
快过HugeCTR:用OneFlow轻松实现大型推荐系统引擎
一、简介
Wide & Deep Learning (以下简称 WDL)是解决点击率预估(CTR Prediction)问题比较重要的模型。WDL 在训练时,也面临着点击率预估领域存在的两个挑战:巨大的词表(Embedding Table),以及大量的数据吞吐。
业界比较有影响力的包含了 WDL 解决方案及评测结果的项目有 HugeCTR[1],该框架通过模型并行、三级流水线等技巧,解决了以上问题。在2020年 MLPerf [2]评测中,英伟达用 HugeCTR 实现了当时最快的 WDL 模型。
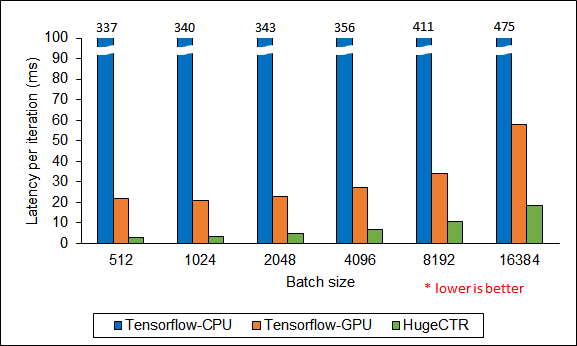
英伟达 Blog[3] 给出的数据显示,在特定的、对齐后的硬件条件下,HugeCTR 的速度是 TensorFlow-CPU 的114倍,是 TensorFlow-GPU 的7.4倍,下图的纵坐标代表每轮迭代的延迟,数值越小,意味着性能越好:
而 OneFlow-WDL 比 HugeCTR 更快,每轮迭代延迟比 HugeCTR 更少: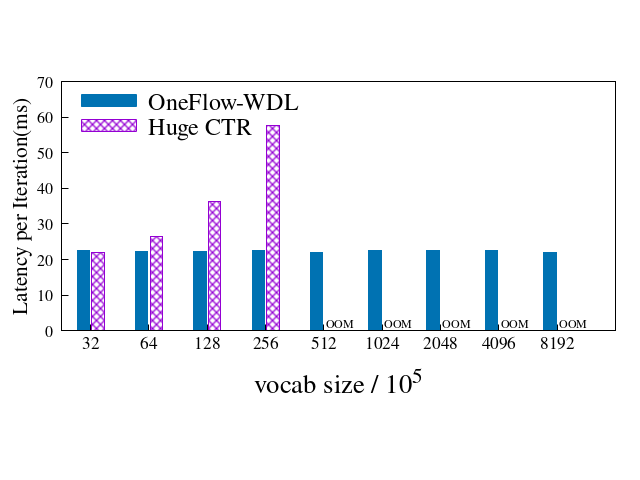 上图节取自 DLPerf[4] 中的 WDL(OneFlow-WDL vs. HugeCTR)评测报告,展示了 vocabulary size 倍增实验的结果,横坐标为实验时所取的 vocabulary size 参数大小,不断翻倍,直到超出框架的最大负荷(OOM 为 Out of Memory 的缩写)。
上图节取自 DLPerf[4] 中的 WDL(OneFlow-WDL vs. HugeCTR)评测报告,展示了 vocabulary size 倍增实验的结果,横坐标为实验时所取的 vocabulary size 参数大小,不断翻倍,直到超出框架的最大负荷(OOM 为 Out of Memory 的缩写)。
可以看到,相同条件下的各组实验中,OneFlow 的训练速度比 HugeCTR 快。并且,随着 vocabulary size 的增大,OneFlow 的每次迭代的 latency 几乎无变化,性能无损失。
使用 OneFlow 在 32 张 V100-SXM2-16GB 组成的集群上训练 WDL,可以支持8亿(819200000)大小的词表。
原始的日志数据、更详细的图表说明,可以参考最近公布的 DLPerf [5]关于 OneFlow 与 HugeCTR 实现相同结构 WDL 的性能测试报告。
OneFlow 作为一款通用的深度学习框架,所实现的 OneFlow-WDL 模型性能却超越了专为 CTR Prediction 问题设计的 HugeCTR 框架,内部的技术原理有哪些呢?本文将详细揭秘 OneFlow-WDL 实现的技术细节,并将不同的场景中 OneFlow-WDL 的多种分布式实现方案做详细的横向对比与分析,以方便读者根据自身需求与应用场景,选择最适合的方案。
熟悉 WDL 模型的读者,可以直接跳到第三节“如何在 OneFlow 中实现分布式 WDL” 开始阅读。
二、WDL、大词表与 OneFlow
OneFlow-WDL 为什么这么快,OneFlow 作为分布式最易用的深度学习框架,在实现 OneFlow-WDL 的过程中有哪些过人之处?这个问题难以简单直接地回答,为此我们准备了此节内容,将依次介绍:
CTR Prediction 是什么?WDL 是什么?它们解决了什么问题? WDL 模型在实际工程中为什么需要分布式?为什么困难? OneFlow 为什么适合解决 WDL 这样的大模型问题?
读者可以根据自身情况,略过已经了解的部分,挑选自己还不了解的部分阅读即可。
2.1 CTR Prediction 与 WDL
2.1.1 CTR Prediction 问题
