学习集合类源码对我们实际工作的帮助和应用!
文章首发在公众号(月伴飞鱼),之后同步到掘金和个人网站:xiaoflyfish.cn/
「觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢」
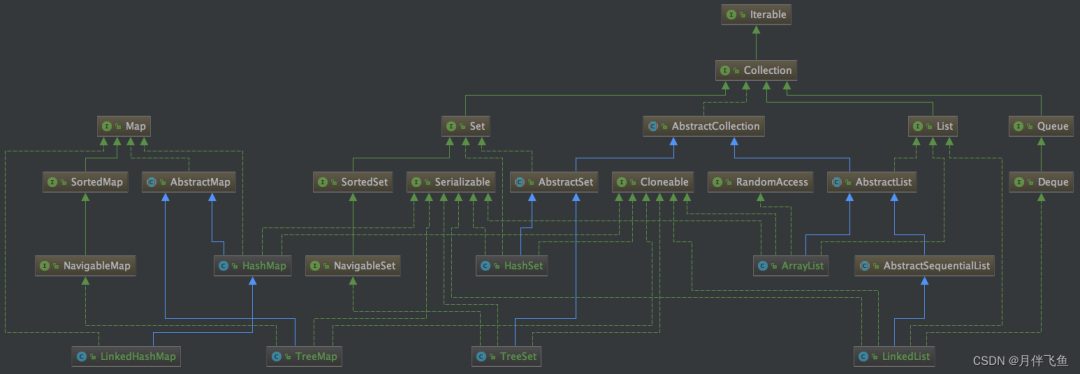
Java的集合类包括Map和Collection两大类。Collection包括List、Set和Queue三个小类。
「如下图:」
这边文章通过源码解读的方式带大家了解一下:集合类使用过程中常见的问题以及学习一些优秀的设计思想。
「集合批量操作性能」
集合的单个操作,一般都没有性能问题,性能问题主要出现的批量操作上。
❝
如批量新增操作:
❞
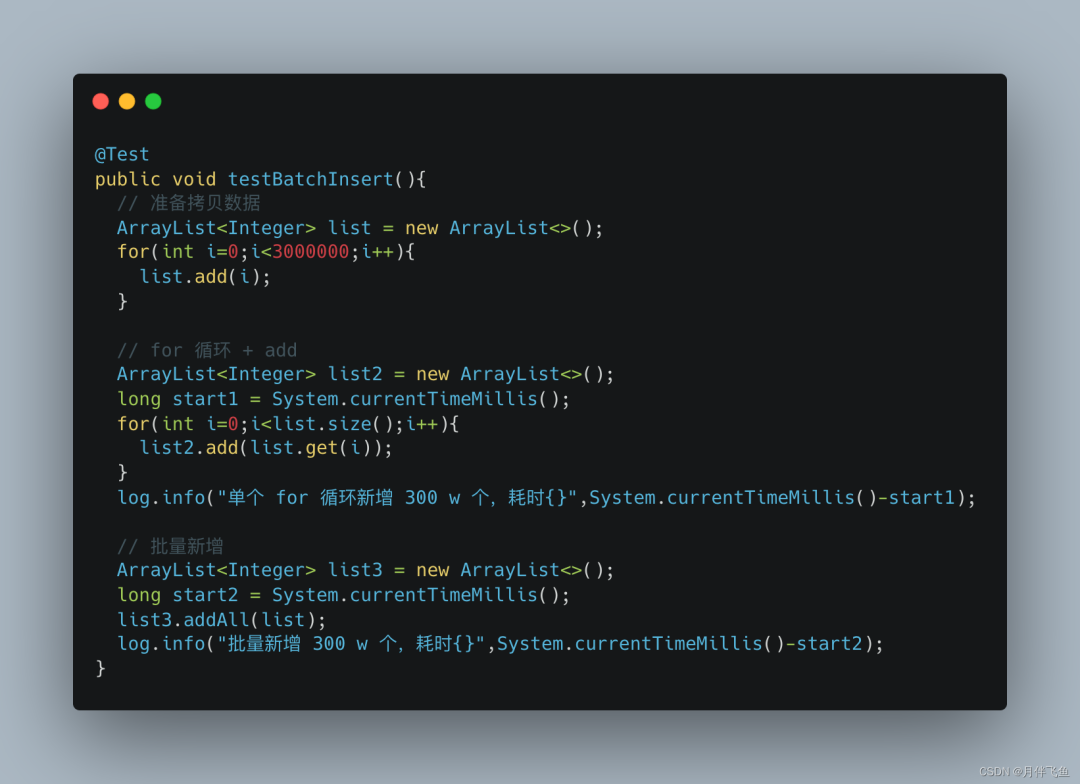
在 List 和 Map 大量数据新增的时候,使用 for 循环 + add/put 方法新增,这样子会有很大的扩容成本,我们应该尽量使用 addAll 和 putAll 方法进行新增,如下演示了两种方案的性能对比:
❝
单个 for 循环新增 300 w 个,耗时1518。
批量新增 300 w 个,耗时8。
❞
可以看到,批量新增方法性能是单个新增方法性能的 189 倍,主要原因在于批量新增,只会扩容一次,大大缩短了运行时间,而单个新增,每次到达扩容阀值时,都会进行扩容,在整个过程中就会不断的扩容,浪费了很多时间。
我们来看下批量新增的源码:
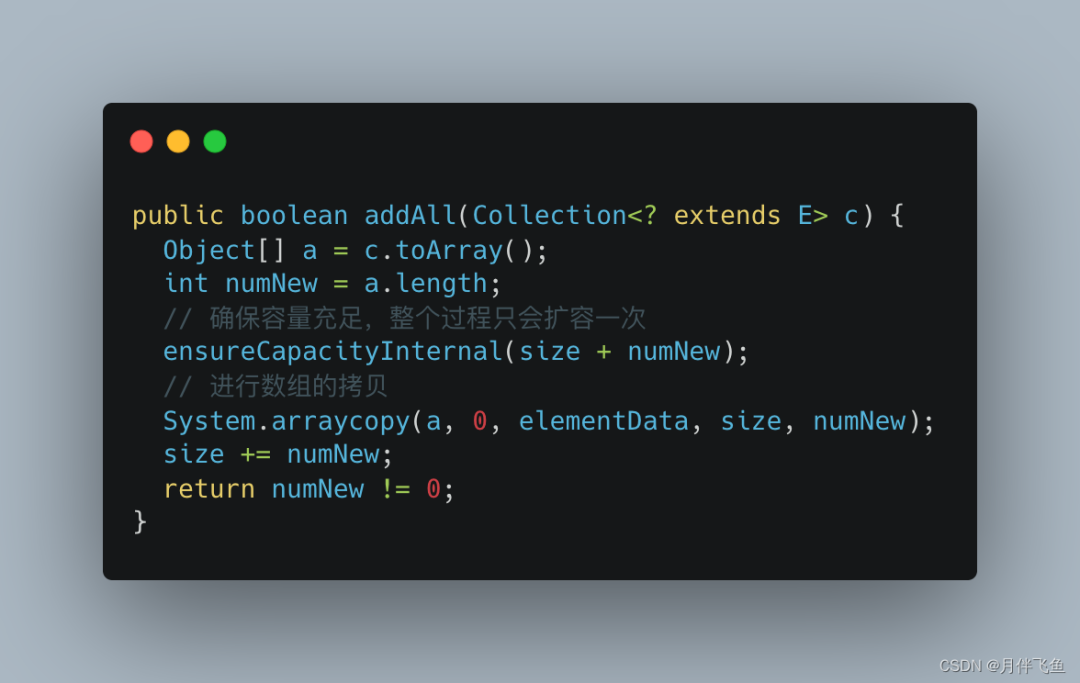
