
空手撸SOLID架构设计原则,六大原则层层解析,你绝想不到
设计原则概述
通常来说,要想构建—个好的软件系统,应该从写整洁的代码开始做起。毕竟,如果建筑所使用的砖头质量不佳,那么架构所能起到的作用也会很有限。反之亦然,如果建筑的架构设计不佳,那么其所用的砖头质量再好也没有用。这就是SOLID设计原则所要解决的问题。
SOLID原则的主要作用就是告诉我们如何将数据和函数组织成为类,以及如何将这些类链接起来成为程序。请注意,这里虽然用到了“类”这个词,但是并不意味着我们将要讨论的这些设计原则仅仅适用于面向对象编程。这里的类仅仅代表了一种数据和函数的分组,每个软件系统都会有自己的分类系统,不管它们各自是不是将其称为“类”,事实上都是SOLID原则的适用领域。
一般情况下,我们为软件构建中层结构的主要目标如下:
使软件可容忍被改动
使软件更容易被理解
构建可在多个软件系统中复用的组件
我们在这里之所以会使用“中层”这个词,是因为这些设计原则主要适用于那些进行模块级编程的程序员。SO凵D原则应该直接紧贴于具体的代码逻辑之上,这些原则是用来帮助我们定义软件架构中的组件和模块的。
当然了,正如用好砖也会盖歪楼一样,采用设计良好的中层组件并不能保证系统的整体架构运作良好。正因为如此,我们在讲完SOLID原则之后,还会再继续针对组件的设计原则进行更进一步的讨论,将其推进到高级软件架构部分。
SOLID原则的历史已经很悠久了,早在20世纪80年代末期,我在 USENET新闻组(该新闻组在当时就相当于今天的 Facebook)上和其他人辩论软件设计理念的时候,该设计原则就已经开始逐渐成型了。随着时间的推移,其中有一些原则得到了修改,有一些则被抛弃了,还有一些被合并了,另外也增加了一些。它们的最终形态是在2000年左右形成的,只不过当时采用的是另外一个展现顺序。
2004年前后, Michael feathers的一封电子邮件提醒我:如果重新排列这些设计原则,那么它们的首字母可以排列成SOLID——这就是SOLID原则诞生的故事。
在这一部分中,我们会逐章地详细讨论每个设计原则,下面先来做一个简单摘要。
SRP:单一职责原则。
该设计原则是基于康威定律( Conway‘s Law)的一个推论——软件系统的最佳结构高度依赖于开发这个系统的组织的内部结构。这样,每个软件模块都有且只有一个需要被改变的理由。
OCP:开闭原则。
该设计原则是由 Bertrand Meyer在20世纪80年代大力推广的,其核心要素是:如果软件系统想要更容易被改变,那么其设计就必须允许新增代码来修改系统行为,而非只能靠修改原来的代码。
LSP:里氏替换原则。
该设计原则是 Barbara liskov在1988年提出的著名的子类型定义。简单来说,这项原则的意思是如果想用可替换的组件来构建软件系统,那么这些组件就必须遵守同一个约定,以便让这些组件可以相互替换。
ISP:接口隔离原则。
这项设计原则主要告诫软件设计师应该在设计中避免不必要的依赖。
DIP:依赖反转原则。
该设计原则指出高层策略性的代码不应该依赖实现底层细节的代码,恰恰相反,那些实现底层细节的代码应该依赖高层策略性的代码。
这些年来,这些设计原则在很多不同的出版物中都有过详细描述。在接下来的章节中,我们将会主要关注这些原则在软件架构上的意义,而不再重复其细节信息。如果你对这些原则并不是特别了解,那么我建议你先通过脚注中的文档熟悉一下它们,否则接下来的章节可能有点难以理解。
SRP:单一职责原则