CTR Prediction 问题的目标是预测用户点击率,点击率作为一种指标,可以一定程度地反映用户对所提供的内容的感兴趣程度。因此,CTR Prediction 技术广泛应用在推荐、排序搜索、在线广告等领域。互联网公司大部分的服务都或多或少与 CTR Prediction 有关系,无论是 BAT 各家的广告业务,还是美团的首页 rank、头条的 feed 流,背后都有 CTR Prediction 的身影。
下面用一个简化的广告推荐例子,来说明 CTR Prediction 所要解决的问题及其解决思路。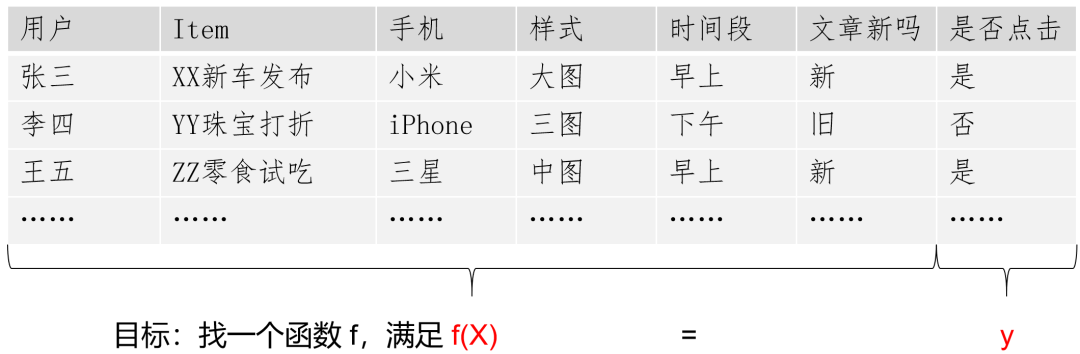
以上的表格中,Item 是将要作为广告展示给用户的内容,我们希望能够根据用户的信息预测用户是否会点击这个广告,从而达到更精确推荐的目的。
我们将用户的相关信息抽象为特征(X),点击行为作为函数的目标(y),那么问题的核心在于,如何尽可能准确地从数据中学习到 X 与 y 的关系 。这可以简化地理解为一个分类问题。其中:y 为是否点击,X 为用户的相关信息。
用来解决 CTR Prediction 问题的模型有很多种,WDL 只是其中(很重要)的一种。
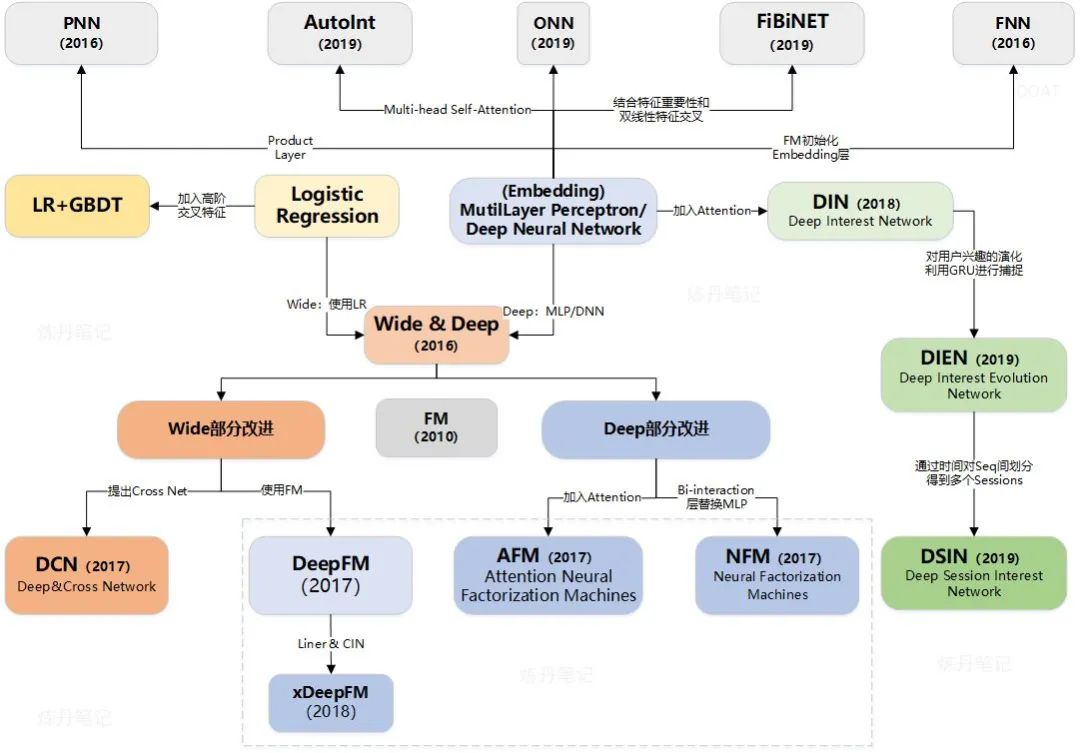
那么,WDL 为什么在 CTR Prediction 模型中如此重要呢?这主要是因为 WDL 模型的特殊历史地位决定的,可以从下图 (图来源:https://zhuanlan.zhihu.com/p/243243145)CTR Prediction 模型演化的历程中看到,WDL 起到了承上启下的作用,可以说,当今落地的 CTR Prediction 模型,都或多或少有 WDL 的影子,它们要么是通过改进 WDL 的 Wide 部分得到,要么是改进 WDL 的 Deep 部分得到,要么是 WDL 的前身。
2.1.2 WDL(Wide & Deep Learning)
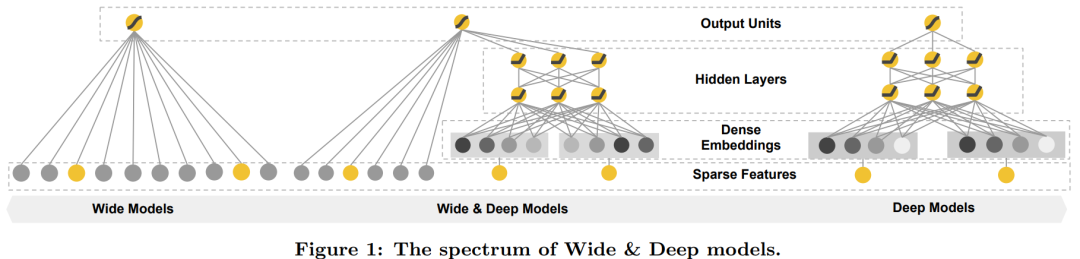
上图展示了 Google 团队 WDL论文[6]中提出的模型的结构,WDL 模型分为 Wide 和 Deep 两部分:
单看 Wide 部分,与 Logistic Regression 模型并没有什么区别,就是一个线性模型。 Deep 部分则是先对类型特征(Categorical Features)做 Embedding,在 Embedding 后接一个由多个隐藏层组成的神经网络,用于学习特征之间的高阶交叉组合关系。
由于 Embedding 机制的引入,WDL 相比于单纯的 Wide 模型有更强的泛化能力。Google 论文中展示了一个具体的例子:
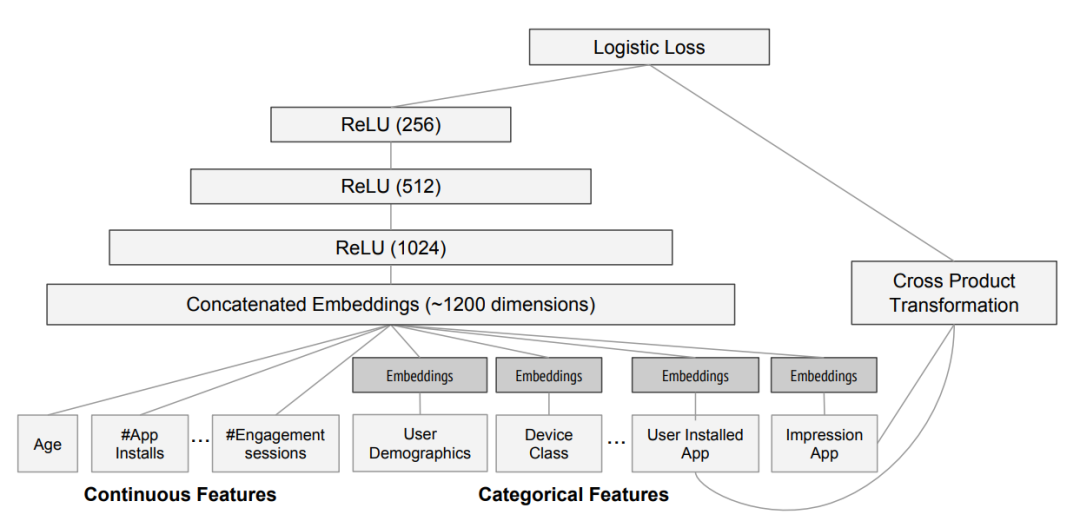
这是一个关于 APP 推荐的例子,WDL 模型的具体网络结构以及输入如下:
Wide 部分:线性模型部分通常输入稀疏的类别特征进行训练。另外,通过利用交叉特征高效的实现记忆能力,达到准确推荐的目的。比如在这个例子里,选取了两个类别特征(User Installed App 与 Impression App)做叉积变换的结果作为线性部分的输入。 Deep部分:稀疏、高维的类别特征首先通过 Embeddings 转换为低维稠密向量,然后与连续值特征拼接在一起,作为MLP的输入。 Wide & Deep联合训练:Wide 部分和 Deep 部分的输出通过加权方式合并到一起,并通过 Logistic Loss 得到最终输出。
注意其中的 Embedding 过程,通常情况下,因 Embedding 而引入的巨大词表(Embedding Table),是 WDL 必须使用分布式的最主要原因。
2.2 词表为什么这么大
本节将介绍:
WDL 中为什么会有巨大的 Embedding Table? 为什么实现模型并行的分布式 WDL 是必需的也是困难的?