我们可以看到,整个批量新增的过程中,只扩容了一次。
「集合线程安全性」
集合的非线程安全指的是:集合类作为共享变量,被多线程读写的时候是不安全的,如果要实现线程安全的集合,在类注释中,JDK 统一推荐我们使用 Collections.synchronized* 类。
Collections 帮我们实现了 List、Set、Map 对应的线程安全的方法, 如下图:
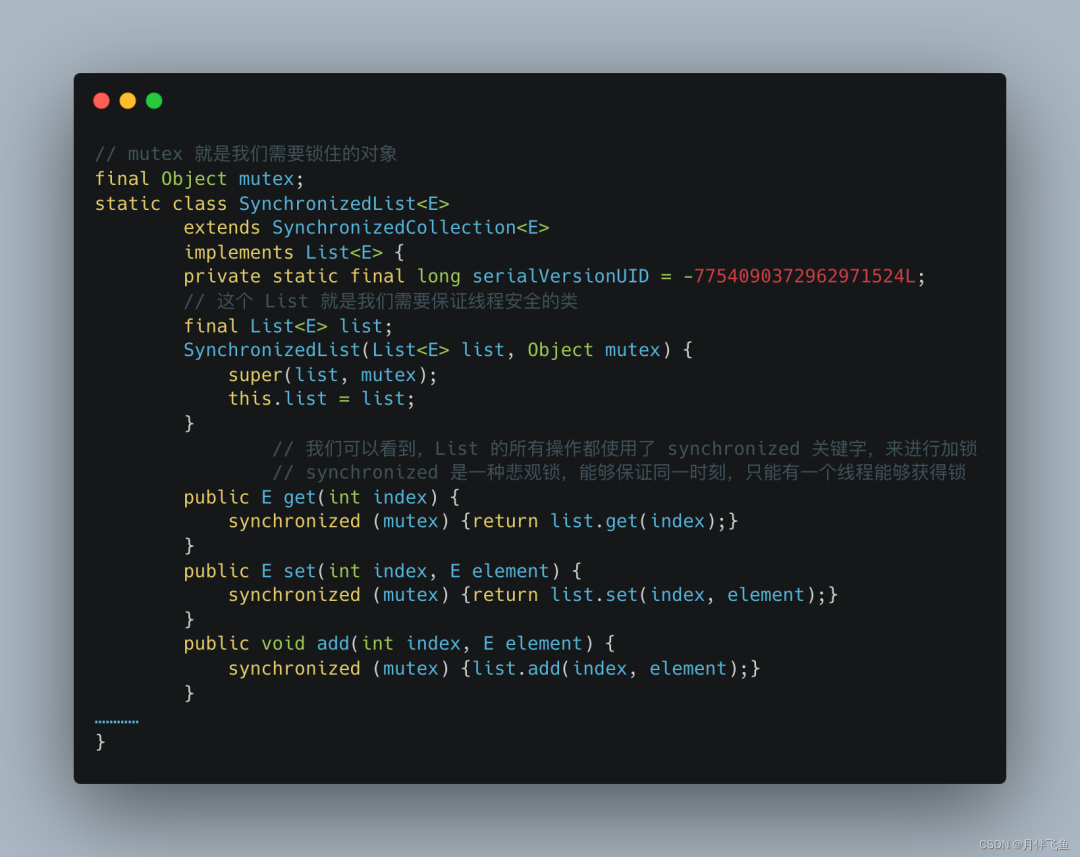
从源码中我们可以看到 Collections 是通过 synchronized 关键字给 List 操作数组的方法加上锁,来实现线程安全的。
集合类方法常见的问题
List
「Arrays.asList()方法」
我们把数组转化成集合时,常使用 Arrays.asList(array),这个方法有两个问题,代码演示如下:
❝
问题一:修改数组的值,会直接影响原list。
❞
public void testArrayToList(){
Integer[] array = new Integer[]{1,2,3,4,5,6};
List<Integer> list = Arrays.asList(array);
// 问题1:修改数组的值,会直接影响原 list
log.info("数组被修改之前,集合第一个元素为:{}",list.get(0));
array[0] = 10;
log.info("数组被修改之前,集合第一个元素为:{}",list.get(0));
}
❝
