
25行代码≈SOTA!OpenAI发布Triton编程语言,比PyTorch快2倍

新智元报道
新智元报道
来源:OpenAI
编辑:Pricilla 好困
【新智元导读】继Copilot后,高产似xx的OpenAI又出了新的编程语言——Triton,能够自动完成CUDA编程的各种优化。大约25行Python代码就能实现大师级性能,没有经验的小白也能写出高效GPU代码,支持Linux系统和NV显卡,项目已开源。
前段时间OpenAI才搞了个大新闻——AI编程神器Copilot。
这次,它又带来了能自动榨干GPU性能的编程语言——Triton。
速度要比PyTorch快两倍!

Triton到底有多强?
只要25行代码就能实现接近「SOTA」的性能!
内存合并,共享内存管理,SM内调度,Triton通通帮你搞定。
此外,Triton代码开源,兼容Python。
项目负责人Philippe Tillet表示:「我们的目标是让Triton成为深度学习中CUDA的替代品」。
项目地址:https://github.com/openai/triton
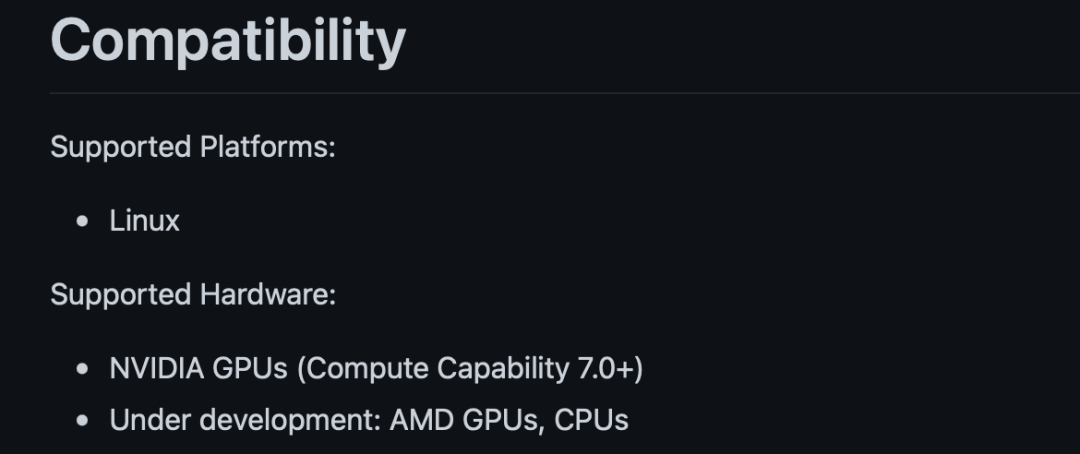
不过,目前Triton 1.0仅支持Linux系统和英伟达的显卡。
AMD的显卡估计再等等也能用上,甚至也会支持CPU。
至于Windows方面……最好的Linux发行版可不是白叫的(狗头)。
网友评论
网友评论
不得不说,深度学习的进展实在是太快了。
有网友就表示:这是啥?pandas的语法用的时候还得谷歌一下,请等等我……
JAX?什么是JAX?对比学习?什么是图像Transformers?GPT-3已经被取代了吗?
