AI打斗地主,除了信息不完全,还要学会合作与竞争。
众所周知,AI 在围棋上的实力是人类所不能及的。不过斗地主还不一定。在 2017 年 AlphaGo 3 比 0 战胜中国棋手,被授予职业九段之后,柯洁决定参加斗地主比赛,并获得了冠军。在当时的赛后采访中,柯洁表示很欢乐,希望以后再多拿一些冠军,无论什么样的冠军都想拿!
但是好景不长,在这种随机性更高的游戏上, AI 紧随而至。近日,快手 AI 平台部的研究者用非常简单的方法在斗地主游戏中取得了突破,几天内就战胜了所有已知的斗地主打牌机器人,并达到了人类玩家水平。而且,实现这个研究只需要一个普通的四卡 GPU 服务器。随着斗地主 AI 的不断进化,人(Ke)类(Jie)的斗地主冠军宝座不知还能否保住。人工智能在很多棋牌类游戏中取得了很大的成功,例如阿尔法狗(围棋)、冷扑大师(德州扑克)、Suphx(麻将)。但斗地主却因其极大的状态空间、丰富的隐含信息、复杂的牌型和并存的合作与竞技,一直以来被认为是一个极具挑战的领域。近日,快手 AI 平台部在斗地主上取得了突破,提出了首个从零开始的斗地主人工智能系统——斗零(DouZero)。比较有趣的是,该系统所使用的算法极其简单却非常有效。团队创新性地将传统的蒙特卡罗方法(即我们初高中课本中常说的「用频率估计概率」)与深度学习相结合,并提出了动作编码机制来应付斗地主复杂的牌型组合。该算法在不借助任何人类知识的情况下,通过自我博弈学习,在几天内战胜了所有已知的斗地主打牌机器人,并达到了人类玩家水平。相关论文已被国际机器学习顶级会议 ICML 2021 接收,论文代码也已开源。同时,论文作者开放了在线演示平台供研究者和斗地主爱好者体验。论文链接:https://arxiv.org/abs/2106.06135
GitHub 链接:https://github.com/kwai/DouZero
在线演示:(电脑打开效果更佳;如果访问太慢,可从 GitHub 上下载并离线安装:https://github.com/datamllab/rlcard-showdown)
