
一个提高效率的工具,正则表达式,值得学习一下!
前言
之前分享过几篇工具系列的文章,受到不少读者喜欢
今天再分享一个关于提高工作效率的工具:正则表达式
在工作中一般使用正则表达式来匹配,替换,检索文本,可以大大提高了工作效率
文章首发在公众号(月伴飞鱼),之后同步到掘金和个人网站:xiaoflyfish.cn/
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
简介
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。
学会使用正则表达式可以极大提高我们文本处理效率,并且各大操作系统、编程语言、文本编辑器都已经支持正则表达式
在线正则测试工具:https://regex101.com/r/PnzZ4k/1
下面的例子我会使用Sublime Text(对了,这个工具也非常好用)实现
元字符
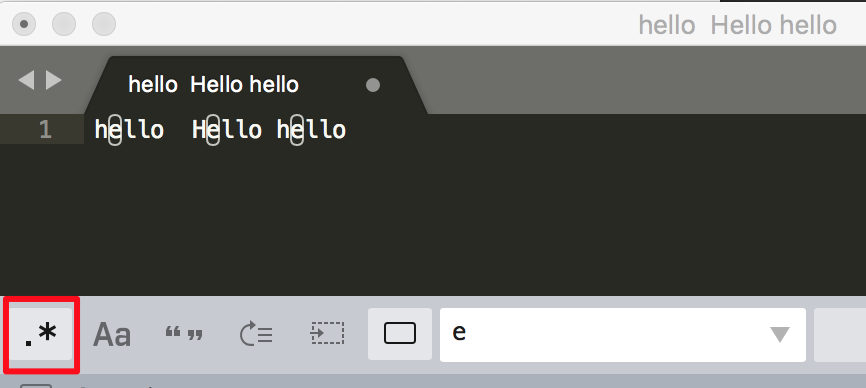
一般普通字符表示的还是原来的意思,比如字符 e
举例:
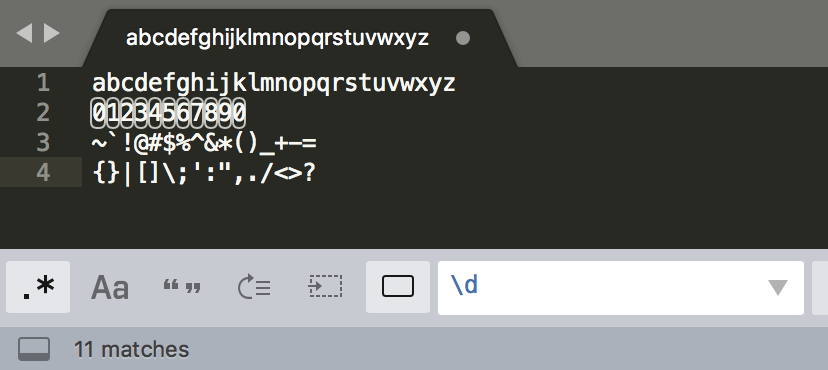
所谓元字符(Metacharacter)就是指那些在正则表达式中具有特殊意义的专用字符
特殊单字符

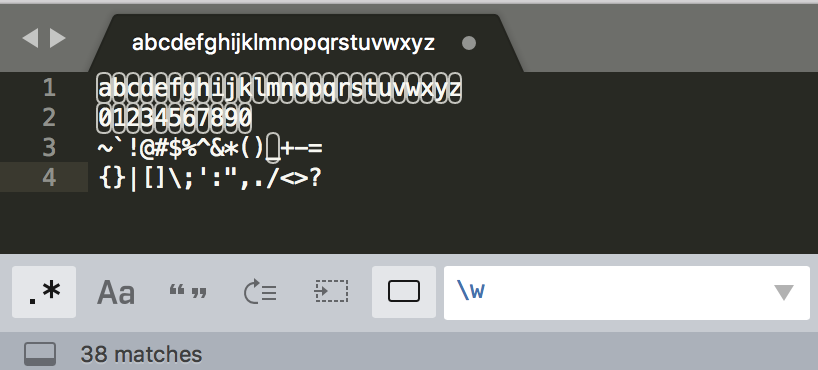
举例1:
举例2:
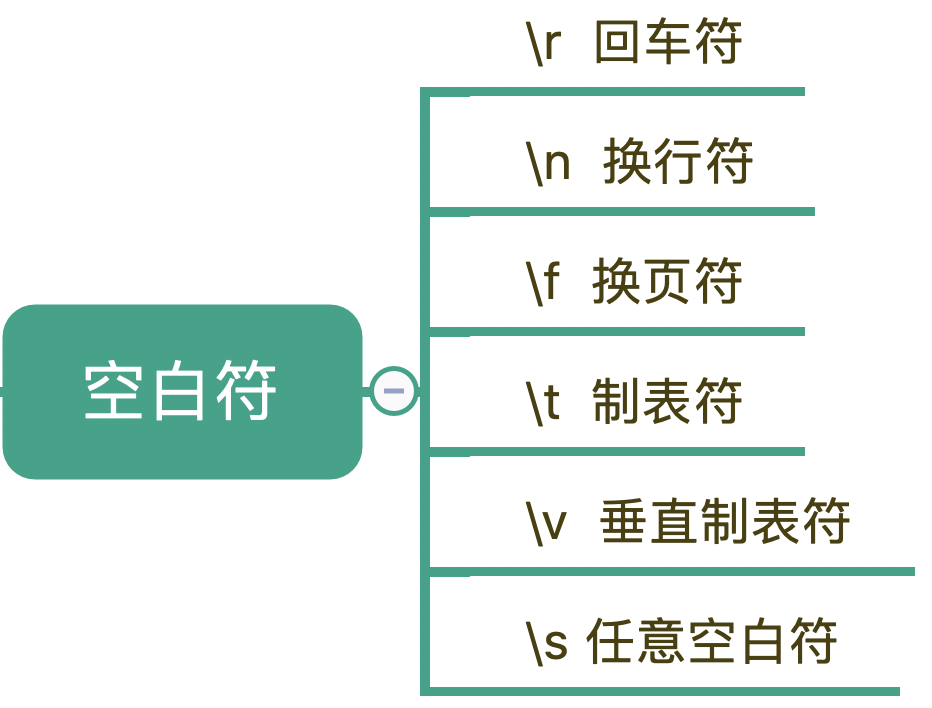
空白符
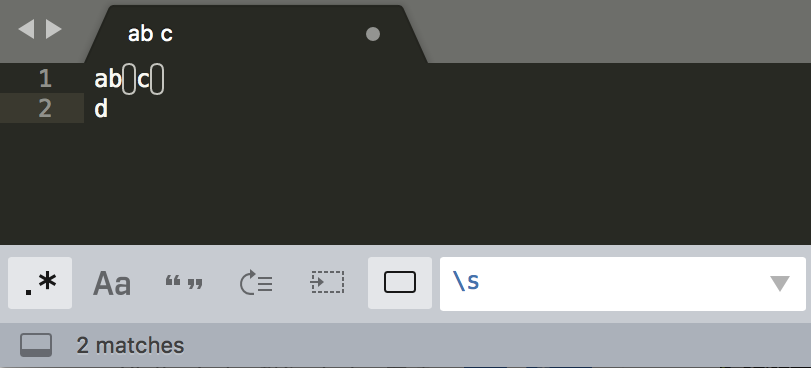
