
二次元新玩法!生成不同风格小姐姐动漫形象,肤色、发型皆可变
点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达
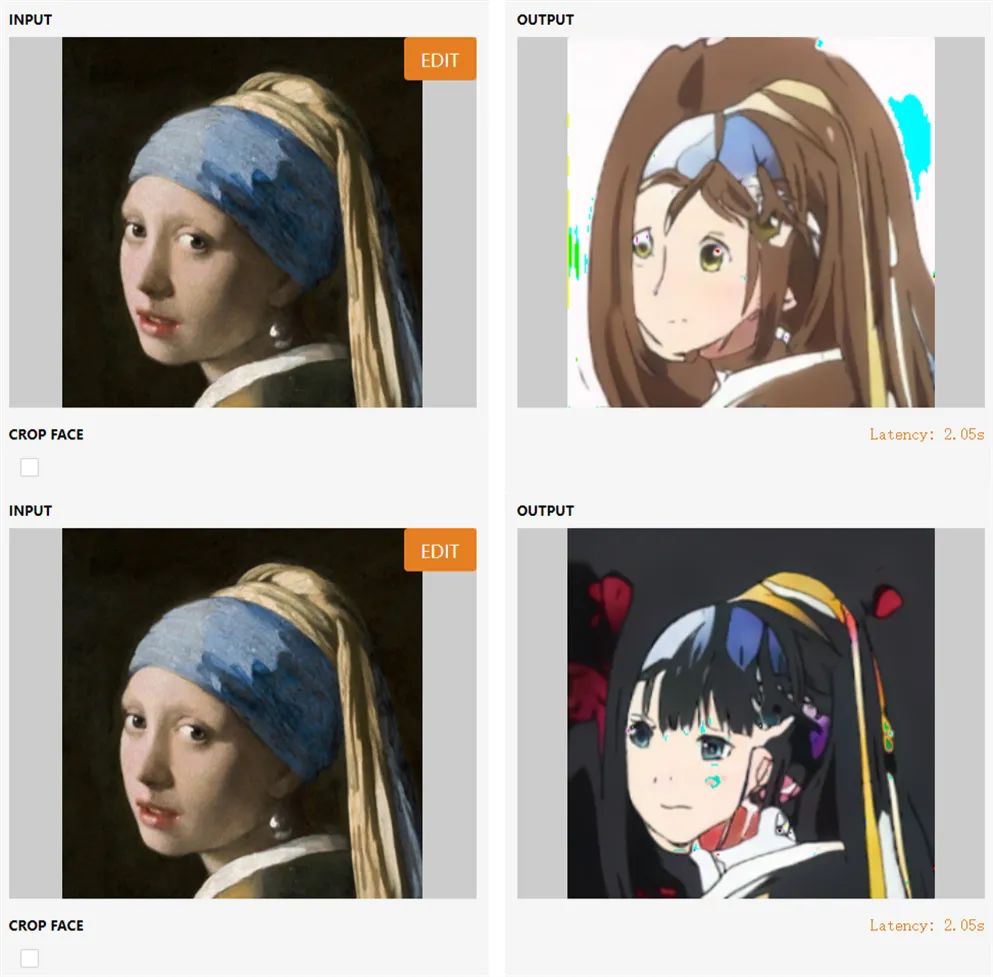
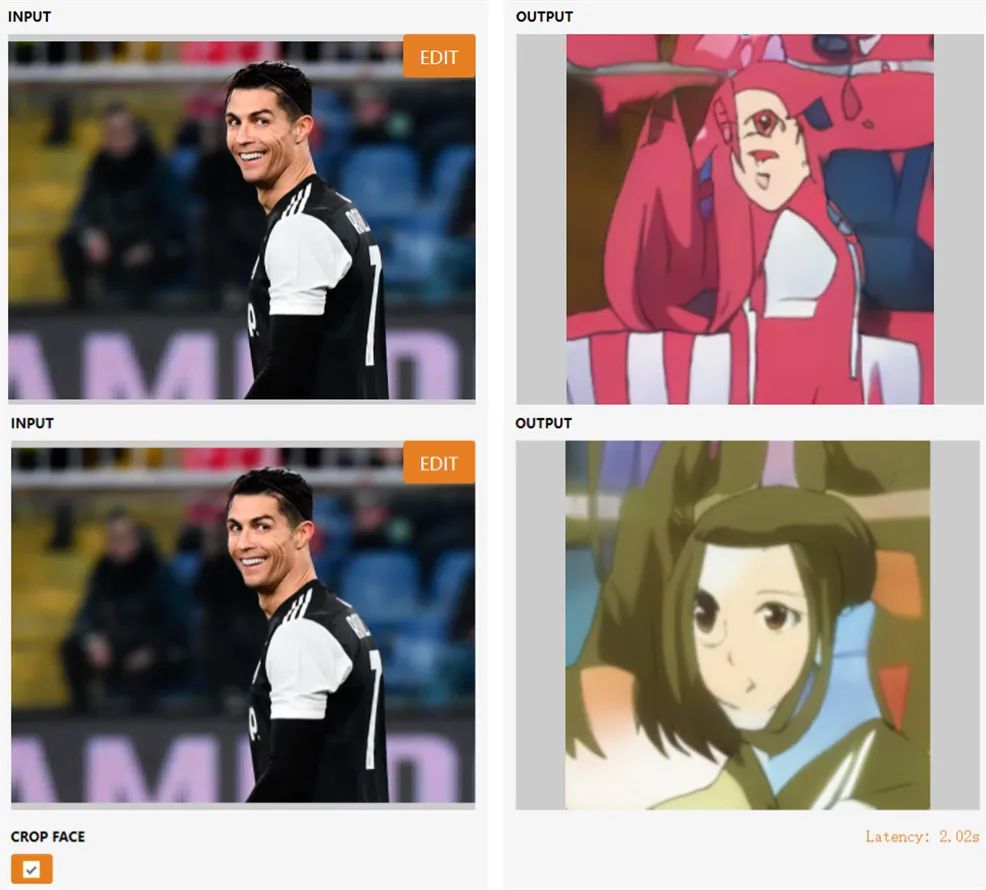
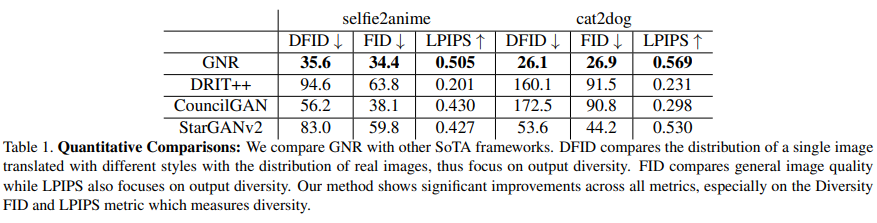
一张输入人脸图像,竟能生成多样化风格的动漫形象。伊利诺伊大学香槟分校的研究者做到了,他们提出的全新 GAN 迁移方法实现了「一对多」的生成效果。
首先是控制(control):通过改变输入人脸来改变动漫人脸的内容(如动漫人脸应该随着输入人脸的转头而转头);
其次是一致性(consistency):使用相同潜变量渲染成动漫的真实人脸应在风格上高度匹配(如不改变潜变量的前提下,动漫人脸不会随输入人脸的转头而改变风格);
最后是覆盖范围(coverage):每个动漫人脸都可以使用内容和风格的组合来获取,这样就可以利用所有可能的动漫形象。

