
面试官:MySQL中SQL语句是如何执行的?
该篇章将开始整理MySQL的优化,不过开始之前,我们想了解清楚那就是MySQL是怎么执行的。
文章目录
MySQL驱动 应用系统数据库连接池 MySQL数据库连接池 SQL执行过程 线程监听:监听网络请求中的SQL语句 SQL接口:负责处理接收到的SQL语句 查询解析器:让MySQL能看懂SQL语句 查询优化器:选择最优的查询路径 存储引擎接口:真正执行SQL语句 执行器:根据执行计划调用存储引擎的接口 总结
MySQL驱动
大家都知道,我们如果要在Java系统中去访问一个MySQL数据库,必须得在系统的依赖中加入一个MySQL驱动,有了这个MySQL驱动才能跟MySQL数据库建立连接,然后执行各种各样的SQL语句。
MySQL驱动,他会在底层跟数据库建立网络连接,有网络连接,接着才能去发送请求给数据库服务器!当我们跟数据库之间有了网络连接之后,我们的Java代码才能基于这个连接去执行各种各样的增删改查SQL语句。
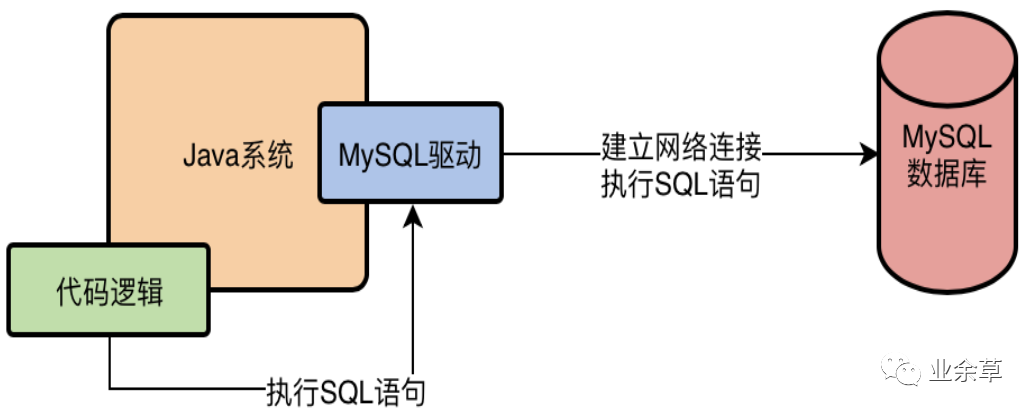
应用系统数据库连接池
假设我们的系统是部署在Tomcat中的,那么Tomcat本身肯定是有多个线程来并发的处理同时接收到的多个请求的,如果Tomcat中的多个线程并发处理多个请求的时候,都要去抢夺一个连接去访问数据库的话,那效率肯定是很低下的。
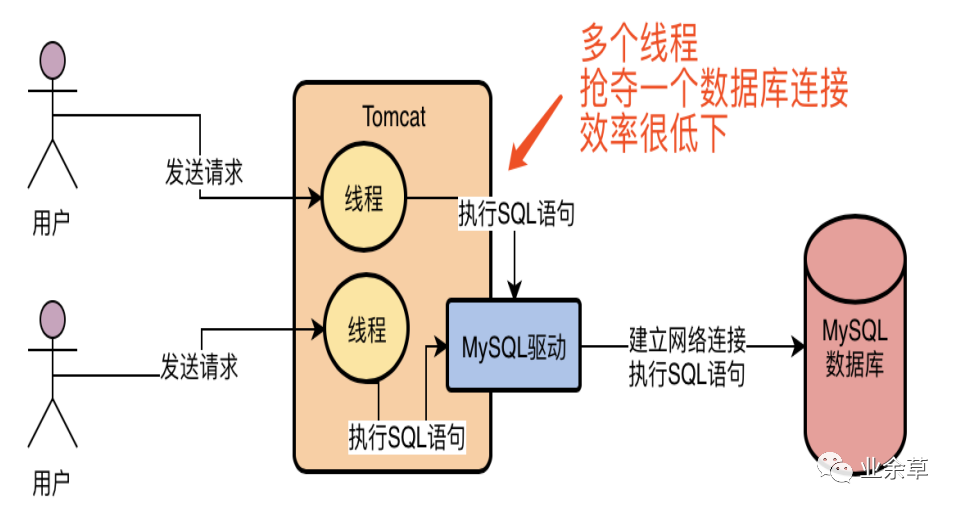
如果Tomcat中的每个线程在每次访问数据库的时候,都基于MySQL驱动去创建一个数据库连接,然后执行SQL语句,然后执行完之后再销毁这个数据库连接,可能Tomcat中上百个线程会并发的频繁创建数据库连接,执行SQL语句,然后频繁的销毁数据库连接,也是非常不好的,因为每次建立一个数据库连接都很耗时,好不容易建立好了连接,执行完了SQL语句,你还把数据库连接给销毁了,下一次再重新建立数据库连接,那肯定是效率很低下的!