问题二:不能对新 List 进行 add、remove 等操作,否则运行时会报 UnsupportedOperationException 错误。
❞
public void testArrayToList(){
Integer[] array = new Integer[]{1,2,3,4,5,6};
List<Integer> list = Arrays.asList(array);
// 问题2:使用 add、remove 等操作 list 的方法时,
// 会报 UnsupportedOperationException 异常
list.add(7);
}
原因分析:
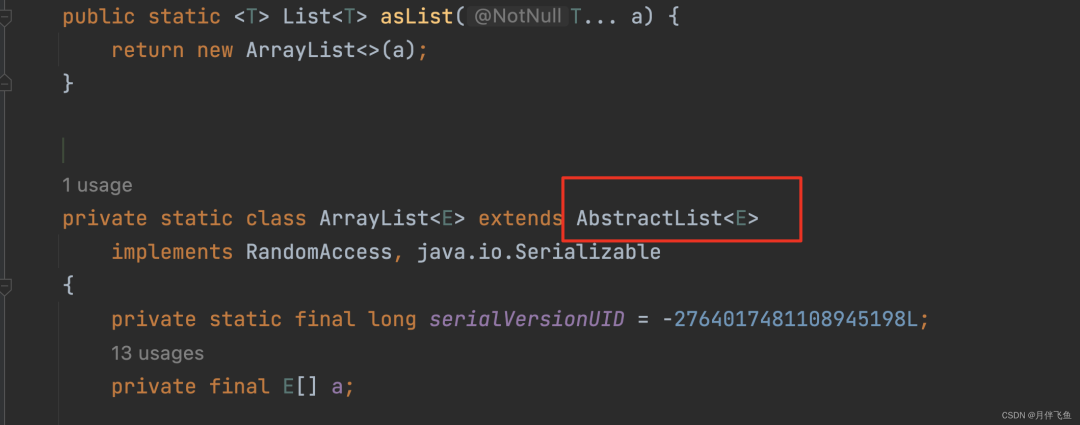

从上图中,我们可以发现,Arrays.asList 方法返回的 List 并不是 java.util.ArrayList,而是自己内部的一个静态类,该静态类直接持有数组的引用,并且没有实现 add、remove 等方法,这些就是问题 1 和 2 的原因。
「list.toArray方法」
public void testListToArray(){
List<Integer> list = new ArrayList<Integer>(){{
add(1);
add(2);
add(3);
add(4);
}};
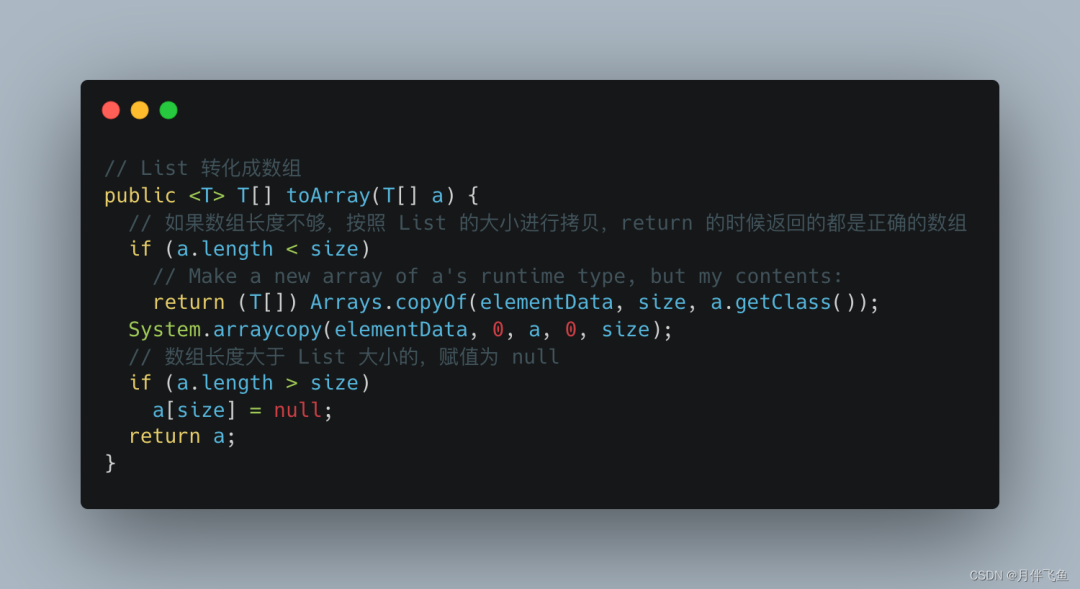
// 下面这行代码是无法转化成数组的,无参 toArray 返回的是 Object[],
// 无法向下转化成 List<Integer>,编译都无法通过