SRP是SOLID五大设计原则中最容易被误解的一。也许是名字的原因,很多程序员根据SRP这个名字想当然地认为这个原则就是指:每个模块都应该只做一件事。
没错,后者的确也是一个设计原则,即确保一个函数只完成一个功能。我们在将大型函数重构成小函数时经常会用到这个原则,但这只是一个面向底层实现细节的设计原则,并不是SRP的全部。
在历史上,我们曾经这样描述SRP这一设计原则:
任何一个软件模块都应该有且仅有一个被修改的原因。
在现实环境中,软件系统为了满足用户和所有者的要求,必然要经常做出这样那样的修改。而该系统的用户或者所有者就是该设计原则中所指的“被修改的原因”。所以,我们也可以这样描述SRP:
任何一个软件模块都应该只对一个用户(User)或系统利益相关者( Stakeholder)负责。
不过,这里的“用户”和“系统利益相关者”在用词上也并不完全准确,它们很有可能指的是一个或多个用户和利益相关者,只要这些人希望对系统进行的变更是相似的,就可以归为一类——一个或多有共同需求的人。在这里,我们将其称为行为者( actor)。
所以,对于SRP的最终描述就变成了:
任何一个软件模块都应该只对某一类行为者负责。
那么,上文中提刭的“软件模块”究竟又是在指什么呢?大部分情况下,其最简单的定义就是指一个源代码文件。然而,有些编程语言和编程环境并不是用源代码文件来存储程序的。在这些情况下,“软件模块”指的就是一组紧密相关的函数和数据结构。
在这里,“相关”这个词实际上就隐含了SRP这一原则。代码与数据就是靠着与某一类行为者的相关性被组合在一起的。
或许,理解这个设计原则最好的办法就是让大家来看一些反面案例。
反面案例1:重复的假象。
这是我最喜欢举的一个例子:某个工资管理程序中的 Employee类有三个函数 calculate Pay()、reportHours()和save()。

如你所见,这个类的三个函数分别对应的是三类非常不同的行为者,违反了SRP设计原则。
calculatePay()函数是由财务部门制定的,他们负责向CFO汇报。
reportHours()函数是由人力资源部门制定并使用的,他们负责向COO汇报。
save()函数是由DBA制定的,他们负责向CTO汇报。
这三个函数被放在同一个源代码文件,即同一个Employee类中,程序员这样做实际上就等于使三类行为者的行为耦合在了一起,这有可能会导致CFO团队的命令影响到COO团队所依赖的功能。
例如, calculatePay()函数和 reportHours()函数使用同样的逻辑来计算正常工作时数。程序员为了避免重复编码,通常会将该算法单独实现为个名为 regularHours()的函数(见下图)。
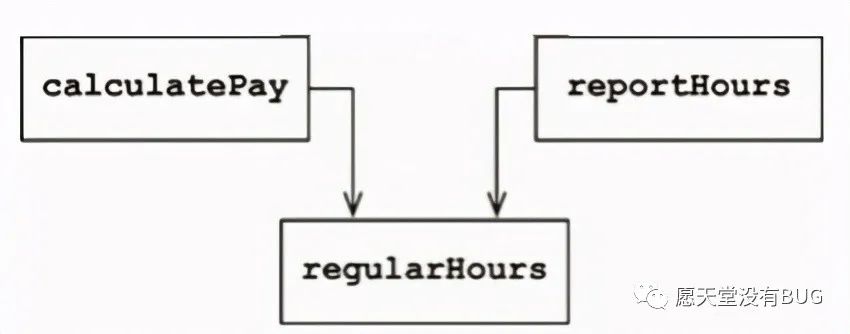
接下来,假设CFO团队需要修改正常工作时数的计算方法,而COO带领的HR团队不需要这个修改,因为他们对数据的用法是不同的。
这时候,负责这项修改的程序员会注意到calculate Pay()函数调用了 regularHours()函数,但可能不会注意到该函数会同时被reportHours()调用。
于是,该程序员就这样按照要求进行了修改,同时CFO团队的成员验证了新算法工作正常。这项修改最终被成功部署上线了。
但是,COO团队显然完全不知道这些事情的发生,HR仍然在使用 reportHours()产生的报表,随后就会发现他们的数据出错了!最终这个问题让COO十分愤怒,因为这些错误的数据给公司造成了几百万美元的损失。
