
GPT-4的多模态能力是如何实现的?
 点蓝色字关注
点蓝色字关注
“机器学习算法工程师
”
设为
星标
,干货直达!
相比ChatGPT,OpenAI最新发布的GPT-4不仅增强了原来的文本生成能力,还支持了多模态能力。GPT-4不仅支持纯文本输入,还支持输入图像,当输入图像时,GPT-4可以生成理解图像的文本回答。下面是GPT-4技术报告中的一个具体示例,这里给定一个图像,模型能够准确找到图像中不正常的现象,可见GPT-4的图像理解能力还是非常强的。 虽然OpenAI展示了GPT-4的视觉理解能力,但是在技术报告中并没有给出实现的具体细节,而且这项功能还处于研究中,并没有对外开放。我想大部分人会对GPT-4的多模态能力比较感兴趣,因为要想实现AGI(通用人工智能),AI必须要掌握多模态理解能力。虽然OpenAI没有给出技术细节,但是其实最近已经有一些工作尝试实现类似的能力,比如最近刚开源的MiniGPT-4。这篇文章我们将简单讲解四个相关的工作,看看它们是如何在语言模型中嵌入视觉理解能力的,这4个工作是:
虽然OpenAI展示了GPT-4的视觉理解能力,但是在技术报告中并没有给出实现的具体细节,而且这项功能还处于研究中,并没有对外开放。我想大部分人会对GPT-4的多模态能力比较感兴趣,因为要想实现AGI(通用人工智能),AI必须要掌握多模态理解能力。虽然OpenAI没有给出技术细节,但是其实最近已经有一些工作尝试实现类似的能力,比如最近刚开源的MiniGPT-4。这篇文章我们将简单讲解四个相关的工作,看看它们是如何在语言模型中嵌入视觉理解能力的,这4个工作是:
Flamingo: a Visual Language Model for Few-Shot Learning
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
LLaVA: Visual Instruction Tuning
这里除了DeepMind的Flamingo,其它3个工作都是开源的,其中后面两个MiniGPT-4和LLaVA是最近的工作。在讲解这4个工作之前,其实我们也可以先简单想一下具体的实现思路,注意这里我们不是直接训练一个多模态模型(目前也没有那么大的多模态数据来训练,我想OpenAI也不是那么做的),而是在已经预训练好的语言大模型中引入图像理解能力。所以这里大概要需要这两点:
首先,我们必须得有个预训练好的视觉模型,它可以用来提取图像的语义特征,而且图像的特征能够很好地嵌入预训练好的语言模型中,我能想到的最合适的模型就是OpenAI所提出的CLIP,CLIP的image encoder能够输出和文本对其的特征。
然后,我们要有一个包含图像和文本的多模态数据集,这个数据集用来finetune模型,由于这里我们只是支持图像输入,而本身的任务还是文本生成,所以训练损失还是采用语言模型的language modeling loss,即根据前面的输入预测下一个token。
我们将要介绍的这4个工作其实也主要来围绕着上面两点来进行实现的。
Flamingo
DeepMind的Flamingo这个工作是在22年4月发表的,也算是比较早的工作。Flamingo模型是一个可以输入图像(也支持视频)和文本来生成文本的多模态模型。它的模型架构如下所示: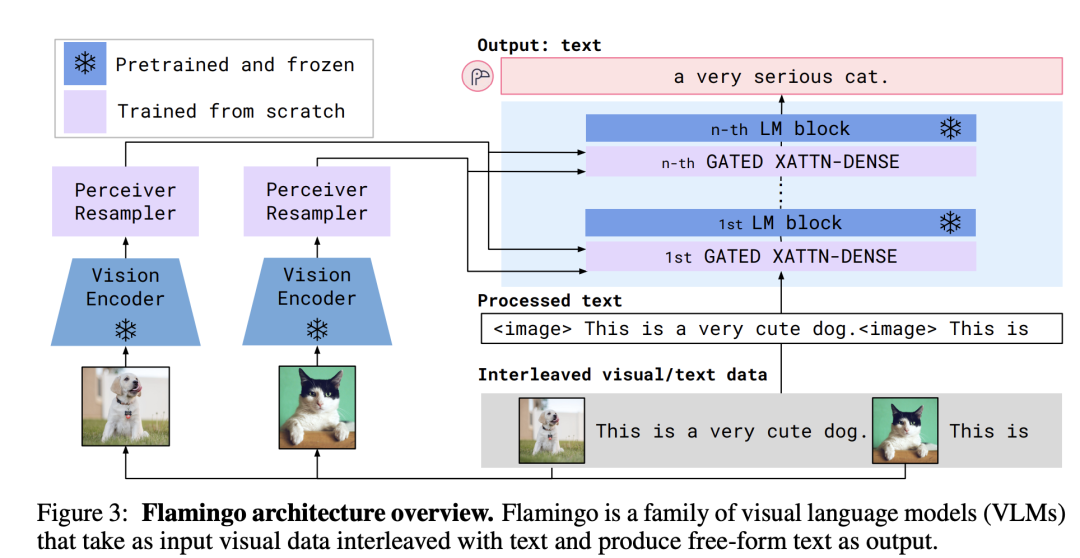 首先,Flamingo模型是建立在一个预训练好的语言模型基础上的,它这里选择的模型是DeepMind之前所提出的Chinchilla,最大的Chinchilla模型参数量虽然只有70B,但是训练的Tokens数量却比GPT-3多:
首先,Flamingo模型是建立在一个预训练好的语言模型基础上的,它这里选择的模型是DeepMind之前所提出的Chinchilla,最大的Chinchilla模型参数量虽然只有70B,但是训练的Tokens数量却比GPT-3多: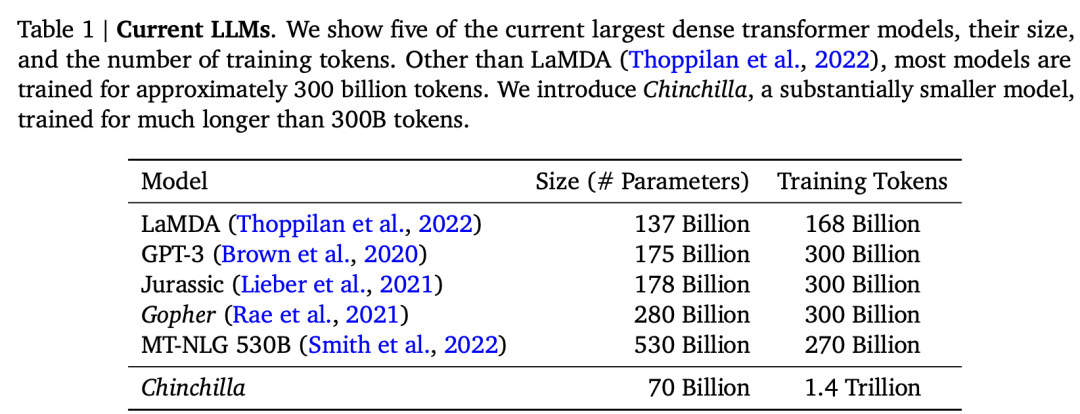 然后,Flamingo模型又引入了一个预训练好的Vision Encoder,这个视觉模型采用的是DeepMind在21年所提出的NFNet-F6(其实是没有Normalization的ResNet),不过这个模型是采用CLIP对比损失在图像文本对数据集上预训练的,所以它提出的特征其实和文本是有一定对齐的,这里采用模型最后一个stage的输出的特征,它是一个2D(有空间结构)特征,可以将它展开为1D的序列特征。前面说过,Flamingo模型也是支持视频输入的,对于视频数据,可以采用Vision Encoder逐帧来提取特征,可以得到一个3D特征,然后加上一个可学习的temporal embeddings(编码时间维度),最后也可以展开为1D的序列特征。虽然图像和视频最终都得到了1D序列,但是它们的长度是不同的,为了解决这个问题,DeepMind又引入了一个新的模块Perceiver Resampler:
然后,Flamingo模型又引入了一个预训练好的Vision Encoder,这个视觉模型采用的是DeepMind在21年所提出的NFNet-F6(其实是没有Normalization的ResNet),不过这个模型是采用CLIP对比损失在图像文本对数据集上预训练的,所以它提出的特征其实和文本是有一定对齐的,这里采用模型最后一个stage的输出的特征,它是一个2D(有空间结构)特征,可以将它展开为1D的序列特征。前面说过,Flamingo模型也是支持视频输入的,对于视频数据,可以采用Vision Encoder逐帧来提取特征,可以得到一个3D特征,然后加上一个可学习的temporal embeddings(编码时间维度),最后也可以展开为1D的序列特征。虽然图像和视频最终都得到了1D序列,但是它们的长度是不同的,为了解决这个问题,DeepMind又引入了一个新的模块Perceiver Resampler: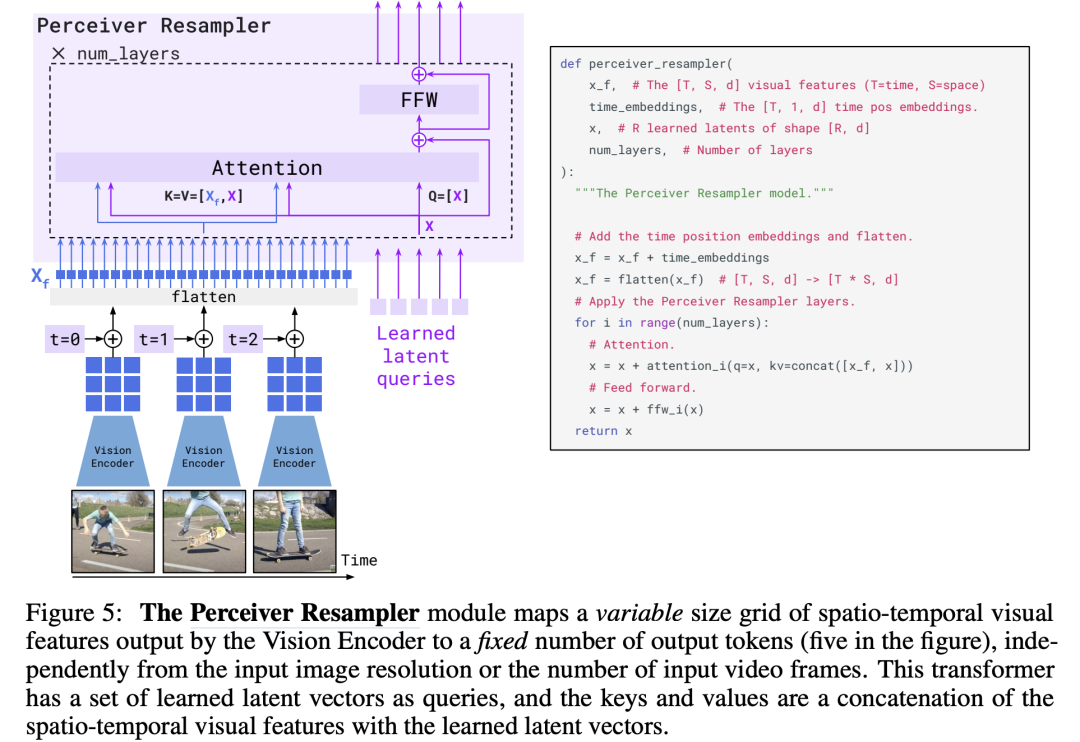 这个Perceiver Resampler可以接受变长度的视觉特征,但是最终输出的是固定长度的特征,其实现思路也很简单,首先我们预定义固定长度的latent input queries,然后通过对Vision Encoder提取的特征进行cross-attention来提取固定长度的视觉特征。那么如何将视觉特征嵌入语言模型中呢?DeepMind这里采用的方式是cross-attention,这是一种最常用的方法了。不过,这里所引入的是GATED XATTN-DENSE layers,它和常规的cross-attention略有不同:
这个Perceiver Resampler可以接受变长度的视觉特征,但是最终输出的是固定长度的特征,其实现思路也很简单,首先我们预定义固定长度的latent input queries,然后通过对Vision Encoder提取的特征进行cross-attention来提取固定长度的视觉特征。那么如何将视觉特征嵌入语言模型中呢?DeepMind这里采用的方式是cross-attention,这是一种最常用的方法了。不过,这里所引入的是GATED XATTN-DENSE layers,它和常规的cross-attention略有不同: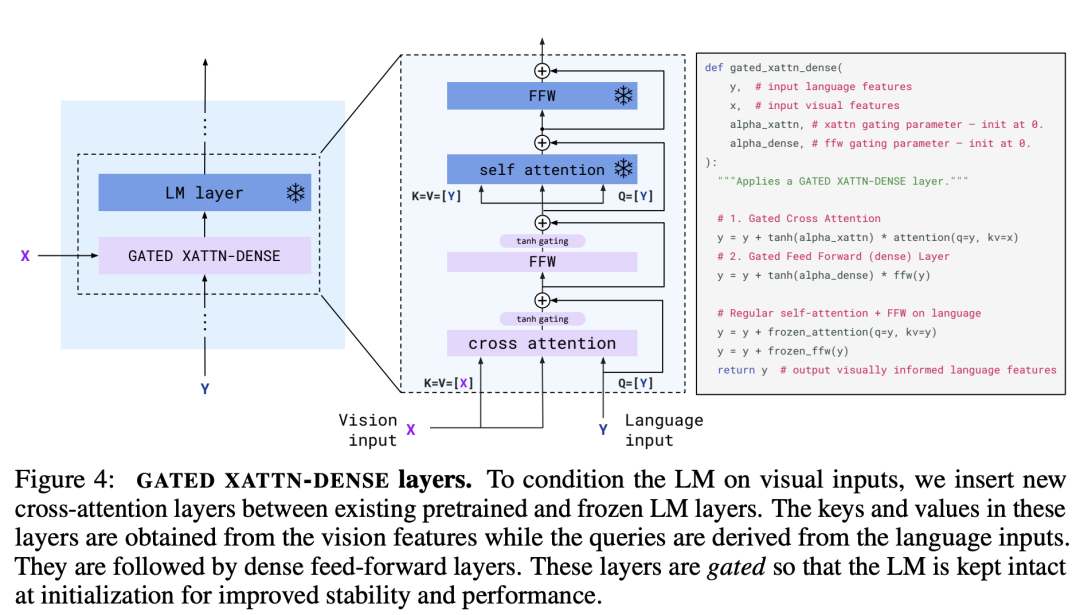 如上所示,可以看到这里是一种gated cross-attention,这里的alpha_xattn是一个可以学习的参数,初始为0,那么初始模型和原来的语言模型输出是一样的。可以看到Flamingo模型共包含4个部分:预训练好的LM和Vision Encoder,以及新引入的Perceiver Resampler和gated cross-attention layers,训练过程前两个部分是冻结的,只有后两个模块是训练的。训练Flamingo模型所采用的训练数据集是文本和图像交叠的多模态数据集,如下图所示:
如上所示,可以看到这里是一种gated cross-attention,这里的alpha_xattn是一个可以学习的参数,初始为0,那么初始模型和原来的语言模型输出是一样的。可以看到Flamingo模型共包含4个部分:预训练好的LM和Vision Encoder,以及新引入的Perceiver Resampler和gated cross-attention layers,训练过程前两个部分是冻结的,只有后两个模块是训练的。训练Flamingo模型所采用的训练数据集是文本和图像交叠的多模态数据集,如下图所示: 这其实包含3个部分,首先是M3W数据集,这是从互联网上收集的图像和文本交叠的数据集,上图的第3个是一个具体的示例。另外两部分是图像-文本对和视频-文本对,它们也可以构造成和M3W一样的格式,如上图的第1个和第2个。由于样本中可能包含不同数量的图像(或者视频),这里为了使得Flamingo模型适配这样的可变输入,每个text token其实只cross-attention一个图像/视频特征:只用它前面最近的图像/视频,如下所示:
这其实包含3个部分,首先是M3W数据集,这是从互联网上收集的图像和文本交叠的数据集,上图的第3个是一个具体的示例。另外两部分是图像-文本对和视频-文本对,它们也可以构造成和M3W一样的格式,如上图的第1个和第2个。由于样本中可能包含不同数量的图像(或者视频),这里为了使得Flamingo模型适配这样的可变输入,每个text token其实只cross-attention一个图像/视频特征:只用它前面最近的图像/视频,如下所示:
 Flamingo模型主打的是它的few-shot能力,就是给定一些任务示例,然后可以对同样的任务做出回答,其实这个和GPT-3采用同样的思路,即构建prompt模版,如下所示:
Flamingo模型主打的是它的few-shot能力,就是给定一些任务示例,然后可以对同样的任务做出回答,其实这个和GPT-3采用同样的思路,即构建prompt模版,如下所示: 下面是一些具体的示例:
下面是一些具体的示例: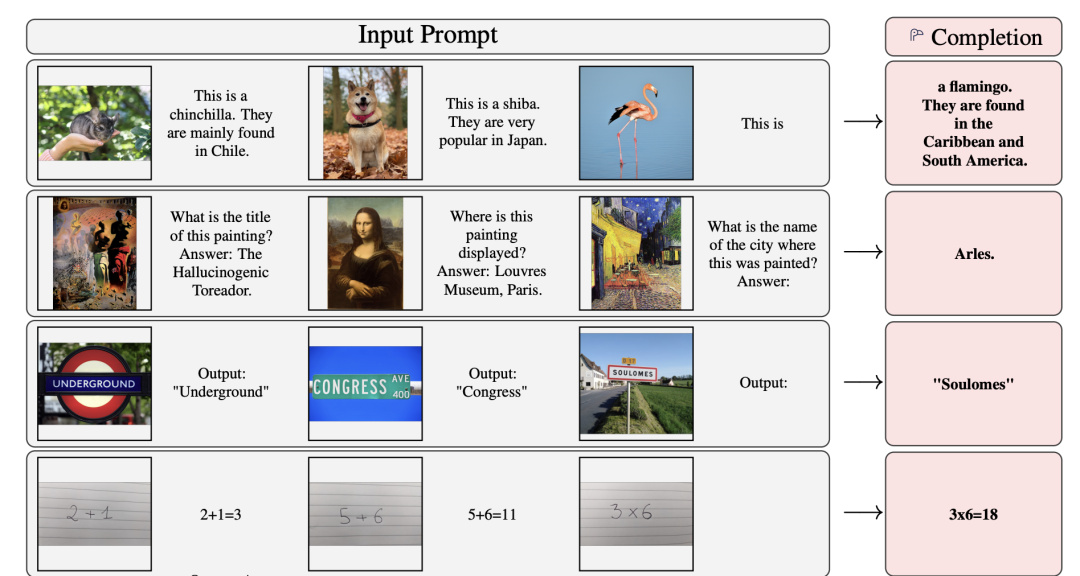 除了这种few-shot能力,其实Flamingo模型也有一定的zero-shot能力,如下所示:
除了这种few-shot能力,其实Flamingo模型也有一定的zero-shot能力,如下所示: 同时,Flamingo模型也可以进行多轮对话:
同时,Flamingo模型也可以进行多轮对话: 虽然看起来Flamingo模型设计的比较复杂,但是它却是一个全能型选手,支持多图片输入,而且也支持视频。不过DeepMind并没有将这个模型开源,但是最近LAION实现了一个开源版本的OpenFlamingo,它的语言模型采用的是LLaMA,而Vision Encoder采用的是CLIP ViT/L-14,同时它们也构建了图像和文本交叠的数据集Multimodal C4来训练模型。
虽然看起来Flamingo模型设计的比较复杂,但是它却是一个全能型选手,支持多图片输入,而且也支持视频。不过DeepMind并没有将这个模型开源,但是最近LAION实现了一个开源版本的OpenFlamingo,它的语言模型采用的是LLaMA,而Vision Encoder采用的是CLIP ViT/L-14,同时它们也构建了图像和文本交叠的数据集Multimodal C4来训练模型。
BLIP-2
BLIP-2是23年1月份的工作,也算是比较新的工作,我个人觉得它应该是借鉴了DeepMind的Flamingo模型,它也是采用了一个预训练好的语言模型和视觉模型,并设计了一个Q-Former模块来连接两者,整体结构如下所示: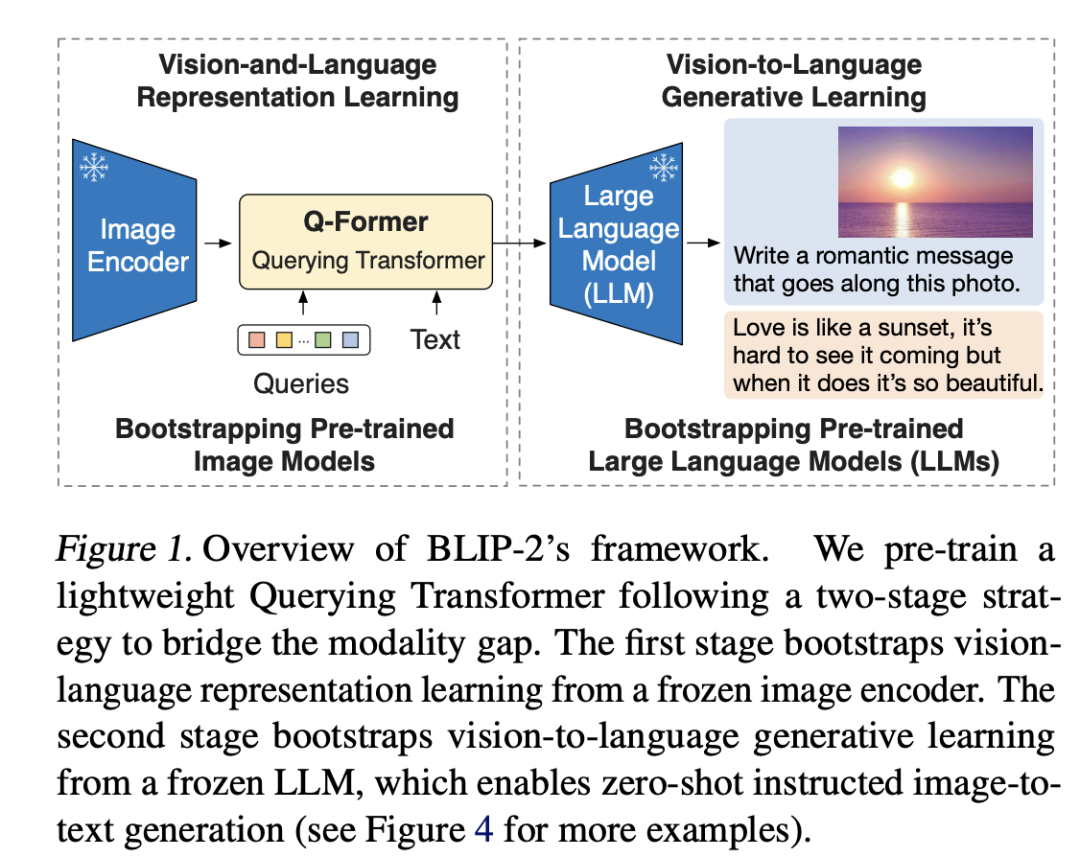 BLIP-2的Q-Former模块和Flamingo模型的Perceiver Resampler模块有点类似,它也是用来从Image Encoder提取的视觉特征中得到固定长度的特征。Q-Former模块包含两个transformer子模块,它们是共享self-attention层的,如下图所示:
BLIP-2的Q-Former模块和Flamingo模型的Perceiver Resampler模块有点类似,它也是用来从Image Encoder提取的视觉特征中得到固定长度的特征。Q-Former模块包含两个transformer子模块,它们是共享self-attention层的,如下图所示: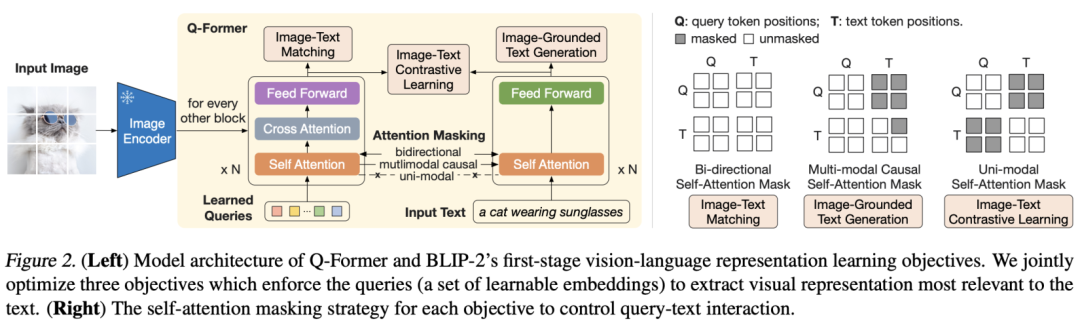 第一个transformer模块是一个image transformer模型,这里预先定义了固定数量(论文中设定为32)的learned queries作为输入,然后在transformer模块中引入cross-attention来和Image Encoder得到的特征进行交互。第二个transformer模块是一个text transformer模型,输入是text,它与image transformer共享self-attention层。Q-Former采用轻量级的transformer,具体的是采用188M参数的BERT-base,也使用了BERT预训练权重进行初始化。与Flamingo模型不同的是,Q-Former模块采用了两阶段的训练策略来将这个模块提取的特征嵌入到预训练好的LM模型中。第一个阶段主要是从Image Encoder中的特征中学习到与文本对齐的固定长度特征,这个阶段的训练是基于图像-文本对数据集来进行训练的。训练采用了3种优化目标:
第一个transformer模块是一个image transformer模型,这里预先定义了固定数量(论文中设定为32)的learned queries作为输入,然后在transformer模块中引入cross-attention来和Image Encoder得到的特征进行交互。第二个transformer模块是一个text transformer模型,输入是text,它与image transformer共享self-attention层。Q-Former采用轻量级的transformer,具体的是采用188M参数的BERT-base,也使用了BERT预训练权重进行初始化。与Flamingo模型不同的是,Q-Former模块采用了两阶段的训练策略来将这个模块提取的特征嵌入到预训练好的LM模型中。第一个阶段主要是从Image Encoder中的特征中学习到与文本对齐的固定长度特征,这个阶段的训练是基于图像-文本对数据集来进行训练的。训练采用了3种优化目标:
**Image-Text Contrastive Learning (ITC)**:这个优化目标采用对比损失来对齐图像特征和文本特征,这里的文本特征采用的是text transformer得到的CLS token对应的特征,它首先和每个query特征计算特征相似度,并匹配到相似度最大的那个query特征。注意,这里采用uni-modal self-attention mask,即保证图像和文本在self-attention互相不可见,以防止信息泄露。
**Image-grounded Text Generation (ITG)**:这个优化目标是给定图像特征作为condition来生成文本,这个采用multi-modal causal self-attention mask,即query可以互相attention,但是不attention text,而每个text token可以attention所有的query,并attention它之前的text tokens。
**Image-Text Matching (ITM)**:采用一个二分类任务来对图像和文本特征进行细粒度的对齐,具体是判定一个image-text对是不是匹配的,这里采用的是bi-directional self-attention mask,即所有的query和text token都可以互相attention。
总之,这个阶段其实是希望通过这三个多模态优化目标让Q-Former模块从Image Encoder提取到和文本相关的固定长度特征。其实BLIP-2所采用的Image Encoder是OpenAI的CLIP-L/14或EVA-CLIP ViT-G/14(采用ViT倒数第2层输出),它们输出的特征本身就是多模态特征,所以第一阶段的对齐可以看成是一个增强。BLIP-2的第二个阶段是将Q-Former提取的图像特征和预训练好的LLM连接在一起,这里不是像Flamingo模型那样采用cross-attention,而是直接采用一个全连接层将特征映射到LLM的特征空间(和LLM的text embeddings同维度),这个映射后的特征可以看成是 soft visual prompts,它可以像文本一样直接输入到LLM模型中,如下图所示: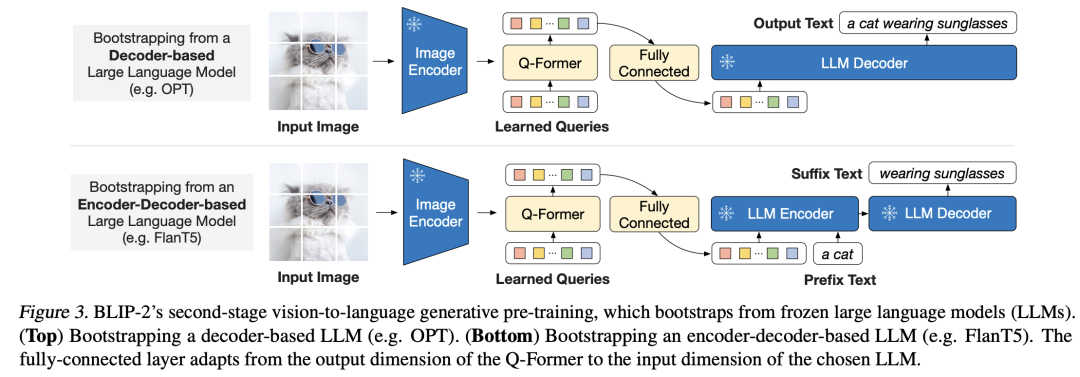 BLIP-2共实验了两种LLM模型:第一种是decoder-based LLM,这里选择的是Meta开源的OPT(开源版本GPT);第二种是 encoder-decoder-based LLM,这里选择的是谷歌开源的FLAN-T5,它是在T5模型基础上进行了instruction finetuning(见Scaling Instruction-Finetuned Language Models)。