
滴滴高级管理层大揭秘!
大家好,我是二哥呀。
滴滴的高级管理层,其实只有 2 人,相信大家也都有耳闻,老大叫程维,老二叫柳青。
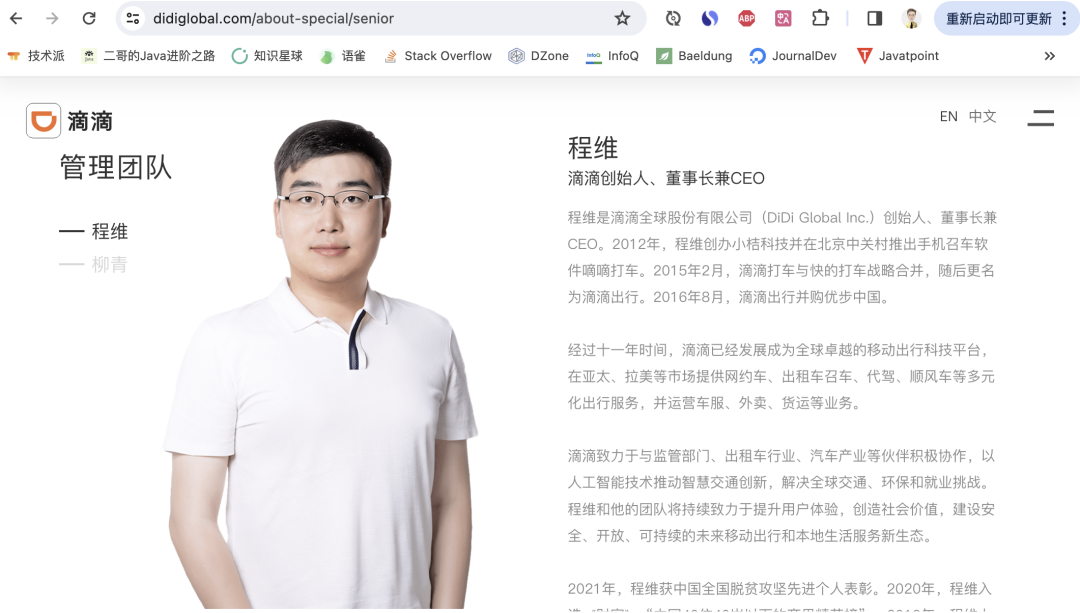
作为年轻人,我其实是比较佩服程维的,80 后,江西上饶人(扯一嘴,我小舅目前在那边打工),2005 年进入阿里巴巴从事销售工作,2012 年离职创业做滴滴打车软件。
如果没记错的话,应该是 2015 年,滴滴、Uber、快的,上演了互联网早期的烧钱大战,不仅乘客打车不要钱,司机还能领到打车软件的高额补贴。
我当时还不懂其中的运转逻辑,觉得这些高层的脑子肯定是被驴踢了(😂),后来才知道自己坐井观天了。总之,程维在快要支撑不下去的时候招募到了柳青,一个有着深厚背景的社会精英。
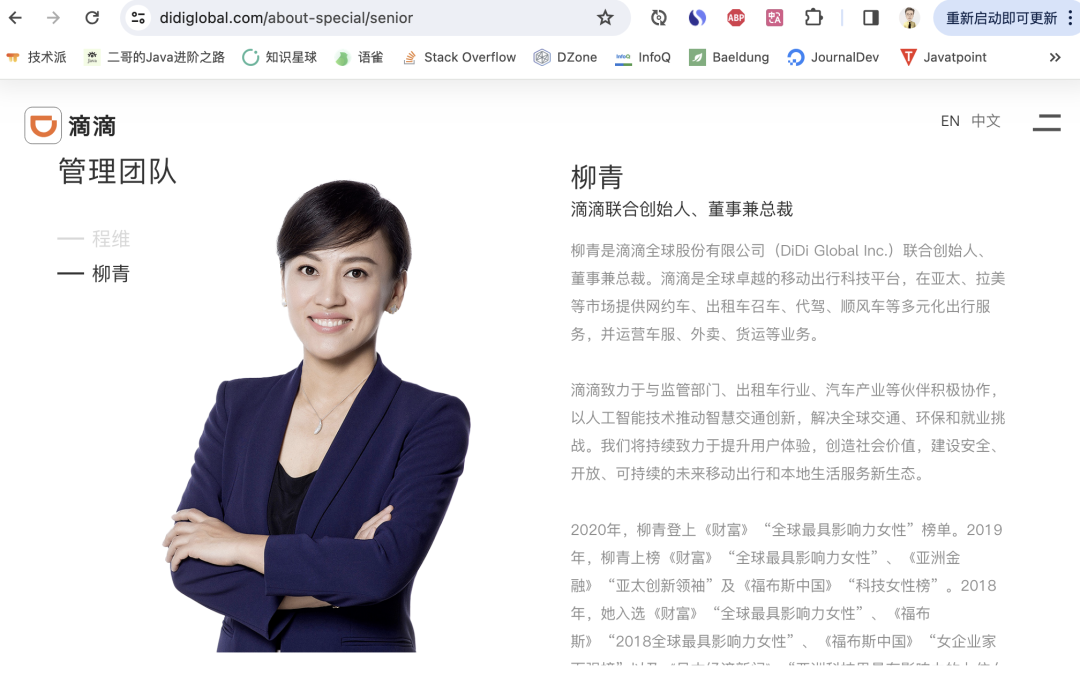
加入滴滴 5 个月后,柳青就帮滴滴拉到了一笔 7 亿美元的融资(当时非上市公司最大的一笔),随后又主导了滴滴与快的合并案、Uber 收购案等等,可以说三举奠定了滴滴的霸主地位。
再后来,大家应该也听过滴滴的一些拂面新闻,我就不敢提了。。。
总之,据在滴滴的一些朋友反馈,滴滴目前的薪资待遇、技术氛围真的挺不错,我个人也一直关注着滴滴的技术博客,内容写得非常扎实,几乎喜欢的技术贴都看了。

滴滴目前的春招和社招也在如期进行着,对桔厂感兴趣的小伙伴可以冲。24 届秋招硕士 211 后端开发能开到年包 36 万左右,真的不少了。

滴滴面经
牛顿曾说过,“如果我比别人看得更远,那是因为我站在巨人的肩膀上”。因此,如果你也想冲滴滴的话,就一定要多看看前辈们的面经。
- 三分恶面渣逆袭在线版:https://javabetter.cn/sidebar/sanfene/nixi.html
- 三分恶面渣逆袭 PDF 版:https://t.zsxq.com/04FuZrRVf
这次我们以《Java 面试指南》中同学 2 的滴滴二面为例,来看看如果你在面试中遇到这些面试题的话,该如何回答?