论文地址:https://arxiv.org/pdf/2106.06561.pdf
GitHub 项目地址:https://github.com/mchong6/GANsNRoses

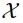 、
、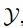
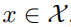 ,目标是在域中生成一组不同的
,目标是在域中生成一组不同的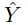 ,使其具有与 x 相似的语义内容。该研究详细阐述了从域 到的转换细节。如图 2 所示,GANs N’ Roses 由一个编码器 E 和一个解码器 F 组成,这两个编码器可用于
,使其具有与 x 相似的语义内容。该研究详细阐述了从域 到的转换细节。如图 2 所示,GANs N’ Roses 由一个编码器 E 和一个解码器 F 组成,这两个编码器可用于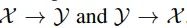 这两个方向。编码器 E 将图像 x 分解为内容编码 c(x) 和风格编码 s(x)。解码器 F 接收内容编码和风格编码,并从 生成合适的图像。
这两个方向。编码器 E 将图像 x 分解为内容编码 c(x) 和风格编码 s(x)。解码器 F 接收内容编码和风格编码,并从 生成合适的图像。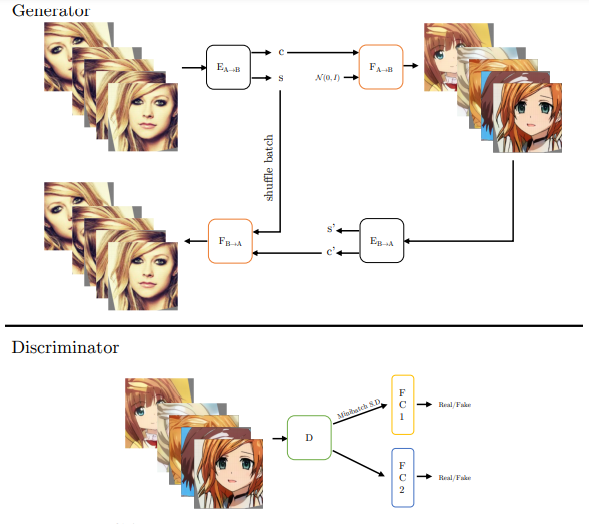
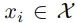 表示从数据中随机选择的单个图像,T(·) 表示对该图像应用随机选择的增强的函数,P(C) 表示内容编码的分布,P(Y) 表示真实动漫(等)的真实分布,为生成的动漫图像。这里必须有 c(xi) ∼ P(C)。因为风格定义为在增强下不会改变的内容,合理选择的增强应该意味着 c(T(x_i)) ∼ P(C) , 即对图像应用随机增强会导致内容编码是先前内容编码的示例。这个假设是合理的,如果它被严重违反,那么图像增强训练分类器将不起作用。
表示从数据中随机选择的单个图像,T(·) 表示对该图像应用随机选择的增强的函数,P(C) 表示内容编码的分布,P(Y) 表示真实动漫(等)的真实分布,为生成的动漫图像。这里必须有 c(xi) ∼ P(C)。因为风格定义为在增强下不会改变的内容,合理选择的增强应该意味着 c(T(x_i)) ∼ P(C) , 即对图像应用随机增强会导致内容编码是先前内容编码的示例。这个假设是合理的,如果它被严重违反,那么图像增强训练分类器将不起作用。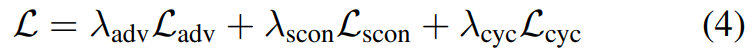





努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论