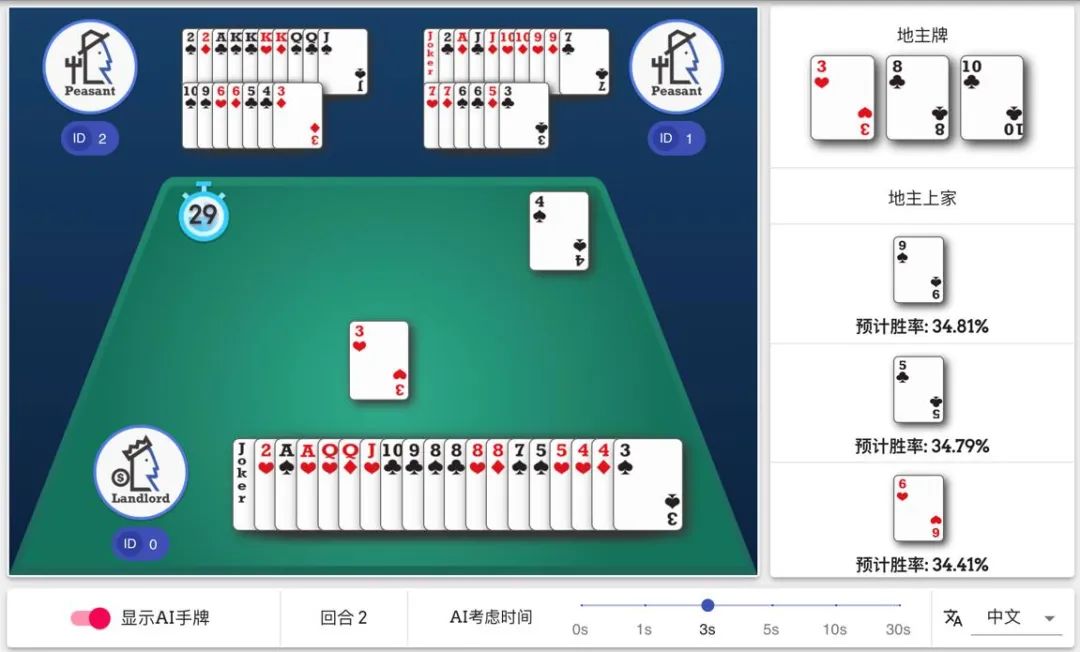
在线演示支持中文和英文。使用者可以选择明牌 / 暗牌,并可以调节 AI 出牌速度。在明牌模式下,用户可以看到 AI 预测出的最好的三个牌型和预计胜率。一直以来,斗地主都被视为一个极具挑战性的领域。首先,与许多扑克游戏和麻将一样,斗地主属于非完美信息游戏(玩家不能看到其他玩家的手牌),且包含很多「运气」成分。因此,斗地主有非常复杂的博弈树,以及非常大的状态空间(每个状态代表一种可能遇到的情况)。除此之外,相较于德州扑克和麻将,斗地主还有两个独特的挑战:- 合作与竞争并存:无论是德州扑克还是麻将,玩家之间都是竞争关系。然而,在斗地主中,两个农民玩家要相互配合对抗地主。虽然过去有论文研究过游戏中的合作关系 [1],但是同时考虑合作和竞争仍然是一个很大的挑战。
- 庞大而复杂的牌型:斗地主有复杂的牌型结构,例如单张、对子、三带一、顺子、炸弹等等。
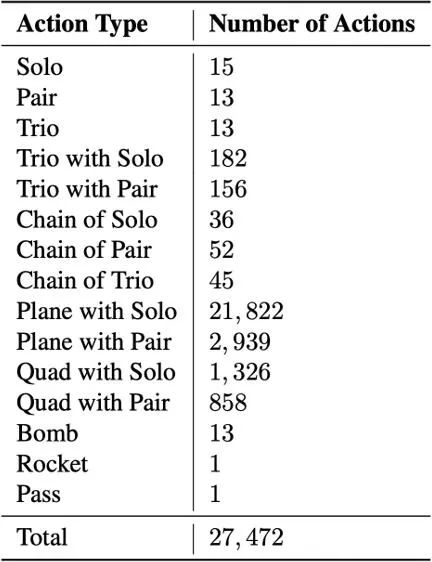
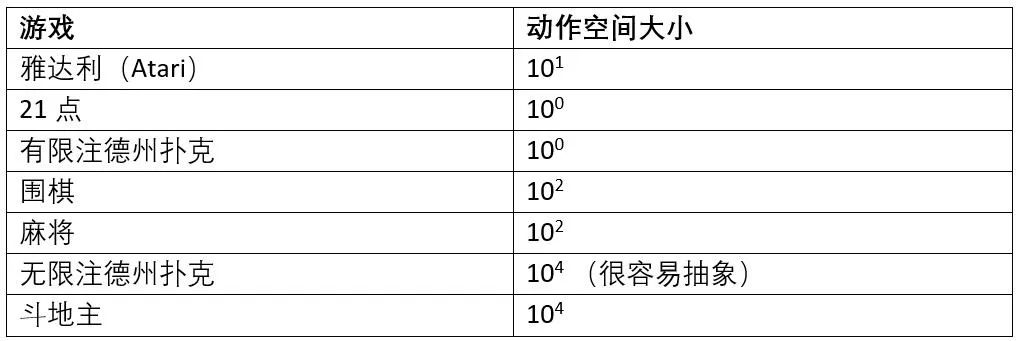
它们的组合衍生出了 27,472 种牌型 [2]:在强化学习里,这些牌型被称为动作空间。作为对比,这里列举出了常见强化学习环境及棋牌类游戏的动作空间大小:虽然无限注德州扑克本身有与斗地主有相同数量级的动作空间,但是其动作空间很容易通过抽象的方式缩小,即把类似的动作合并成一个。例如,加注 100 和加注 101 没有很大的区别,可以合并成一个。然而,斗地主中一个动作中的每张牌都很重要,且很难进行抽象。例如,三带一中带的单张可以是任意手牌。选错一次(比如拆掉了一个顺子)就很可能导致输掉整局游戏。几乎所有的强化学习论文都只考虑了很小动作集的情况,例如最常用的环境雅达利只有十几个动作。有部分论文考虑了较大动作集的环境,但一般也只有几百个。斗地主却有上万个可能的动作,并且不同状态有不同的合法动作子集,这无疑给设计强化学习算法带来了很大挑战。