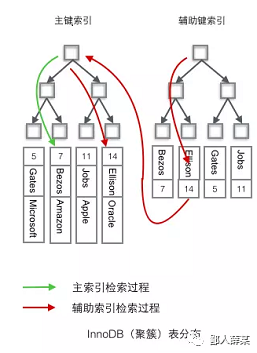
从图中就可以看出,如果我们使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶结点,之后获得行数据。
若对Name列进行条件搜索,则需要两个步骤:
第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。
第二步使用主键在主索引B+树中再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据**。(**重点在于通过其他键需要建立辅助索引)
这是聚簇索引的结构,而非聚簇索引的代表是MyISM,这也是MySQL中常见的搜索引擎。
非聚簇索引
非聚簇索引的两棵B+树看上去没什么不同,结点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。索引本身不存储数据,数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据。
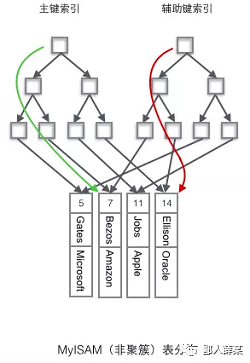
看上去,好像非聚簇索引的效率要高于聚簇索引,因为不用查两次B+树,那为什么最常用的InnoDB引擎还要用这种存储结构呢?它本身的优势在哪?
1、聚簇索引中,由于行数据和叶子结点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,所以,如果按照主键Id来组织数据,获得数据更快。
2、辅助索引使用主键作为"指针"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作**,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。**也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
3、聚簇索引适合用在排序、范围查询,非聚簇索引不适合。
覆盖索引
说到辅助索引,我们还可以延伸出另一种特别的索引,就是覆盖索引。
上面说了,聚簇索引中访问数据要经过二次查找,就是先找到辅助键的叶子结点,得到主键对应的结点后再用主键索引查询数据,这样还是比较慢的,其实,如果我们所需的字段第一次查找就能获取到的话,就不用再二次查找主键了,也就是不用“回表”。
就还是上面那张表有三个字段id,name,company的表来说,我给name加了索引,在查询数据的时候,我就这么写语句:
select name from user where name like '张%';
因为我们的语句走了索引,并且返回的字段在叶子结点都存在,查询的时候就不会回表了,多好啊~~
所以,如果所需的字段刚好是索引列的话,尽量用这种查询方式,不要用select *这种语句。
索引种类
前面说的索引分类是按照结构来分,如果按作用范围来分的话,索引还可以分为以下几种:
普通索引:这是最基本的索引类型,没唯一性之类的限制。
CREATE INDEX INDEX_NAME ON TABLE_NAME(PROPERTY_NAME)
唯一性索引:和普通索引基本相同,但所有的索引列只能出现一次,保持唯一性。
CREATE UNIQUE INDEX INDEX_NAME ON TABLE_NAME(PROPERTY_NAME)
主键:跟唯一索引一样,不能有重复的列,但本质上,主键不能算是索引,而是一种约束,必须指定为"PRIMARY KEY"。它跟唯一索引的区别在于:
主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。 唯一性索引列允许空值,而主键列不允许为空值。 主键列在创建时,已经默认为空值 + 唯一索引了。 主键可以被其他表引用为外键,而唯一索引不能。 一个表最多只能创建一个主键,但可以创建多个唯一索引。 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
全文索引:全文索引的索引类型为FULLTEXT,可以在VARCHAR或者TEXT类型的列上创建。在MySQL5.6以前的版本,只有 MyISAM 存储引擎支持全文索引,5.6及之后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引。
CREATE FULLTEXT INDEX INDEX_NAME ON TABLE_NAME(PROPERTY_NAME)
联合索引:联合索引其实不是一种索引分类,就是包含多个字段的普通索引,比如有个联合索引为index(a,b),查找的时候可以用 a and b 作为条件,
最左匹配原则
联合索引中,最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
就像上面说的index(a,b)或者是a单独作为查询条件都会走索引,但是如果是单独用 b 做查询条件就不会走索引了
或者是如果建立(a,b,c,d)顺序的索引的话,用a = 1 and b = 2 and c > 3 and d = 4这样的语句搜索,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
索引什么时候会失效
1、索引列用函数或表达式,比如这种
select * from test where num + 1 = 5
MySQL无法解析这种方程,这完全是用户的行为,应该把索引列当成独立的列,这样索引才会生效。
2、存在NULL值条件
select * from user where user_id is not null;
我们在设计数据库表时,应该尽力避免NULL值出现,如果数据有为空的情况可以给一个默认值,比如数值型的可以给0、-1,字符类型的可以给空字符串。
3、用or表达式作为条件,有一个列没有索引,那么其它列的索引将不起作用
select * from user where user_id = 700 or user_name = "老薛";
像这种,如果user_id有加索引,而user_name没有的话,那么执行的时候user_id的索引也是失效的,这也是为什么开发中尽量少用or的原因,除非是两个字段都加了索引。
4、列与列对比,某个表中,有两列(id和c_id)都建了单独索引,下面这种查询条件不会走索引
select * from test where id = c_id;
5、数据类型的转换。如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
create index `idx_user_name` ON user(user_name)
select * from user where user_name = 123;
像上面这种,虽然给user_name建立了索引,但查询的时候条件没有当成字符串,这样的话就不会走索引。
6、NOT条件
当查询条件为非时,索引定位就困难了,执行计划此时可能更倾向于全表扫描,这类的查询条件有:<>、NOT、in、not exists
select * from user where user_id<>500;
select * from user where user_id in (1,2,3,4,5);
select * from user where user_id not in (6,7,8,9,0);
select * from user where user_id exists (select 1 from user_record where user_record.user_id = user.user_id);
7、like查询是以%开头
当使用模糊搜索时,尽量采用后置的通配符,例如要查姓张的人,可以用user_name like ‘张%’,这样走索引时,可以从前面开始匹配索引列,但如果是这样user_name like ‘%张’,那么就会走全表扫描的方式
8、多列索引,遵循最左匹配原则,这个上面说了
什么时候该用索引
前面说了,索引虽然能加快查询速度,但本身也会占用空间,所以,索引的创建并不是越多越好,为了使索引能有效应用,我们要把索引留给最有用的查询字段,一般来说,应该在这些字段上创建索引:
主键字段,这不用多说了吧; 经常需要搜索的列,比如where条件经常用到的字段; 其他表的外键字段,作为连接表的条件字段,可以有效加快连表查询速度; 查询中作为排序、统计或者是分组的字段;
同样,对于有些字段不应该创建索引,这些列包括
频繁更新的字段不适合创建索引,因为每次更新不单单是更新记录,还会更新索引,保存索引文件 where条件里用不到的字段,不创建索引; 表记录太少,不需要创建索引; 对于那些定义为text,image类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引; 数据重复且分布平均的字段,因此为经常查询的和经常排序的字段建立索引。注意某些数据包含大量重复数据,这种字段建立索引就没有太大的效果,例如性别字段,只有男女,不适合建立索引。
explain关键字
explain是MySQL的关键字,通过该关键字我们可以查看搜索语句的性能。