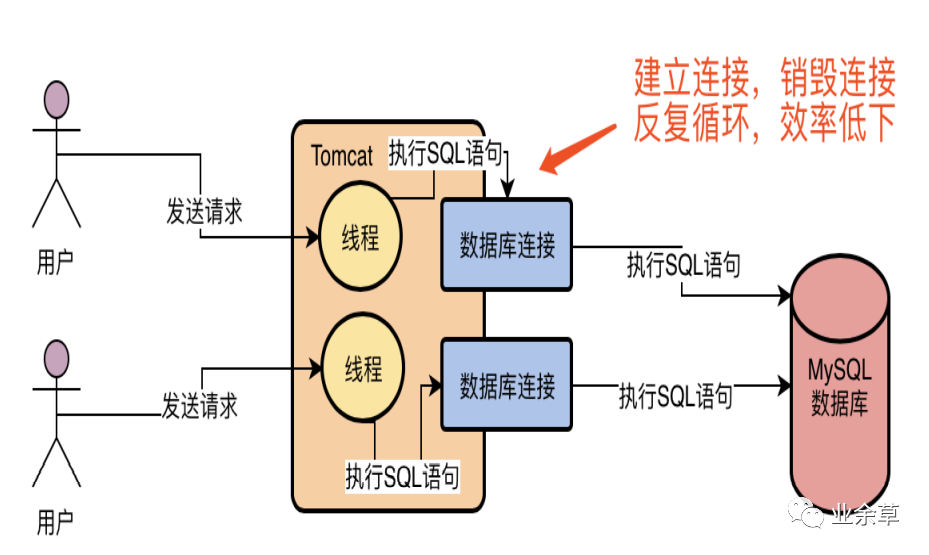
所以一般我们必须要使用一个数据库连接池,也就是说在一个池子里维持多个数据库连接,让多个线程使用里面的不同的数据库连接去执行SQL语句,然后执行完SQL语句之后,不要销毁这个数据库连接,而是把连接放回池子里,后续还可以继续使用。基于这样的一个数据库连接池的机制,就可以解决多个线程并发的使用多个数据库连接去执行SQL语句的问题,而且还避免了数据库连接使用完之后就销毁的问题。
常见的数据库连接池有DBCP,C3P0,Druid
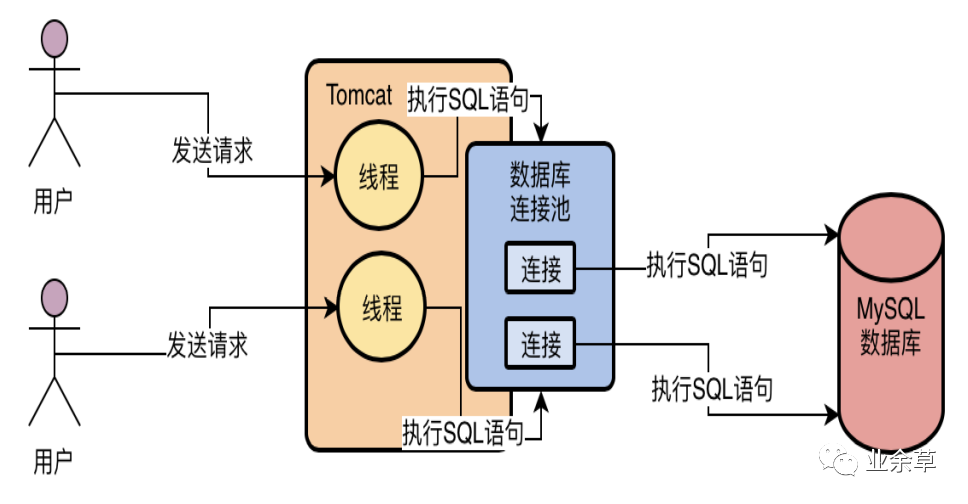
MySQL数据库连接池
任何一个系统都会有一个数据库连接池去访问数据库,也就是说这个系统会有多个数据库连接,供多线程并发的使用。同时我们可能会有多个系统同时去访问一个数据库,这都是有可能的。MySQL也必然要维护与系统之间的多个连接。