之前的研究表明,常用的强化学习算法,如 DQN 和 A3C,在斗地主上仅仅略微好于随机策略[2][3]。比较有趣的是,斗零的核心算法极其简单。斗零的设计受启发于蒙特卡罗方法(Monte-Carlo Methods)[4]。具体来说,算法的目标是学习一个价值网路。网络的输入是当前状态和一个动作,输出是在当前状态做这个动作的期望收益(比如胜率)。简单来说,价值网络在每一步计算出哪种牌型赢的概率最大,然后选择最有可能赢的牌型。蒙特卡罗方法不断重复以下步骤来优化价值网络:- 记录下该对局中所有的状态、动作和最后的收益(胜率)
- 将每一对状态和动作作为网络输入,收益作为网络输出,用梯度下降对价值网络进行一次更新
其实,所谓的蒙特卡罗方法就是一种随机模拟,即通过不断的重复实验来估计真实价值。在初高中课本中,我们学过「用频率估计概率」,这就是典型的蒙特卡罗方法。以上所述是蒙特卡罗方法在强化学习中的简单应用。然而,蒙特卡罗方法在强化学习领域中被大多数研究者忽视。学界普遍认为蒙特卡罗方法存在两个缺点:1. 蒙特卡罗方法不能处理不完整的状态序列。2. 蒙特卡罗方法有很大的方差,导致采样效率很低。然而,作者却惊讶地发现蒙特卡罗方法非常适合斗地主。首先,斗地主可以很容易产生完整的对局,所以不存在不完整的状态序列。其次,作者发现蒙特卡罗方法的效率其实并没有很低。因为蒙特卡罗方法实现起来极其简单,我们可以很容易通过并行化来采集大量的样本以降低方差。与之相反,很多最先进的强化学习算法虽然有更好的采样效率,但是算法本身就很复杂,因此需要很多计算资源。综合来看,蒙特卡罗方法在斗地主上运行时间(wall-clock time)并不一定弱于最先进的方法。除此之外,作者认为蒙特卡罗方法还有以下优点:- 很容易对动作进行编码。斗地主的动作与动作之前是有内在联系的。以三带一为例:如果智能体打出 KKK 带 3,并因为带牌带得好得到了奖励,那么其他的牌型的价值,例如 JJJ 带 3,也能得到一定的提高。这是由于神经网络对相似的输入会预测出相似的输出。动作编码对处理斗地主庞大而复杂的动作空间非常有帮助。智能体即使没有见过某个动作,也能通过其他动作对价值作出估计。
