
玩转Service Mesh微服务熔断、限流骚操作

在微服务架构中,随着服务调用链路变长,为了防止出现级联雪崩,在微服务治理体系中,熔断、限流作为服务自我保护的重要机制,是确保微服务架构稳定运行的关键手段之一。
那么什么是熔断、限流?在传统Spring Cloud微服务、以及新一代Service Mesh微服务架构中,它们分别又是怎么实现的?本文将对此进行阐述!
服务熔断、限流概述

先理解下熔断、限流的基本概念以及它们的应用场景。说起熔断这个词,大家印象深刻的可能是股市交易熔断、或者电路保险丝断开这样的场景;而微服务中的熔断本质上和这些场景中所描述的理念是一致的。都是为了在极端情况下,保证系统正常运行而设计的一种自我保护机制。
熔断的基本逻辑就是隔离故障。在微服务架构盛行的今天,服务之间的调用链路相比单体应用时代变得更长了,服务化拆分带来系统整体能力提升的同时,也增加了服务级联故障出现的概率。例如调用链路“A->B->C->D”,如果服务D出现问题,那么链路上的A、B、C都可能会出现问题,这一点也很好理解,因为出现故障的服务D,必然会在某个时间段内阻塞C->D的调用请求,并最终蔓延至整个链路。而服务连接资源又是有限的,这种增加的调用耗时,会逐步消耗掉整个链路中所有服务的可用线程资源,从而成为压垮整个微服务体系的幕后黑手。
而为了防止故障范围的扩大,就需要对故障服务D进行隔离,隔离的方式就是服务C在感知到对D的调用频繁出现故障(超时或错误)后,主动断掉对D的连接,直接返回失败调用结果。以此类推,如果微服务中的所有链路都设置这样的熔断机制,那么就能逐级实现链路的分级保护效果。
熔断机制虽然解决不了故障,但却能在故障发生时尽量保全非故障链路上的服务接口能被正常访问,从而将故障范围控制在局部。当然被熔断的服务也不会一直处于熔断状态,在熔断机制的设计中还要考虑故障恢复处理机制。
说完熔断,再来说说限流。熔断的主要目的是隔离故障,而引起故障的原因除了系统本身的问题外,还有一种可能就是请求量达到了系统处理能力的极限,后续新进入的请求会持续加重服务负载,最终导致资源耗尽,从而引起系统级联故障、导致雪崩。而限流的目的就是拒绝多余流量、保证服务整体负载始终处于合理水平。
从限流范围上看,微服务体系中的每个服务都可以根据自身情况设置合理的限流规则,例如调用链路“A->B->C->D”,B服务的承受力是1000QPS,如果超过该阀值,那么超出的请求就会被拒绝,但这也容易引起A对B的熔断,所以对于微服务设置限流规则的设置最好还是根据压测结果确定。
在实际场景中,对单个节点的微服务分别设置限流,虽然从逻辑上没啥毛病,但实际操作起来却并不容易,这主要是因为限流规则分散不好统一控制,另外对于单节点阀值的评估,在全链路环境下并不能得出“1+1=2”的结果。所以,一般做法是根据全链路压测结果,在服务网关统一进行集群级别的限流处理。
接下来将分别介绍在Spring Cloud传统微服务体系,以及新一代Service Mesh微服务体系中,熔断、限流的基本实现原理,并重点演示基于Istio的微服务熔断、限流逻辑具体实践!