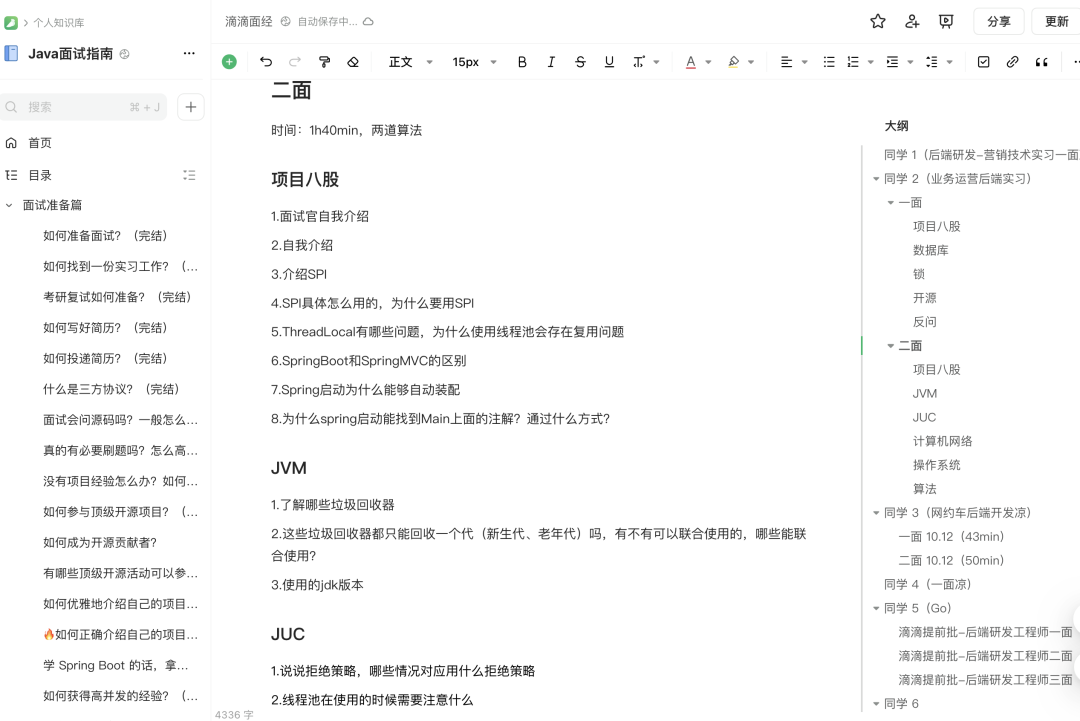
先来看技术一面的题目大纲(围绕 Java 后端四大件展开):
- ThreadLocal有哪些问题,为什么使用线程池会存在复用问题
- SpringBoot和SpringMVC的区别
- SpringBoot 启动时为什么能够自动装配
- 为什么 Spring Boot 启动时能找到 Main 类上面的注解?
- 了解哪些垃圾回收器
- 这些垃圾回收器都只能回收一个代(新生代、老年代)吗,有不有可以联合使用的,哪些能联合使用?
- 使用的jdk版本
- 说说并发编程中的拒绝策略,哪些情况对应用什么拒绝策略
- 线程池在使用的时候需要注意什么
内容较长,撰写硬核面经不容易,建议大家先收藏起来,面试的时候大概率会碰到,二哥会尽量用通俗易懂+手绘图的方式,让你能背会的同时,还能理解和掌握,总之:让天下没有难背的八股 😂
01、ThreadLocal有哪些问题,为什么使用线程池会存在复用问题
ThreadLocal 是什么?
ThreadLocal 是 Java 中提供的一种用于实现线程局部变量的工具类。它允许每个线程都拥有自己的独立副本,从而实现线程隔离,用于解决多线程中共享对象的线程安全问题。
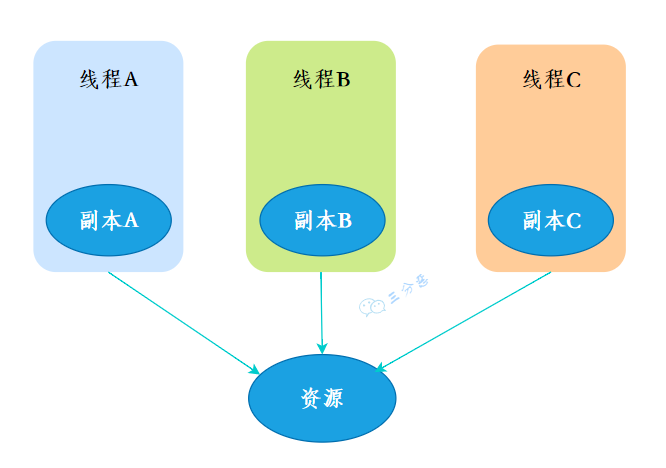 三分恶面渣逆袭:ThreadLocal线程副本
三分恶面渣逆袭:ThreadLocal线程副本使用 ThreadLocal 通常分为三步:
①、创建 ThreadLocal 变量
//创建一个ThreadLocal变量
public static ThreadLocal<String> localVariable = new ThreadLocal<>();
②、设置 ThreadLocal 变量的值
//设置ThreadLocal变量的值
localVariable.set("沉默王二是沙雕");
③、获取 ThreadLocal 变量的值
//获取ThreadLocal变量的值
String value = localVariable.get();
ThreadLocal可能会出现内存泄露问题
在 Java 虚拟机中,栈是线程私有的,堆是线程共享的。
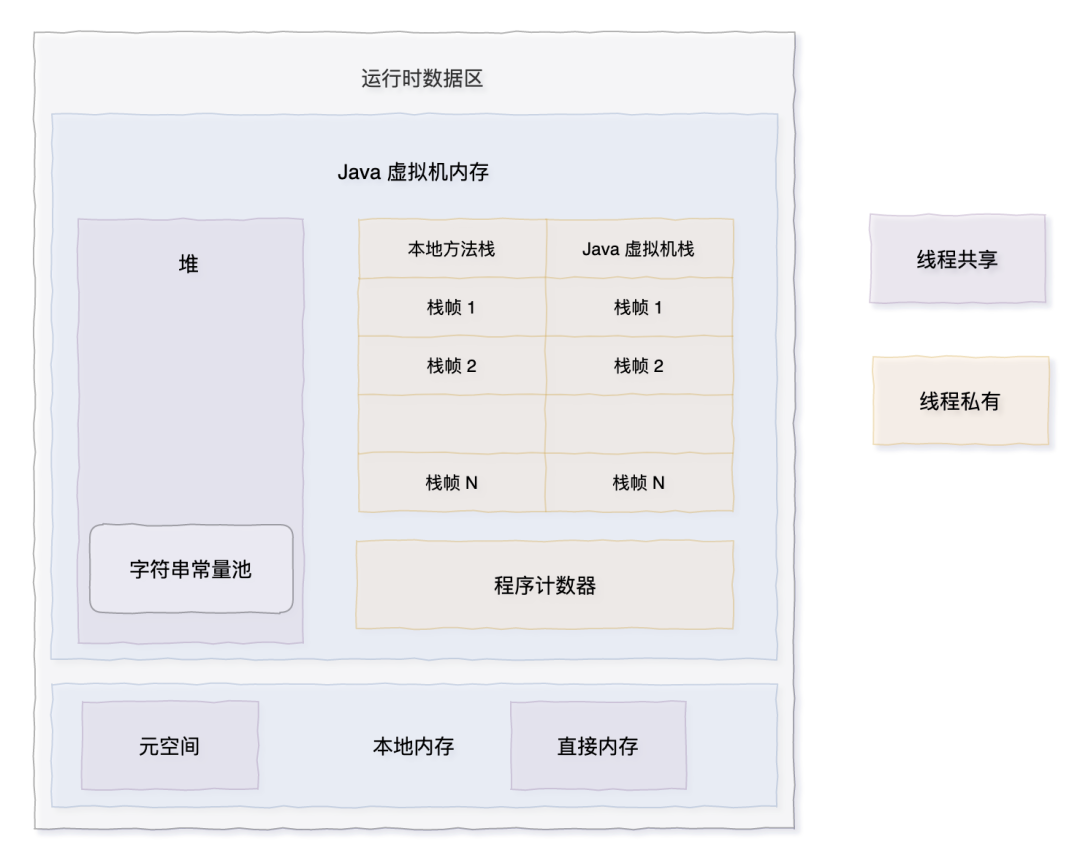
每个 Thread 对象内部都有一个 ThreadLocal.ThreadLocalMap,用于存储与该线程相关的 ThreadLocal 变量。
ThreadLocalMap 是一个键值对集合,其中键是 ThreadLocal 对象的引用,值是使用 ThreadLocal 存储的数据。
也就是说,栈中存储了 ThreadLocal 和 Thread 的引用,堆中存储了它们的具体实例。
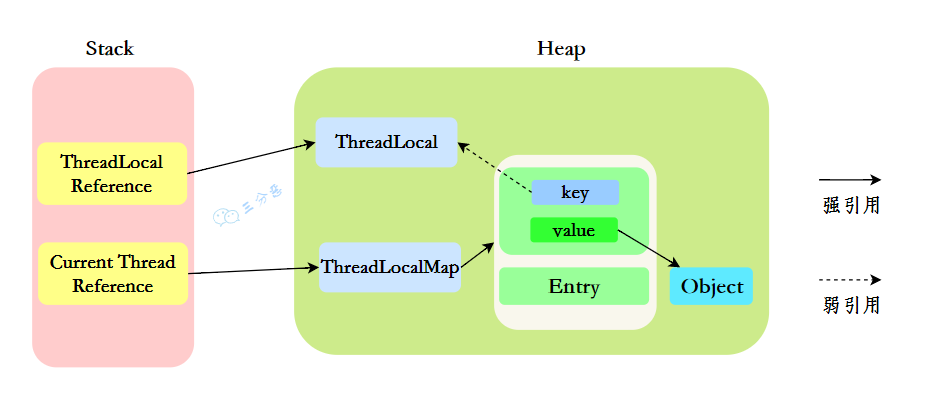 三分恶面渣逆袭:ThreadLocal内存分配
三分恶面渣逆袭:ThreadLocal内存分配使用 ThreadLocal 发生内存泄露的原因可能是:
①、ThreadLocalMap 的生命周期过长,在使用线程池等长生命周期的线程时,线程不会立即销毁。