- 不受过度估计(over-estimation)的影响。最常用的基于价值的强化学习方法是 DQN。但众所周知,DQN 会受过度估计的影响,即 DQN 会倾向于将价值估计得偏高,并且这个问题在动作空间很大时会尤为明显。不同于 DQN,蒙特卡罗方法直接估计价值,因此不受过度估计影响。这一点在斗地主庞大的动作空间中非常适用。
- 蒙特卡罗方法在稀疏奖励的情况下可能具备一定优势。在斗地主中,奖励是稀疏的,玩家需要打完整场游戏才能知道输赢。DQN 的方法通过下一个状态的价值估计当前状态的价值。这意味着奖励需要一点一点地从最后一个状态向前传播,这可能导致 DQN 更慢收敛。与之相反,蒙特卡罗方法直接预测最后一个状态的奖励,不受稀疏奖励的影响。
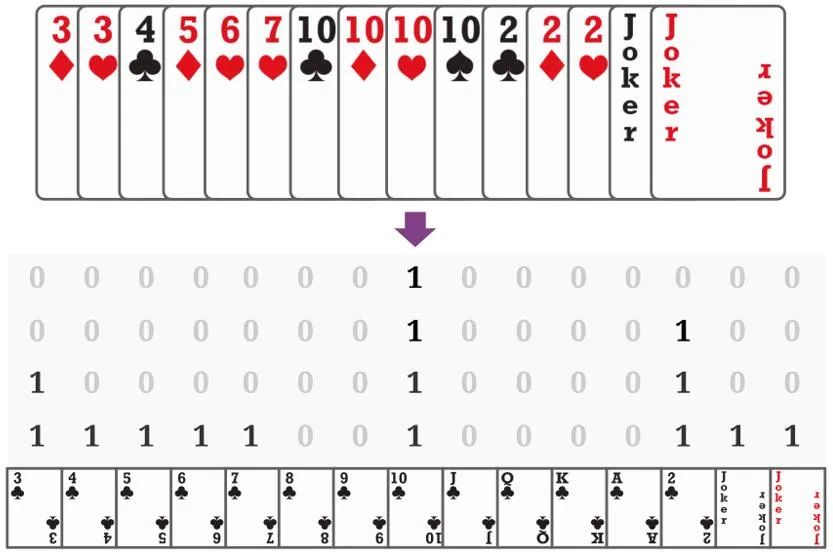
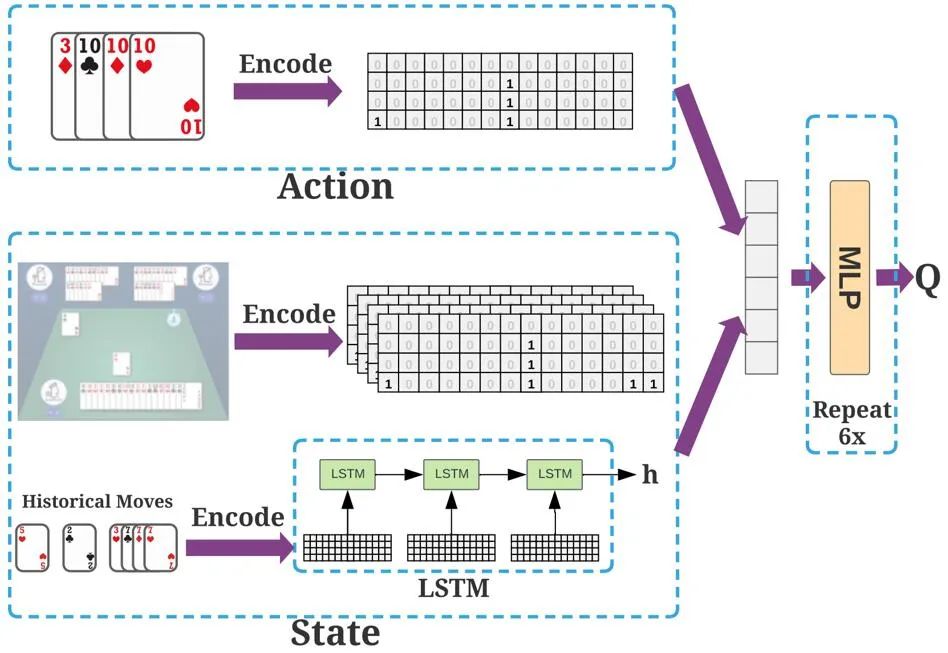
斗零系统的实现也并不复杂,主要包含三个部分:动作 / 状态编码、神经网络和并行训练。如下图所示,斗零将所有的牌型编码成 15x4 的由 0/1 组成的矩阵。其中每一列代表一种牌,每一行代表对应牌的数量。例如,对于 4 个 10,第 8 列每一行都是 1;而对于一个 4,第一行只有最后一行是 1。这种编码方式可适用于斗地主中所有的牌型。斗零提取了多个这样的矩阵来表示状态,包括当前手牌,其他玩家手牌之和等等。同时,斗零提取了一些其他 0/1 向量来编码其他玩家手牌的数量、以及当前打出的炸弹数量。动作可以用同样的方式进行编码。如下图所示,斗零采用一个价值神经网络,其输入是状态和动作,输出是价值。首先,过去的出牌用 LSTM 神经网络进行编码。然后 LSTM 的输出以及其他的表征被送入了 6 层全连接网络,最后输出价值。系统训练的主要瓶颈在于模拟数据的生成,因为每一步出牌都要对神经网络做一次前向传播。斗零采用多演员(actor)的架构,在单个 GPU 服务器上,用了 45 个演员同时产生数据,最终数据被汇集到一个中央训练器进行训练。