Spring Cloud微服务对熔断/限流的处理
说起Spring Cloud微服务中的熔断、限流,最先想到的肯定是Hystrix、Sentinel这样的技术组件。关于这两种著名的熔断、限流组件,在笔者早先的文章<<Spring Cloud中Hystrix、Ribbon及Feign的熔断关系是什么?>>以及<<Spring Cloud微服务Sentinel+Apollo限流、熔断实战>>中都曾详细介绍过,细节就不再赘述,感兴趣的朋友可以翻阅下。这里只从微服务架构的宏观视角,来对比分析下其与服务网格(Service Mesh)在架构上的区别。
从本质上说Hystrix与Sentinel并无实质差别,它们都是以SDK的形式附着在具体微服务进程之上的、实现了熔断/限流功能的本地工具包。具体示意图如下:
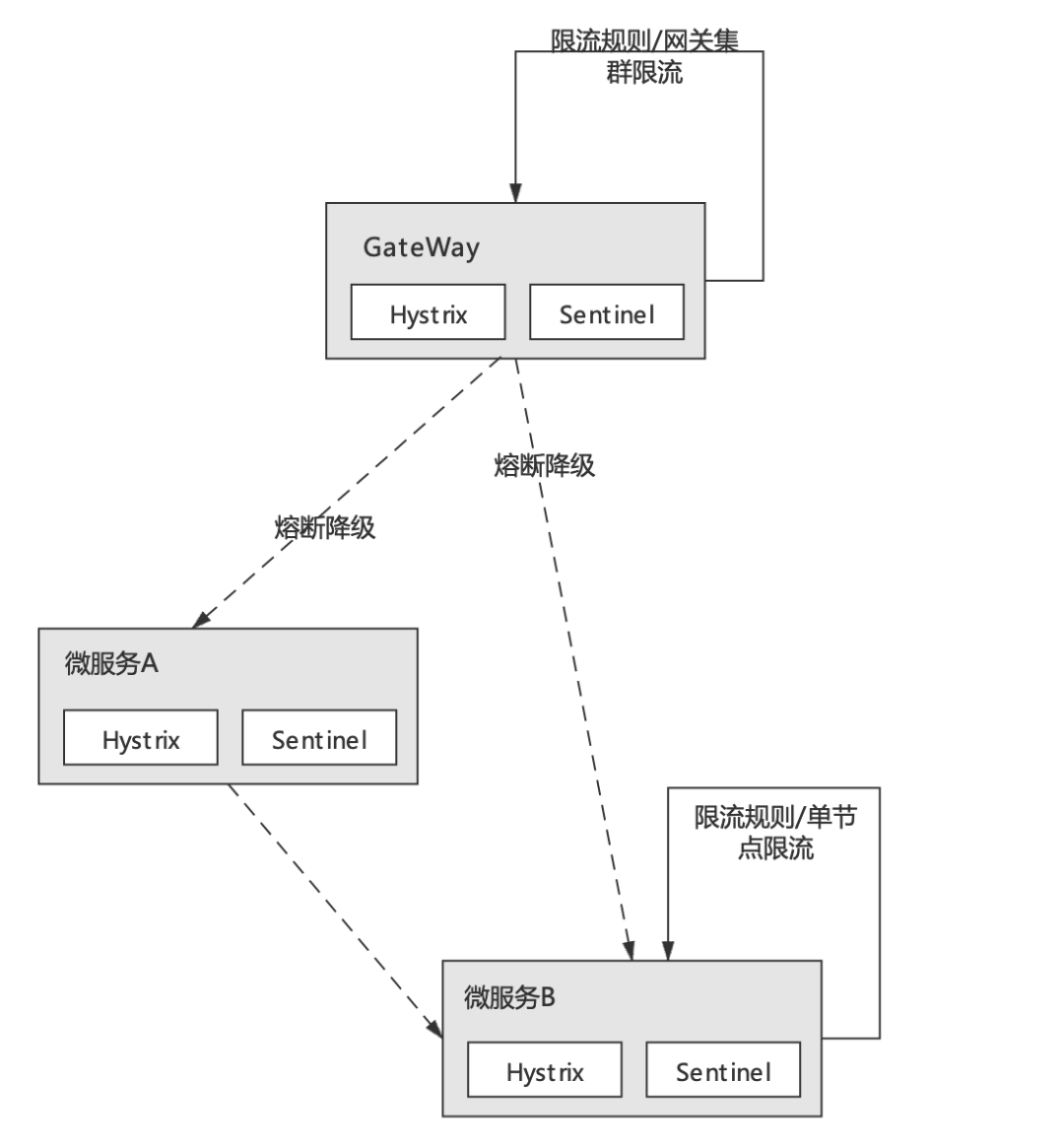
在Spring Cloud微服务中,Hystrix、Sentinel等熔断、限流组件通过嵌入微服务进程,统计微服务一段时期内的入口流量及依赖服务的错误调用次数、并根据组件的所提供功能及规则配置,来决定是否触发限流或熔断降级逻辑。这样的过程完全是附着在微服务进程本身完成的,虽然限流/熔断组件本身也提供了线程池隔离之类资源隔离手段,但从服务治理的角度来看,这样的方式显然还是侵入了业务、占用了业务系统资源;并且分散于应用的规则配置,也不利于微服务体系的整体管控。
Service Mesh微服务熔断/限流实现
前面简单概述了Spring Cloud微服务体系中实现熔断、限流机制的基本框架及存在的弊端。接下来将具体分析下同样的逻辑在Service Mesh微服务架构中是如何实现的?