2.2.1 从 One-Hot 到 Embedding
WDL 需要 Embeding,虽然 Embedding 已经是 CTR 系统的基本操作,但是名气最大的可能还是词嵌入(word embedding),它也更容易解释。我们先简单介绍 One-Hot 与词嵌入,在下一节将看到,它与 WDL 中采用的 Embedding 没有本质区别。众所周知,One-Hot 编码是最原始的用来表示字、词的方式。假如能使用的字只有五个:“牛、年、运、气、旺”,那么它们的 One-Hot 编码可以是:
牛: [1, 0, 0, 0, 0]
年: [0, 1, 0, 0, 0]
运: [0, 0, 1, 0, 0]
气: [0, 0, 0, 1, 0]
旺: [0, 0, 0, 0, 1]
“运气”这个词,采用以上 One-Hot 编码,就是:
这太稀疏了,在工程实现中有诸多弊端,于是我们可以准备一个矩阵,利用矩阵乘法: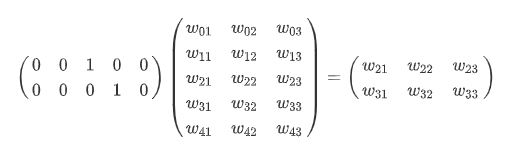
将2个1×5的稀疏向量,“压缩到”到 2个1×3 的稠密向量中(词向量)。
以上包含有 的矩阵,就称为词表(Embedding Table),且由于 One-Hot 编码的特殊性,One-Hot 向量与词表的矩阵乘法,其实相当于是一次“查表”的过程,如上例中,其实就是根据“1”在 One-Hot 向量中的位置(第2列、第3列),从词表中取出对应的向量(第2行、第3行)。
在实际工程中,并不会真正进行 One-Hot 编码(浪费内存),而是将 One-Hot 编码中 “1”的位置作为编号(通常称为 sparse ID),利用 gather[7] 操作,从词表中取出词向量,等价于矩阵乘法。
如,上例的矩阵乘法,在 OneFlow 中用代码表示,则为:
embedding = flow.gather(embedding_table, index, axis=0) # index: [2, 3]
2.2.2 WDL 中的 Embedding
实际场景中,图像识别、语音识别等问题的输入常常具有连续、稠密且空间/时间有良好局部相关性的特点,CTR Prediction 问题则不同,大多数输入都是稀疏、离散、高维的类别特征(Categorical Features),因此通常需要通过 Embedding Table 将这些稀疏的类别特征转换为低维稠密向量。
我们已经知道,对于 Word Embedding,有多少个字(词),Embedding Table 就有多少行;那么,Wide & Deep 中的 Embedding Table 的行数,又是由什么决定的呢?它其实是所有 Categorical Features 做 One-Hot 编码后的维度总和。
我们以找到以下表格对应的词表的大小为例:
| 手机 | 样式 | 时间段 | 文章新吗 |
|---|---|---|---|
| 小米 | 大图 | 早上 | 新 |
| iPhone | 三图 | 下午 | 旧 |
| 三星 | 中图 | 早上 | 新 |
先对各个类别特征分别做 One-Hot 编码:
| 手机 | 样式 | 时间段 | 文章新吗 |
|---|---|---|---|
| (1, 0, 0) | (1, 0, 0) | (1, 0) | (1, 0) |
| (0, 1, 0) | (0, 1, 0) | (0, 1) | (0, 1) |
| (0, 0, 1) | (0, 0, 1) | (1, 0) | (1, 0) |
理论上,每个类别特征的 One-Hot 编码都应该有对应的 Embeding Table:
| 手机 | 样式 | 时间段 | 文章新吗 | |
|---|---|---|---|---|
| (1, 0, 0) | (1, 0, 0) | (1, 0) | (1, 0) | |
| (0, 1, 0) | (0, 1, 0) | (0, 1) | (0, 1) | |
| (0, 0, 1) | (0, 0, 1) | (1, 0) | (1, 0) | |
| 词表行数 | 3 | 3 | 2 | 2 |
工程实践中,往往将各个特征类别的词表拼起来成为一个大词表,并且,像前文介绍的那样,用 gather 方法可以代替 One-Hot 向量与矩阵的乘法,因此实际操作中,并不会真正对类别特征的值进行 One-Hot 编码,仅仅赋予类别特征 sparse ID 作为查表索引即可:

对于我们以上有3个样本、4个类别特征的数据,词表共需要9行。
在工业实际场景中,总的类别种类往往达到百万、千万甚至上亿级别,因此 Embedding Table 非常巨大(GBs~TBs),将 Embedding Table 存放在一个单独的 GPU 上通常是做不到的。
因此需要实现分布式 WDL。更具体地说,是要实现模型并行的分布式 WDL。
数据并行:将训练样本分发到各个计算设备上,而每个设备上保存完整的模型。
模型并行:将模型参数分配到不同计算设备上,各设备只有部分模型。
目前已有的深度学习框架,大多数提供了对数据并行的原生支持,但是对模型并行支持的还不完善。如果用户想要将模型参数分配到不同设备上,往往会遇到需要人工指定模型切分方式、手工编写数据通信逻辑代码等问题。
以 WDL 的词表切分为例,既可以按照第0维度切分,也可以按第1维度切分,分发到各个 GPU 设备上,但是它们的效率是等价的吗?编写模型算法时如何表达切分的不同方式呢?大多数深度学习框架都没有给出优雅成熟的解决方案,而是对算法工程师提出了较高的要求,需要他们为各个部分手动进行运算设备定制。
此外,WDL 的模型训练中,与计算量相比,数据 I/O 吞吐量非常大,如果不协调好 I/O 与 GPU 计算的关系,很容易使得 I/O 成为整个系统的瓶颈。
综合以上两点原因,在很长一段时间内,各深度学习框架都未能提出一个很好的利用 GPU 算力进行 WDL 模型训练的解决方案,最终表现为:
仅用数据并行,容易 out of memory,无法支持更大的模型。 低效实现的模型并行容易出现 I/O 瓶颈问题,不能很好利用 GPU 算力,导致 GPU 版本解决方案与 CPU 方案比较提速不明显。
2.3 OneFlow 为什么这么快
OneFlow 在分布式上的优势,主要体现在:
顶层设计中将数据加载、数据搬运等一起纳入了优化范畴,一劳永逸地解决了数据加载瓶颈、流水并行效率等问题。 对算法工程师友好,提供的 Placement 机制与 SBP 的概念,能轻松地解决 WDL 这类大模型的复杂并行问题。比如,后文中将要介绍三种并行方案,并均给出了实现,我们会发现 OneFlow 中切换三种方案只涉及改动极少量的代码,完全不需要改模型结构。目前这在其它框架中还难以做到。
总结而言,OneFlow 的“快”是:让模型训练更快;让算法工程师编程更快。
2.3.1 让模型训练更快
对于顶层设计上的优势及框架内部通用优化技术,可以参考已经发布的文章《深度解读:让你掌握OneFlow系统设计》上篇、中篇、下篇与《深度学习框架如何进行性能优化?》,在此不再重复。
2.3.2 让算法工程师编程更快
OneFlow 独创的 SBP 概念,使得算法工程师可以专注于逻辑,将并行时算子的复杂 placement 问题交给 OneFlow 框架。理解 OneFlow 如何搭建分布式 WDL,需要先了解 SBP 与 SBP Signature 的概念,我们在此做简单介绍,已经了解的读者,可以直接跳过本节。