这是查询表的数量,一共有三千多万行,这么多的数据,我们搜索的时候肯定要用到索引才行,至于索引是否会生效,我们也可以通过该关键字来看下,

看,搜索的条数瞬间降到了16条,走的索引是 index_user_id,证明我们的索引是生效的。
关于explain的几个重要参数,我们有必要了解一些:
id:查询的序列号
select_type:查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。
type:
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref >fulltext > ref_or_null > index_merge > unique_subquery >index_subquery > range > index > ALL
System效率最高,ALL的话已经是全表扫描了,一般来说,查询至少要达到range级别。
key:
显示MySQL实际决定使用的键。如果没有索引被选择,键是NULL。
key=primary的话,表示使用了主键;
key=null表示没用到索引。
possible_keys:
指出MySQL能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要检查语句中是不是有什么情况导致索引失效。
rows:
表示执行计划中估计扫描的行数,是个估计值。
Extra:
如果是Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。
如果是where used,就是使用上了where限制。
如果是impossible where 表示用不着where,一般就是没查出来啥。
出现using index就说明我们的索引是生效的。
总结
好了,索引的知识点就介绍到这了,最后总结一下索引的注意事项吧。
1、索引要根据表数据的使用情况来创建,不能创建太多,一般一张表不建议超过6个索引字段
2、好刀要用在刀刃上,经常用于查询,没多少重复数据,搜索行数不超过表数据量4%的字段用索引的效果比较好
3、创建联合索引要注意最左匹配原则,切记,最左边的字段是必传字段,这点我他妈就吃过大亏
4、查询语句要用explain执行计划来查看性能。
参考:
https://www.jianshu.com/p/fa8192853184 MySQL实战45讲







关注Java技术栈看更多干货