关于Service Mesh微服务架构如果你还比较陌生,可以先通过笔者之前的文章<<干货|如何步入Service Mesh微服务架构时代>><<实战|Service Mesh微服务架构实现服务间gRPC通信>>进行了解,这两篇文章从概念到实践详细介绍了基于Istio的Service Mesh微服务架构的具体玩法。本文所依赖的操作环境及示例代码均依赖于该文章所演示的案例。
而回到本文的主题,要了解Service Mesh微服务架构中熔断、限流的实现机制,还是需要从整体上理解服务网格实现的基本架构,具体如下图所示:
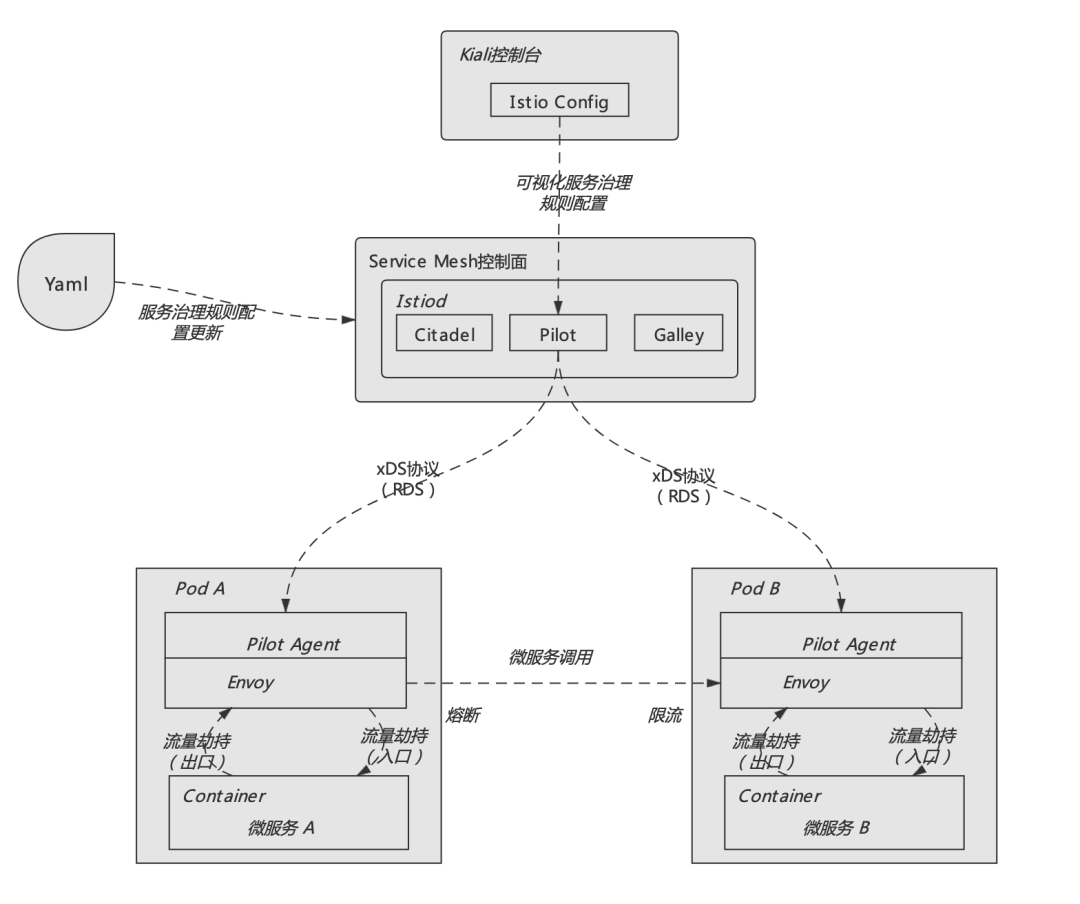
如上图所示,Service Mesh架构总体上由控制面(Control Plane)、数据面(Data Plane)这两部分组成。其中控制面主要承担整个微服务体系治理信息的集中管控;而数据面则负责具体执行由控制面下发的各类服务治理信息及规则。例如服务节点信息的发现、以及本文所讲述的熔断、限流规则等都是通过控制面统一下发至各数据面节点的。
数据面就是一个个代理服务,在Service Mesh体系下每个具体的微服务实例都会自动创建一个与之对应的代理,这个代理服务就是我们俗称的边车(SideCar)。这些代理会主动劫持所代理的微服务实例的入口流量和出口流量,从而根据控制面下发的服务治理信息实现路由发现、负载均衡、熔断、限流等系列逻辑。