如果ThreadLocal变量在使用后没有被及时清理(通过调用ThreadLocal的remove()方法),那么ThreadLocalMap中的键值对会一直存在,即使外部已经没有对ThreadLocal对象的引用。
这意味着ThreadLocalMap中的键值对无法被垃圾收集器回收,从而导致内存泄露。
②、ThreadLocal 对象生命周期结束,线程继续运行。
如果一个ThreadLocal对象已经不再被使用,但是线程仍然在运行,并且其ThreadLocalMap中还保留着对这个ThreadLocal对象的键的引用,这会导致ThreadLocal对象所引用的数据也无法被回收,因为ThreadLocalMap中的键是对ThreadLocal对象的弱引用(WeakReference),但值(存储的数据)是强引用。
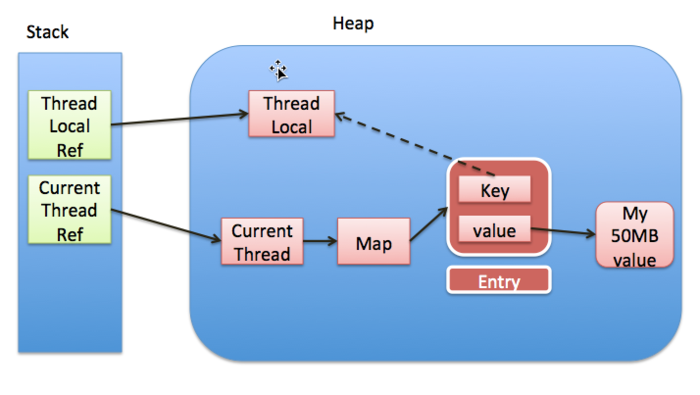
举例说明一下:
public class ThreadLocalLeakExample {
private static final ThreadLocal<UserInfo> userThreadLocal = new ThreadLocal<>();
public static void main(String[] args) throws InterruptedException {
// 创建一个UserInfo对象并设置到ThreadLocal中
UserInfo userInfo = new UserInfo("沉默王二");
userThreadLocal.set(userInfo);
// 模拟在一段时间后,UserInfo不再被使用
// 在实际应用中,这可能是因为请求处理完毕等原因
userThreadLocal.remove(); // 假设这一行被遗忘或漏掉了
// 强制GC尝试回收
System.gc();
Thread.sleep(1000); // 等待GC完成,只是为了示例需要
// 模拟线程继续运行
System.out.println("线程继续执行");
}
}
如果userThreadLocal.remove();这行代码被遗漏或者因为某些原因没有执行,即使UserInfo对象已经不再需要了,它也不会被垃圾回收器回收。这是因为ThreadLocalMap中对UserInfo的引用是一个强引用。虽然ThreadLocal对象本身(作为ThreadLocalMap的键)可能由于是弱引用而被回收,但由于ThreadLocalMap的值是强引用,所以UserInfo仍然被ThreadLocalMap所引用,阻止了其被垃圾回收。
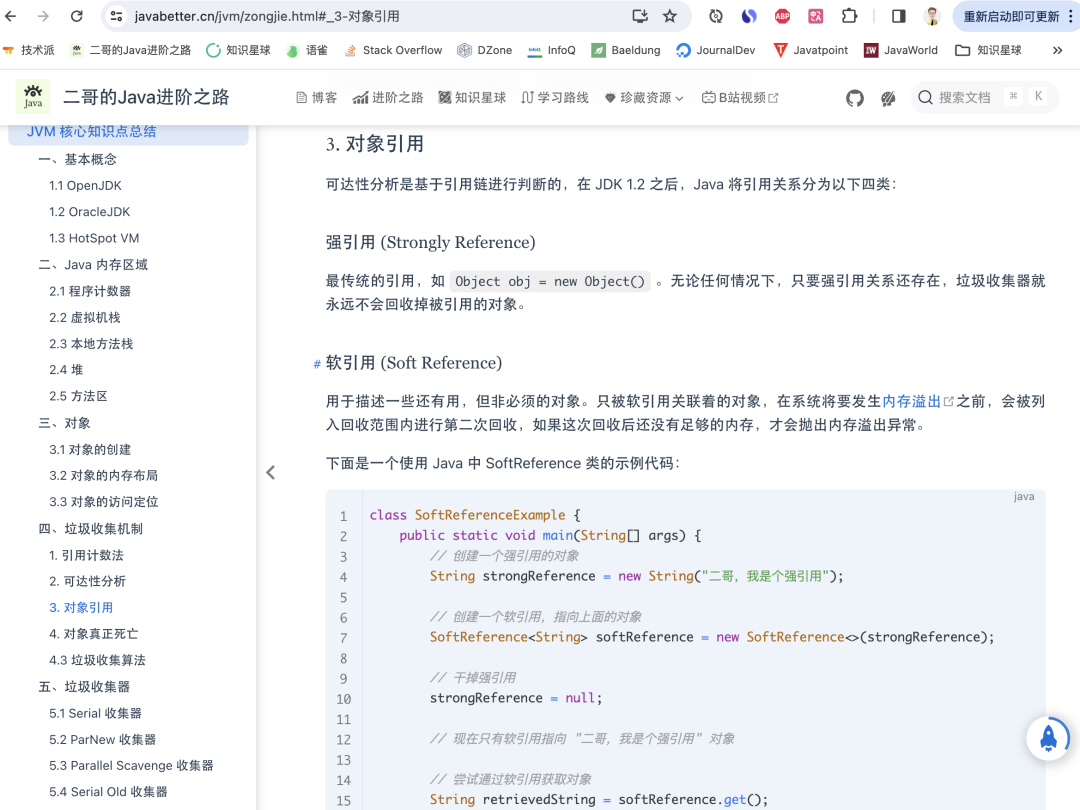
强引用是 Java 中最常见的引用类型。如果一个对象具有强引用,垃圾收集器绝不会回收它。当内存空间不足时,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会回收这种对象。
Object obj = new Object();
弱引用需要用 java.lang.ref.WeakReference 类来实现。
Object obj = new Object();