// List<Integer> list2 = list.toArray();
// 有参 toArray 方法,数组大小不够时,得到数组为 null 情况
Integer[] array0 = new Integer[2];
list.toArray(array0);
log.info("toArray 数组大小不够,array0 数组[0] 值是{},数组[1] 值是{},",array0[0],array0[1]);
// 数组初始化大小正好,正好转化成数组
Integer[] array1 = new Integer[list.size()];
list.toArray(array1);
log.info("toArray 数组大小正好,array1 数组[3] 值是{}",array1[3]);
// 数组初始化大小大于实际所需大小,也可以转化成数组
Integer[] array2 = new Integer[list.size()+2];
list.toArray(array2);
log.info("toArray 数组大小多了,array2 数组[3] 值是{},数组[4] 值是{}",array2[3],array2[4]);
}
toArray 数组大小不够,array0 数组[0] 值是null,数组[1] 值是null,
toArray 数组大小正好,array1 数组[3] 值是4
toArray 数组大小多了,array2 数组[3] 值是4,数组[4] 值是null
❝
原因分析:
❞
toArray 的无参方法,无法强转成具体类型,这个编译的时候,就会有提醒,我们一般都会去使用带有参数的 toArray 方法,这时就有一个坑,如果参数数组的大小不够,这时候返回的数组值是空。
「Collections.emptyList()方法」
❝
问题:
❞
在返回的 Collections.emptyList(); 上调用了add()方法,抛出异常 UnsupportedOperationException。
❝
分析:
❞
Collections.emptyList() 返回的是不可变的空列表,这个空列表对应的类型是EmptyList,这个类是Collections中的静态内部类,继承了AbstractList。
AbstractList中默认的add方法是没有实现的,直接抛出UnsupportedOperationException异常。
而EmptyList只是继承了AbstractList,却并没有重写add方法,因此直接调用add方法会抛异常。
除了emptyList,还有emptySet、emptyMap等也一样。

「List.subList()方法」
list.subList() 产生的集合也会与原始List互相影响。

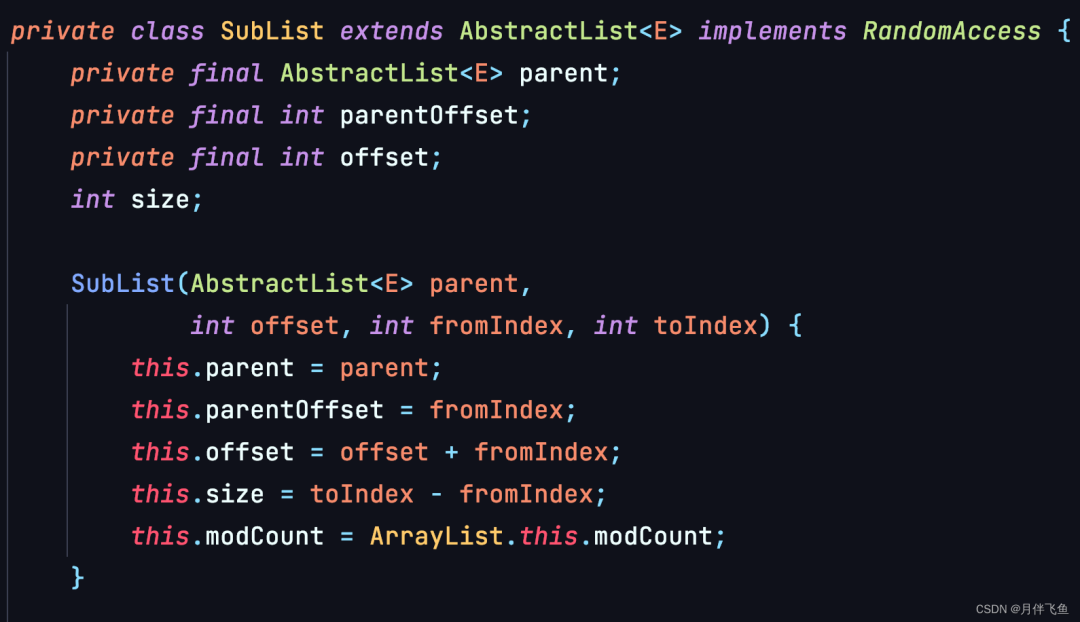
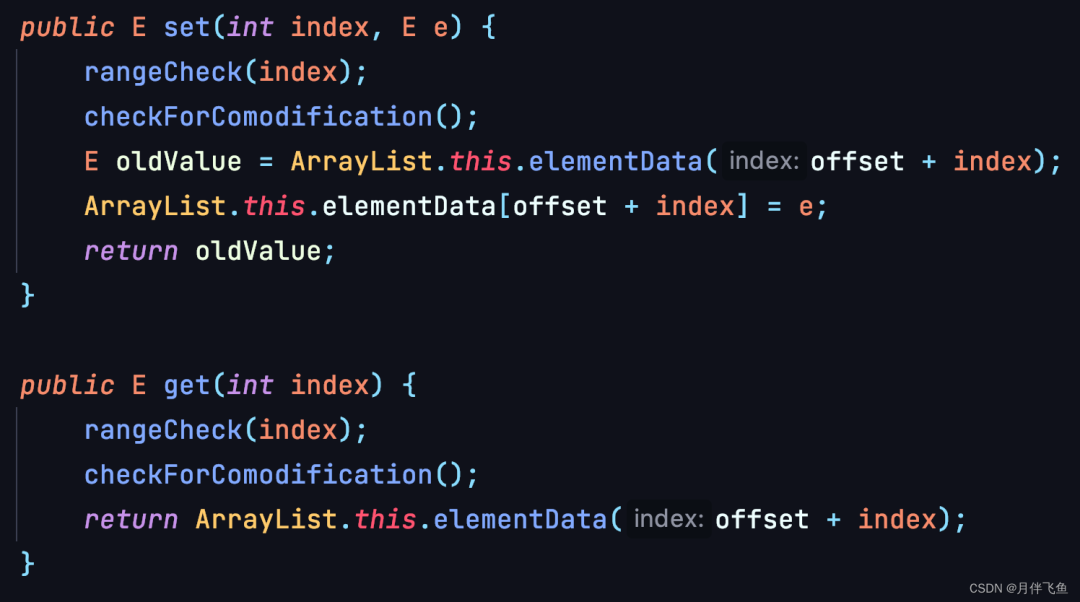
建议使用时,通过List list = Lists.newArrayList(arrays); 来生成一个新的list,不要再操作原列表。
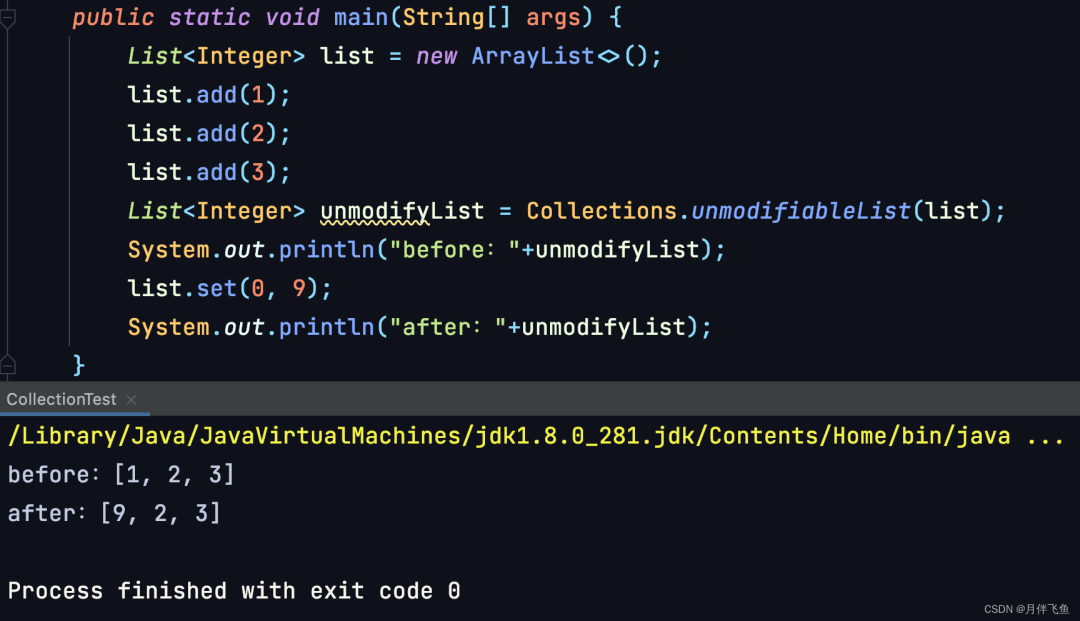