从中可以看出,在Service Mesh微服务架构中,各个具体的微服务之间不再直接发生连接,而是转由各自的SideCar代理实现,因此在应用形态上就形成了一组由代理所组成的网状交互结构,这就是服务网格名称的由来。具体如下图所示:
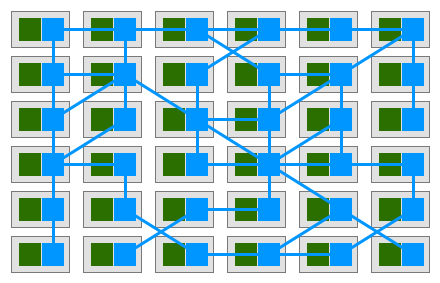
将微服务治理逻辑从原先具体的微服务进程中抽离出来,并实现由统一控制面管理、代理数据面执行的体系结构,这就是Service Mesh微服务体系与Spring Cloud传统微服务体系在架构上最大的区别。
本文所提到的熔断、限流逻辑,也是在这样的架构模式下实现的。而控制面与数据面之间的具体通信则是通过一组被称为xDS协议的数据交互方式实现。xDS协议的核心是定义了一套可扩展的通用微服务控制API,这些API不仅可以做到服务发现、还可以做到路由发现,可以说Service Mesh微服务体系中所有与服务治理相关的配置都可以通过xDS所提供的发现方式来实现,控制面与数据面之间正是通过这种全新的方案实现了各类数据的获取、及动态资源的变更。
而具体来说xDS包含LDS(监听发现服务)、CDS(集群发现服务)、EDS(节点发现服务)、SDS(密钥发现服务)和RDS(路由发现服务)。xDS中的每种类型都会对应一个发现资源,而本文所要讲述的熔断、限流逻辑则是由RDS(路由发现服务)实现。由于篇幅的关系,就不展开讲了,感兴趣的读者可以看看官方文档,大家对此有个印象即可!