举例:
s 能匹配上各种空白符号,也可以匹配上空格
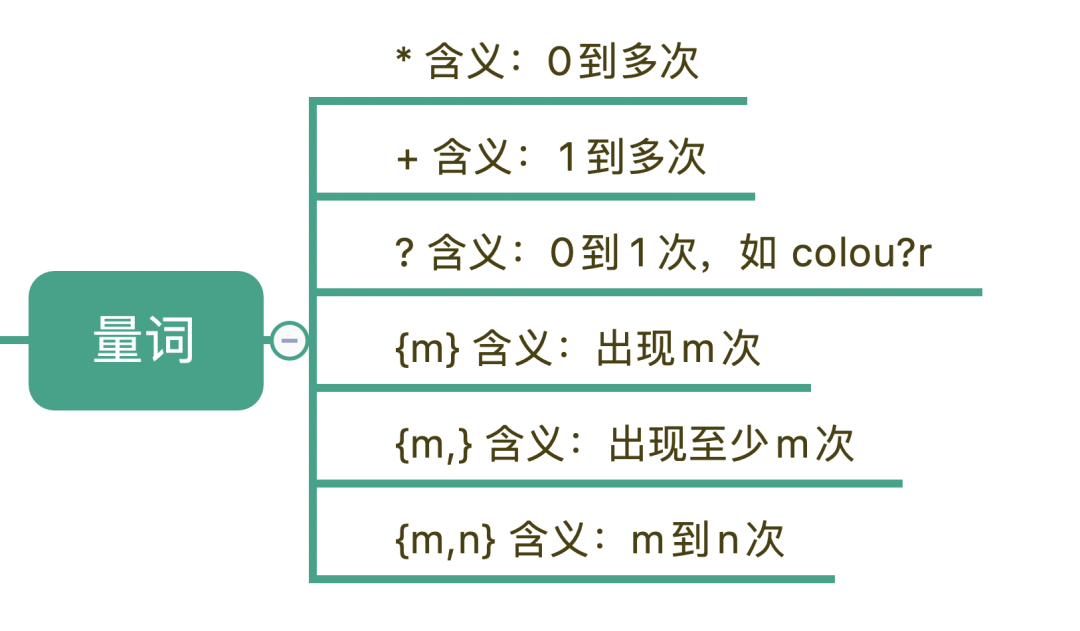
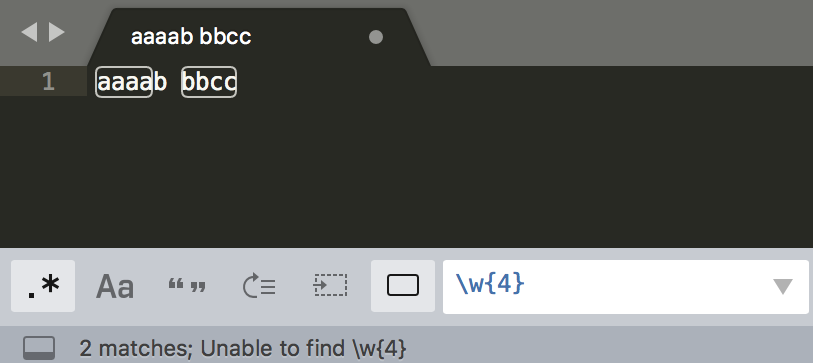
量词
举例1:
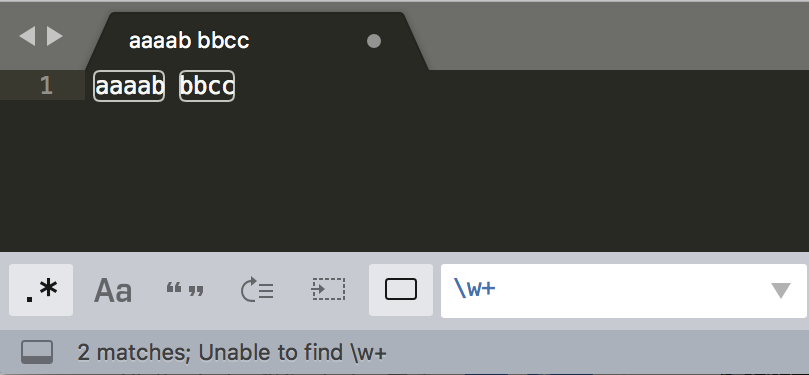
举例2:
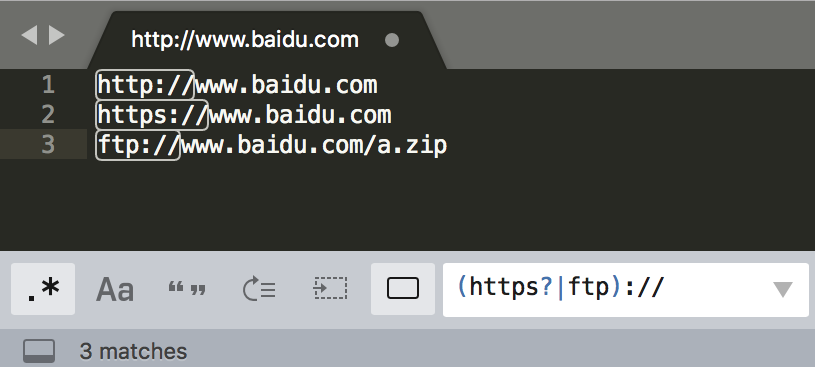
范围

举例:
贪婪、非贪婪与独占
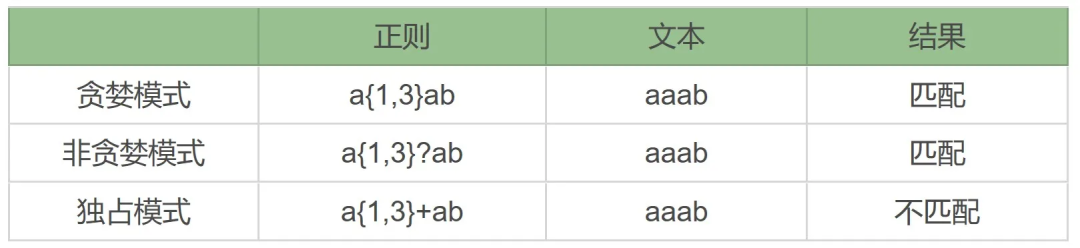
正则有三种模式:贪婪匹配、非贪婪匹配和独占模式
-
贪婪匹配:在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