(1)SBP:SBP 是 OneFlow 独有的概念,它来自 Split, Broadcast, Partial-value 三个首字母的组合。SBP 代表着1个逻辑上的Tensor 与多个物理上的 Tensor 的映射关系。
Split:表示物理上的多个 Tensor 是由逻辑上的 Tensor 进行切分后得到的。Split 会包含一个参数 Axis,表示被切分的维度。如果把所有物理上的 Tensor 按照 Split 的维度进行拼接,就能还原出逻辑上的 Tensor。 Broadcast:表示物理上的多个 Tensor 是逻辑上 Tensor 的复制,完全相同。 Partial-value:表示物理上的多个 Tensor 跟逻辑上的 Tensor 的形状相同,但每个对应位置上元素的值是逻辑 Tensor 对应位置元素的值的一部分。如果把所有物理上的 Tensor 对应位置进行 element-wise 操作,即可还出原逻辑上的Tensor。常见的有 PartialSum、PartialMax、PartialMin 等。
以下是关于 SBP 的简单示例,以逻辑上的 2×2 的张量为例,分别展示了 Split(0)、Split(1)、Broadcast、Partialsum 几种情况下,逻辑张量(下图左侧)与物理张量(下图右侧)的对应关系。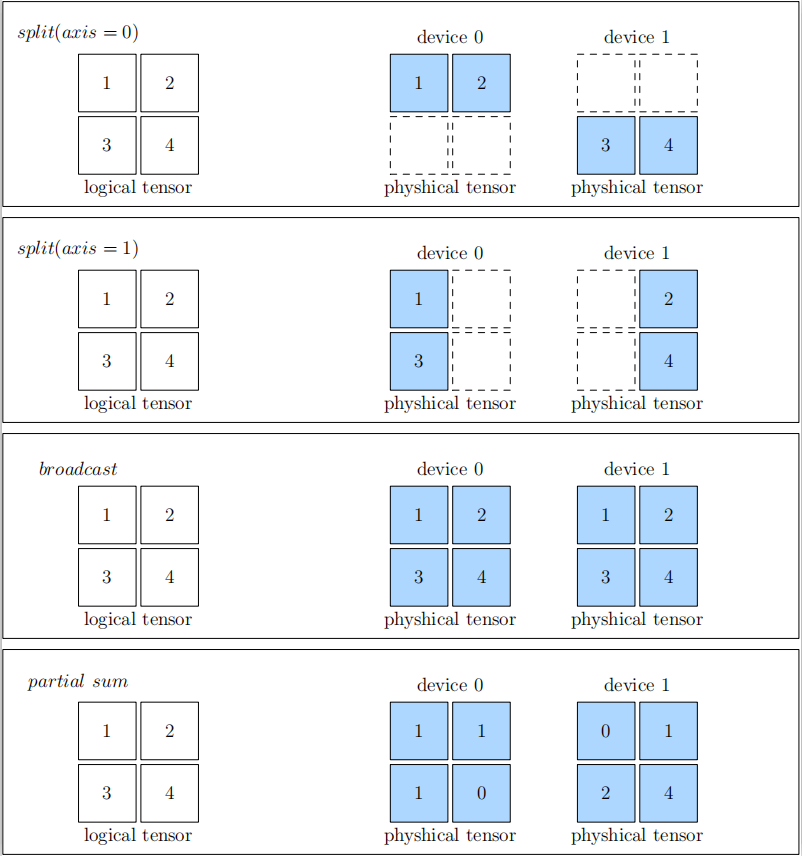
(2)SBP Signature:对于一个孤立的数据,其 SBP 属性可以随意设置,但是对于Op,它的输入、输出的 SBP,应该符合逻辑上 Op 的运算法则。让我们以矩阵乘法为例,看看在有2个设备的分布式系统中,矩阵乘法的输入、输出的 SBP 要如何组合才合法。
逻辑上,一个性质为 (m, k) 的矩阵 A 与形状为 (k, n) 的矩阵 W 相乘得到 Y,Y的形状必然为 (m, n),表示如下:
A * W = Y
(m, k) (k, n) (m, n)
依据矩阵乘法的规律,我们可以将矩阵 A 按第0维进行切分,切分为形状分别为 (m0, k)、(m1, k) 的两个矩阵:A0 和 A1,然后分布到2个设备上分别计算:
device 0:
A0 * W = Y0
(m0, k) (k, n) (m0, n)
device 1:
A1 * W = Y1
(m1, k) (k, n) (m1, n)
我们容易得到物理设备上的 A0、A1 与逻辑上的 A 的关系,以及 Y0、Y1 与逻辑上的 Y 的关系:
A == A0 + A1
(m, k) (m0, k) (m1, k)
Y == Y0 + y1
(m, n) (m0, n) (m1, n)
注意,以上的“+”表示拼接(concat),而不是 element-wise 加法。可见,按照以上的方式,将逻辑上的数据分发到各个物理设备上,是能够完成运算,并且最终得到逻辑上的正确结果的。以上的过程,若使用 SBP 来描述,会变得异常简单:
A 矩阵 为 S(0),W 矩阵为 B,结果 Y 为 S(0)。
对于某个 Op,其输入输出的 一个特定的、合法的 SBP 属性组合,称为这个 Op 的一个 SBP Signature。SBP Signature 描绘了 Op 如何看待逻辑视角的输入输出与物理视角的映射关系。
一个 Op 的 SBP Signature 往往可以有多个,对于上例的矩阵乘法,有以下 SBP Signature:
| A | W | Y |
|---|---|---|
| S(0) | B | S(0) |
| B | S(1) | S(1) |
| S(1) | S(0) | PartialSum |
| PartialSum | B | PartialSum |
| B | PartialSum | PartialSum |
OneFlow 的算子作者,在开发算子的过程中,会注册好相关算子的 SBP Signature,使得 OneFlow 用户使用分布式时,把精力专注于算子逻辑上,逻辑上像使用一台“超级计算机”那样操作整个集群。
三、如何在 OneFlow 中实现分布式 WDL
上一小节介绍了 WDL 模型结构以及 OneFlow 的 SBP 与 SBP Signature 的概念,下面我们就来详细揭秘,如何用 OneFlow 的“SBP”语言,轻松实现分布式 WDL。
3.1 OneFLow-WDL 网络结构

在 OneFlow-Benchmark[8] 仓库中,给出了对标 HugeCTR[9] 实现的 OneFlow-WDL[10],模型的网络结构如上图所示:
Wide 部分的输入是
wide_sparse_fields,Deep 部分的输入是deep_sparse_fields和dense_fields。其中wide_sparse_fields和deep_sparse_fields是类别特征的 sparse ID,dense_fields是稠密的连续值特征。具体的数据处理过程见:OneFlow-WDL 的 Criteo 数据集预处理[11]。Wide 部分是 Logistic Regression 线性模型,图中的
wide_embedding_table是一个形状为(wide_vocab_size, 1) 的向量, gather + reduce_sum 的操作组合起来实际上等价于 Logistic Regression 中的全连接层。Deep 部分的 gather 操作,就如我们之前介绍,实现了 Embedding 操作。
wide_sparse_fields就是 sparse ID,经过对deep_embedding_table查表,转换为低维稠密的deep_embedding,然后通过 concat 操作与dense_fields组成一个稠密的实值特征deep_features作为后续深度神经网络的输入。
3.2 三种并行方案
前面已经介绍实际场景中 WDL 需要巨大的 Embedding Table,通常单一计算设备无法放下完整的 Embedding Table,需要将 Embedding Table 切分到不同的设备上,即通过模型并行实现 WDL 的训练。
借助 SBP 概念,可以很容易描述和实现分布式的并行方案,我们先对照 WDL 的网络结构图总结并行时的约束:
wide_embedding_table是形状为 (wide_vocab_size, 1) 的向量,所以只能 Split(0) 切分;deep_embedding_table可以 Split(0) 切分,也可以 Split(1) 切分;sparse ID 可以选择通过 Broadcast 的方式聚合到各个计算设备,也可以保持 Split(0) 切分(OneFlow 在默认情况下会为数据做 Split(0) 切分,即数据并行)。
在遵循以上约束的前提下,我们共设计了三种方案,分别是:
| 并行方案 | sparse ID (wide_sparse_fields deep_sparse_fields) | wide_embedding_table | deep_embedding_table |
|---|---|---|---|
| 方案一 | Broadcast | Split(0) | Split(1) |
| 方案二 | Broadcast | Split(0) | Split(0) |
| 方案三 | Split(0) | Split(0) | Split(0) |