比较有趣的是,斗零并不需要太多的计算资源,仅仅需要一个普通的四卡 GPU 服务器就能达到不错的效果。这可以让大多数实验室轻松基于作者的代码做更多的尝试。为验证斗零系统的有效性,作者做了大量的实验。这里我们选取部分实验结果。作者将斗零和多个已有的斗地主 AI 系统进行了对比,具体包括:- DeltaDou [5] 是首个达到人类玩家水平的 AI。算法主要基于贝叶斯推理和蒙特卡罗树搜索,但缺点是需要依赖很多人类经验,并且训练时间非常长。即使在用规则初始化的情况下,也需要训练长达两个月。
- CQN [3] 是一个基于牌型分解和 DQN 的一种方法。虽然牌型分解被证明有一定效果,但是该方法依然不能打败简单规则。
- SL (supervised learning,监督学习)是基于内部搜集的顶级玩家的对战数据,用同样的神经网络结构训练出来的模型。
- 除此之外,作者尽可能搜集了所有已知的规则模型,包括 RHCP、RHCP-v2、RLCard 中的规则模型[2],以及一个随机出牌策略。
斗地主中玩家分为地主和农民两个阵营。作者使用了两个评估指标来比较算法之间的性能:- WP (Winning Percentage) 代表了地主或农民阵营的胜率。算法 A 对算法 B 的 WP 指标大于 0.5 ,代表算法 A 强于算法 B。
- ADP(Average Difference in Points)表示地主或农民的得分情况。每有一个炸弹 ADP 都会翻倍。算法 A 对算法 B 的 ADP 指标大于 0 ,代表算法 A 强于算法 B。
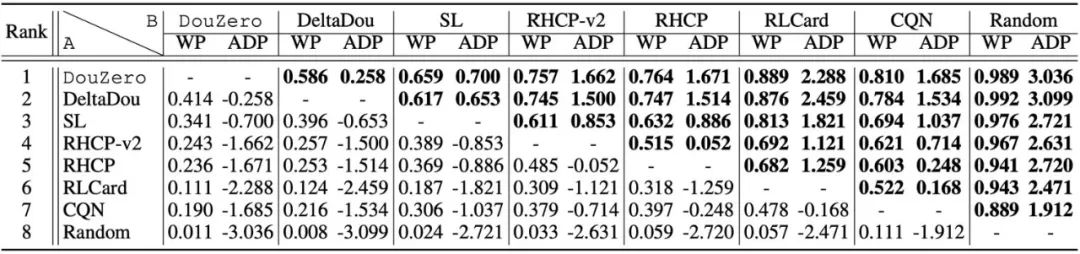
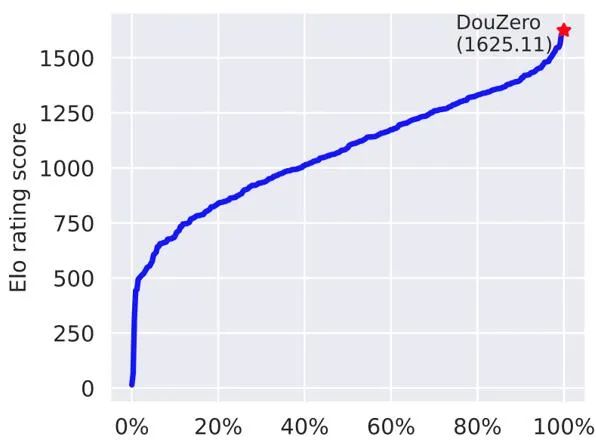
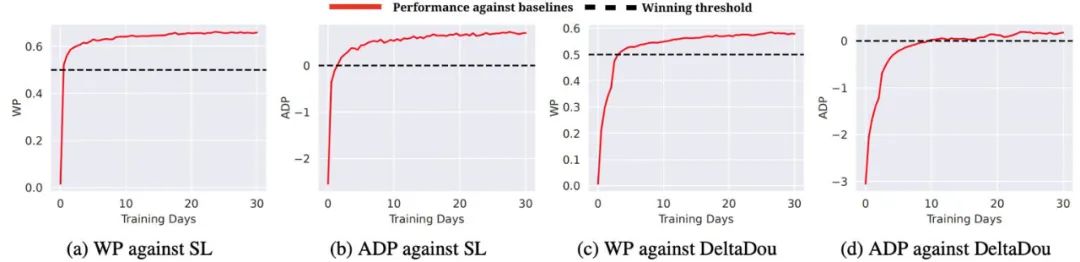
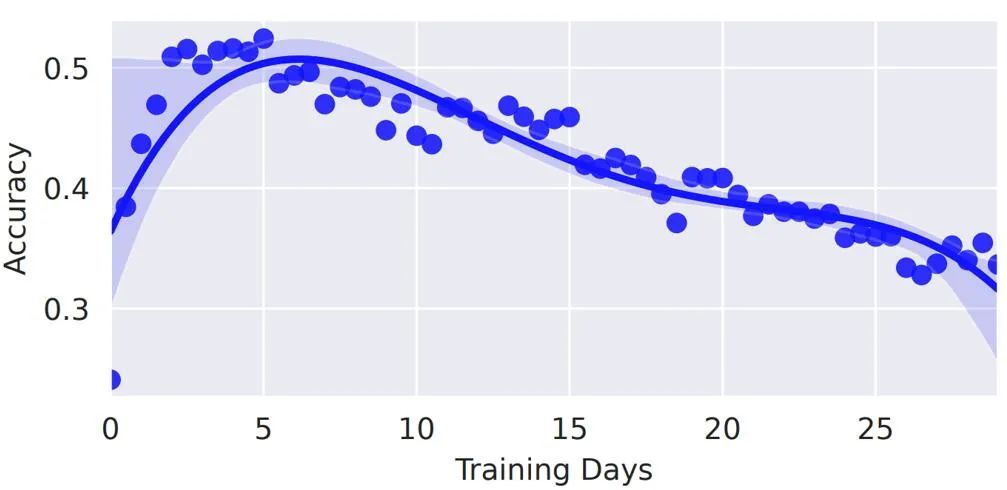
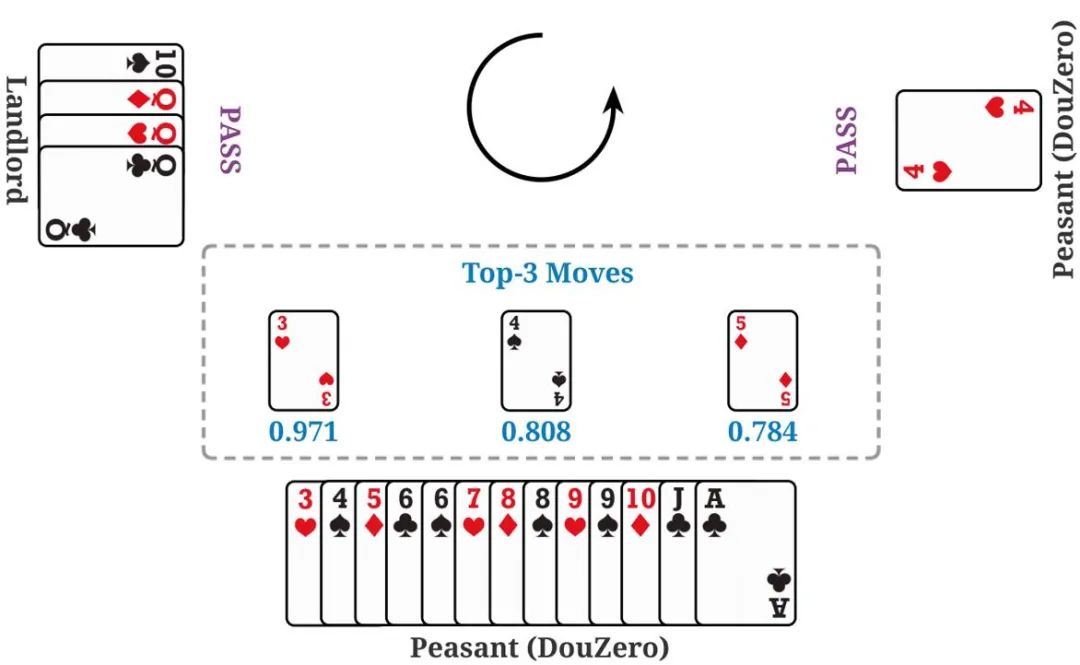