-
非贪婪匹配:找出长度最小且满足要求的,量词后面要加上英文的问号(
?),正则就变成了a*?。
举个例子1:
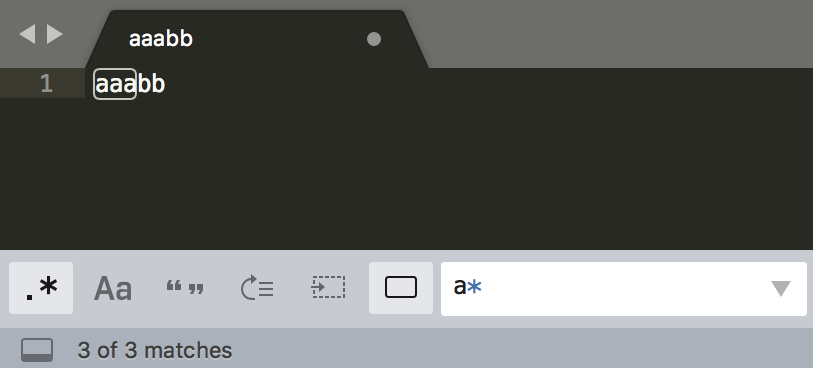
匹配结果是:"aaa",""
为什么会匹配到空字符串?
因为星号(*)代表0到多次。
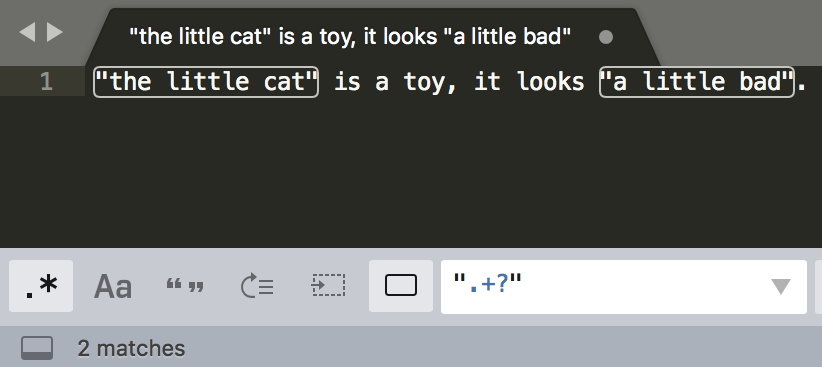
举个例子2:
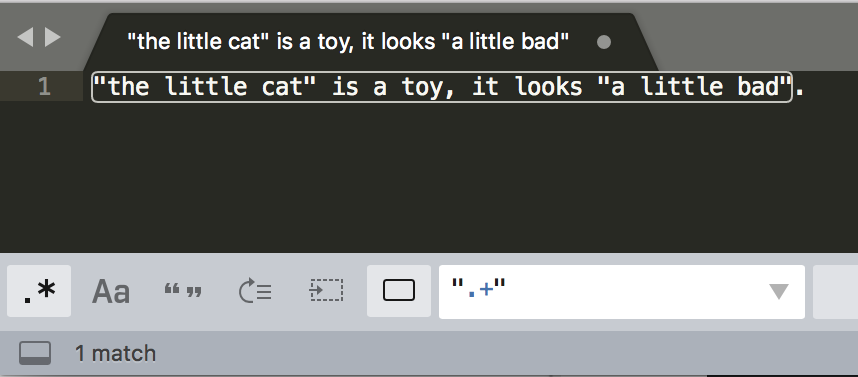
独占模式:
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。
但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
什么是回溯?