Istio服务网格熔断、限流实践
前面从整体架构的角度简单分析了Service Mesh微服务治理体系的基本原理,接下来将基于Istio并结合微服务实战案例,从实践角度具体演示如何实现微服务之间的熔断、限流配置。以下操作假设你已经在Kubernetes集群安装了Istio,并正常部署了<<干货|如何步入Service Mesh微服务架构时代>><<实战|Service Mesh微服务架构实现服务间gRPC通信>>所演示的微服务案例。
Istio无需对代码进行任何更改就可以为应用增加熔断和限流功能。Istio中熔断和限流在DestinationRule的CRD资源的TrafficPolicy中设置,通过设置连接池(connectionPool)实现限流、设置异常检测(outlierDetection)实现熔断。
限流逻辑演示
在Istio中,微服务的限流主要是通过设置connectionPool参数实现。该参数可以对上游服务的并发连接数和请求数进行限制(适用于TCP和HTTP),从而实现限流功能。例如要在API服务层实现限流,链路示意图如下:
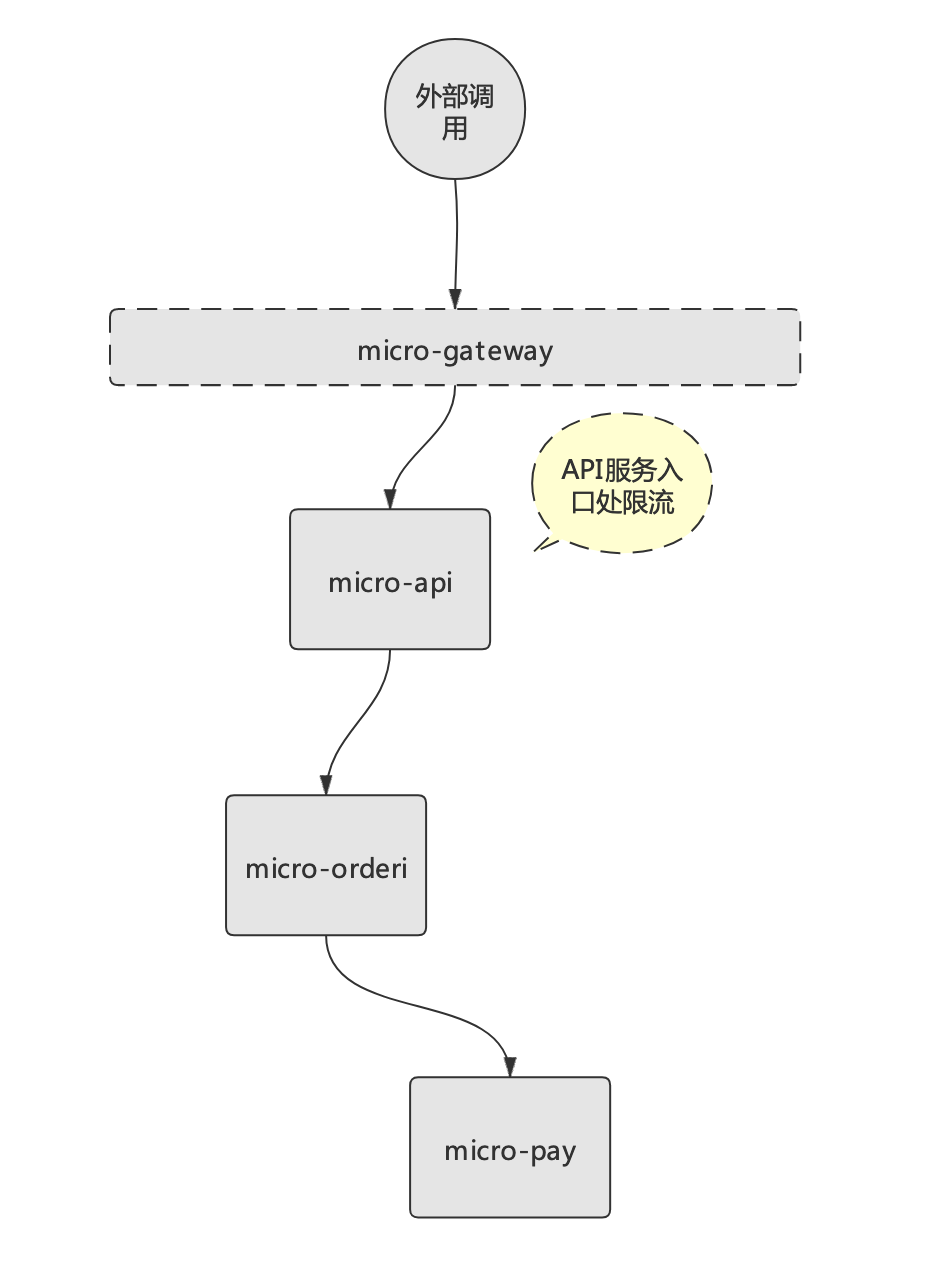
在Istio中实现此类限流逻辑,步骤如下:
1)、创建统一管理路由规则的配置文件(destination-rule-all.yaml),如:
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: micro-api
spec:
host: micro-api
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
---
上述规则文件定义了针对mico-api服务的限流规则,其中maxConnections(最大连接数为1)、http1MaxPendingRequests(最大等待请求数为1),如果连接和并发请求数超过1个,那么该服务就会触发限流规则。
创建规则资源,命令如下:
$ kubectl apply -f destination-rule-all.yaml
destinationrule.networking.istio.io/micro-api unchanged
规则创建完后可以通过命令查看规则,命令如下:
$ kubectl get destinationrule micro-api -o yaml
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
...
spec:
host: micro-api
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
maxConnections: 1可以看到,规则资源已经成功创建!2)、部署压测工具,验证限流效果
接下来,通过部署Istio提供的压测工具fortio,模拟调用微服务并触发限流规则。部署fortio命令如下:
$ kubectl apply -f samples/httpbin/sample-client/fortio-deploy.yaml
找到Istio安装目录“samples/httpbin/sample-client”后执行上述部署命令。
接下来通过fortio工具模拟压测mico-api服务接口,命令如下:
#将fortio服务pod信息写入系统变量
$ export FORTIO_POD=$(kubectl get pods -lapp=fortio -o 'jsonpath={.items[0].metadata.name}')
#通过设置2个线程,并发调用20次进行压测
$ kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 2 -qps 0 -n 20 -loglevel Warning -H "Content-Type:application/json" -payload '{"businessId": "51210428001784966", "amount":100, "channel":1}' http://10.211.55.12:31107/api/order/create
压测数据效果如下:
11:18:54 I logger.go:127> Log level is now 3 Warning (was 2 Info)