对于decoder-based LLM,这个阶段的finetune是直接language modeling loss:根据soft visual prompts来生成文本;而对于encoder-decoder-based LLM,则是采用 prefix language modeling loss :将文本拆分成两个部分,第一部分作为prefix text接在soft visual prompts后面,然后送入LLM Encoder,LLM Decoder将据此来生成第二部分文本。注意,这个阶段的训练也是对冻结LLM的,训练数据也是采用图像文本对。相比较Flamingo,BLIP-2的训练是直接在图像文本对数据集上训练的,图像文本对数据集是先收集 129M 图像,然后采用BLIP的caption模型生成对应的文本描述(每个图像生成两个top captions)。但是BLIP-2也能够实现zero-shot的生成,你只需要将text prompt接在soft visual prompts后面就可以了,下面是一些具体的示例:
BLIP-2共实验了两种LLM模型:第一种是decoder-based LLM,这里选择的是Meta开源的OPT(开源版本GPT);第二种是 encoder-decoder-based LLM,这里选择的是谷歌开源的FLAN-T5,它是在T5模型基础上进行了instruction finetuning(见Scaling Instruction-Finetuned Language Models)。对于decoder-based LLM,这个阶段的finetune是直接language modeling loss:根据soft visual prompts来生成文本;而对于encoder-decoder-based LLM,则是采用 prefix language modeling loss :将文本拆分成两个部分,第一部分作为prefix text接在soft visual prompts后面,然后送入LLM Encoder,LLM Decoder将据此来生成第二部分文本。注意,这个阶段的训练也是对冻结LLM的,训练数据也是采用图像文本对。相比较Flamingo,BLIP-2的训练是直接在图像文本对数据集上训练的,图像文本对数据集是先收集 129M 图像,然后采用BLIP的caption模型生成对应的文本描述(每个图像生成两个top captions)。但是BLIP-2也能够实现zero-shot的生成,你只需要将text prompt接在soft visual prompts后面就可以了,下面是一些具体的示例:
论文中比较了BLIP-2在Zero-shot VQA 任务上的性能,如下表所示,这里 BLIP-2 ViT-G FlanT5XXL 的性能要超过 Flamingo80B。另外从表中的对比结果,我们也可以看到:a stronger image encoder or a stronger LLM both lead to better performance。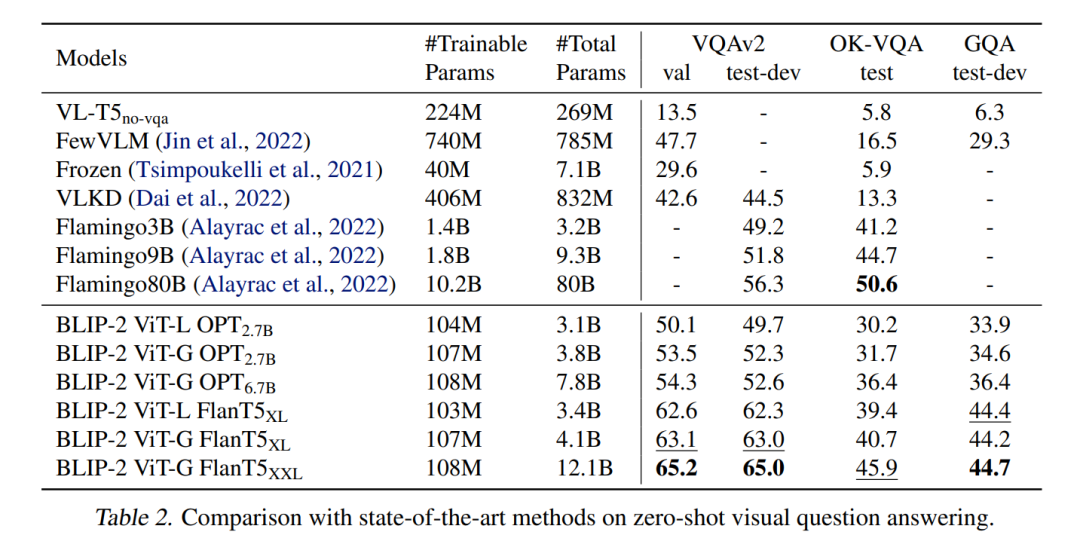
12.1B的BLIP-2之所以能够比80B的Flamingo强,我觉得最主要的原因还是在于视觉特征嵌入到LLM的方式,Flamingo引入了额外的cross-attention层来实现这种嵌入,反而有点破坏了原来的LLM,而BLIP-2这种直接将视觉特征转到LLM特征空间就能够很好的保持原有模型能力。
MiniGPT-4
MiniGPT-4是近期的工作,它其实可以看成是BLIP-2的升级版本。在ChatGPT发布之后,其实已经有越来越多的开源工作来复现ChatGPT的效果,目前很多工作是使用高质量数据在Meta开源的LLaMA进行finetune。所以,MiniGPT-4直接选择了一个效果更好的LLM:Vicuna,它是基于ShareGPT数据集finetune的模型,号称用GPT-4来评测可以达到ChatGPT 90%的水平。它是基于LLaMA-13B进行finetune的,所以又称为Vicuna-13B。MiniGPT-4的模型结构非常简单,如下所示,这里是直接将BLIP-2的预训练好的Q-Former拿过来,这里Image Encoder用的是最大的 EVA-CLIP ViT-G/14模型。