与此类似的事情我们肯定多多少少都经历过。这类问题发生的根源就是因为我们将不同行为者所依赖的代码强凑到了一起。对此,SRP强调这类代码一定要被分开。
反面案例2:代码合并
一个拥有很多函数的源代码文件必然会经历很多次代码合并,该文件中的这些函数分别服务不同行为者的情况就更常见了。
例如,CTO团队的DBA决定要对 Employee数据库表结构进行简单修改。与此同时,COO团队的HR需要修改工作时数报表的格式。
这样一来,就很可能出现两个来自不同团队的程序员分别对 Employee类进行修改的情况。不出意外的话,他们各自的修改一定会互相冲突,这就必须要进行代码合并。
在这个例子中,这次代码合并不仅有可能让CTO和COO要求的功能出错,甚至连CFO原本正常的功能也可能受到影响。
事实上,这样的案例还有很多,我们就不一一列举了。它们的一个共同点是,多人为了不同的目的修改了同一份源代码,这很容易造成问题的产生。
而避免这种问题产生的方法就是将服务不同行为者的代码进行切分。
解决方案
我们有很多不同的方法可以用来解决上面的问题每一种方法都需要将相关的函数划分成不同的类。
其中,最简单直接的办法是将数据与函数分离,设计三个类共同使用一个不包括函数的、十分简单的EmployeeData类(见下图),每个类只包含与之相关的函数代码,互相不可见,这样就不存在互相依赖的情况了。
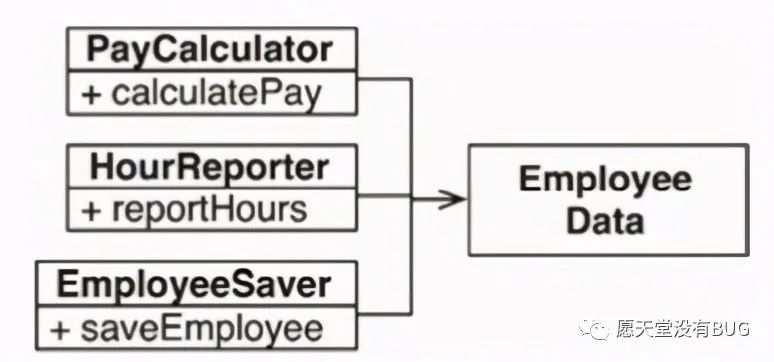
这种解决方案的坏处在于:程序员现在需要在程序里处理三个类。另一种解决办法是使用 Facade设计模式(见下图)。
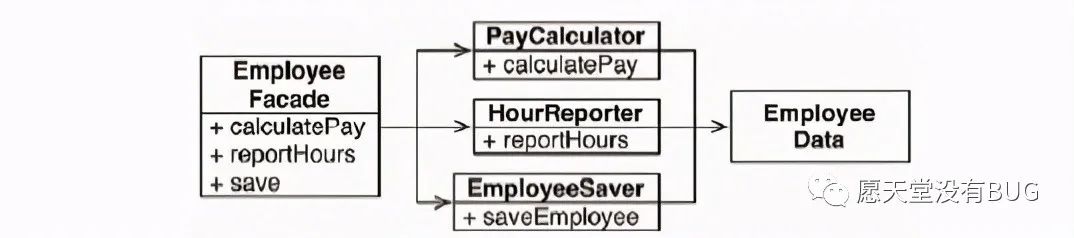
这样一来, Employee Facade类所需要的代码量就很少了,它仅仅包含了初始化和调用三个具体实现类的函数。
当然,也有些程序员更倾向于把最重要的业务逻辑与数据放在一起,那么我们也可以选择将最重要的函数保留在 Employee类中,同时用这个类来调用其他没那么重要的函数(见下图)。

读者也许会反对上面这些解决方案,因为看上去这里的每个类中都只有一个函数。事实上并非如此,因为无论是计算工资、生成报表还是保存数据都是一个很复杂的过程,每个类都可能包含了许多私有函数。
总而言之,上面的每一个类都分别容纳了一组作用于相同作用域的函数,而在该作用域之外,它们各自的私有函数是互相不可见的。
本章小结
单一职责原则主要讨论的是函数和类之间的关系——但是它在两个讨论层面上会以不同的形式出现。在组件层面,我们可以将其称为共同闭包原则( Common Closure Principle),在软件架构层面,它则是用于奠定架构边界的变更轴心( Axis of Change)。我们在接下来的章节中会深入学习这些原则。
OCP:开闭原则
开闭原则(OCP)是 Bertrand Meyer在1988年提出的,该设计原则认为:
设计良好的计算机软件应该易于扩展,同时抗拒修改。
换句话说,一个设计良好的计算机系统应该在不需要修改的前提下就可以轻易被扩展。
其实这也是我们研究软件架构的根本目的。如果对原始需求的小小延伸就需要对原有的软件系统进行大幅修改,那么这个系统的架构设计显然是失败的。
尽管大部分软件设计师都已经认可了OCP是设计类与模块时的重要原则,但是在软件架构层面,这项原则的意义则更为重大。
下面,让我们用一个思想实验来做一些说明。
思想实验
假设我们现在要设计一个在Web页面上展示财务数据的系统,页面上的数据要可以滚动显示,其中负值应显示为红色。