Fortio 1.11.3 running at 0 queries per second, 2->2 procs, for 20 calls: http://10.211.55.12:31107/api/order/create
Starting at max qps with 2 thread(s) [gomax 2] for exactly 20 calls (10 per thread + 0)
11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
Ended after 262.382465ms : 20 calls. qps=76.225
Aggregated Function Time : count 20 avg 0.025349997 +/- 0.01454 min 0.001397264 max 0.049622545 sum 0.506999934
# range, mid point, percentile, count
>= 0.00139726 <= 0.002 , 0.00169863 , 15.00, 3
> 0.003 <= 0.004 , 0.0035 , 20.00, 1
> 0.016 <= 0.018 , 0.017 , 25.00, 1
> 0.018 <= 0.02 , 0.019 , 30.00, 1
> 0.02 <= 0.025 , 0.0225 , 50.00, 4
> 0.025 <= 0.03 , 0.0275 , 65.00, 3
> 0.03 <= 0.035 , 0.0325 , 70.00, 1
> 0.035 <= 0.04 , 0.0375 , 80.00, 2
> 0.04 <= 0.045 , 0.0425 , 95.00, 3
> 0.045 <= 0.0496225 , 0.0473113 , 100.00, 1
# target 50% 0.025
# target 75% 0.0375
# target 90% 0.0433333
# target 99% 0.048698
# target 99.9% 0.0495301
Sockets used: 6 (for perfect keepalive, would be 2)
Jitter: false
Code 200 : 16 (80.0 %)
Code 503 : 4 (20.0 %)
Response Header Sizes : count 20 avg 148.8 +/- 74.4 min 0 max 186 sum 2976
Response Body/Total Sizes : count 20 avg 270.8 +/- 2.4 min 266 max 272 sum 5416
All done 20 calls (plus 0 warmup) 25.350 ms avg, 76.2 qps
在可以看到20次请求,共成功16次,4次被限流后返回了503。查看istio-proxy状态日志,命令如下:
$ kubectl exec "$FORTIO_POD" -c istio-proxy -- pilot-agent request GET stats | grep micro-api | grep pending
cluster.outbound|19090||micro-api.default.svc.cluster.local.circuit_breakers.default.rq_pending_open: 0
cluster.outbound|19090||micro-api.default.svc.cluster.local.circuit_breakers.high.rq_pending_open: 0
cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_active: 0
cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_failure_eject: 0
cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_overflow: 0
cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_total: 0从上述日志可以看出micro-api服务的限流规则被触发了!