这里增加了一个Linear Layer来将Q-Former提取的特征映射到Vicuna的特征空间,得到的 soft prompt 就可以直接嵌入到Vicuna模型中。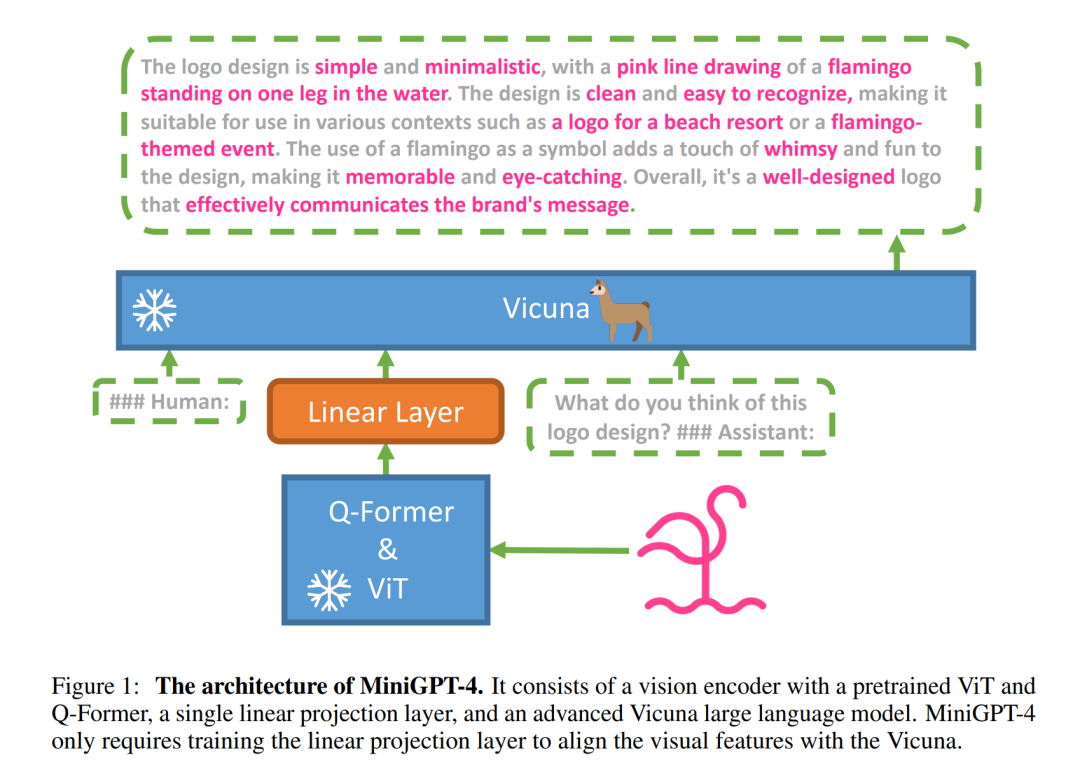 要注意的是,MiniGPT-4这里不仅冻结了Vicuna模型,而且冻结了Q-Former,所以训练参数只剩下一个Linear Layer了。那么重点就是MiniGPT-4是怎么训练的,或者说MiniGPT-4采用了什么样的数据来进行训练。当然,MiniGPT-4也可以简单地像BLIP-2那样采用图像文本对来训练,但是实验发现了这样效果并不太好。相比BLIP-2,MiniGPT-4采用了两阶段的训练策略,这个两阶段和BLIP-2不太一样,其实BLIP-2的第一阶段只是为了得到初步的Q-Former,并没有涉及LLM。MiniGPT-4的第一阶段训练和BLIP-2的第二阶段一样,采用图像文本对数据集进行训练,训练目标是基于soft prompt来生成对应的文本描述,训练数据集是CC、SBU和LAION数据集中筛选的5M样本。完成这个阶段的训练后,虽然模型能够有一定的生成能力,但是它比较难产生连贯的语言,比如生成重复的单词或句子、零散的句子或不相关的内容。论文任务模型需要 instruction fine-tuning或者RLHF,这也是GPT-3到GPT-3.5进化的关键。所以MiniGPT-4的第二阶段构建了一个高质量的图像文本数据集来进行finetune。首先从CC数据集中选择5000张图像,然后使用第一阶段训练好的模型来生成详细的文本描述,这里采用了如下所示的prompt来进行生成:
要注意的是,MiniGPT-4这里不仅冻结了Vicuna模型,而且冻结了Q-Former,所以训练参数只剩下一个Linear Layer了。那么重点就是MiniGPT-4是怎么训练的,或者说MiniGPT-4采用了什么样的数据来进行训练。当然,MiniGPT-4也可以简单地像BLIP-2那样采用图像文本对来训练,但是实验发现了这样效果并不太好。相比BLIP-2,MiniGPT-4采用了两阶段的训练策略,这个两阶段和BLIP-2不太一样,其实BLIP-2的第一阶段只是为了得到初步的Q-Former,并没有涉及LLM。MiniGPT-4的第一阶段训练和BLIP-2的第二阶段一样,采用图像文本对数据集进行训练,训练目标是基于soft prompt来生成对应的文本描述,训练数据集是CC、SBU和LAION数据集中筛选的5M样本。完成这个阶段的训练后,虽然模型能够有一定的生成能力,但是它比较难产生连贯的语言,比如生成重复的单词或句子、零散的句子或不相关的内容。论文任务模型需要 instruction fine-tuning或者RLHF,这也是GPT-3到GPT-3.5进化的关键。所以MiniGPT-4的第二阶段构建了一个高质量的图像文本数据集来进行finetune。首先从CC数据集中选择5000张图像,然后使用第一阶段训练好的模型来生成详细的文本描述,这里采用了如下所示的prompt来进行生成:
###Human: Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
但是这里生成的文本质量可能存在噪音或者错误,所以又基于ChatGPT来对生成的文本进行refine,这里采用的prompt是:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation
另外为了保证数据质量,最后还是人工对ChatGPT美化后的文本进行检查,最终选出了大约3500个样本。然后基于这些样本进行第二阶段finetune,这里首先将数据集按照如下prompt构建:
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
这里的从一些预先定义好的模版中选取,比如“Describe this image in detail” 和 “Could you describe the contents of this image for me”。训练的优化目标就是根据prompt来生成对应的文本。论文里面说第二阶段的finetune非常高效,在batch=12下只需要训练400 steps就可以了。经过第二阶段finetune的MiniGPT-4的生成效果就有明显改善,它不仅可以对图像生成详细的描述,也可以识别图像中有趣的地方,甚至发现图像中异常内容,具体的示例如下所示:

 MiniGPT-4甚至可以像GPT-4一样根据手写内容生成网站代码:
MiniGPT-4甚至可以像GPT-4一样根据手写内容生成网站代码: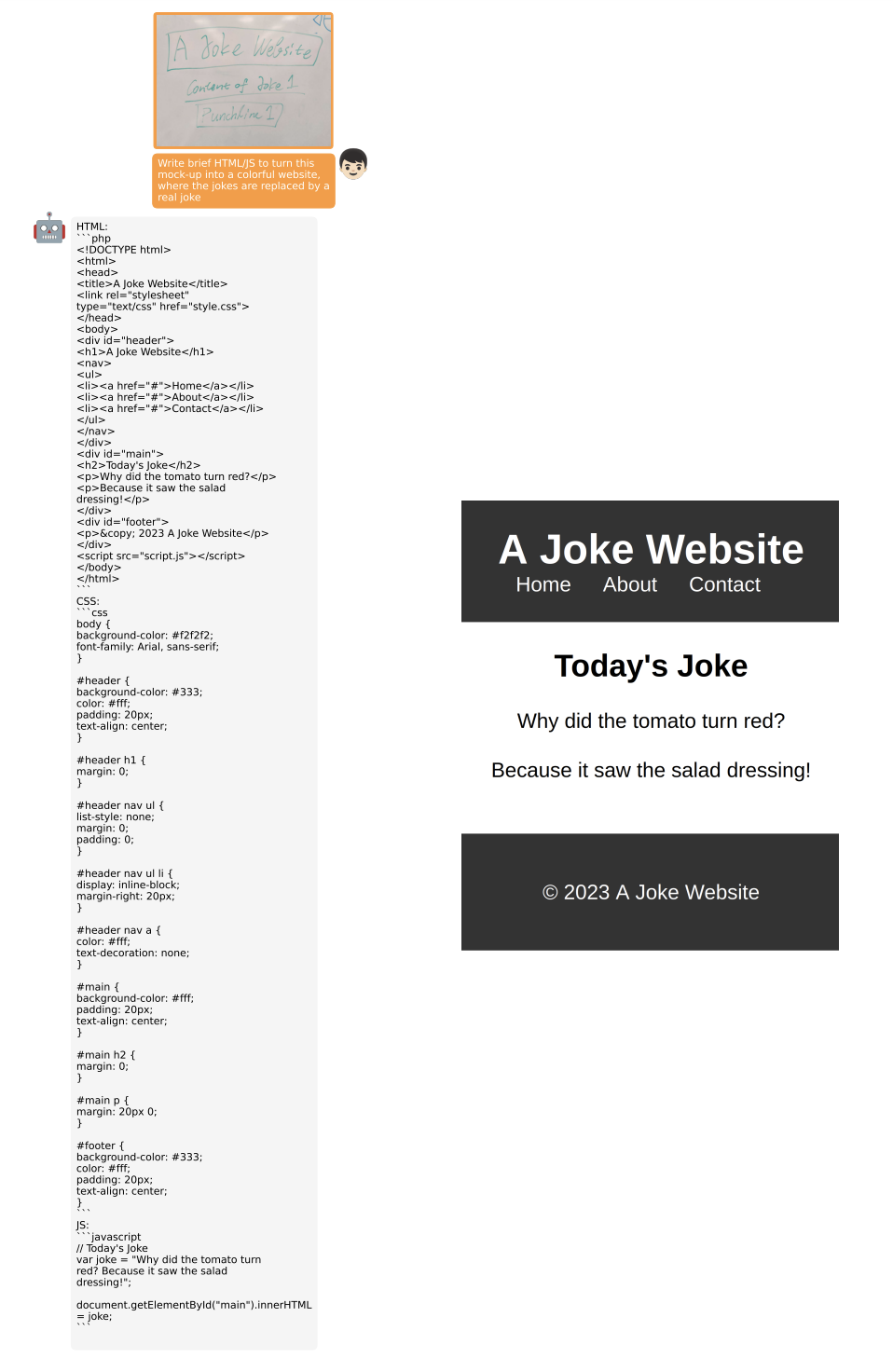 相比较BLIP-2来说,MiniGPT-4提升的关键在于采用了更好的LLM,同时采用了高质量数据集进行finetune。但论文中也说到MiniGPT-4也存在一定的局限性,比如无法从图像中获取细粒度的信息以及无法识别位置信息,我想这主要还在于第二阶段构建的数据集的多样性较少,另外只finetune了一个linear layer。
相比较BLIP-2来说,MiniGPT-4提升的关键在于采用了更好的LLM,同时采用了高质量数据集进行finetune。但论文中也说到MiniGPT-4也存在一定的局限性,比如无法从图像中获取细粒度的信息以及无法识别位置信息,我想这主要还在于第二阶段构建的数据集的多样性较少,另外只finetune了一个linear layer。
LLaVA
LLaVA(Large Language and Vision Assistant)是微软最新的一个工作,这个工作的模型设计和MiniGPT-4基本一样,但是更简单,如下所示: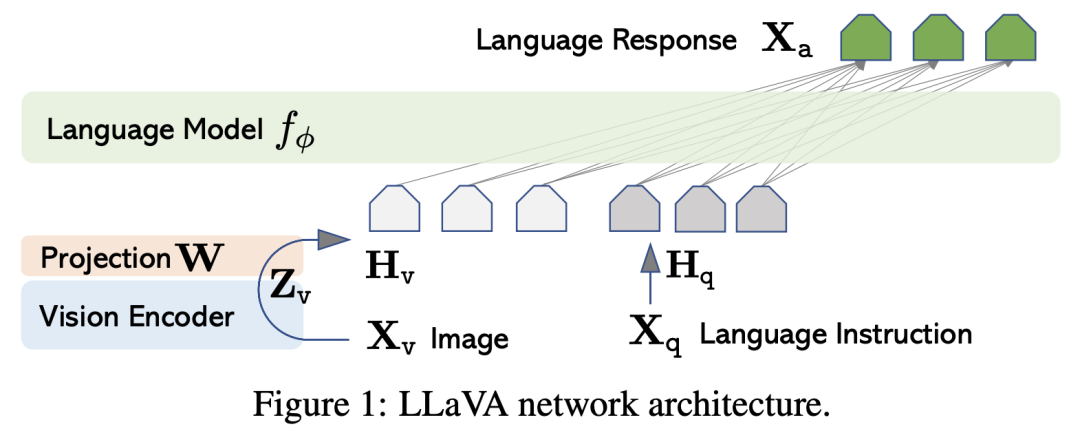 这里的Vision Encoder直接采用预训练好的CLIP ViT-L/14模型,然后直接用它倒数第二层的grid特征,加上一个Projection层映射到LLM的特征空间。相比BLIP-2和MiniGPT-4引入Q-Former,LLaVA可谓是简单粗暴。另外对于语言模型,LLaVA也采用了Meta的LLaMA。LLaVA最重要的部分是它如何构建高质量的multimodal instruction-following dataset,前面的工作基本上都是用图像文本对数据集来进行训练,这肯定是存在一定的局限性,但是目前又没有更好的数据集,LLaVA给出的解决方案是采用GPT-4(或者ChatGPT)来生成这样的数据集,注意这里并不是依赖GPT-4的多模态能力,而只用GPT-4的文本理解和生成能力。虽然我们不能给GPT-4真送入一张图像,但是其实我们可以模拟这个场景,这里我们用一个非常详尽的文本描述来替代图像输入。LLaVA使用两种类型的文本描述:
这里的Vision Encoder直接采用预训练好的CLIP ViT-L/14模型,然后直接用它倒数第二层的grid特征,加上一个Projection层映射到LLM的特征空间。相比BLIP-2和MiniGPT-4引入Q-Former,LLaVA可谓是简单粗暴。另外对于语言模型,LLaVA也采用了Meta的LLaMA。LLaVA最重要的部分是它如何构建高质量的multimodal instruction-following dataset,前面的工作基本上都是用图像文本对数据集来进行训练,这肯定是存在一定的局限性,但是目前又没有更好的数据集,LLaVA给出的解决方案是采用GPT-4(或者ChatGPT)来生成这样的数据集,注意这里并不是依赖GPT-4的多模态能力,而只用GPT-4的文本理解和生成能力。虽然我们不能给GPT-4真送入一张图像,但是其实我们可以模拟这个场景,这里我们用一个非常详尽的文本描述来替代图像输入。LLaVA使用两种类型的文本描述:
captions:从不同的角度描述图像内容;
Bounding boxes:定位图像中的物体,每个框编码物体类别及其空间位置。
下面是一个具体的示例: 这两方面的描述算是近似等价于图像,送入GPT-4中就如同送入图像本身。论文采用COCO中的图像,共根据GPT-4产生3种类型的instruction-following data:第一种是Conversation:构建视觉问答的多轮对话数据,具体是通过如下的方式来生成:
这两方面的描述算是近似等价于图像,送入GPT-4中就如同送入图像本身。论文采用COCO中的图像,共根据GPT-4产生3种类型的instruction-following data:第一种是Conversation:构建视觉问答的多轮对话数据,具体是通过如下的方式来生成: 第二种是Detailed description:根据图像生成详细的描述,这里采用如下的prompt来让GPT-4生成:
第二种是Detailed description:根据图像生成详细的描述,这里采用如下的prompt来让GPT-4生成: 第三种是Complex reasoning:前面的两种主要是和图像内容有关,这部分是构建复杂的推理问题,这里需要手工设计一些问题来让GPT-4来生成。论文中共构建了158K样本,其中 conversations 有58K,detailed description有23K,complex reasoning有77K。下面是根据前面的图像示例来构建的三种类型数据的示例:
第三种是Complex reasoning:前面的两种主要是和图像内容有关,这部分是构建复杂的推理问题,这里需要手工设计一些问题来让GPT-4来生成。论文中共构建了158K样本,其中 conversations 有58K,detailed description有23K,complex reasoning有77K。下面是根据前面的图像示例来构建的三种类型数据的示例: 相比较MiniGPT-4,LLaVA构建的instruction-following data多样性更好,这也能让模型学习到更强的视觉理解能力。具体在训练方面,LLaVA也采用了两阶段的训练策略。第一阶段采用CC3M中筛选的595K图像文本对训练,这里采用的任务是根据图像来生成对应的文本描述,其中prompt采用如下的方式:
相比较MiniGPT-4,LLaVA构建的instruction-following data多样性更好,这也能让模型学习到更强的视觉理解能力。具体在训练方面,LLaVA也采用了两阶段的训练策略。第一阶段采用CC3M中筛选的595K图像文本对训练,这里采用的任务是根据图像来生成对应的文本描述,其中prompt采用如下的方式: 注意第一阶段Vision Encoder和LLM都是冻结的,只finetune了Projection层,所以第一阶段主要是让图像特征能够映射到LLM的特征空间。第二阶段采用收集的instruction-following data数据集来进行finetune,这个阶段Vision Encoder是冻结的,同时训练LLM和Projection层。具体训练样式如下所示:
注意第一阶段Vision Encoder和LLM都是冻结的,只finetune了Projection层,所以第一阶段主要是让图像特征能够映射到LLM的特征空间。第二阶段采用收集的instruction-following data数据集来进行finetune,这个阶段Vision Encoder是冻结的,同时训练LLM和Projection层。具体训练样式如下所示: 下面是LLaVA的几个具体示例,可以看到它比BLIP-2和OpenFlamingo有更强的视觉理解能力:
下面是LLaVA的几个具体示例,可以看到它比BLIP-2和OpenFlamingo有更强的视觉理解能力: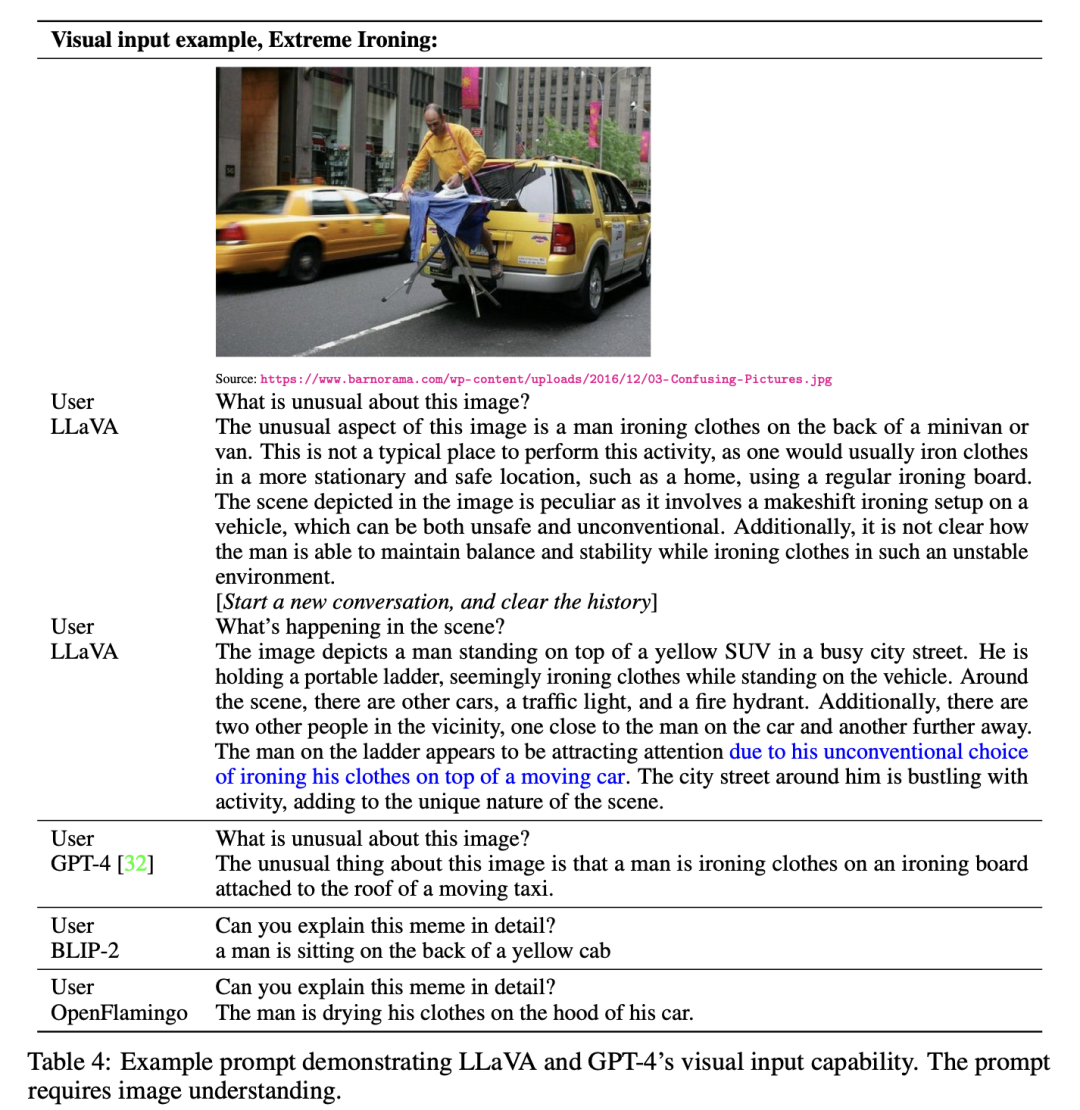
 这里也放一个LLaVA让人惊艳的例子,它不仅能识别艺术作品,而且给定仿造品也能识别:
这里也放一个LLaVA让人惊艳的例子,它不仅能识别艺术作品,而且给定仿造品也能识别:
总结
这里我们简单总结了和GPT-4多模态能力相关的四个工作,再回到我们开头的总结,可以看到这四个工作都选择了具有多模态能力的CLIP模型来提取图像特征,而将图像特征连接到语言模型的方式略有不同,后面的工作很重要的方面是构建高质量的图文多模态数据集。所以虽然GPT-4并没有开源,但是可以想象,GPT-4也应该是采用了一个多模态的视觉模型,很有可能是CLIP,另外GPT-4应该构建了一个比较好的图文数据集来进行训练。
参考
https://openai.com/research/gpt-4
GPT-4 Technical Report
https://github.com/Vision-CAIR/MiniGPT-4
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Visual Instruction Tuning
推荐阅读
使用PyTorch 2.0加速Transformer:训练推理均拿下!
机器学习算法工程师
一个用心的公众号