通过下文的具体分析可以发现,对 deep_embedding_table 进行 Split(1) 切分, 通信量比 Split(0) 切分少,方案一是通常情况下的最优选择,也是 OneFlow 与 HugeCTR 对比测试时所选择的方案。
但是,如果实际场景中,deep_embedding_table 的第1维无法被计算设备的个数整除时,方案一就失效了,若不愿意用其它手段绕过(如修改第1维的大小或使用非均衡的切分),则只能使用 Split(0) 切分,所以我们还设计了方案二。
方案三是对方案二的一个补充,即改变了 sparse ID 的分发方式,使用 Split(0) 代替 Broadcast,虽然 sparse ID 进行 Split(0) 切分会引入额外的操作,但是通过下文的具体的分析可以发现,在某些情况下,方案三节省的通信操作开销会多于 Split(0) 切分引入的额外操作开销,那样,方案三会比方案二更有优势。
下面分别对这三种方案进行详细解释和分析。
3.2.1 方案一
| 并行方案 | sparse ID (wide_sparse_fields deep_sparse_fields) | wide_embedding_table | deep_embedding_table |
|---|---|---|---|
| 方案一 | Broadcast | Split(0) | Split(1) |
为方便读者理解,我们在 WDL 模型的网络结构图中,标出了 OneFlow 在逻辑视角下插入 SBP 属性转换操作(parallel_cast op)的位置,以及所有操作前后数据的 SBP 属性,如下图所示:
下面逐一介绍各个 parallel_cast op 的作用。
(1) sparse ID 广播
方案一中 wide_sparse_fields 和 deep_sparse_fields 的 SBP 属性是 Broadcast,需要先将完整的数据从CPU 拷贝到各个 GPU 设备上,存在以下两种选择:
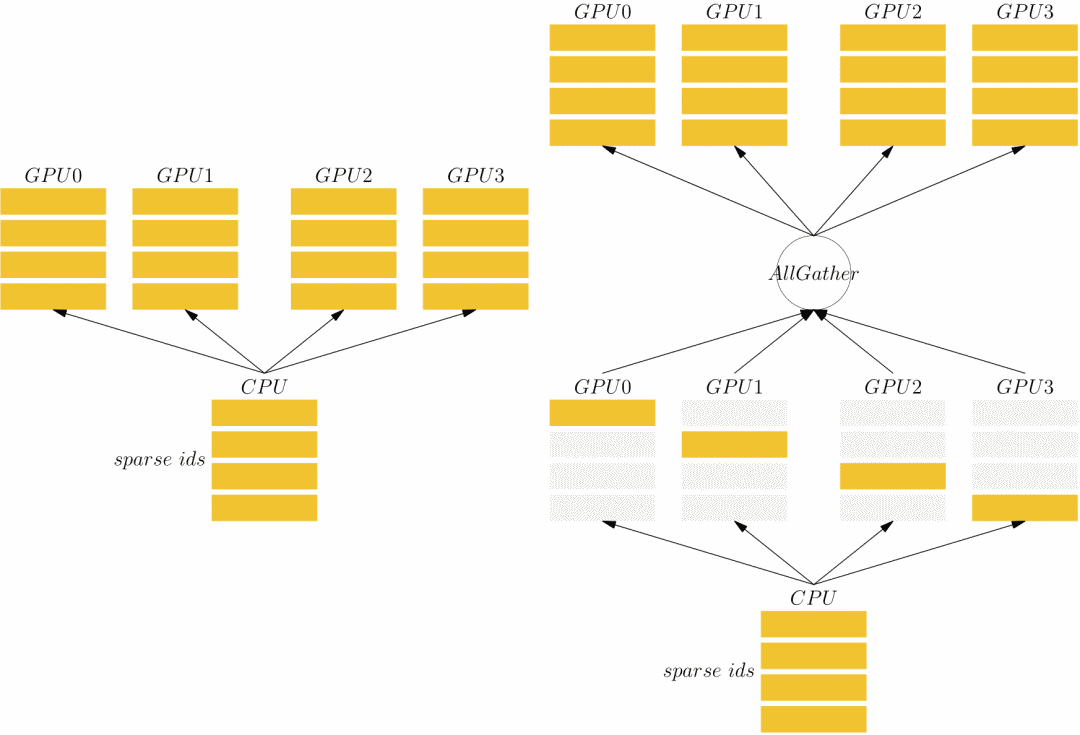
1)由 CPU 逐个将完整数据拷贝到各个 GPU 设备上,如以上左图所示。2)先将一部分数据块从 CPU 拷贝到 GPU 上,然后在GPU上执行 AllGather 操作,如上图右侧所示。
假设 GPU 数为 P,完整数据块大小为 D,上述两种方法通信量均为 P*D,但由于通常情况下,GPU 之间的带宽(尤其对于有 NVLink 的设备)大于 CPU 到 GPU 的带宽,GPU 之间执行 AllGather 操作很快,因此在实际实现中,我们建议采用第二种方法。
sparse ID 广播的实现代码:
# 将decoder产生的数据分块从CPU拷贝到各个GPU上
labels, dense_fields, wide_sparse_fields, deep_sparse_field = flow.identity_n(
[labels, dense_fields, wide_sparse_fields, deep_sparse_fields]
)
# 将wide_sparse_fields的SBP属性转换为Broadcast
wide_sparse_fields = flow.parallel_cast(
wide_sparse_fields, distribute=flow.distribute.broadcast()
)
# 将deep_sparse_fields的SBP属性转换为Broadcast
deep_sparse_fields = flow.parallel_cast(
deep_sparse_fields, distribute=flow.distribute.broadcast()
)
代码说明:首先,因为OneFlow 默认的并行方式是数据并行, oneflow.identity_n 的作用是将 CPU 产生的数据分块拷贝到各个 GPU上,每个 GPU 设备上的数据的 SBP 属性为 Split(0)。
其次,通过调用 flow.parallel_cast ,将 wide_sparse_fields 和 deep_sparse_fields 并行方式转换为 Broadcast,从而实现每个 GPU 设备上都拿到完整的数据。在这一步,OneFlow 内部会自动执行 AllGather 操作,完成各个 GPU 设备之间数据传输。
(2) Wide 部分
Wide 部分的 wide_embedding_talbe 的形状为(wide_vocab_size, 1),我们将其进行 Split(0) 切分,即将其按第0维均分到 P 个 GPU 设备上,每个GPU设备上有(wide_vocab_size / P, 1) 大小的模型。
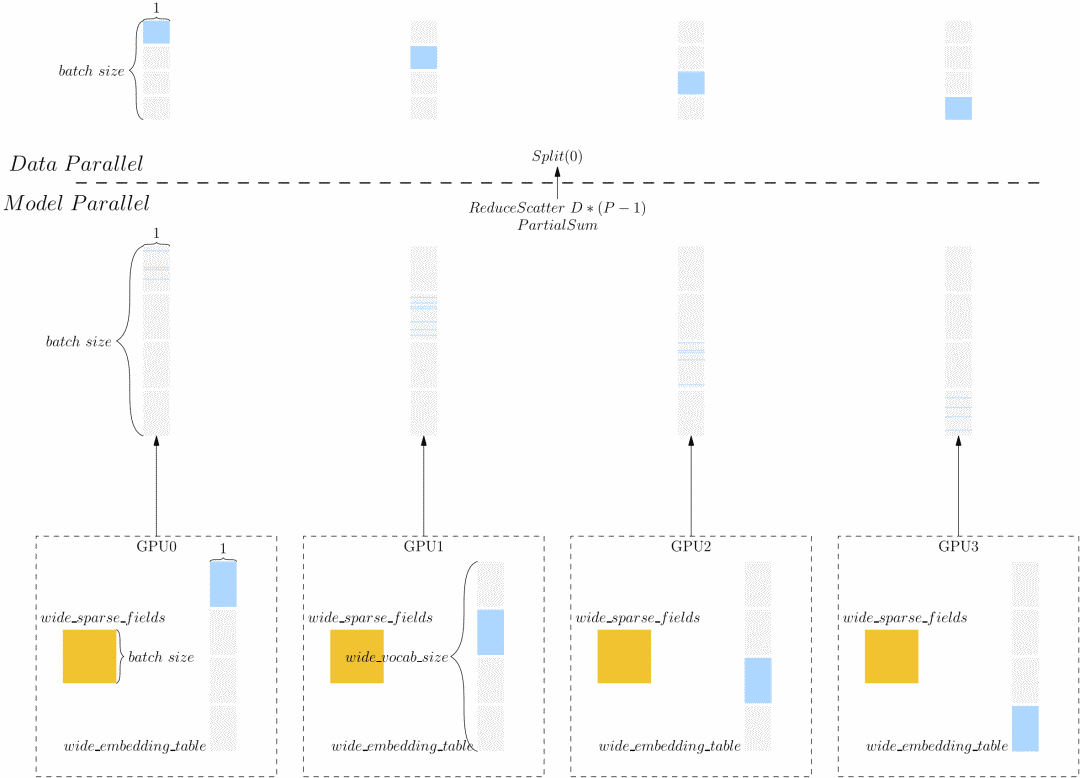
wide_sparse_fields 与部分wide_embedding_table 通过 gather 操作得到部分 wide_embedding 的示意图。注意到,各个设备只持有部分模型,计算只能得到部分结果,即该操作后得到的 wide_embedding 的 SBP 属性为 PartialSum。reduce_sum 操作不会改变数据的 SBP 属性,因此 wide_scores 的 SBP 属性仍然为 PartialSum。但是由于后续的计算是数据并行,因此需要将后续的 wide_scores 的 SBP 属性转换为 Split(0)。我们通过插入 parallel_cast op,实现 wide_scores 的 SBP 属性转换,在这一步,OneFlow 内部会自动执行 ReduceScatter 操作完成各个 GPU 设备之间数据传输。
Wide 部分的实现代码:
# 配置wide_embedding_table 的SBP属性为Split(0)
wide_embedding_table = flow.get_variable(
name='wide_embedding',
shape=(FLAGS.wide_vocab_size, 1),
distribute=flow.distribute.split(0),
)
# gather + reduce_sum的操作实现Logistic Regression线性模型
# gather: Split(0) + Broadcast -> PartialSum
wide_embedding = flow.gather(
params=wide_embedding_table, indices=wide_sparse_fields
)
#reshepe: PartialSum -> PartialSum
wide_embedding = flow.reshape(
wide_embedding, shape=(-1, wide_embedding.shape[-1] * wide_embedding.shape[-2])
)
#reduce_sum: PartialSum -> PartialSum
wide_scores = flow.math.reduce_sum(
wide_embedding, axis=[1], keepdims=True
)
# 将wide_scores的SBP属性转换为Split(0)
wide_scores = flow.parallel_cast(
wide_scores, distribute=flow.distribute.split(0),
