
「大模型」之所短,「知识图谱」之所长
👆点击“博文视点Broadview”,获取更多书讯

近两年,人工智能领域的大模型可谓炙手可热。以自然语言处理领域为例,自BERT横空出世,在各种评测上分数一飞冲天,在斯坦福阅读理解评测集上超越人类水平之后,各种越来越大的自然语言处理模型不断涌现,并在各种评测中不断刷新出新的记录。
图1是近年来不同的预处理模型的情况,可以看出模型规模呈指数级增长。由此,许多人已经对模型越大效果越好(Larger model, better performance)深信不疑,并逐渐形成了AI领域的“军备竞赛”。

图1 “大模型”的参数指数级增长
确实!如果仅仅考虑各种评测,以刷榜为目标的话,这种趋势毫无争议。不管是微软与 OpenAI的Megatron-Turing NLG,还是谷歌的 PaLM,以及国内如智源研究院的悟道、百度文心3.0等,其评测成绩之斐然是有目共睹的。但这一切并不是没有批评的声音。
一方面,这种超大模型的能力是存在争议的,其到底是具备“超级能力”,还是因为其训练语料足够丰富而使得模型仅仅是“记忆”这些内容?进一步地,这种基于深度学习的大模型,还有其天然的难以解释的特点。
另一方面,这种依靠超级计算资源和数据资源打造的大模型,在面对真正的应用时显得心有余而力不足,绝大多数情况下,仅仅适用于“刷个榜”,即使财大气粗,也无法真正使用这些看起来非常美好的“大模型”。
此外,在许多领域的专业应用中,比如尖端医疗器械制造的失效分析,因其语料在广泛的数据中显得数据量如此之少,而在使用这些大模型时毫无优势。
于是,有识之士在这种“超级算力”+“海量数据”+“大模型”的范式之外,提出了以“算法”+“算力”+“数据”+“知识”的新范式。
比如,张钹院士就说过“人的智能没法通过单纯的大数据学习把它学出来,那怎么办?很简单,加上知识,让它有推理的能力,做决策的能力。”
而知识图谱则是人工智能领域中用以存储和表示知识的最新的一种方法,目前正驱动这人工智能的进一步发展,也被认为是实现认知智能的核心技术之一。
事实上,对于芸芸众生,这些大模型“可望而不可及”。
最近几年我一直在达观数据做自然语言处理和知识图谱的技术研究、产品开发和产业落地方面的工作。期间走访了各行各业的头部企业,了解到不管是金融行业的巨头,制造业各细分领域的领头羊还是垄断性大国企,都没有将这些大模型使用在其业务上,用于提升效率、降低成本、提升竞争力等。甚至于人工智能巨头也没有很好地用上这些大模型。
而以知识图谱为核心的认知智能技术,因加入了“知识”这一人类发展经验的总结,使得能够摆脱“大模型”的缺陷,更适合于在各行各业的实践应用。
并且,以知识图谱为核心的认知智能技术,因其计算资源更少,推断结果可解释,进而在产品落地和产业应用中具备了极大的优势。
为了介绍这种具备巨大前景又具有非常实在的产业应用的认知智能技术,我倾注了大量的心血,梳理知识图谱的前沿技术研究成果,总结十多年来在人工智能产品开发和产业应用方面的经验,写下了学术界和企业界十多位知名专家倾力推荐的《知识图谱:认知智能理论与实战》一书。