例如下面的正则:
regex = “xy{1,3}z”
text = “xyyz”
在匹配时,y{1,3}会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配
分组与引用
举个例子:
假设我们现在要去查找15位或18位数字。
根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,你应该很快就能写出d15}。
但经过测试,你会发现,这个正则并不能很好地完成任务,因为18位数字也会匹配上前15位
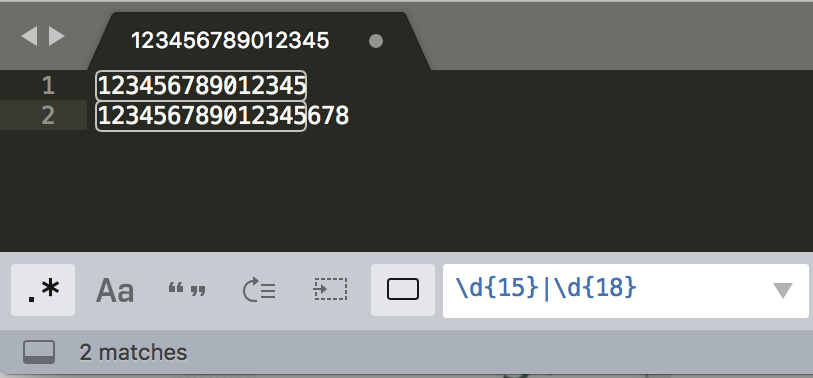
没有匹配到18位的记录
解决方式
可以用括号括起来表示一个整体
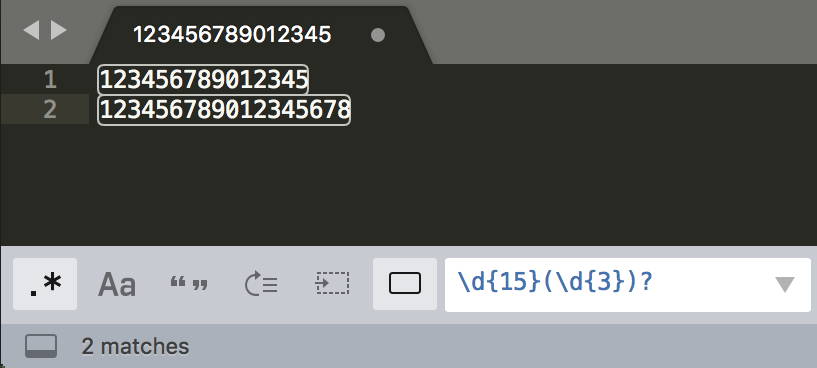
替换举例
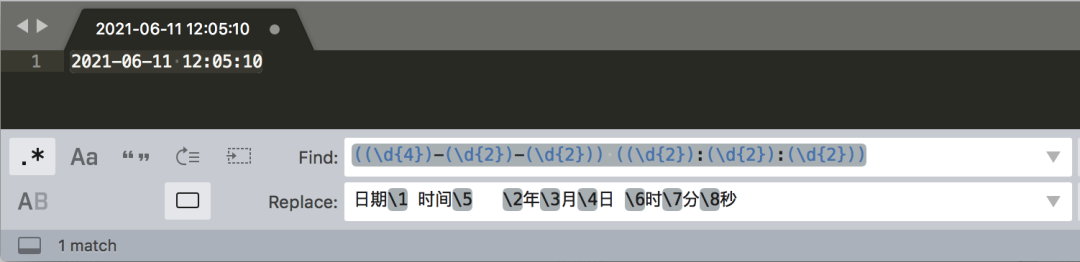
替换后:
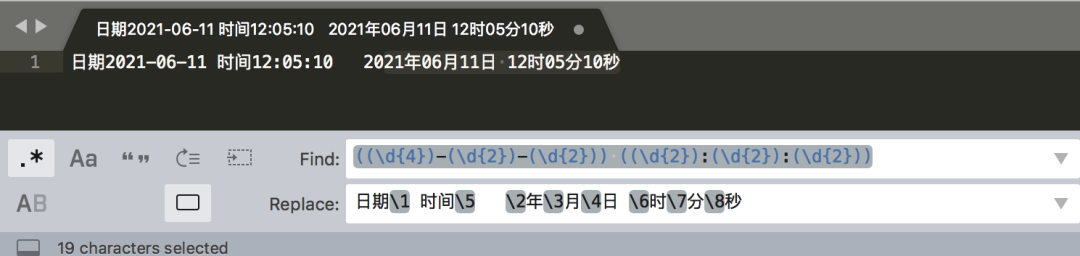
匹配模式
常见的匹配模式有4种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式
不区分大小写模式
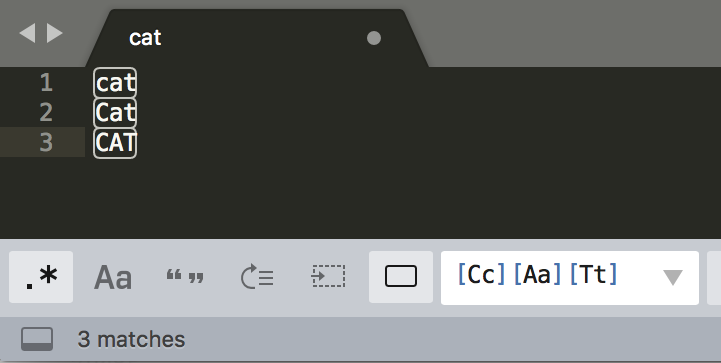
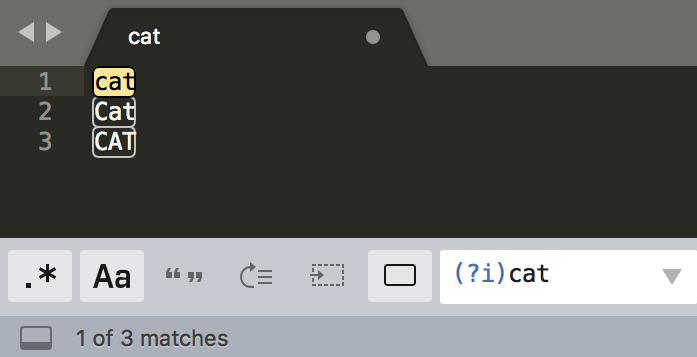
**使用模式修饰符:**放在整个正则前面时,表示匹配模式
点号通配模式
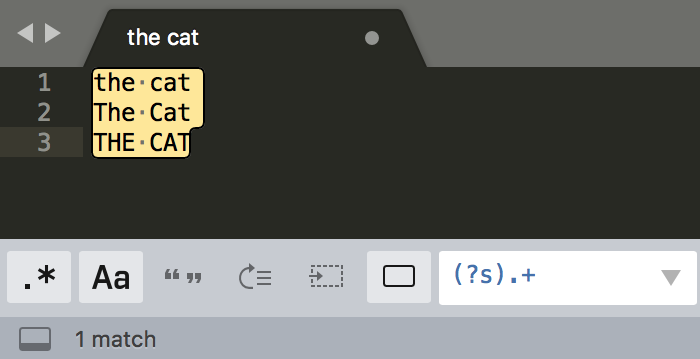
点号它可以匹配上任何符号,但不能匹配换行,如何匹配真正的“任意”符号
多行匹配模式
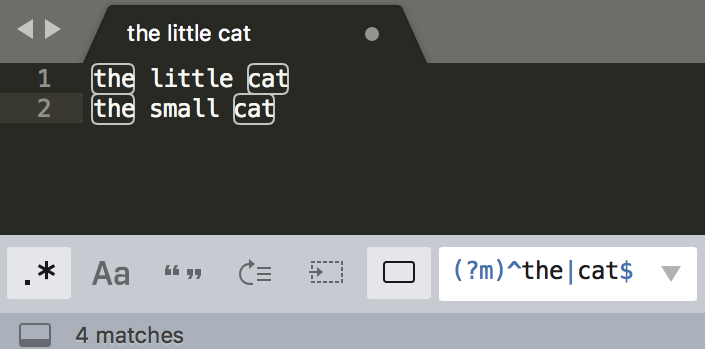
多行模式的作用在于,使 ^ 和 $ 能匹配上每行的开头或结尾,我们可以使用模式修饰符号 (?m) 来指定这个模式
注释模式
为正则添加注释

断言
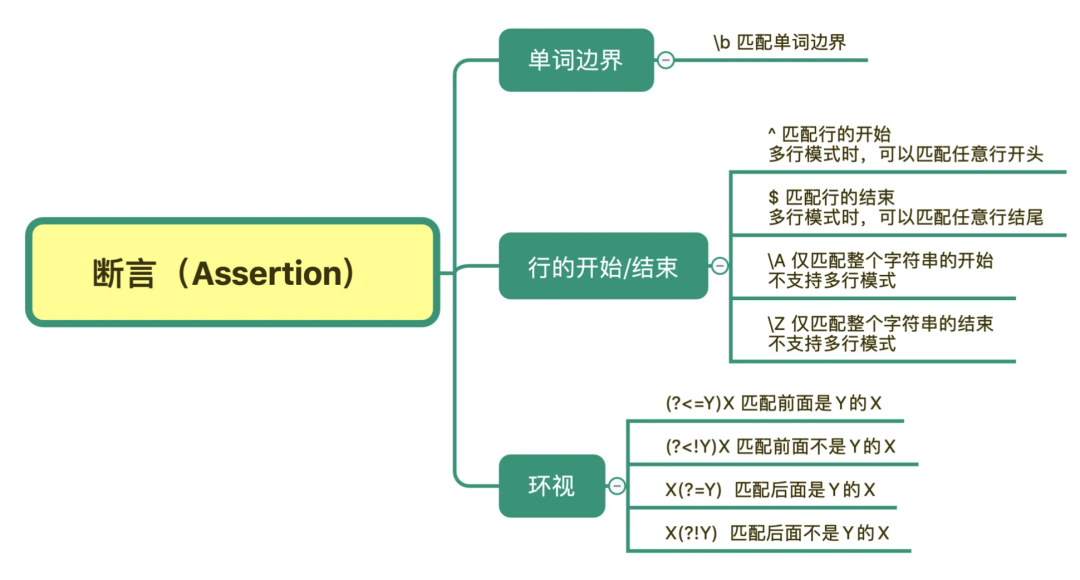
