2019 年,凭借着 Chirpy Cardinal 机器人,斯坦福首次在 Alexa Prize Socialbot Grand Challenge 3 中赢得了第二名。本文将进一步揭示 Chirpy Cardinal 开发细节,来还原斯坦福团队如何与人机交互过程中常见的疑难杂症过招,并探索相应的解决方案。Alexa Prize 是一个独特的研究环境,它允许研究人员按照自己的意愿来研究人机交互。在比赛期间,美国的 Alexa 用户可以通过“让我们来聊天吧”这句指令,来用英语与一个匿名且随机的参赛机器人对话。在这个过程中,他们可以随时结束对话。由于 Alexa Prize 社交机器人致力于创造尽可能自然的体验,他们需要能应对长时间的、开放领域的社交,尽可能地囊括更多的话题。我们发现 Chirpy 用户对许多不同的主题感兴趣,从时事(比如新冠病毒)到热点(比如《冰雪奇缘 2》)再到个人兴趣(比如用户个人的宠物)。Chirpy 通过使用结合了神经生成和脚本对话的模块化设计来实现对这些话题的覆盖,正如我们此前的文章所述。我们使用此设置研究了有关社交机器人对话的三个问题:1、用户们在吐槽些啥,我们如何从吐槽中学习来改进神经生成的对话?2、哪些策略在处理和阻止冒犯性的用户行为方面有效或者无效?3、我们该如何调整优先权,来让用户和机器人都能有意义地掌控对话?这篇文章将分享一些关键发现,为聊天机器人的研发人员提供一些实用的见解(“数据实战派”后台回复“chatbot”获取 3 篇论文下载地址)。
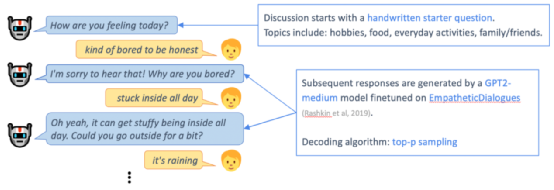
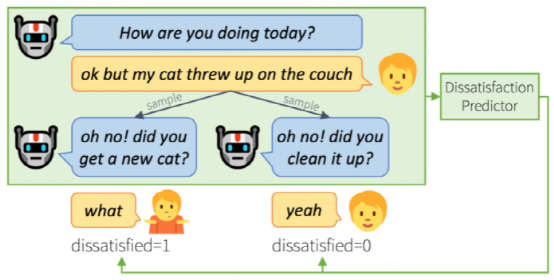
神经生成对话模型(如 DialoGPT、Meena 和 BlenderBot)通过使用大型预训练神经语言模型,在给定历史对话的情况下生成响应。这些模型在工作人员精心设置的情况下(一般是具备某些特定主题或者长度有限制的书面对话)表现良好。然而,像 Alexa Prize 这样的现实生活中的场景,往往无章可循。用户们的期待值和个性差异都非常大,并且对话过程中往往充满了噪音,在这样的环境中,用户们仍然会要求对话机器人快速做出回应。通过 Chirpy Cardinal,我们有了个独特的机会来研究现代神经生成对话模型如何在这种环境中保持稳定。Chirpy Cardinal 使用在 EmpatheticDialogues 上微调的 GPT2-medium 模型,与用户就他们的日常生活和情绪进行简短的讨论。尤其是在疫情期间,我们发现 Chirpy 向用户们询问这些话题十分重要。尽管有更大、更强的预训练模型可以用,但是由于预算和响应速度的限制,我们还是使用了 GPT2-medium。虽然 GPT2-medium 模型能用几句话来围绕这些简单的话题聊天,但是一旦对话时间变长,聊天就会出现偏差,机器人迟早会作出不合理的响应。无论是用户还是模型都很难再让对话恢复正常。为了理解这些对话是如何脱轨的,我们定义了 7 种神经生成模型所犯的错误的类型——重复、多余问题、不清晰的话语、错觉、忽略、逻辑错误、侮辱性话语。在对用户对话样本进行标注后,我们发现机器人的错误很常见,超过了一半(53%)的神经生成语句包含某种错误。我们还发现,由于极具挑战的嘈杂环境(可能涉及背景噪声、串扰和 ASR 错误),几乎四分之一 (22%) 的用户话语无法被理解,即使是人工注释者也是如此。这解释了一些更基本的机器人错误,例如忽略、错觉、不清楚和重复的话语。在其他机器人犯的错误中,多余问题和逻辑错误尤为常见,这表明更好地推理和使用历史对话是神经生成模型开发的优先事项。我们还定位了用户表达不满的 9 种方式,例如要求澄清、批评机器人和结束对话。尽管机器人的错误和用户不满之间存在关系,但这种相关性千丝万缕,纷繁复杂。即使出现机器人错误,许多用户也不会表达不满,而是试图继续对话。在逻辑错误之后尤其如此,其中机器人表现出缺乏现实世界的知识或常识——一些好心的用户甚至将此作为教育机器人的机会。相反,一些用户表达了与任何明显的机器人错误无关的不满——例如,用户对机器人所问的哪些问题是合时宜的有很大不同的期望。