WeakReference<Object> weakRef = new WeakReference<Object>(obj);
obj = null; // 取消强引用
在取消 obj 的强引用之后,只剩下 obj 对象的弱引用 weakRef 了。在这种情况下,垃圾收集器在下一次执行时会回收 obj 对象。
更多强引用和弱引用的区别,推荐阅读:JVM 核心知识点总结
为什么使用线程池会存在复用问题
使用线程池存在复用问题主要是因为,线程池的设计初衷是为了减少在多线程中频繁创建和销毁线程的开销,通过重用一组现有的线程来执行任务。
这种机制带来了性能上的优势,但也引入了一些潜在的问题,尤其是 ThreadLocal 的复用问题。
由于线程被重用,如果上一个任务在ThreadLocal中存储了一些数据并且没有适当地清理,那么这些数据就会留在线程中,当这个线程被下一个任务重用时,下一个任务就可能意外地访问到这些残留数据。
02、SpringBoot 和 SpringMVC 的区别
Spring MVC 是基于 Spring 框架的一个模块,提供了一种 Model-View-Controller(模型-视图-控制器)的开发模式。
Spring Boot 旨在简化 Spring 应用的配置和部署过程,提供了大量的自动配置选项,以及运行时环境的内嵌 Web 服务器,这样就可以更快速地开发一个 SpringMVC 的 Web 项目。
03、SpringBoot 启动时为什么能够自动装配
在 Spring 中,自动装配是指容器利用反射技术,根据 Bean 的类型、名称等自动注入所需的依赖。
在 Spring 的 XML 配置文件中,可以通过 autowire 属性来指定自动装配的模式,如 byType、byName 等。
也可以在 Java 类中使用@Autowired、@Resource 等注解来表明该成员变量或方法需要被自动装配。
在 Spring Boot 中,开启自动装配的注解是@EnableAutoConfiguration。
Spring Boot 项目为了进一步简化,直接通过 @SpringBootApplication 注解一步搞定,这个注解包含了 @EnableAutoConfiguration 注解。
①、@EnableAutoConfiguration 只是一个简单的注解,但是它的背后却是一个非常复杂的自动装配机制,它的核心是AutoConfigurationImportSelector 类。
@AutoConfigurationPackage //将main同级的包下的所有组件注册到容器中
@Import({AutoConfigurationImportSelector.class}) //加载自动装配类 xxxAutoconfiguration
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
②、AutoConfigurationImportSelector实现了ImportSelector接口,这个接口的作用就是收集需要导入的配置类,配合@Import()就将相应的类导入到 Spring 容器中。
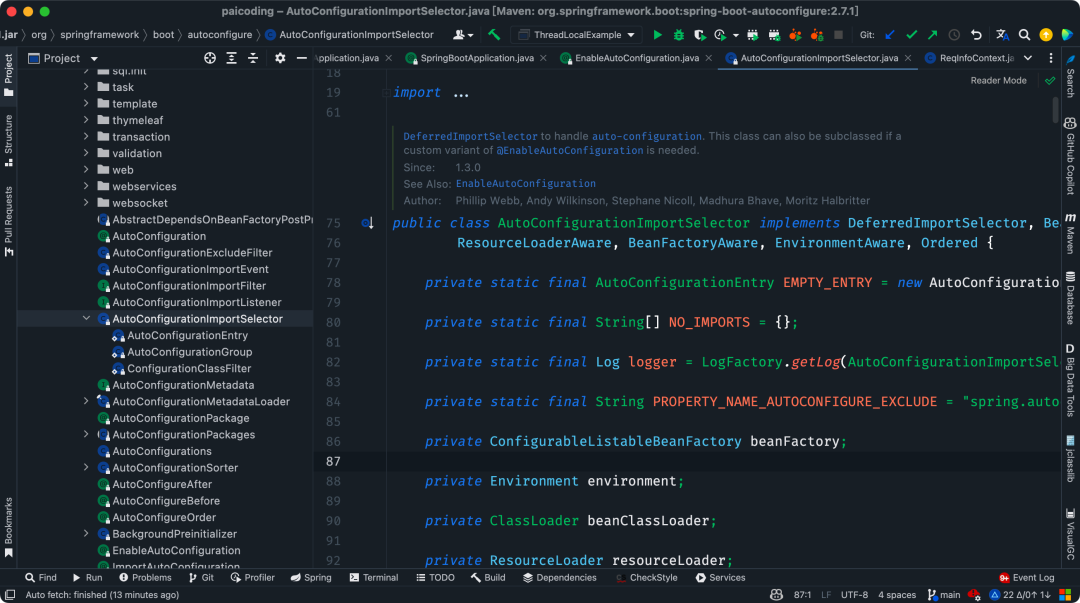