gradient_distribute=flow.distribute.broadcast()
)
代码说明:首先,通过指定 flow.get_variable 的 distribute 参数,将 wide_embedding_table 的 SBP 属性设置为 Split(0),这样每个 GPU 设备上的模型是逻辑视角上的第0维切分。
接下来, flow.gather 操作根据本设备上的 wide_embedding_table 及 wide_sparse_fields 获得 wide_embedding,OneFlow 可以自动推导出 flow.gather 的返回结果(wide_embedding)的 SBP 属性为 PartialSum。此外, flow.reshape 和 flow.math.reduce_sum 均支持 PartialSum -> PartialSum 的数据处理,OneFlow 可以自动推导出wide_scores的SBP属性保持为PartialSum。
最后,为了支持后续的数据并行,因此我们通过插入parallel_cast,将 wide_scores 转变为 Split(0)。
Wide 部分的通信量分析:假设卡数为 P,传输的数据块大小 D 为 batch_size * 1,那么每次迭代训练需要的通信量由以下两部分组成:
前向计算时,前向数据由 PartialSum 切分变成 Split(0) 切分,执行 ReduceScatter 操作,通信量为: D * (P - 1)。反向计算时,梯度由 Split(0) 切分转换为 Broadcast,执行 AllGather 操作,通信量为: D * (P - 1)。
综合以上两部分,总通信量为 2 * D * (P - 1) = 2 * batch_size * (P - 1)。
(3) Deep 部分
Deep 部分 deep_embedding_table 的形状为 (deep_vocab_size, deep_embedding_vec_size),本方案中,将 deep_embedding_table 按照第1维切分,每个GPU设备上的模型大小为 (deep_vocab_size, deep_embedding_vec_size / P) ,其SBP 属性为 Split(1)。
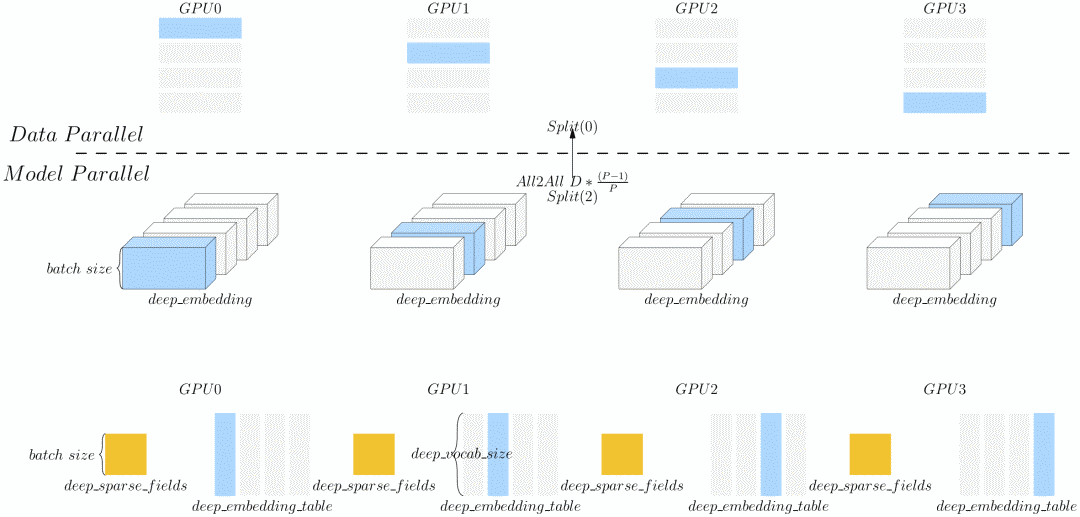
上图显示了在 4 个计算设备上,各个设备上的 deep_sparse_fields 与部分 deep_embedding_table 通过 gather 操作得到部分deep_embedding的示意图。注意到,由于deep_embedding_table是 Split(1),该操作后得到的deep_embedding的 SBP 属性为 Split(2)。
Deep 部分的实现代码:
# 配置deep_embedding_table的SBP属性为Split(1)
deep_embedding_table = flow.get_variable(
name='deep_embedding',
shape=(FLAGS.deep_vocab_size, deep_embedding_vec_size),
distribute=flow.distribute.split(1),
)
# deep部分的embedding操作
# gather: Split(1) + Broadcast -> Split(2)
deep_embedding = flow.gather(
params=deep_embedding_table, indices=deep_sparse_fields
)
# 将deep_embedding的SBP属性转换为Split(0)
deep_embedding = flow.parallel_cast(
deep_embedding, distribute=flow.distribute.split(0), gradient_distribute=flow.distribute.split(2)
)
代码说明:首先,通过指定 flow.get_variable 的 distribute 参数为 flow.distribute.split(1) 将 deep_embedding_table 的属性设置为 Split(1),这样,逻辑视角上的模型按第1维切分至每个 GPU 设备。
接下来, deep_embedding_table 与 deep_sparse_fields通过 flow.gather操作,生成deep_embedding。deep_embedding_table 与 deep_sparse_fields 的 SBP 属性分别为 Split(1) 和 Broadcast,OneFlow 会自动推导出其结果 deep_embedding 的 SBP 为 Split(2)。
最后,为了支持后续的数据并行,通过调用 flow.parallel_cast 将将 deep_embedding 的 SBP 属性由 Split(2) 转为 Split(0)。在这一步,OneFlow 会自动将各个 GPU 设备上原本按照 Split(2) 切分的数据,转为按照 Split(0) 切分并分发,实现模型并行到数据并行的转换。
Deep 部分的通信量分析:假设 GPU 设备数为 P,此时传输的数据块大小 D = batch_size * num_deep_sparse_fields * deep_embedding_vec_size,每次迭代训练的通信量由以下两部分组成:
前向计算时,前向数据由 Split(2)切分变成 Split(0) 切分,执行 All2All 操作,其通信量为: D * (P - 1) / P。反向计算时,梯度由 Split(0) 切分变成 Split(2) 切分,执行 All2All 操作,其通信量为: D * (P - 1) / P。
综合以上两部分,总通信量为2 * D * (P - 1) / P = 2 * deep_embedding_vec_size * batch_size * num_deep_sparse_fields * (P - 1) / P。
3.2.2 方案二
| 并行方案 | sparse ID (wide_sparse_fields deep_sparse_fields) | wide_embedding_table | deep_embedding_table |
|---|---|---|---|
| 方案二 | Broadcast | Split(0) | Split(0) |
当 deep_embedding_table 的第1维无法被计算设备的个数整除时,我们可以选择本方案,将deep_embedding_table 进行 Split(0) 切分。
在本方案中,sparse ID 广播问题与 Wide 部分的实现均与方案一相同,所以在此我们仅给出 Deep 部分的实现代码并进行通信量分析。
Deep 部分的实现代码:
# 配置deep_embedding_table的SBP属性为Split(0)
deep_embedding_table = flow.get_variable(
name='deep_embedding',
shape=(FLAGS.deep_vocab_size, deep_embedding_vec_size),
distribute=flow.distribute.split(0),