接下来,该系统的所有者又要求同样的数据需要形成一个报表,该报表要能用黑白打印机打印,并且其报表格式要得到合理分页,每页都要包含页头、页尾及栏目名。同时,负值应该以括号表示。
显然,我们需要增加一些代码来完成这个要求。但在这里我们更关注的问题是,满足新的要求需要更改多少旧代码。
一个好的软件架构设计师会努力将旧代码的修改需求量降至最小,甚至为0。
但该如何实现这一点呢?我们可以先将满足不同需求的代码分组(即SRP),然后再来调整这些分组之间的依赖关系(即DIP)
利用SRP,我们可以按下图中所展示的方式来处理数据流。即先用一段分析程序处理原始的财务数据,以形成报表的数据结构,最后再用两个不同的报表生成器来产生报表。
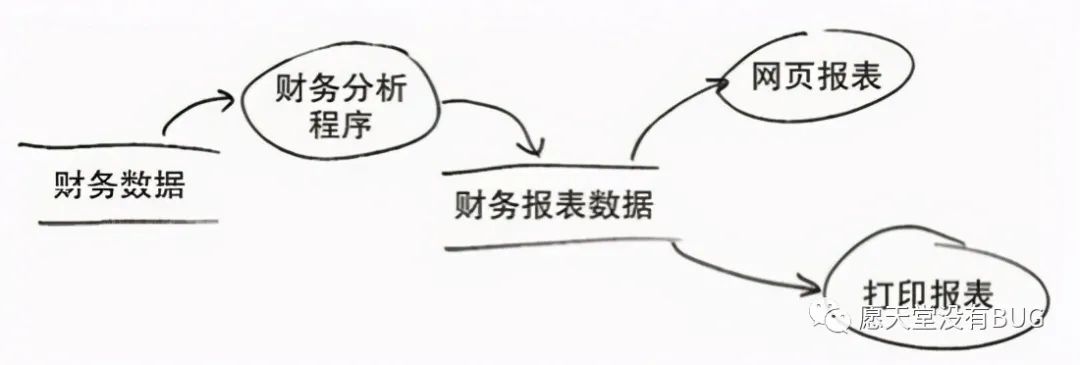
这里的核心就是将应用生成报表的过程拆成两个不同的操作。即先计算出报表数据,再生成具体的展示报表(分别以网页及纸质的形式展示)。
接下来,我们就该修改其源代码之间的依赖关系了。这样做的目的是保证其中一个操作被修改之后不会影响到另外一个操作。同时,我们所构建的新的组织形式应该保证该程序后续在行为上的扩展都无须修改现有代码。
在具体实现上,我们会将整个程序进程划分成一系列的类,然后再将这些类分割成不同的组件。下面,我们用下图中的那些双线框来具体描述一下整个实现。在这个图中,左上角的组件是Controller,右上角是 Interactor,右下角是Database,左下角则有四个组件分别用于代表不同的 Presente和VieW。
在图中,用“I”标记的类代表接口,用 标记的则代表数据结构;开放箭头指代的是使用关系,闭合箭头则指代了实现与继承关系。

首先,我们在图中看到的所有依赖关系都是其源代码中存在的依赖关系。这里,从类A指向类B的箭头意味着A的源代码中涉及了B,但是B的源代码中并不涉及A。因此在图中,FinancialDataMapper在实现接口时需要知道FinancialDataGateway的实现,而FinancialDataGateway则完全不必知道FinancialDataMapper的实现。
其次,这里很重要的一点是这些双线框的边界都是单向跨越的。也就是说,上图中所有组件之间的关系都是单向依赖的,如下图所示,图中的箭头都指向那些我们不想经常更改的组件。

让我们再来复述一下这里的设计原则:如果A组件不想被B组件上发生的修改所影响,那么就应该让B组件依赖于A组件。
所以现在的情况是,我们不想让发生在 Presenter上的修改影响到 Controller,也不想让发生在view上的修改影响到 Presenter。而最关键的是,我们不想让任何修改影响到 Interactor。
其中, Interactor组件是整个系统中最符合OCP的。发生在 Database、 Controller、 Presenter甚至view上的修改都不会影响到 Interactor。
为什么 interactor会被放在这么重要的位置上呢?因为它是该程序的业务逻辑所在之处, Interactor中包含了其最高层次的应用策略。其他组件都只是负责处理周边的辅助逻辑,只有 Interactor才是核心组件。
虽然 Controller组件只是 interactor的附属品,但它却是 Presenter和vew所服务的核心。同样的,虽然 Presenter组件是 Controller的附属品,但它却是view所服务的核心。