③、获取注入类的方法是 selectImports(),它实际调用的是getAutoConfigurationEntry,这个方法是获取自动装配类的关键。
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
// 检查自动配置是否启用。如果@ConditionalOnClass等条件注解使得自动配置不适用于当前环境,则返回一个空的配置条目。
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
// 获取启动类上的@EnableAutoConfiguration注解的属性,这可能包括对特定自动配置类的排除。
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// 从spring.factories中获取所有候选的自动配置类。这是通过加载META-INF/spring.factories文件中对应的条目来实现的。
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
// 移除配置列表中的重复项,确保每个自动配置类只被考虑一次。
configurations = removeDuplicates(configurations);
// 根据注解属性解析出需要排除的自动配置类。
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
// 检查排除的类是否存在于候选配置中,如果存在,则抛出异常。
checkExcludedClasses(configurations, exclusions);
// 从候选配置中移除排除的类。
configurations.removeAll(exclusions);
// 应用过滤器进一步筛选自动配置类。过滤器可能基于条件注解如@ConditionalOnBean等来排除特定的配置类。
configurations = getConfigurationClassFilter().filter(configurations);
// 触发自动配置导入事件,允许监听器对自动配置过程进行干预。
fireAutoConfigurationImportEvents(configurations, exclusions);
// 创建并返回一个包含最终确定的自动配置类和排除的配置类的AutoConfigurationEntry对象。
return new AutoConfigurationEntry(configurations, exclusions);
}
画张图来总结下:
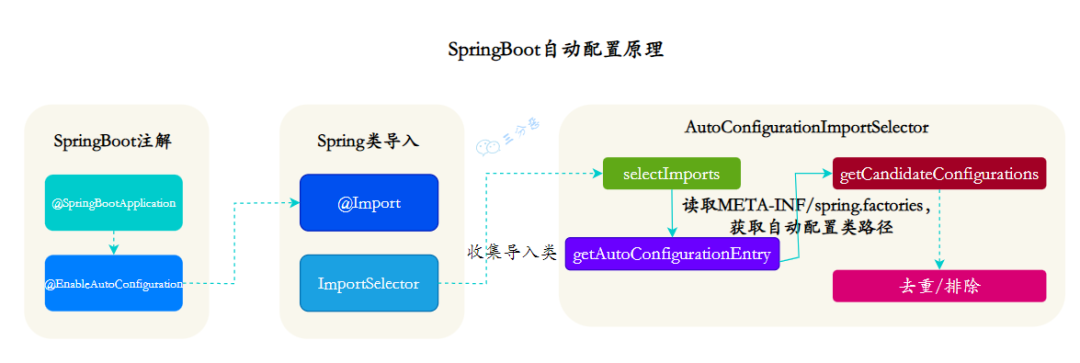 三分恶面渣逆袭:SpringBoot自动配置原理
三分恶面渣逆袭:SpringBoot自动配置原理04、为什么 Spring Boot 启动时能找到 Main 类上面的注解
SpringApplication 这个类主要做了以下四件事情:
- 推断应用的类型是普通的项目还是 Web 项目
- 查找并加载所有可用初始化器 , 设置到 initializers 属性中
- 找出所有的应用程序监听器,设置到 listeners 属性中