)
# deep部分的embedding操作
# gather: Split(0) + Broadcast -> PartialSum
deep_embedding = flow.gather(
params=deep_embedding_table, indices=deep_sparse_fields
)
# 将deep_embedding的SBP属性转换为Split(0)
deep_embedding = flow.parallel_cast(
deep_embedding, distribute=flow.distribute.split(0), gradient_distribute=flow.distribute.broadcast()
)
代码说明:首先,通过指定 flow.get_variable 的 distribute 参数,将 wide_embedding_table 的 SBP 属性设置为 Split(0),这样每个 GPU 设备上的模型是逻辑视角上的第0维切分。
接下来, flow.gather 操作根据本设备上的 deep_embedding_table 及 deep_sparse_fields 获得 deep_embedding,OneFlow 可以自动推导出 flow.gather 的返回结果(deep_embedding)的 SBP 属性为 PartialSum。
最后,为了支持后续的数据并行,我们通过插入parallel_cast,将 deep_embedding 转变为 Split(0)。
Deep 部分的通信量分析:在方案二中,Deep 部分也按照 Split(0) 切分,通信量分析的方法与 Wide 部分相同,通信量为:2 * D * (P-1)。
回顾前面的方案一, Deep 部分是按 Split(1) 进行切分,通信量为 2 * D * (P-1) / P ,显然,按照 Split(1) 切分通信量更少。
3.2.3 方案三
| 并行方案 | sparse ID (wide_sparse_fields deep_sparse_fields) | wide_embedding_table | deep_embedding_table |
|---|---|---|---|
| 方案三 | Split(0) | Split(0) | Split(0) |
本方案是方案二的备选方案,在 sparse ID 大量重复的极端前提下,方案三会更具有优势。
在方案二的基础上,若保持每个设备上的 sparse ID 按 Split(0) 的方式均分到各个设备上,就得到了本方案,那么每个设备上有(batch_size / P, num_sparse_fields) 大小的数据。

注意到,因为我们对 embedding_table 进行了 Split(0) 切分,所以在某个特定计算设备上进行查表操作(即 gather 操作)时,可能会出现本设备上的某个 sparse ID 对应的 embedding_table 行不在本设备上的情况,这就需要额外增加一些操作,具体描述如下。
上图展示了在计算设备 GPU0 上进行一次训练迭代的操作流程:
1.先将本设备的部分 sparse_ids 进行去重(Unique)。2.如果去重后的 sparse_ids 对应的模型在本设备上已经存在,则直接完成查表操作;否则,将 sparse_ids 发送到其对应模型所在的设备上,完成查表操作,该操作通过 OneFlow 中的 distribute_gather 完成。3.从对应设备上拉取对应的 embedding_table 行,更新到本设备(Pull Model)。4.在反向计算时,将梯度回传到 sparse_ids 对应模型所在的卡上(Push Grad)。
代码:
# wide部分:
wide_embedding_table = flow.get_variable(
name='wide_embedding',
shape=(FLAGS.wide_vocab_size, 1),
initializer=flow.random_uniform_initializer(minval=-0.05, maxval=0.05),
distribute=flow.distribute.split(0),
)
wide_embedding = flow.distribute_gather(params=wide_embedding_table, indices=wide_sparse_fields)
wide_embedding = flow.reshape(wide_embedding, shape=(-1, wide_embedding.shape[-1] * wide_embedding.shape[-2]))
wide_scores = flow.math.reduce_sum(wide_embedding, axis=[1], keepdims=True)
# deep部分:
deep_embedding_table = flow.get_variable(
name='deep_embedding',
shape=(FLAGS.deep_vocab_size, FLAGS.deep_embedding_vec_size),
initializer=flow.random_uniform_initializer(minval=-0.05, maxval=0.05),
distribute=flow.distribute.split(1),
)
deep_embedding = flow.distribute_gather(params=deep_embedding_table, indices=deep_sparse_fields)
deep_embedding = flow.reshape(deep_embedding, shape=(-1, deep_embedding.shape[-1] * deep_embedding.shape[-2]))
deep_features = flow.concat([deep_embedding, dense_fields], axis=1)
注:flow.distribute_gather 为 OneFlow 的新特性,目前(2021.2.5)还未合并到 OneFlow 仓库[12] 的主分支中,想快速尝试使用该新特性的读者,可以查看这个 PR[13]。
通信量分析:
在每次训练过程中,此方案的通信量由以下几个部分组成:
从CPU将(batch_size / P, num_sparse_fields) 大小的数据分别拷贝到每个 GPU 上,那么总通信量为: batch_size * num_sparse_fields。各个 GPU 将本卡上的 sparse id 去重后传给对应模型所在的GPU,若对应的模型属于本卡,则无需通信。最坏的情况下,需要把所有sparse id 传到其他卡,此时总通信量为: batch_size * num_sparse_fields。从对应的GPU Pull需要的模型,最坏情况下,sparse id 对应的所有模型都在其他GPU上,则每个 GPU 需要 Pull 的模型大小为 (batch_size / P , num_sparse_fields , embedding_vec_size),总通信量为: batch_size * num_sparse_fields * embedding_vec_size。将计算得到的梯度 Push 到模型所在的GPU,最坏情况下,sparse id 对应的所有模型都在其他GPU上,每个 GPU 需要 Push 的梯度大小为( batch_size / P , num_sparse_fields , embedding_vec_size),总通信量为: batch_size * num_sparse_fields * embedding_vec_size。