熔断逻辑演示
熔断是减少服务异常、降低服务延迟的一种设计模式,如果在一定时间内服务累计发生错误的次数超过了预定义阀值,Istio就会将该错误的服务从负载均衡池移除,当超过一段时间后,又会将服务再移回服务负载均衡池。
具体来说Istio引入了异常检测来完成熔断功能,通过周期性的动态异常检测来确定上游服务(被调用方)中的某些实例是否异常,如果发现异常就将该实例从连接池中隔离出去,这就是异常值检测。例如对于HTTP服务,如果API调用连续返回5xx错误,则在一定时间内连接池拒绝此服务;而对于TCP服务,一个主机连接超时/失败次数达到一定次数就认为是连接错误。
隔离不是永久的,会有一个时间限制。当实例被隔离后会被标记为不健康,并且不会被加入到负载均衡池中。具体的隔离时间等于envoy中“outlier_detection.baseEjectionTime”的值乘以实例被隔离的次数。经过规定的隔离时间后,被隔离的实例将会自动恢复过来,重新接受调用方的远程调用。
回到熔断演示案例,假设micro-pay服务不稳定,micro-order服务要实现对该服务的熔断策略,链路示意图如下:
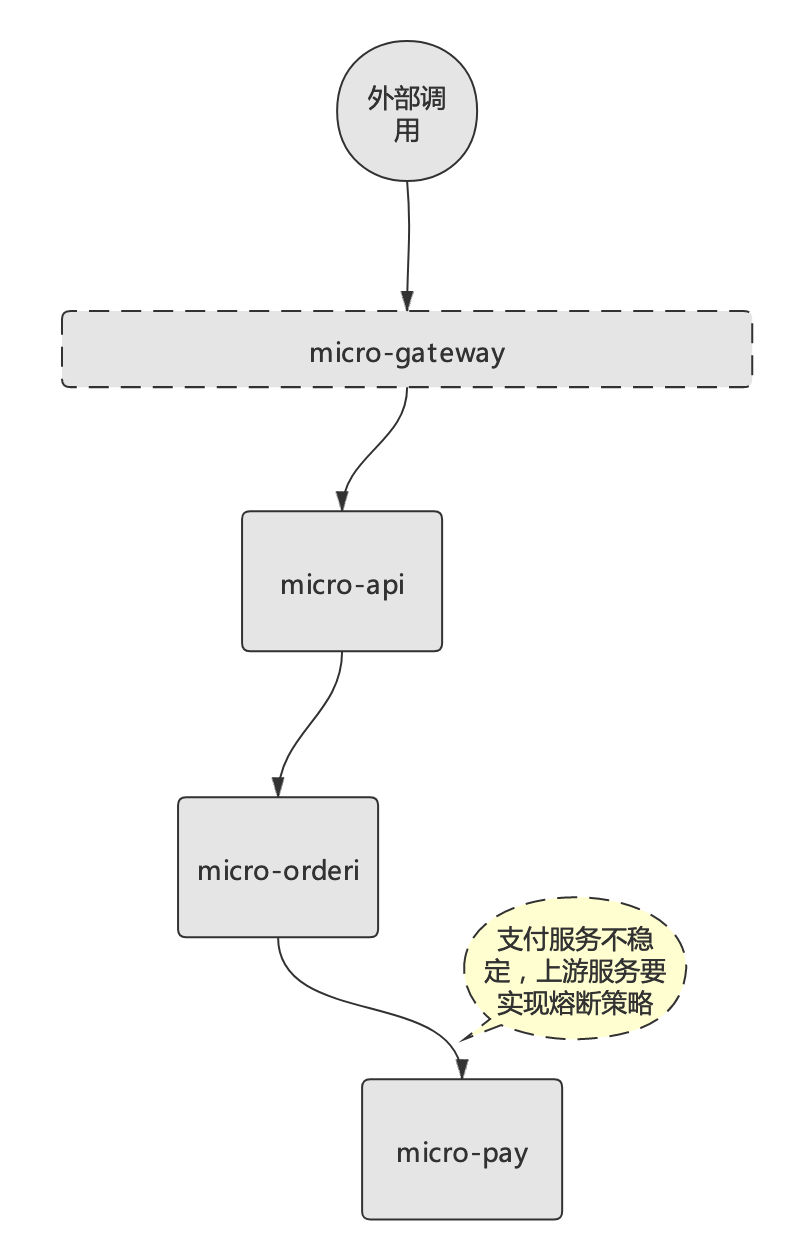
与限流配置类似,Istio的熔断逻辑也是基于“DestinationRule”资源。针对micro-pay微服务的熔断规则配置如下(可在destination-rule-all.yaml文件增加配置):
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: micro-pay
spec:
host: micro-pay
trafficPolicy:
#限流策略
connectionPool:
tcp:
maxConnections: 1
http:
#http2MaxRequests: 1
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
#熔断策略
outlierDetection:
consecutive5xxErrors: 1
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 100
---
如上配置,为了演示micro-pay的报错情况,这里也针对该微服务配置了限流规则。而熔断策略配置的意思是:“每1秒钟(interval)扫描一次上游主机(mico-pay)实例的情况,连续失败1次返回5xx码(consecutive5xxErrors)的所有实例,将会被移除连接池3分钟(baseEjectionTime)”。
应用该规则,命令如下:
$ kubectl apply -f destination-rule-all.yaml
之后可通过压测工具(与限流方式类似),测试触发熔断规则的情况。具体查看方式如下:
# kubectl exec -it $FORTIO_POD -c istio-proxy -- sh -c 'curl localhost:15000/stats' | grep micro-pay | grep outlier
如触发成功,则可以查看到的信息如下:
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_active: 1
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_consecutive_5xx: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_5xx: 2
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_gateway_failure: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_local_origin_failure: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_failure_percentage: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_local_origin_failure_percentage: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_local_origin_success_rate: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_success_rate: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_5xx: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_gateway_failure: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_local_origin_failure: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_failure_percentage: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_local_origin_failure_percentage: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_local_origin_success_rate: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_success_rate: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_total: 1
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_overflow: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_success_rate: 0
cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_total: 0
具体的触发需要模拟上游服务失败的情况,可以通过编写错误代码的方式进行模拟!
后记
本文从原理到实践比较详细地介绍了以Istio为代表的Service Mesh微服务架构实现熔断、限流的基本方法。希望本文可以帮助各位老铁进一步理解服务网格的架构内涵,并打开大家学习Service Mesh微服务架构的大门!如果本文对你有所帮助,不妨点赞+转发支持下!你们的支持将是作者笔耕不辍的动力!
—————END—————
推荐阅读
实战|Service Mesh微服务架构实现服务间gRPC通信
Kubernetes学习环境难搭建?Mac笔记本上安装一个!
参考文档:
#Istio 流量管理官方文档(英文版)
https://istio.io/latest/docs/concepts/traffic-management/#introducing-istio-traffic-management
#Istio Fault Injection介绍
https://istio.io/latest/docs/tasks/traffic-management/fault-injection/
#网文参考
https://www.kubernetes.org.cn/5556.html