断言是指对匹配到的文本位置有要求。
通过一些例子来讲解。
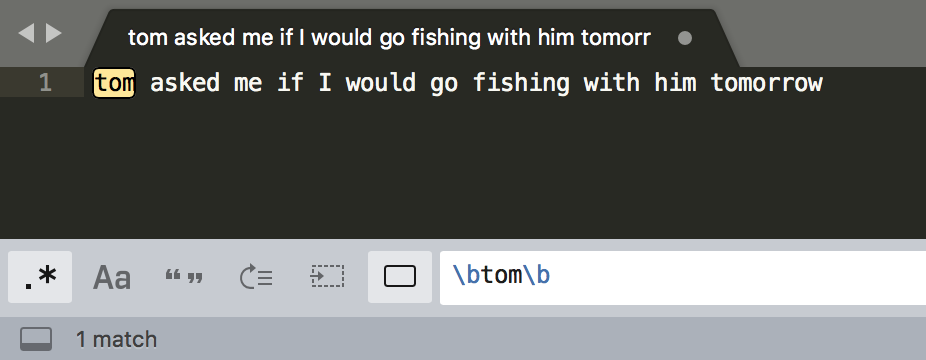
你应该知道 d{11} 能匹配上11位数字,但这11位数字可能是18位身份证号中的一部分。再比如,去查找一个单词,我们要查找 tom,但其它的单词,比如 tomorrow 中也包含了tom
单词边界
环视
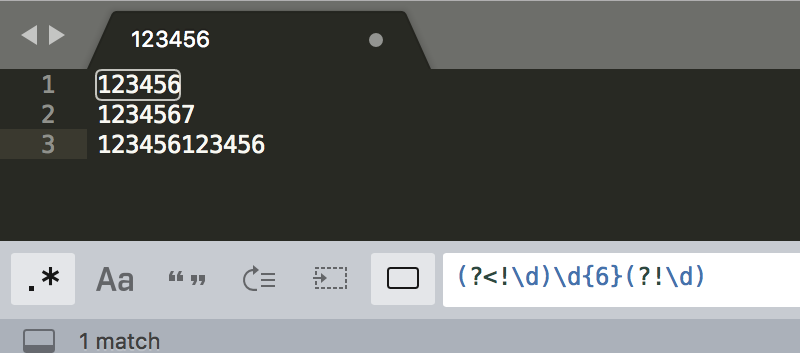
举例邮政编码的判断:6位数字,且左边不是数字,右边不是数字
最后
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
微信搜索:月伴飞鱼,交个朋友,进面试交流群
公众号后台回复666,可以获得免费电子书籍
参考资料:
-
极客时间:正则表达式入门课

面试题:在日常工作中怎么做MySQL优化的?

来自读者的面试题:谈谈Spring用到了哪些设计模式?