作者比较胜率(WP)和分值(ADP),如下表所示,斗零(DouZero)在两项指标上都明显好于已知方法。值得一提的是,因为斗地主本身有很大的「运气」成分,高几个百分点的胜率就代表很大的提高了。Botzone(https://www.botzone.org.cn/)是由北京大学 AI 实验室开发的在线对战平台,支持多种游戏的在线评测,并举办过多场棋牌类 AI 比赛。作者将斗零上传到了斗地主对战的系统。Botzone 计分结果表明,斗零在 344 个对战机器人中脱颖而出,在 2020 年 10 月 30 日排名第一。作者用 DeltaDou 和 SL 作为对手,测量斗零的训练效率。所有的实验都在一个服务器上进行,该服务器包括 4 个 1080Ti GPU 和 48 核处理器。如下图所示,斗零在两天内超过了 SL,在 10 天内超过了 DeltaDou。斗零究竟学出了什么样的策略呢?作者将人类数据作为测试数据,计算不同阶段的模型在人类数据上的准确率,如下图所示。我们可以发现两个有趣的现象。首先,斗零在前五天的训练中准确率不断提高。这表明斗零通过自我博弈的方式学到了类似于人类的出牌方式。其次,在五天以后,准确率反而下降,这说明斗零可能学到了一些超出人类知识的出牌方式。上文提到,斗地主游戏中两个农民需要配合才能战胜地主。作者为此做了一个案例分析,如下图所示,图中下方农民出一个小牌就能帮助右方农民获胜。图中显示了预测出的最优的三个牌型和预测的价值,我们可以看到预测结果基本符合预期。下方农民「认为」出 3 有非常高的获胜概率,而出 4 或 5 的预期价值会明显变低,因为右方农民的手牌很有可能是 4,结果表明斗零确实学到了一定的合作策略。斗零的成功表明简单的蒙特卡罗算法经过一些加强(神经网络和动作编码)就可以在复杂的斗地主环境上有着非常好的效果。作者希望这个结果能启发未来强化学习的研究,特别是在稀疏奖励、复杂动作空间的任务中。蒙特卡罗算法在强化学习领域一直不受重视,作者也希望斗零的成功能启发其他研究者对蒙特卡罗方法做更深入的研究,更好地理解在什么情况下蒙特卡罗方法适用,什么情况下不适用。为推动后续研究,作者开源了斗地主的模拟环境和所有的训练代码。值得一提的是,斗零可以在普通的服务器上训练,并不需要云计算的支持。作者同时开源了在线演示平台和分析平台,以帮助研究者和斗地主爱好者更好地理解和分析 AI 的出牌行为。鉴于当前的算法极其简单,作者认为未来还有很大的改进空间,比如引入经验回放机制来提高效率、显性建模农民之间的合作关系等等,作者也希望未来能将斗零的技术应用到其他扑克游戏以及更加复杂的问题中。研发团队介绍:这项工作是由 Texas A&M University 的 DATA 实验室和快手 AI 平台部的游戏 AI 团队合作而成。DATA 实验室主要从事数据挖掘和机器学习算法等方面的研究,以更好地从大规模、网络化、动态和稀疏数据中发现可操作的模式。快手游戏 AI 团队,主要依托在最先进的机器学习技术,致力于服务游戏研发,推广,运营等各个环节。[1] Lerer, Adam, et al. "Improving policies via search in cooperative partially observable games." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.
[2] Zha, Daochen, et al. "RLCard: A Platform for Reinforcement Learning in Card Games." IJCAI. 2020.
[3] You, Yang, et al. "Combinational Q-Learning for Dou Di Zhu." arXiv preprint arXiv:1901.08925 (2019).
[4] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
[5] Jiang, Qiqi, et al. "DeltaDou: Expert-level Doudizhu AI through Self-play." IJCAI. 2019.
编辑:于腾凯
校对:王欣