将以上几个部分相加,得到每次训练的总通信量为:2 * batch_size * num_sparse_fields + 2 * batch_size * num_sparse_fields * embedding_vec_size。
3.2.4 三种并行方案的比较
(1) 方案一 vs. 方案二方案一与方案二的区别在于deep部分的 deep_embedding_table 切分方式不同,导致deep部分的通信量不同:
deep_embedding_table | 通信量 | |
|---|---|---|
| 方案一 | Split(1)切分 | 2*D*(P-1)/P |
| 方案二 | Split(0)切分 | 2*D*(P-1) |
其中,
P代表设备数。 D代表deep部分传输的数据块大小, D = batch_size * num_deep_sparse_fields * deep_embedding_vec_size。
显然,deep部分按照 Split(1) 切分时通信量更少,因此建议使用 Split(1) 切分。只有当deep_embedding_table的第1维无法被计算设备(比如GPU)的个数整除时,才建议使用Split(0)切分。
(2) 方案二 vs. 方案三相比于方案二,方案三省略了对 sparse ID 的广播操作,从单纯的模型并行变成混合并行(既有数据并行,也有模型并行)。
方案三增加了对 sparse ID 的 Unique 操作,增加了一定的计算开销,但是也正是因为去除了一些重复的 sparse ID,相应的减少了一些通信开销。两种方案的通信量总结如下:
| 方案二 | 方案三 最坏情况 | |
|---|---|---|
| sparse ID | batch_size * num_sparse_fields *P | batch_size * num_sparse_fields |
| Wide部分 | 2 *D1 * (P - 1) | 2 * D1 |
| Deep部分 | 2 * D2 * (P-1)/P | 2 * D2 |
其中,
P 代表设备数。 D1 代表 Wide 部分传输的数据块大小, D1 = batch_size * num_wide_sparse_fields * wide_embedding_vec_size。D2 代表 Wide 部分传输的数据块大小, D2 = batch_size * num_deep_sparse_fields * deep_embedding_vec_size。
方案二与方案三最坏情况的通信量相比,deep部分两种方案的通信量相差不大,sparse ID 和 Wide 部分的通信量方案三较少。
那么,能得出方案三在所有情况下都比方案二有优势的结论吗?答案是否定的,原因如下:
1)注意到,方案二利用了 OneFlow 的集合通信操作进行数据传输,可以充分利用带宽,通信传输效率比方案三的 Push、Pull 操作高很多,在通信量差距不大时,方案二往往更有优势。
2)方案三有对 Sparse ID 的去重操作,因此,在某些极端情况下(当有大量sparse ID 重复时,方案三的通信量会进一步减少),方案三才会更有优势。
四、结语
本文以 WDL 为例,展示了如何凭借 OneFlow 独创的 SBP 概念,轻松设计并实现不同的并行方案。除了本文介绍的高效的 WDL 训练模型外,OneFlow 团队也正在开发和筹划为大型推荐系统适配更多的功能,包括可将模型高频部分切分到 GPU 上,将低频部分切分到 CPU 上;更丰富的模型库、高效方便的 Serving 系统、动态缩放的词表、在线学习等。
适配更多种类硬件设备、全新的1.0 interface 的 OneFlow 版本也即将来袭。敬请期待:https://github.com/Oneflow-Inc/oneflow 。
参考资料
CTR Prediction 问题的介绍,参考了这篇文章:《CTR 预估[一]: Problem Description and Main Solution》[14] 词向量和 Embedding 的解释,参考了这篇文章:《词向量与 Embedding 究竟是怎么回事?》[15]
文中注释对照
HugeCTR: https://github.com/NVIDIA/HugeCTR
[2]MLPerf : https://github.com/mlperf/training_results_v0.7
[3]英伟达 Blog: https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
[4]DLPerf: https://github.com/Oneflow-Inc/DLPerf#wide-and-deep-learning
[5]DLPerf : https://github.com/Oneflow-Inc/DLPerf/tree/master/reports
[6]WDL论文: https://arxiv.org/pdf/1606.07792.pdf%29/
[7]gather: https://oneflow.readthedocs.io/en/master/oneflow.html?#oneflow.gather
[8]OneFlow-Benchmark: https://github.com/Oneflow-Inc/OneFlow-Benchmark/tree/master/ClickThroughRate/WideDeepLearning
[9]HugeCTR: https://github.com/NVIDIA/HugeCTR
[10]OneFlow-WDL: https://github.com/Oneflow-Inc/OneFlow-Benchmark/tree/74caa439bbe0fb2368878d4fb771525b70831d27/ClickThroughRate/WideDeepLearning
[11]OneFlow-WDL 的 Criteo 数据集预处理: https://github.com/Oneflow-Inc/OneFlow-Benchmark/blob/master/ClickThroughRate/WideDeepLearning/how_to_make_ofrecord_for_wdl.md
[12]OneFlow 仓库: https://github.com/Oneflow-Inc/oneflow
[13]PR: https://github.com/Oneflow-Inc/oneflow/pull/3931
[14]《CTR 预估[一]: Problem Description and Main Solution》: https://zhuanlan.zhihu.com/p/31499375
[15]《词向量与 Embedding 究竟是怎么回事?》: https://spaces.ac.cn/archives/4122