作者表示Triton是自己在2019年的论文中提出来的,即使跟英伟达产品「Triton推理服务器」撞名了,也依然会采用「Triton」这个名字。
这是我在读博士时开始的一个项目,而Triton是唯一能将我的博士生导师与该项目联系起来的东西。
Triton,你从哪里来
Triton,你从哪里来
正如上文所说,Triton的历史可以追溯到2019年,作者Tillet在哈佛大学读博时发表的一篇论文。

论文地址:https://dl.acm.org/doi/abs/10.1145/3315508.3329973
深度学习方面新的研究大多都是通过结合原生框架算子完成的。
这种方法方便是方便,但通常需要创建或移动许多临时张量,从而造成神经网络性能上的损失。
本来是可以通过编写专用的GPU内核来解决这个问题,然而……
由于许多错综复杂的问题,直接用CUDA进行编程实在是太难了。
虽然已经有不少系统能够简化这个过程,但对比起cuBLAS、cuDNN 或TensorRT,要么太冗长、不够灵活,要么是生成的代码速度太慢。
Triton则简化了专用内核的开发,速度比通用库中的要快得多。
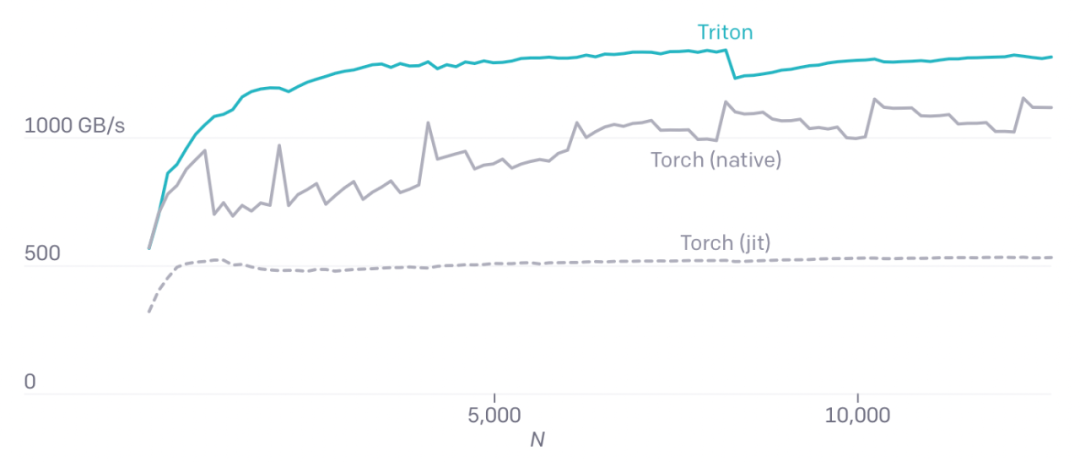
M=4096时,A100处理融合softmax的性能
Triton能够在现有的GPU上高效运行,比PyTorch实现高出2倍。
GPU编程
GPU编程
现有的GPU架构可以大致分为三个主要部分:DRAM、SRAM和ALU。
在优化CUDA代码时必须考虑到每一部分。
来自DRAM的内存传输必须经过合并,从而利用现代内存接口的总线带宽。
数据在被重新使用之前必须被手动存储到SRAM中,从而在检索时减少共享内存库的冲突。
计算必须在流式多处理器(SM)之间和内部仔细分区和调度,从而完成指令或线程级的并行处理,以及对专用ALU的利用。
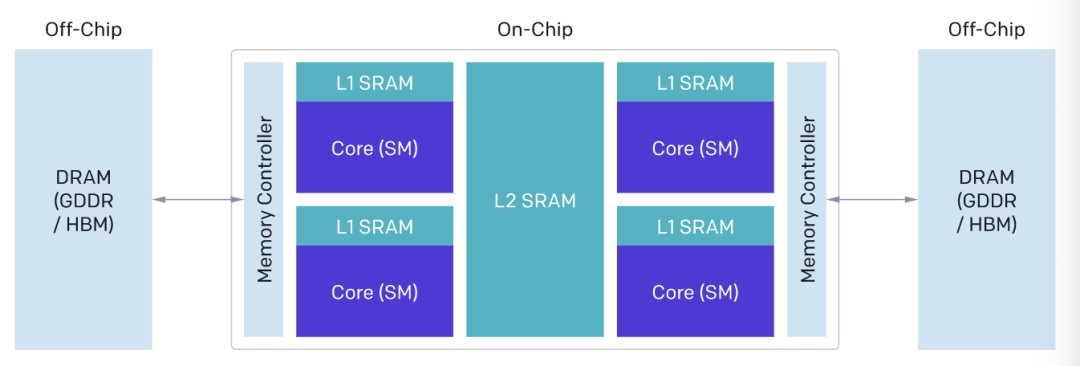
GPU的基本架构
上面这些因素解决起来非常难,就算是经验丰富的CUDA程序员也会「双手挠头」。
不过,Triton就能自动优化这些问题。
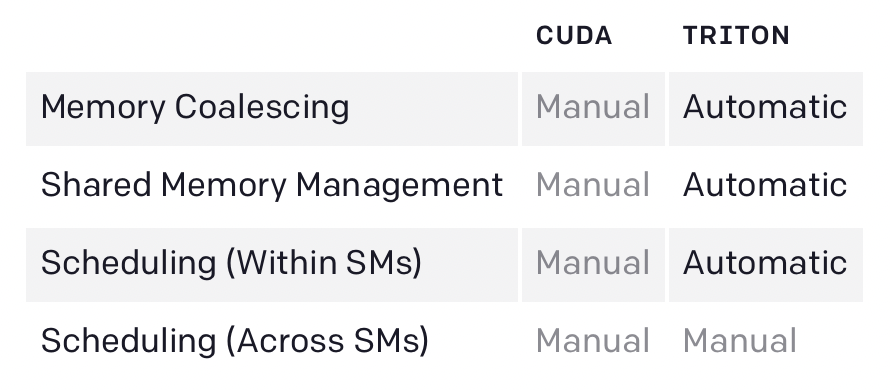
CUDA与Triton的编译器优化
针对如何划分每个程序实例完成的工作这一点,Triton编译器使用了大量块级数据流分析。
这是一种基于目标程序的控制和数据流结构静态调度迭代块的技术。
有了Triton编译器的自动优化、简化功能,开发人员就能把精力放在并行代码的高级逻辑上。
矩阵乘法
矩阵乘法
能够为逐个元素的运算和缩减编写融合内核很重要。
但要是考虑到神经网络中矩阵乘法任务的重要性,这还远远不够。
事实证明,Triton也能很好地解决这个问题:
只需大约25行Python代码,就能够实现最佳性能。
但如果是CUDA,那只会花掉更多的精力,甚至有可能降低性能。
 Triton中的矩阵乘法
Triton中的矩阵乘法
手写矩阵乘法内核的一个优点是能够按需定制,从而适应其输入和输出的融合变换。
对于那些没有GPU编程知识的开发人员来说,Triton能够帮助他们对矩阵乘法内核大刀阔斧地修改。