- 推断并设置 main 方法的定义类,找到运行的主类
SpringBoot 启动大致流程如下 :
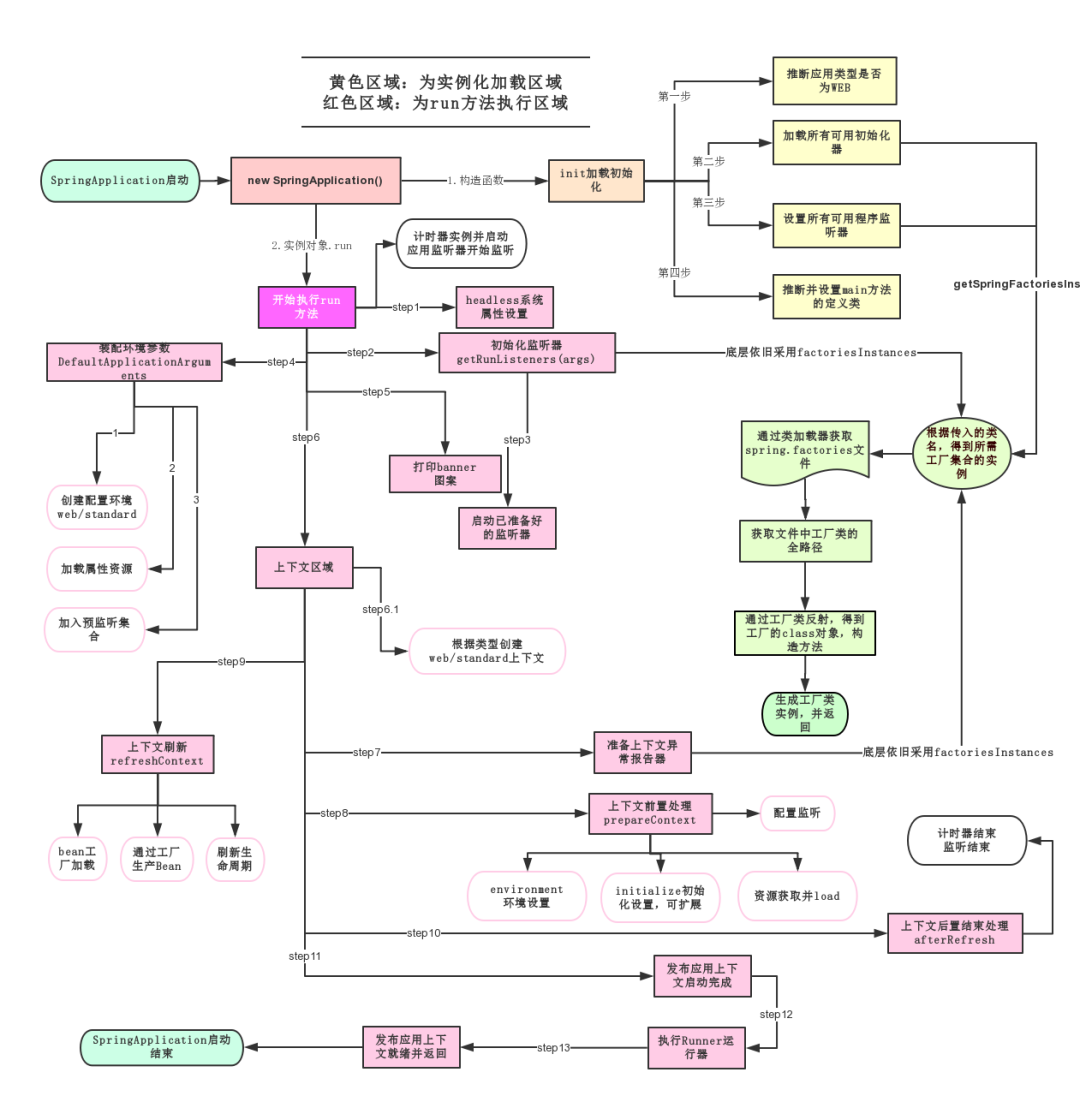 SpringBoot 启动大致流程-图片来源网络
SpringBoot 启动大致流程-图片来源网络为什么 Spring Boot 在启动的时候能够找到 main 方法上的@SpringBootApplication 注解?
Spring Boot 在启动时能够找到主类上的@SpringBootApplication注解,是因为它利用了 Java 的反射机制和类加载机制,结合 Spring 框架内部的一系列处理流程。
当运行一个 Spring Boot 程序时,通常会调用主类中的main方法,这个方法会执行SpringApplication.run(),比如:
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
SpringApplication.run(Class<?> primarySource, String... args)方法接收两个参数:第一个是主应用类(即包含main方法的类),第二个是命令行参数。primarySource参数提供了一个起点,Spring Boot 通过它来加载应用上下文。
Spring Boot 利用 Java 反射机制来读取传递给run方法的类(MyApplication.class)。它会检查这个类上的注解,包括@SpringBootApplication。
05、了解哪些垃圾回收器,只能回收一个代(新生代、老年代)吗,使用的jdk版本
推荐阅读:深入理解 JVM 的垃圾收集器:CMS、G1、ZGC
就目前来说,JVM 的垃圾收集器主要分为两大类:分代收集器和分区收集器,分代收集器的代表是 CMS,分区收集器的代表是 G1 和 ZGC。
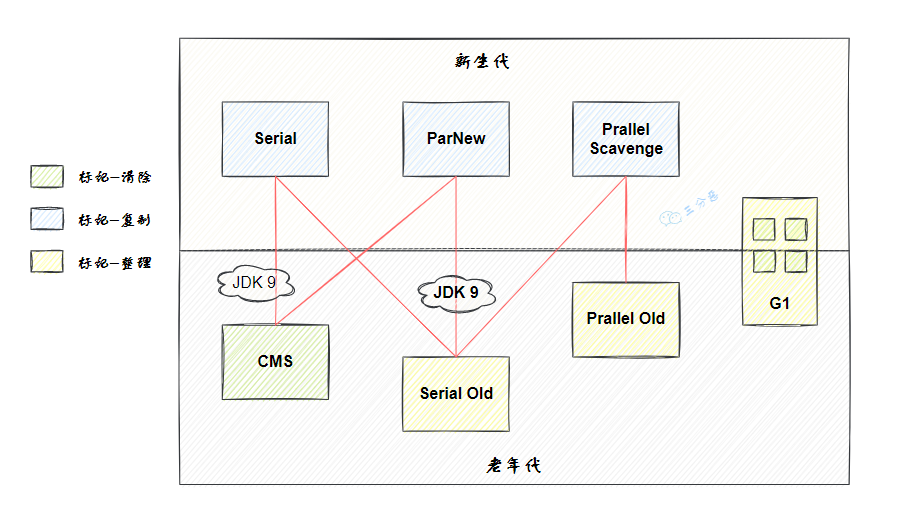 三分恶面渣逆袭:HotSpot虚拟机垃圾收集器
三分恶面渣逆袭:HotSpot虚拟机垃圾收集器CMS 收集器
以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW,JDK 1.5 时引入,JDK9 被标记弃用,JDK14 被移除。
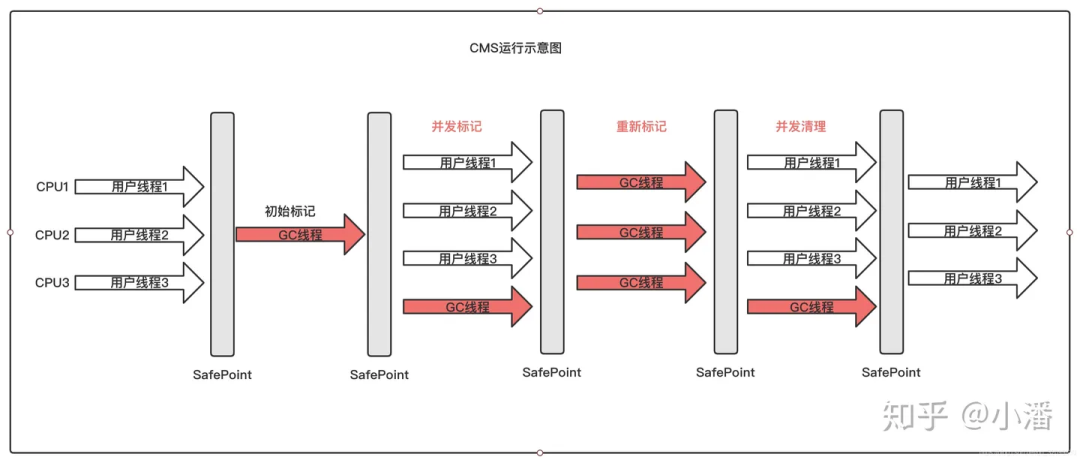
Garbage First 收集器
G1(Garbage-First Garbage Collector)在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为了默认的垃圾收集器。G1 有五个属性:分代、增量、并行、标记整理、STW。
ZGC 收集器
ZGC 是 JDK 11 时引入的一款低延迟的垃圾收集器,它的目标是在不超过 10ms 的停顿时间内,为堆大小达到 16TB 的应用提供一种高吞吐量的垃圾收集器。
ZGC 的两个关键技术:指针染色和读屏障,不仅应用在并发转移阶段,还应用在并发标记阶段:将对象设置为已标记,传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;而在ZGC中,只需要设置指针地址的第42-45位即可,并且因为是寄存器访问,所以速度比访问内存更快。
 得物技术
得物技术新生代和老年代
根据对象存活周期的不同会将内存划分为几块,一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
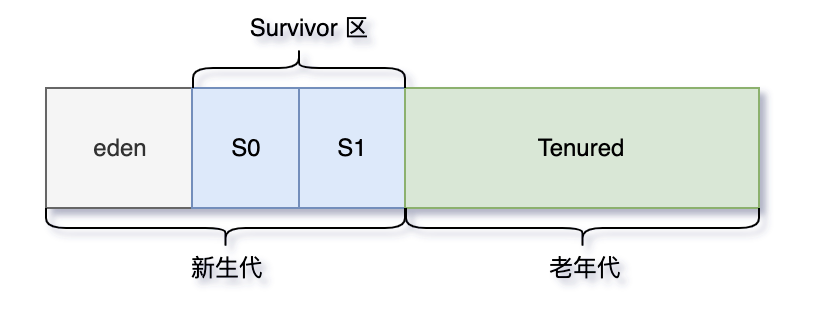
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记清理或者标记整理算法来进行回收。
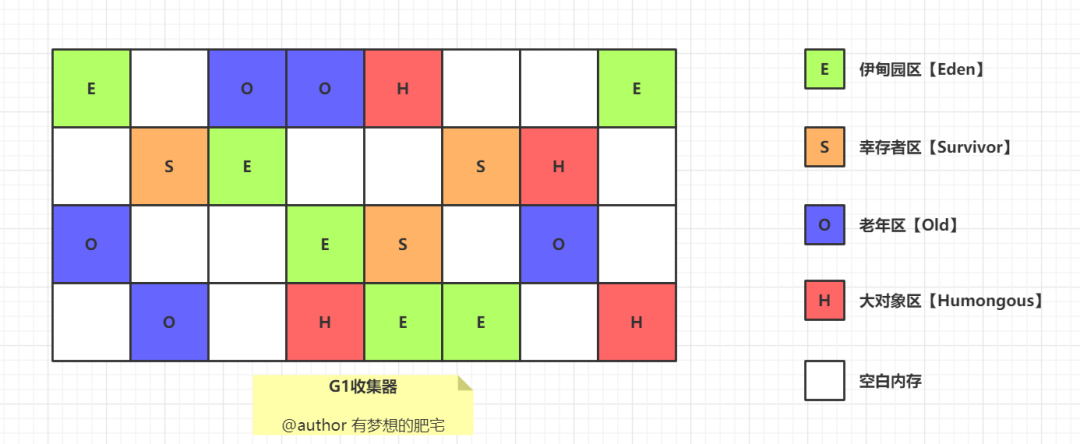
Eden 区和 Survivor 区
其中年轻代又分 Eden 区和 Survivor 区,其中 Survivor 区又分 From 和 To 两个区。
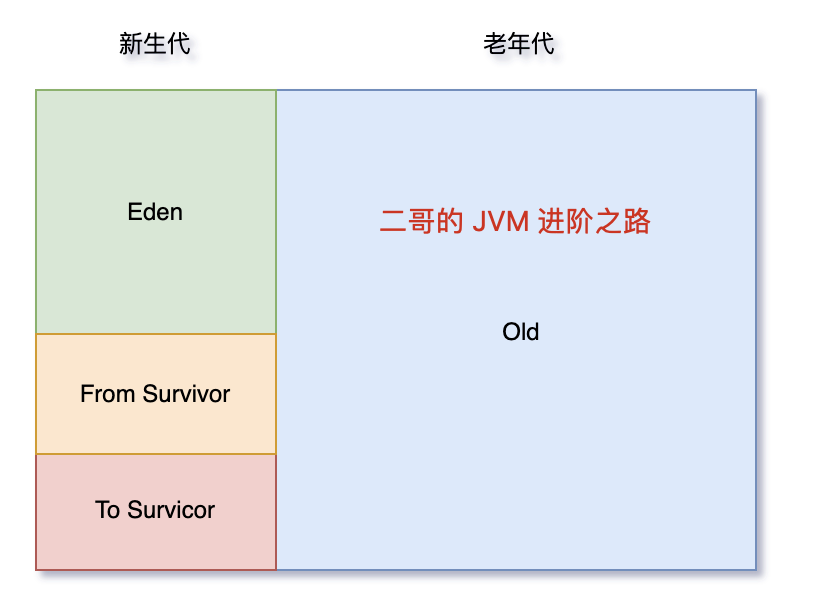
据 IBM 公司之前的研究表明,有将近 98% 的对象是朝生夕死,所以针对这一现状,大多数情况下,对象会在新生代 Eden 区中进行分配,当 Eden 区没有足够空间进行分配时,JVM 会发起一次 Minor GC,Minor GC 相比 Major GC 更频繁,回收速度也更快。
通过 Minor GC 之后,Eden 区中绝大部分对象会被回收,而那些无需回收的存活对象,将会进到 Survivor 的 From 区,如果 From 区不够,则直接进入 To 区。
Survivor 区相当于是 Eden 区和 Old 区的一个缓冲,类似于我们交通灯中的黄灯。
因为 Survivor 有 2 个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责兑换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。
老年代占据着 2/3 的堆内存空间,只有在 Major GC 的时候才会进行清理,每次 GC 都会触发“Stop-The-World”。内存越大,STW 的时间也越长,所以内存也不仅仅是越大就越好。
垃圾收集器对新生代和老年代的处理
CMS 属于分代收集器,G1 和 ZGC 属于分区收集器。
- CMS:主要优化老年代的并发收集,减少停顿时间,但不直接处理新生代且可能导致内存碎片。
- G1:通过将堆分割成多个区域来同时管理新生代和老年代,提供了更平衡的性能,旨在控制长时间的停顿,适用于大堆内存。
- ZGC:采用全新的垃圾回收机制,不区分新生代和老年代,通过并发执行大部分垃圾回收工作实现极低的停顿时间,适用于大堆内存且要求低延迟的场景。
06、说说并发编程中的拒绝策略,哪些情况对应用什么拒绝策略
我现在去银行办理业务,被经历“薄纱”了:“我们系统瘫痪了”、“谁叫你来办的你找谁去”、“看你比较急,去队里加个塞”、“今天没办法,不行你看改一天”。
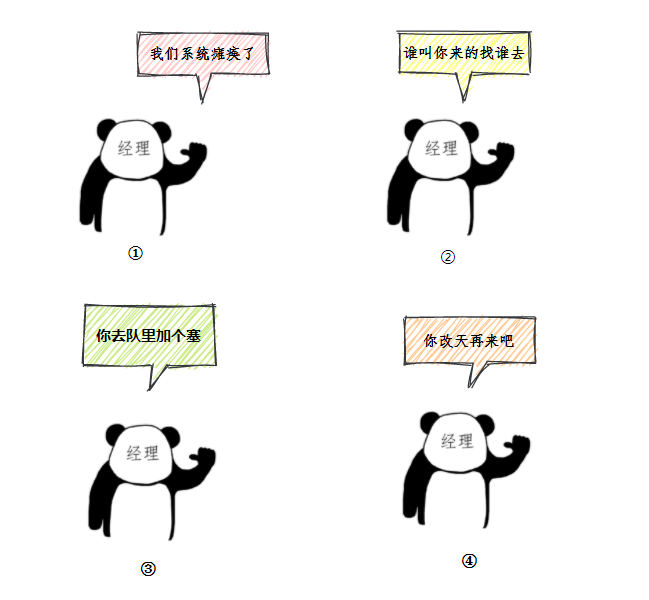 三分恶面渣逆袭:四种策略
三分恶面渣逆袭:四种策略分别对应上了线程池中的四种拒绝策略:
- AbortPolicy:这是默认的拒绝策略。该策略会抛出一个 RejectedExecutionException 异常。也就对应着“我们系统瘫痪了”。
- CallerRunsPolicy:该策略不会抛出异常,而是会让提交任务的线程(即调用 execute 方法的线程)自己来执行这个任务。也就对应着“谁叫你来办的你找谁去”。
- DiscardOldestPolicy:策略会丢弃队列中最老的一个任务(即队列中等待最久的任务),然后尝试重新提交被拒绝的任务。也就对应着“看你比较急,去队里加个塞”。
- DiscardPolicy:策略会默默地丢弃被拒绝的任务,不做任何处理也不抛出异常。也就对应着“今天没办法,不行你看改一天”。
如果想实现自己的拒绝策略,实现 RejectedExecutionHandler 接口即可。
07、线程池在使用的时候需要注意什么
我认为比较重要的关注点有 3 个:
①、选择合适的线程池大小
- 过小的线程池可能会导致任务一直在排队
- 过大的线程池可能会导致大家都在竞争 CPU 资源,增加上下文切换的开销
可以根据业务是 IO 密集型还是 CPU 密集型来选择线程池大小:
- CPU 密集型:指的是任务主要使用来进行大量的计算,没有什么导致线程阻塞。一般这种场景的线程数设置为 CPU 核心数+1。
- IO 密集型:当执行任务需要大量的 io,比如磁盘 io,网络 io,可能会存在大量的阻塞,所以在 IO 密集型任务中使用多线程可以大大地加速任务的处理。一般线程数设置为 2*CPU 核心数。
②、任务队列的选择
- 使用有界队列可以避免资源耗尽的风险,但是可能会导致任务被拒绝
- 使用无界队列虽然可以避免任务被拒绝,但是可能会导致内存耗尽
一般需要设置有界队列的大小,比如 LinkedBlockingQueue 在构造的时候可以传入参数来限制队列中任务数据的大小,这样就不会因为无限往队列中扔任务导致系统的 oom。
③、尽量使用自定义的线程池,而不是使用 Executors 创建的线程池,因为 newFixedThreadPool 线程池由于使用了 LinkedBlockingQueue,队列的容量默认无限大,实际使用中出现任务过多时会导致内存溢出;newCachedThreadPool 线程池由于核心线程数无限大,当任务过多的时候会导致创建大量的线程,可能机器负载过高导致服务宕机。
参考链接
- 1、星球嘉宾三分恶的面渣逆袭,可微信搜索三分恶关注他的公众号:https://javabetter.cn/sidebar/sanfene/nixi.html
- 2、二哥的Java进阶之路:https://javabetter.cn
- 3、PDF 版面渣逆袭:https://t.zsxq.com/04FuZrRVf
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 4700 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个编程学习指南 + Java 项目实战 + LeetCode 刷题的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。

两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。