「UnmodifiableList」
UnmodifiableList是Collections中的内部类,通过调用 Collections.unmodifiableList(List list) 可返回指定集合的不可变集合。
集合只能被读取,不能做任何增删改操作,从而保护不可变集合的安全。但这个不可变仅仅是正向的不可变。
反过来如果修改了原来的集合,则这个不可变集合仍会被同步修改。因为不可变集合底层使用的还是原来的List。
Map
「ConcurrentHashMap不允许为null」
ConcurrentHashMap#put方法的源码,开头就看到了对KV的判空校验。
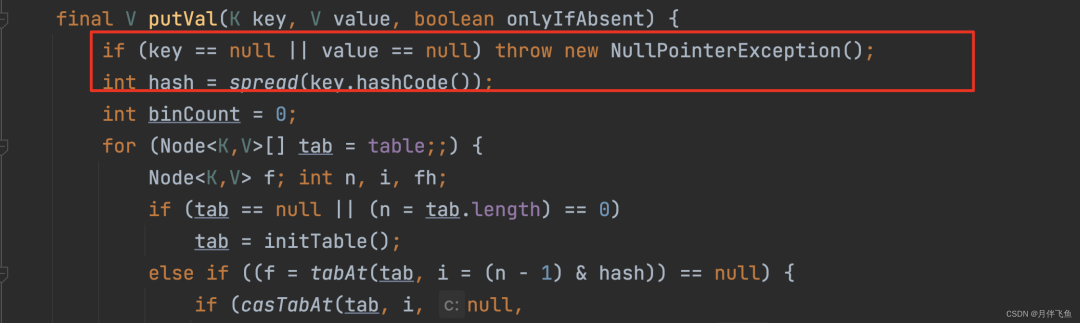
为什么ConcurrentHashMap与 HashMap设计的判断逻辑不一样?
Doug Lea 老爷子的解释是:
null会引起歧义,如果value为null,我们无法得知是值为null,还是key未映射具体值?
Doug Lea 并不喜欢null,认为null就是个隐藏的炸弹。
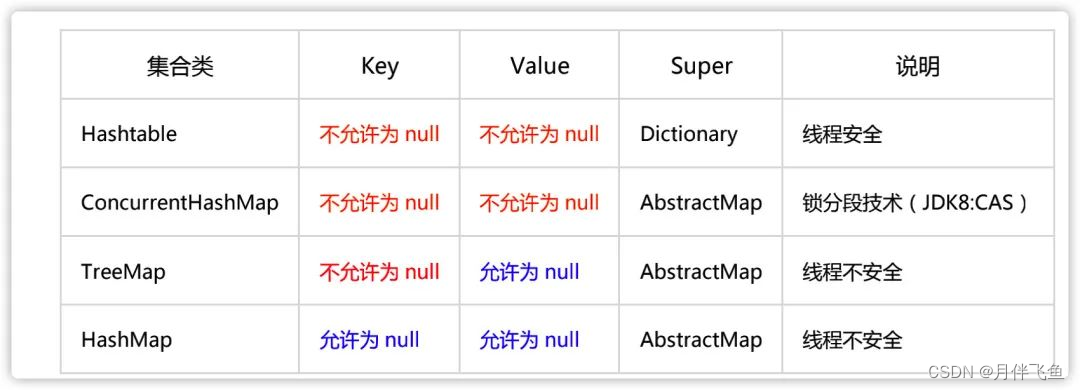
贴一下常用Map子类集合对于 null存储情况:
「HashMap 是无序的」
举例:
import java.util.HashMap;
public class App {
public static void main(String[] args) {
HashMap<String, Object> result = getList();
result.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
}
// 查询方法(简化版)
public static HashMap<String, Object> getList() {
HashMap<String, Object> result = new HashMap<>(); // 最终返回的结果集
// 伪代码:从数据库中查询出了数据,然后对数据进行处理之后,存到了
for (int i = 1; i <= 5; i++) {
result.put("2022-" + i, "hello java" + i);
}
return result;
}
}
结果并没有按先后顺序返回。
❝
原因分析
❞
HashMap 使用的是哈希方式进行存储的,因此存入和读取的顺序可能是不一致的,这也说 HashMap 是无序的集合,所以会导致插入的顺序,与最终展示的顺序不一致。
解决方案:将无序的 HashMap 改为有序的 LinkedHashMap。
LinkedHashMap 属于 HashMap 的子类,所以 LinkedHashMap 除了拥有 HashMap 的所有特性之后,还具备自身的一些扩展属性,其中就包括 LinkedHashMap 中额外维护了一个双向链表,这个双向链表就是用来保存元素的(插入)顺序的。
Set
如果是需要对我们自定义的对象去重,就需要我们重写 hashCode 和 equals 方法。
不然HashSet调用默认的hashCode方法判断对象的地址,不等就达不到想根据对象的值去重的目的。