本书系统全面地介绍了知识图谱的核心技术,既有宏观整体的技术体系,也有关键技术和算法细节,内容包括:
知识图谱模式设计的方法论——六韬法;
知识图谱构建中的实体抽取和关系抽取;
知识存储中的属性图模型及图数据库,重点介绍了JanusGraph分布式图数据库;
知识计算中的图论基础,以及中心性、社区检测等经典图计算算法;
知识推理中的逻辑推理、几何变换推理和深度学习推理,及其编程实例。
最后,本书以金融、医疗和智能制造三大行业的应用场景为例,梳理了知识图谱的应用价值和应用程序形态。
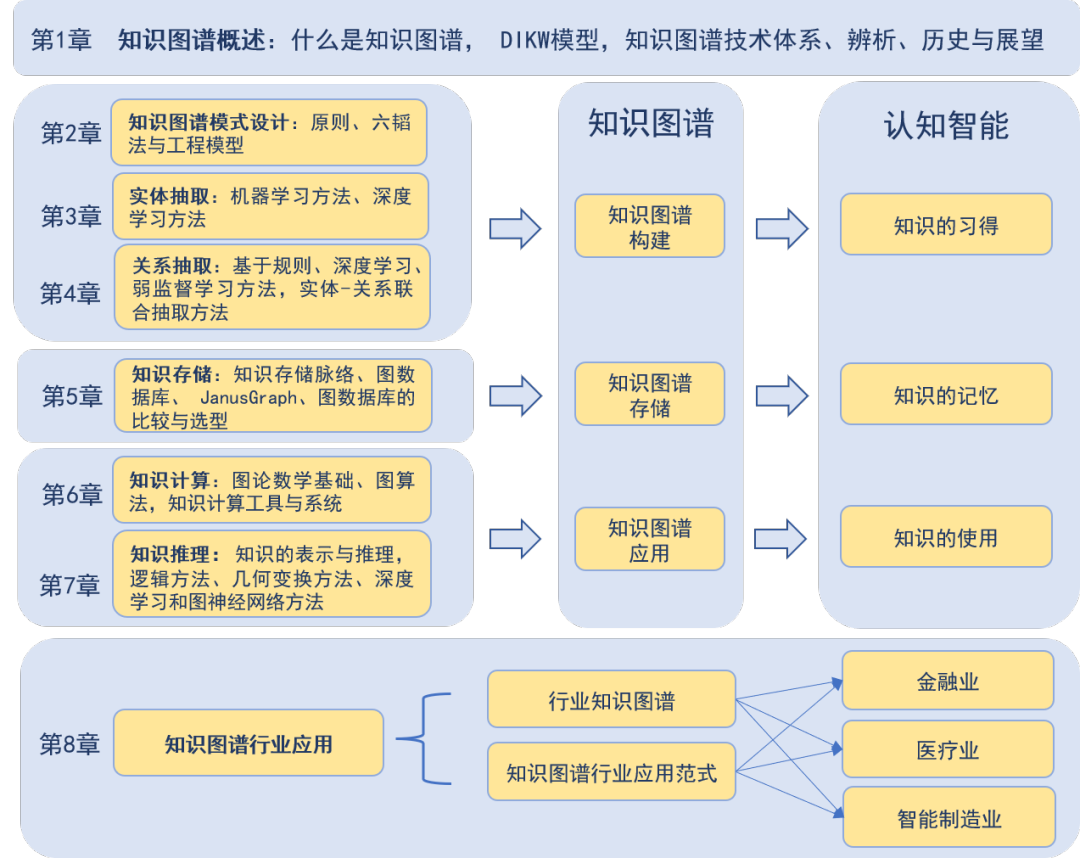
图2 《知识图谱:认知智能理论与实战》内容框架

本书既适合人工智能行业从业者和研究人员系统学习知识图谱,也适合一线工程师和技术人员参考使用,并可作为企业管理人员、政府人员、政策制定人员、公共政策学者的参考材料,以及高等院校计算机、金融和人工智能等相关专业师生的参考资料和培训学校的教材。

知识图谱作为人工智能中知识获取、存储和使用的技术,是弥补深度学习和“大模型”短处的良方,是缝合认知智能前沿技术理论和产业应用的有效方法。“日月丽乎天,百谷草木丽乎土”,知识乃是人工智能不断进步必不可少的养分,因而知识图谱也正是人工智能进步的阶梯。
希望《知识图谱:认知智能理论与实战》这本书能够为读者在探索这个人工智能中提供一点帮助,能够为认知智能的产业应用做出微薄的贡献。


如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,了解本书详情~