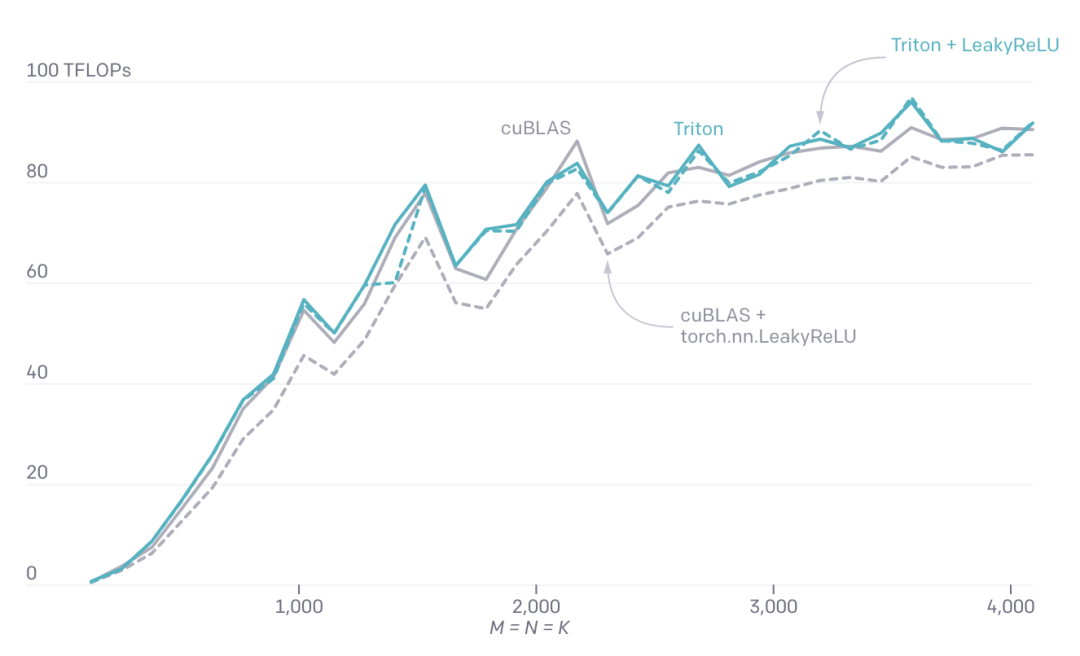
矩阵乘法中V100 Tenser核心的性能
高级系统架构与编译器后端
高级系统架构与编译器后端
能达到如此优秀的性能,是因为Triton有一个以Triton-IR为中心的模块化系统架构。
Python函数的抽象语法树(Abstract Syntax Tree,AST),能够使用常见的SSA构造算法生成Triton-IR。

Triton的架构
生成的IR代码由编译器后端进行简化、优化和自动并行化。
转换为高质量的LLVM-IR(最终转换为 PTX)后,能够在最新的NVIDIA GPU上执行。
编译器后端可以自动优化各种重要的程序。
例如,通过分析计算密集型操作中的块变量的有效范围,数据就能自动存储到共享内存中,还能使用标准活性分析技术进行分配/同步。
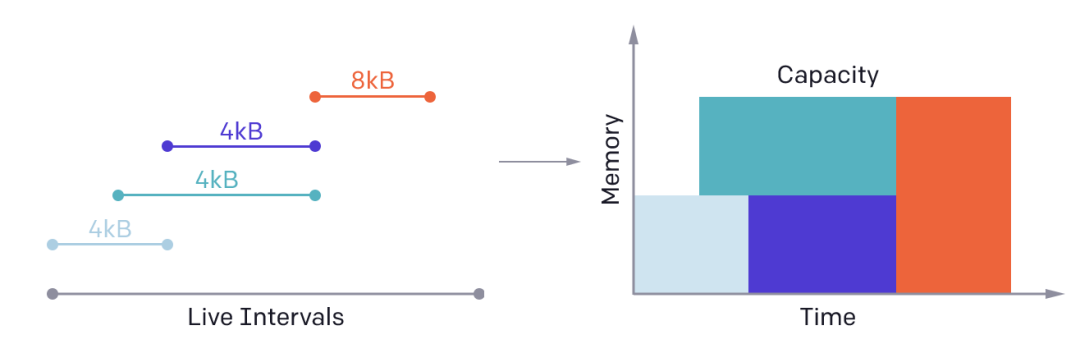
另一方面,Triton的自动并行化非常高效。
通过同时执行不同的内核实例跨SM,以及在SM内分析每个块级操作的迭代空间,并在不同的 SIMD单位中进行分区。
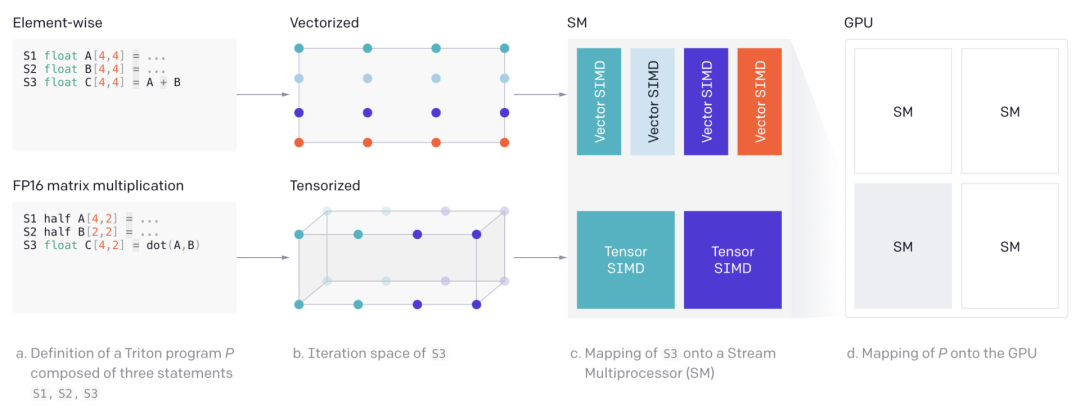
Triton的自动并行化
每个块级操作都定义了一个迭代空间,该空间被自动并行化以利用流式多处理器(SM)上的可用资源。
Triton性能高、速度快,再也不用在GPU编程时「一行代码写一天了」。
虽说目前只支持Linux,不过——
来日方长嘛。
参考资料:
https://www.openai.com/blog/triton/