另外需要注意的是,这里利用“层级”这个概念创造了一系列不同的保护层级。譬如, Interactor是最高层的抽象,所以它被保护得最严密,而Presenter比view的层级高,但比 Controller和Interactor的层级低。
以上就是我们在软件架构层次上对OCP这一设计原则的应用。软件架构师可以根据相关函数被修改的原因、修改的方式及修改的时间来对其进行分组隔离,并将这些互相隔离的函数分组整理成组件结构,使得高阶组件不会因低阶组件被修改而受到影响。
依赖方向的控制
如果刚刚的类设计把你吓着了,别害怕!你刚刚在图表中所看到的复杂度是我们想要对组件之间的依赖方向进行控制而产生的。
例如,FinancialReportGenerator和FinancialDataMapper之间的FinancialDataGateway接口是为了反转 interactor与Database之间的依赖关系而产生的。同样的,FinancialReportPresente接口与两个View接口之间也类似于这种情况。
信息隐藏
当然, FinancialReportRequester接口的作用则完全不同,它的作用是保护FinancialReportController不过度依赖于Interactor的内部细节。如果没有这个接口,则Controller将会传递性地依赖于 Financialentities。
这种传递性依赖违反了“软件系统不应该依赖其不直接使用的组件”这一基本原则。之后,我们会在讨论接口隔离原则和共同复用原则的时候再次提到这一点。
所以,虽然我们的首要目的是为了让 Interactor屏蔽掉发生在 Controller上的修改,但也需要通过隐藏 Interactor内部细节的方法来让其屏蔽掉来自Controller的依赖。
本章小结
OCP是我们进行系统架构设计的主导原则,其主要目标是让系统易于扩展,同时限制其每次被修改所影响的范围。实现方式是通过将系统划分为一系列组件,并且将这些组件间的依赖关系按层次结构进行组织,使得高阶组件不会因低阶组件被修改而受到影响。
LSP:里氏替换原则
1988年, Barbara liskov在描述如何定义子类型时写下了这样一段话:
这里需要的是一种可替换性:如果对于每个类型是S的对象o1都存在一个类型为T的对象o2,能使操作T类型的程序P在用o2替换o1时行为保持不变,我们就可以将S称为T的子类型。
为了让读者理解这段话中所体现的设计理念,也就是里氏替换原则(LSP),我们可以来看几个例子。
继承的使用指导
假设我们有一个 License类,其结构如下图所示。该类中有一个名为 callee()的方法,该方法将由Billing应用程序来调用。而 License类有两个“子类型” :PersonalLicense与 Businesslicense,这两个类会用不同的算法来计算授权费用。
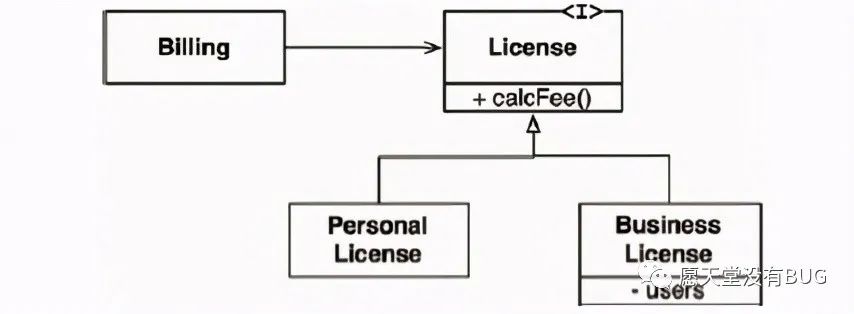
上述设计是符合LSP原则的,因为 Billing应用程序的行为并不依赖于其使用的任何一个衍生类。也就是说,这两个衍生类的对象都是可以用来替换License类对象的。
正方形/长方形问题
正方形/长方形问题是一个著名(或者说臭名远扬)的违反LSP的设计案例。
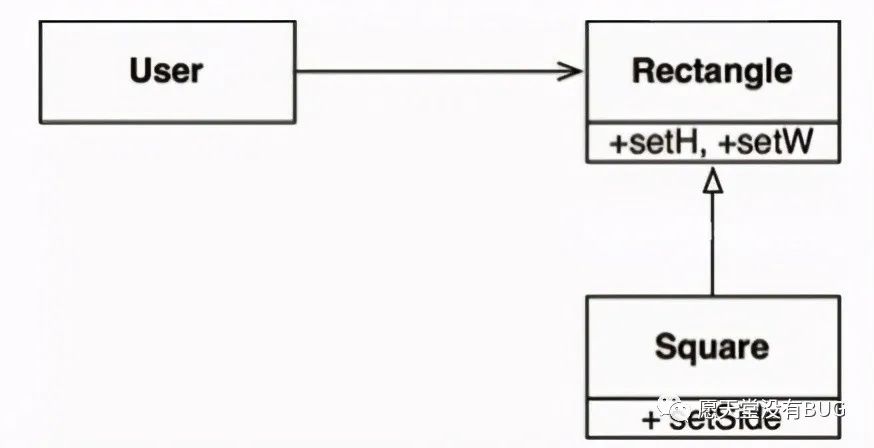