实际上MySQL中的连接池就是维护了与系统之间的多个数据库连接。除此之外,你的系统每次跟MySQL建立连接的时候,还会根据你传递过来的账号和密码,进行账号密码的验证,库表权限的验证。

SQL执行过程
线程监听:监听网络请求中的SQL语句
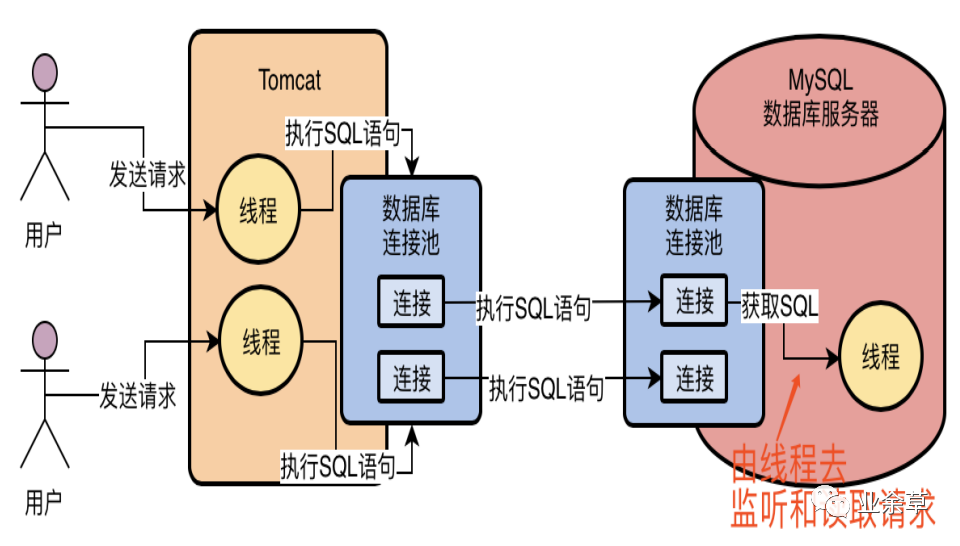
现在假设我们的数据库服务器的连接池中的某个连接接收到了网络请求,假设就是一条SQL语句,那么大家先思考一个问题,谁负责从这个连接中去监听网络请求?谁负责从网络连接里把请求数据读取出来?
我想很多人恐怕都没思考过这个问题,但是如果大家对计算机基础知识有一个简单了解的话,应该或多或少知道一点,那就是网络连接必须得分配给一个线程去进行处理,由一个线程来监听请求以及读取请求数据,比如从网络连接中读取和解析出来一条我们的系统发送过去的SQL语句,如下图所示
SQL接口:负责处理接收到的SQL语句
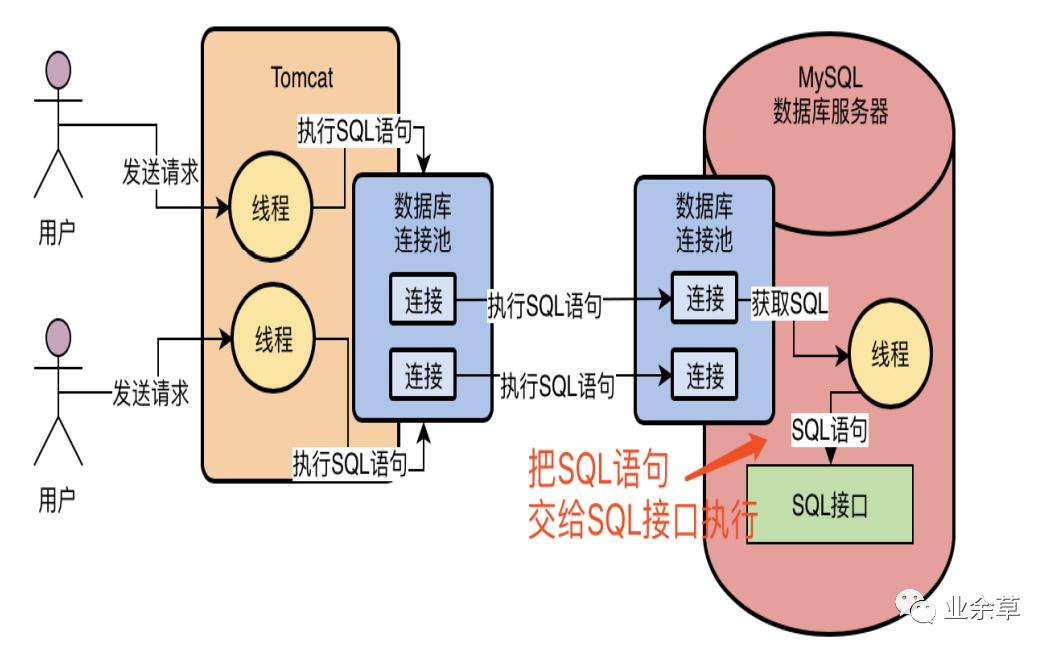
当MySQL内部的工作线程从一个网络连接中读取出来一个SQL语句之后,此时会如何来执行这个SQL语 句呢?