在更好地理解了用户表达不满的方式和原因后,我们不禁疑问:我们能否学会预测不满,从而在用户不满之前加以预防?利用在比赛期间收集到的用户对话,我们训练了一个模型来预测某句机器人说的话会导致用户不满的概率。考虑到机器人错误和用户不满之间的复杂相关性,这非常具有挑战性。尽管有这种复杂性,我们的预测模型还是能够找到用户不满的信号。一旦经过训练,我们的不满意预测器就可以在对话中用于在多个备选话语之间进行选择。通过人工评估,我们发现预测器选择的机器人响应——即那些被判断为最不可能引起用户不满的响应——总体上比随机选择的响应质量更好。尽管我们尚未将此反馈循环整合到 Chirpy Cardinal 中,但我们的方法展示了一种可行的方法来实现半监督在线学习方法,以不断改进神经生成对话系统。
语音助手正变得越来越流行,并且在此过程中,它们被越来越多的用户群的滥用。我们估计,超过 10% 的用户与我们的机器人 Chirpy Cardinal 的对话包含亵渎和公然冒犯的语言。虽然有大量此前的工作试图解决这个问题,但大多数先前的方法都使用基于在实验室环境中进行的调查的定性指标。在这项工作中,我们对开放世界中攻击性用户的响应策略进行了大规模的定量评估。在实验中,我们发现礼貌地拒绝用户的冒犯,同时将用户重定向到另一个主题是遏制冒犯的最佳策略。1、重定向——受到 Brahnam 的启发,我们假设在响应冒犯性用户话语时,使用明了的重定向是一种有效的策略。例如,“我宁愿不谈论这个。那么,你最喜欢的音乐家是谁?”2、姓名——受到 Suler、Chen 和 Williams 的启发,我们假设在机器人的响应中包含用户的姓名是一种有效的策略。例如,“我不想谈这个,Peter。”3、疑问——受 Shapior 等人的启发,我们假设礼貌地询问用户他们发表冒犯性言论的原因,引导他们反思自己的行为,从而减少之后可能的冒犯。例如,“你为什么这么说?”4、关怀与问询——受 Chin 等人的启发,我们假设带有感情的回应比一般的回避反应更有效,而反击反应没有作用。例如,一个善解人意的回应是“如果我可以谈论它,我会谈论它,但我真的不能。很抱歉让您失望了”,而反击式回应则是“这是一个非常具有暗示性的说法。我认为我们不应该谈论这个。”我们构建了囊括上述多个因素的响应。例如,回避 + 姓名 + 重定向会产生这样的表达“我宁愿不谈论那个(回避的内容),Peter(姓名)。那么,你最喜欢的音乐家是谁?(重定向)”为了衡量响应策略的有效性,我们提出了 3 个指标:1、再具攻击性——测量在初始机器人响应后包含另一个攻击性语句的对话数量。2、结束——假设未来没有违规行为,以机器人响应后的对话长度来衡量。3、下一个——测量为在用户再次冒犯之前经过的对话数。我们认为,这些指标比 Cohn 等人所做的用户评级更直接地衡量了响应策略的有效性,它衡量了对话的整体质量。正如我们所见,带有(重定向)的策略比不带重定向的策略表现得更好,将再具攻击性的概率降低了 53%。我们的成对假设检验进一步表明,在重定向的基础上带上用户的名字,进一步降低了大约 6% 的再具攻击性的概率,而询问用户为什么他们发表冒犯性言论却让再具攻击性率增加了 3%,这表明询问的效果不尽如人意。感性的回应同样能使再具攻击性率降低 3%,而反击式回应则没有显著的影响。左图显示了直到下一次攻击性语句出现(Next)的平均对话数差异,右图显示了直到对话结束(End)的平均对话数差异。我们再次看到使用重定向的策略能够显着延长非冒犯性对话。这进一步表明重定向是抑制用户冒犯的非常有效的方法。这样做的结果显示,机器人应该始终通过重定向,并以善解人意的方式回应用户的冒犯,并尽可能地使用用户的名字。尽管被动回避和重定向策略具备有效性,我们想提醒研究人员采用类似策略的潜在社会风险。由于大多数基于语音的代理都有默认的女性声音,因此这些策略可能会进一步加深性别刻板印象,并对女性在现实世界中对言语的冒犯行为设定不合理的期望。因此,在部署这些策略时必须谨慎。
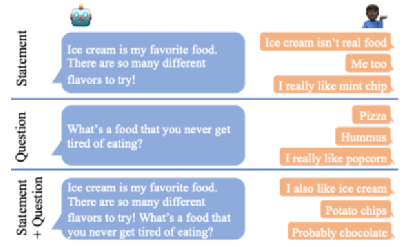
对话要么由用户控制(例如,像 Apple 的 Siri 这样的机器人,它被动地等待用户命令),要么由机器人(例如,CVS 的客户服务机器人,它反复提示用户输入特定信息)。这种属性——用户在给定时刻拥有控制权——被称为主动性。让一个人参加鸡尾酒会并参与每一个主题,而不是给你机会分享自己的兴趣,这会很无趣。同样的,和拒绝谈论自己,而只是强迫你来维持对话的人交流也很乏味。最理想的情况是,每个人轮流回应提示,分享关于自己的事,并且介绍新的话题加入聊天。我们将这种对话模式称为混合主动性,并假设它是一种令人愉快的人与人之间的社交对话,这也是一种更具吸引力和更理想的人机对话形式。我们设计了 Chirpy Cardinal 机器人,通过在每一个转折点提出问题来保持对话向前发展。尽管这有助于防止对话停滞,但也很难使用户采取主动。在我们的数据中,我们观察到用户对此进行了抱怨,例如机器人提出了太多问题,或者这不是用户想要谈论的内容。由于研究主动性的目的是让人类与机器人的对话,更像人类之间的对话,因此我们希望研究人类对话来获得灵感。基于这项研究,我们形成了三个关于如何提高用户主动性的假设。下图展示了测试的话语类型以及具有代表性的用户语句。根据 Alexa Prize 竞赛规则,这些不是机器人收到的实际用户语句。在人类对话研究中,往往提问者更具有主动性,因为他们给出了回答者的方向。相比之下,开放式的陈述句让对方更有机会采取主动。这是我们的第一个策略的基础:使用陈述而不是疑问。人与人之间的对话和人类与机器人对话的研究发现,自我信息的披露具有互惠效应。如果一个参与者分享了他们自己,那么另一个人更有可能做同样的事情。我们假设,如果 Chirpy 提供个人陈述而不是其他的陈述,那么用户会采取主动和回报。左图是一个利用回馈信息的对话示例,右图没有。在这种情况下,回馈允许用户将对话导向他们想要的(获得建议),而不是强迫他们谈论他们不感兴趣的事情(爱好)。反馈信息,例如“hmm”、“I see”和“mm-hmm”,都是简短的话语,用作从听众到演讲者的信号,表明演讲者应该继续主动。我们的最终假设是它们可以用于人机对话以达到相同的效果,即如果我们的机器人反向引导,那么用户将引导对话。为了测试这些策略的效果,我们更改了机器人的不同组件。我们进行了小型实验,只改变了一次谈话,以测试问题与陈述以及个人陈述与一般陈述的效果差异。为了测试在更多对话上用问题替换陈述的效果,我们更改了使用神经生成对话的机器人组件,因为这些组件更灵活地更改用户输入。最后我们在机器人的全神经模块中尝试了用上反馈信息。使用我们手动注释验证的一组自适应指标,发现了以下结果,这些结果为未来的对话设计提供了方向:2、给出个人意见陈述(例如“我喜欢马男波杰克”)比个人经验陈述(例如“我昨天看了马男波杰克”)和一般性陈述(例如“马男波杰克由 Raphael Bob-Waksberg 和 Lisa Hanawalt 创始”)更有效;4、当我们在 33% 的时间中(相对于 0%、66% 或 100%)利用反馈信息时,用户主动性最高。由于这些实验是在有限的环境中进行的,我们并不期望它们会完美地转移到所有社交机器人上;然而,我们相信,这些简单而有效的策略,是构建更自然的对话式人工智能的一个有希望的方向。
我们的每个项目都是从用户的不满意开始的,他们用自己的方式告诉我们,机器人可以做得更好。
通过对这些投诉进行系统分析,我们更准确地了解了用户对我们神经生成的反应的具体困扰。通过这些反馈,我们训练了一个模型,该模型能够成功预测生成的响应何时可能导致对话误入歧途。有时,是用户会说出冒犯性的话。我们研究了这些案例,并确保包含用户姓名的,带着同理心的重定向,能最有效地保持对话正常进行。最后,我们尝试了单纯的少说话,并为用户创造更多引导对话的机会。结果发现,当有这个机会时,许多人都会抓住它,从而能进行更长、更丰富的对话。在我们所有的工作中,人类对话的直观原则也适用于社交机器人:做一个好的倾听者,以同理心回应,当你得到反馈和学习的机会时,接受它。- 机器学习交流qq群955171419,加入微信群请扫码:








 下载APP
下载APP