在这个案例中, Square类并不是 Rectangle类的子类型,因为 Rectangle类的高和宽可以分别修改,而 Square类的高和宽则必须一同修改。由于User类始终认为自己在操作 Rectangle类,因此会带来一些混淆。例如在下面的代码中:
Rectangle r
r.setw(5)
r.setH(2)
assert( rarea()==10)很显然,如果上述代码在…处返回的是 Square类,则最后的这个 assert是不会成立的。
如果想要防范这种违反LSP的行为,唯一的办法就是在User类中增加用于区分 Rectangle和 Square的检测逻辑(例如增加if语句)。但这样一来,User类的行为又将依赖于它所使用的类,这两个类就不能互相替换了。
LSP与软件架构
在面向对象这场编程革命兴起的早期,我们的普遍认知正如上文所说,认为LSP只不过是指导如何使用继承关系的一种方法,然而随着时间的推移,LSP逐渐演变成了一种更广泛的、指导接口与其实现方式的设计原则。
这里提到的接口可以有多种形式——可以是Java风格的接口,具有多个实现类;也可以像Ruby一样,几个类共用一样的方法签名,甚至可以是几个服务响应同一个REST接口。
LSP适用于上述所有的应用场景,因为这些场景中的用户都依赖于一种接口,并且都期待实现该接口的类之间能具有可替换性。
想要从软件架构的角度来理解LSP的意义,最好的办法还是来看几个反面案例。
违反LSP的案例
假设我们现在正在构建一个提供出租车调度服务的系统。在该系统中,用户可以通过访问我们的网站,从多个出租车公司内寻找最适合自己的出租车。当用户选定车子时,该系统会通过调用 restful服务接口来调度这辆车。
接下来,我们再假设该 restful调度服务接口的UR被存储在司机数据库中。一旦该系统选中了最合适的出租车司机,它就会从司机数据库的记录中读取相应的URI信息,并通过调用这个URI来调度汽车。
也就是说,如果司机Bob的记录中包含如下调度URI:
purplecab. com/driver/ Bob那么,我们的系统就会将调度信息附加在这个URI上,并发送这样一个PUT请求:
purplecab. com/driver/Bob
/pickup Address/24 Maple St
/pickupTime/153
/destination/ORD很显然,这意味着所有参与该调度服务的公司都必须遵守同样的REST接口,它们必须用同样的方式处理 pickupAddress、 pickup Time和 destination字段。
接下来,我们再假设Acme出租车公司现在招聘的程序员由于没有仔细阅读上述接口定义,结果将destination字段缩写成了dest。而Acme又是本地最大的出租车公司,另外, Acme CEO的前妻不巧还是我们CEO的新欢……你懂的!这会对系统的架构造成什么影响呢?
显然,我们需要为系统増加一类特殊用例,以应对Acme司机的调度请求。而这必须要用另外一套规则来构建。
最简单的做法当然是增加一条i语句:
if(driver.getDispatchUri().startsWith(“acme.com))...然而很明显,任何一个称职的软件架构师都不会允许这样一条语句出现在自己的系统中。因为直接将“acme“这样的字串写入代码会留下各种各样神奇又可怕的错误隐患,甚至会导致安全问题。
例如,Acme也许会变得更加成功,最终收购了Purple出租车公司。然后,它们在保留了各自名字的同时却统一了彼此的计算机系统。在这种情况下,系统中难道还要再增加一条“ purple“的特例吗?
软件架构师应该创建一个调度请求创建组件,并让该组件使用一个配置数据库来保存URI组装格式,这样的方式可以保护系统不受外界因素变化的影响。例如其配置信息可以如下

但这样一来,软件架构师就需要通过増加一个复杂的组件来应对并不完全能实现互相替换的 restful服务接口。
本章小结
LSP可以且应该被应用于软件架构层面,因为一旦违背了可替换性,该系统架构就不得不为此増添大量复杂的应对机制。
ISP:接口隔离原则
“接口隔离原则”这个名字来自下图所示的这种软件结构。
在图中所描绘的应用中,有多个用户需要操作OPS类。现在,我们假设这里的User1只需要使用op1,User2只需要使用op2,User3只需要使用op3。
在这种情况下,如果OPS类是用Java编程语言编写的,那么很明显,User1虽然不需要调用op2、op3,但在源代码层次上也与它们形成依赖关系。
这种依赖意味着我们对OPS代码中op2所做的任何修改,即使不会影响到User1的功能,也会导致它需要被重新编译和部署。
这个问题可以通过将不同的操作隔离成接口来解决,具体如下图所示。

同样,我们也假设这个例子是用Java这种静态类型语言来实现的,那么现在User1的源代码会依赖于U1Ops和op1,但不会依赖于OPS。这样一来,我们之后对OPS做的修改只要不影响到User1的功能,就不需要重新编译和部署User1了。
ISP与编程语言
很明显,上述例子很大程度上也依赖于我们所采用的编程语言。对于Java这样的静态类型语言来说,它们需要程序员显式地 Import、use或者 include其实现功能所需要的源代码。而正是这些语句带来了源代码之间的依赖关系,这也就导致了某些模块需要被重新编译和重新部署。
而对于Ruby和 Python这样的动态类型语言来说,源代码中就不存在这样的声明,它们所用对象的类型会在运行时被推演出来,所以也就不存在强制重新编译和重新部署的必要性。这就是动态类型语言要比静态类型语言更灵活、耦合度更松的原因。
当然,如果仅仅就这样说的话,读者可能会误以为ISP只是一个与编程语言的选择紧密相关的设计原则而非软件架构问题,这就错了。
ISP与软件架构
回顾一下ISP最初的成因:在一般情况下,任何层次的软件设计如果依赖于不需要的东西,都会是有害的。从源代码层次来说,这样的依赖关系会导致不必要的重新编译和重新部署,对更高层次的软件架构设计来说,问题也是类似的。
例如,我们假设某位软件架构师在设计系统S时,想要在该系统中引入某个框架F。这时候,假设框架F的作者又将其捆绑在一个特定的数据库D上,那么就形成了S依赖于F,F又依赖于D的关系。
在这种情况下,如果D中包含了F不需要的功能,那么这些功能同样也会是S不需要的。而我们对D中这些功能的修改将会导致F需要被重新部署,后者又会导致S的重新部署。更糟糕的是,D中一个无关功能的错误也可能会导致F和S运行出错。
本章小结
本章所讨论的设计原则告诉我们:任何层次的软件设计如果依赖了它并不需要的东西,就会带来意料之外的麻烦。
DIP:依赖反转原则
依赖反转原则(DIP)主要想告诉我们的是,如果想要设计一个灵活的系统,在源代码层次的依赖关系中就应该多引用抽象类型,而非具体实现。
也就是说,在Java这类静态类型的编程语言中,在使用use、 Import、 include这些语句时应该只引用那些包含接口、抽象类或者其他抽象类型声明的源文件,不应该引用任何具体实现。
同样的,在Ruby、 Python这类动态类型的编程语言中,我们也不应该在源代码层次上引用包含具体实现的模块。当然,在这类语言中,事实上很难清晰界定某个模块是否属于“具体实现′。
显而易见,把这条设计原则当成金科玉律来加以严格执行是不现实的,因为软件系统在实际构造中不可避免地需要依赖到一些具体实现。例如,Java中的 String类就是这样一个具体实现,我们将其强迫转化为抽象类是不现实的,而在源代码层次上也无法避免对 java.lang.String的依赖,并且也不应该尝试去避免。
但 String类本身是非常稳定的,因为这个类被修改的情况是非常罕见的,而且可修改的内容也受到严格的控制,所以程序员和软件架构师完全不必担心String类上会发生经常性的或意料之外的修改。
同理,在应用DIP时,我们也不必考虑稳定的操作系统或者平台设施,因为这些系统接口很少会有变动。
我们主要应该关注的是软件系统内部那些会经常变动的( volatile)具体实现模块,这些模块是不停开发的,也就会经常出现变更。
稳定的抽象层
我们每次修改抽象接口的时候,一定也会去修改对应的具体实现。但反过来,当我们修改具体实现时,却很少需要去修改相应的抽象接口。所以我们可以认为接口比实现更稳定。
的确,优秀的软件设计师和架枃师会花费很大精力来设计接口,以减少未来对其进行改动。毕竟争取在不修改接口的情况下为软件增加新的功能是软件设计的基础常识。
也就是说,如果想要在软件架构设计上追求稳定,就必须多使用稳定的抽象接口,少依赖多变的具体实现。下面,我们将该设计原则归结为以下几条具体的编码守则:
应在代码中多使用抽象接口,尽量避免使用那些多变的具体实现类。这条守则适用于所有编程语言无论静态类型语言还是动态类型语言。同时,对象的创建过程也应该受到严格限制,对此,我们通常会选择用抽象工厂( abstract factory)这个设计模。
不要在具体实现类上创建衍生类。上一条守则虽然也隐含了这层意思,但它还是值得被单独拿出来做次详细声明。在静态类型的编程语言中,继承关系是所有一切源代码依赖关系中最强的、最难被修改的,所以我们对继承的使用应该格外小心。即使是在稍微便于修改的动态类型语言中,这条守则也应该被认真考虑。
不要覆盖( override)包含具体实现的函数。调用包含具体实现的函数通常就意味着引入了源代码级别的依赖。即使覆盖了这些函数,我们也无法消除这其中的依赖——这些函数继承了那些依赖关系在这里,控制依赖关系的唯一办法,就是创建一个抽象函数,然后再为该函数提供多种具体实现。
应避免在代码中写入与任何具体实现相关的名字或者是其他容易变动的事物的名字。这基本上是DIP原则的另外一个表达方式。
工厂模式
如果想要遵守上述编码守则,我们就必须要对那些易变对象的创建过程做一些特殊处理,这样的谨慎是很有必要的,因为基本在所有的编程语言中,创建对象的操作都免不了需要在源代码层次上依赖对象的具体实现。
在大部分面向对象编程语言中,人们都会选择用抽象工厂模式来解决这个源代码依赖的问题。
下面,我们通过下图来描述一下该设计模式的结构。如你所见, Application类是通过 Service接口来使用 Concretelmp类的。然而, Application类还是必须要构造 Concretelmpl类实例。于是,为了避免在源代码层次上引入对 Concretelmpl类具体实现的依赖,我们现在让 Application类去调用ServiceFactory接口的 makeSvc方法。这个方法就由 ServiceFactorylmpl类来具体提供,它是ServiceFactoryl的一个衍生类。该方法的具体实现就是初始化一个 Concretelmpl类的实例,并且将其以 Service类型返回。

中间的那条曲线代表了软件架构中的抽象层与具体实现层的边界。在这里,所有跨越这条边界源代码级别的依赖关系都应该是单向的,即具体实现层依赖抽象层。
这条曲线将整个系统划分为两部分组件:抽象接口与其具体实现。抽象接口组件中包含了应用的所有高阶业务规则,而具体实现组件中则包括了所有这些业务规则所需要做的具体操作及其相关的细节信息。
请注意,这里的控制流跨越架构边界的方向与源代码依赖关系跨越该边界的方向正好相反,源代码依赖方向永远是控制流方向的反转——这就是DIP被称为依赖反转原则的原因。
具体实现组件
在上图中,具体实现组件的内部仅有一条依赖关系,这条关系其实是违反DIP的。这种情况很常见,我们在软件系统中并不可能完全消除违反DIP的情况。通常只需要把它们集中于少部分的具体实现组件中,将其与系统的其他部分隔离即可。
绝大部分系统中都至少存在一个具体实现组件我们一般称之为main组件,因为它们通常是main函数所在之处。在图中,main函数应该负责创建 ServiceFactorylmp实例,并将其赋值给类型为 ServiceFactory的全局变量,以便让 Application类通过这个全局变量来进行相关调用。
本章小结
在系统架构图中,DIP通常是最显而易见的组织原则。我们把图中的那条曲线称为架构边界,而跨越边界的、朝向抽象层的单向依赖关系则会成为一个设计守则——依赖守则。
以上就是有关设计原则的学习笔记,希望可以对大家学习设计模式有所帮助,喜欢的小伙伴可以帮忙转发+关注,感谢大家!Lz也会不定时的更新干货的!
原文链接:
https://www.tuicool.com/articles/VjA3mqI