MySQL内部首先提供了一个组件,就是SQL接口(SQL Interface),他是一套执行SQL语句的接口,专门用于执行我们发送给MySQL的那些增删改查的SQL语句。因此MySQL的工作线程接收到SQL语句之后,就会转交给SQL接口去执行,如下图:
查询解析器:让MySQL能看懂SQL语句
SQL接口怎么执行SQL语句呢?你直接把SQL语句交给MySQL,他能看懂和理解这些SQL语句吗?
比如我们来举一个例子,现在我们有这么一个SQL语句:
select id,name,age from users where id=1
MySQL自己本身也是一个系统,是一个数据库管理系统,他没法直接理解这些SQL语句!
所以此时有一个关键的组件要出场了,那就是查询解析器。
这个查询解析器(Parser)就是负责对SQL语句进行解析的,比如对上面那个SQL语句进行一下拆解,拆解成以下几个部分:
我们现在要从“users”表里查询数据(from users) 查询“id”字段的值等于1的那行数据(where id=1) 对查出来的那行数据要提取里面的“id,name,age”三个字段(select id,name,age)
所谓的SQL解析,就是按照既定的SQL语法,对我们按照SQL语法规则编写的SQL语句进行解析,然后理解这个SQL语句要干什么事情,如下图所示

查询优化器:选择最优的查询路径
当我们通过解析器理解了SQL语句要干什么之后,接着会找查询优化器(Optimizer)来选择一个最优的查询路径。
在语法分析阶段:会对SQL语句进行分析,比如如下sql语句
select A.name, A.age from tb_student A where A.age=18 and A.name='张三'
该SQL在被执行之前,会先进行语法检测,判断有无错误,之后会分析出如下两个sql查询条件,
where A.age=18 where A.name=‘张三’
问题就来了,这两个条件谁先执行有区别吗?答案是肯定的,在我们编写SQL的时候,都会遵循一个原则,就是把区分度最高的放在左侧。
where A.name=‘张三’ AND A.age=18 where A.age=18 AND A.name=‘张三’
上面这就是一个最简单的SQL语句的两种实现路径,其实我们会发现,要完成这个SQL语句的目标,两个路径都可以做到,但是哪一种更好呢?显然感觉上是第一种查询路径更好一些。因为在我们数据库系统中,叫张三的人可能只有几百个,但是年龄为18岁的,可能有几万个。
所以查询优化器大概就是干这个的,他会针对你编写的几十行、几百行甚至上千行的复杂SQL语句生成查询路径树,然后从里面选择一条最优的查询路径出来。相当于他会告诉你,你应该按照一个什么样的步骤和顺序,去执行哪些操作,然后一步一步的把SQL语句就给完成了。

存储引擎接口:真正执行SQL语句
把查询优化器选择的最优查询路径,也就是你到底应该按照一个什么样的顺序和步骤去执行这个SQL语句的计划,把这个计划交给底层的存储引擎去真正的执行。这个存储引擎是MySQL的架构设计中很有特色的一个环节。
真正在执行SQL语句的时候,要不然是更新数据,要不然是查询数据,那么数据你觉得存放在哪里?
以对数据库而言,我们的数据要不然是放在内存里,要不然是放在磁盘文件里。
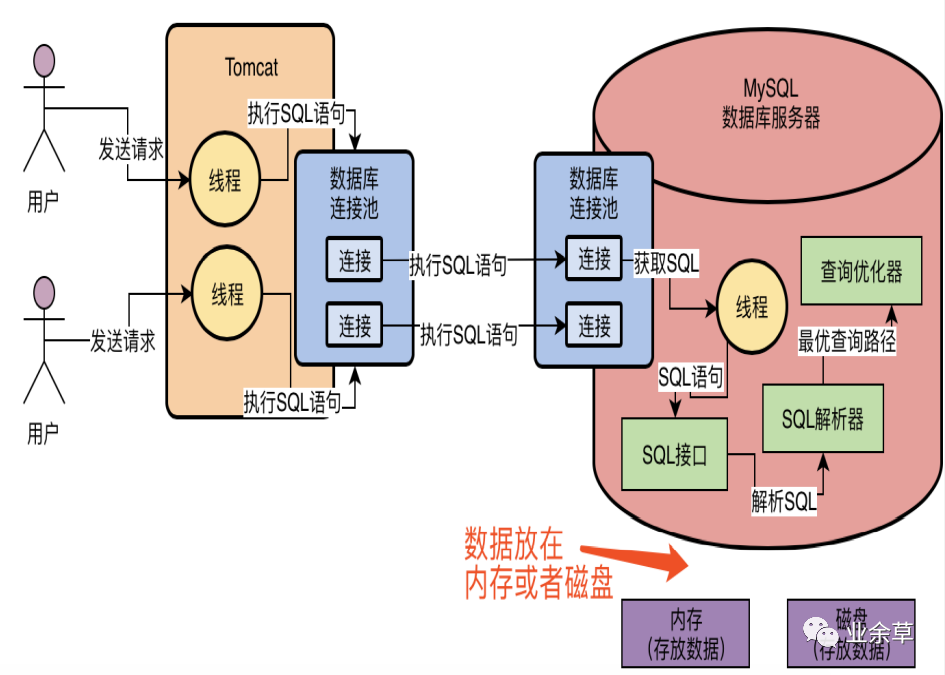
那么现在问题来了,我们已经知道一个SQL语句要如何执行了,但是我们现在怎么知道哪些数据在内存里?哪些数据在磁盘里?我们执行的时候是更新内存的数据?还是更新磁盘的数据?我们如果更新磁盘的数据,是先查询哪个磁盘文件,再更新哪个磁盘文件?
所以这个时候就需要存储引擎了,存储引擎其实就是执行SQL语句的,他会按照一定的步骤去查询内存缓存数据,更新磁盘数据,查询磁盘数据,等等,执行诸如此类的一系列的操作,如下图所示。
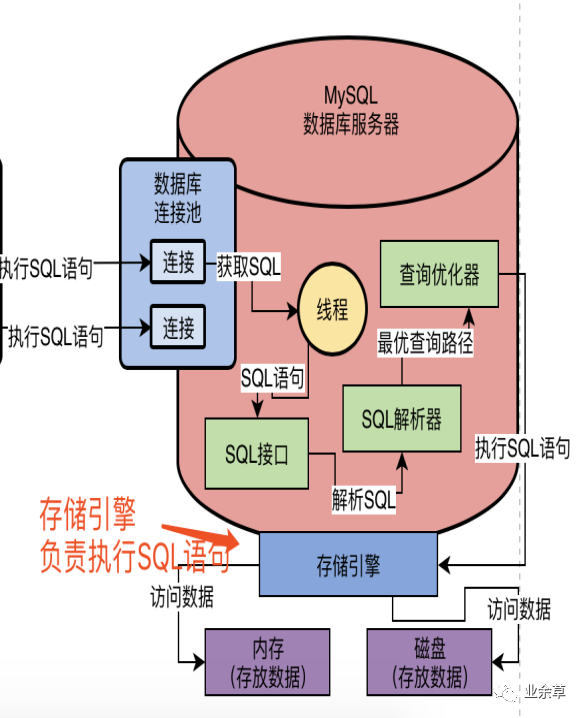
存储引擎支持各种各样的存储引擎的,比如我们常见的InnoDB、MyISAM、Memory等等,我们是可以选择使用哪种存储引擎来负责具体的SQL语句执行的。当然现在MySQL一般都是使用InnoDB存储引擎。
执行器:根据执行计划调用存储引擎的接口
存储引擎可以帮助我们去访问内存以及磁盘上的数据,那么是谁来调用存储引擎的接口呢?
其实我们现在还漏了一个执行器的概念,这个执行器会根据优化器选择的执行方案,去调用存储引擎的接口按照一定的顺序和步骤,就把SQL语句的逻辑给执行了。
执行器就会去根据我们的优化器生成的一套执行计划,然后不停的调用存储引擎的各种接口去完成SQL
语句的执行计划,大致就是不停的更新或者提取一些数据出来。

总结
本文介绍内容总体如下流程图所示:
