
盘点一道Python网络爬虫中使用正则表达式匹配字符的题目
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
大家好,我是Python进阶者。前几天在Python交流群里边有个叫【Arkham】的粉丝问了一个小问题。
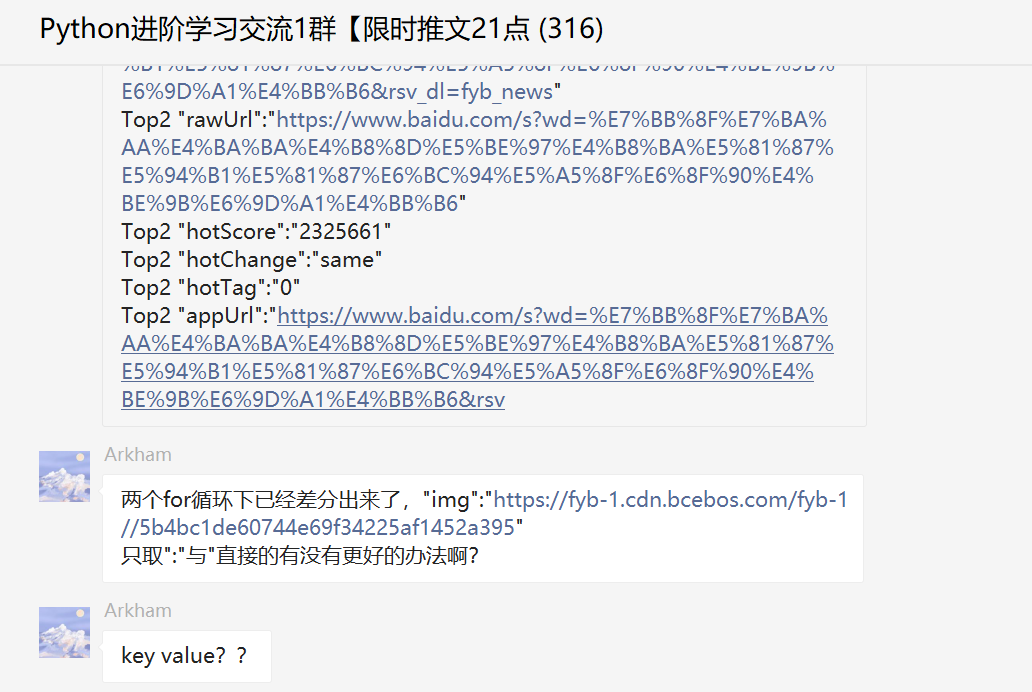
一开始还是觉得挺奇怪的,瞅着这个格式十分像是json格式,直接用json提取不香么,但是后来发现就是这么个格式,而且硬是要提取这个里边的文本信息。
二、思路
一般的,针对文本提取,正则表达式是首选,十分是方便快捷。
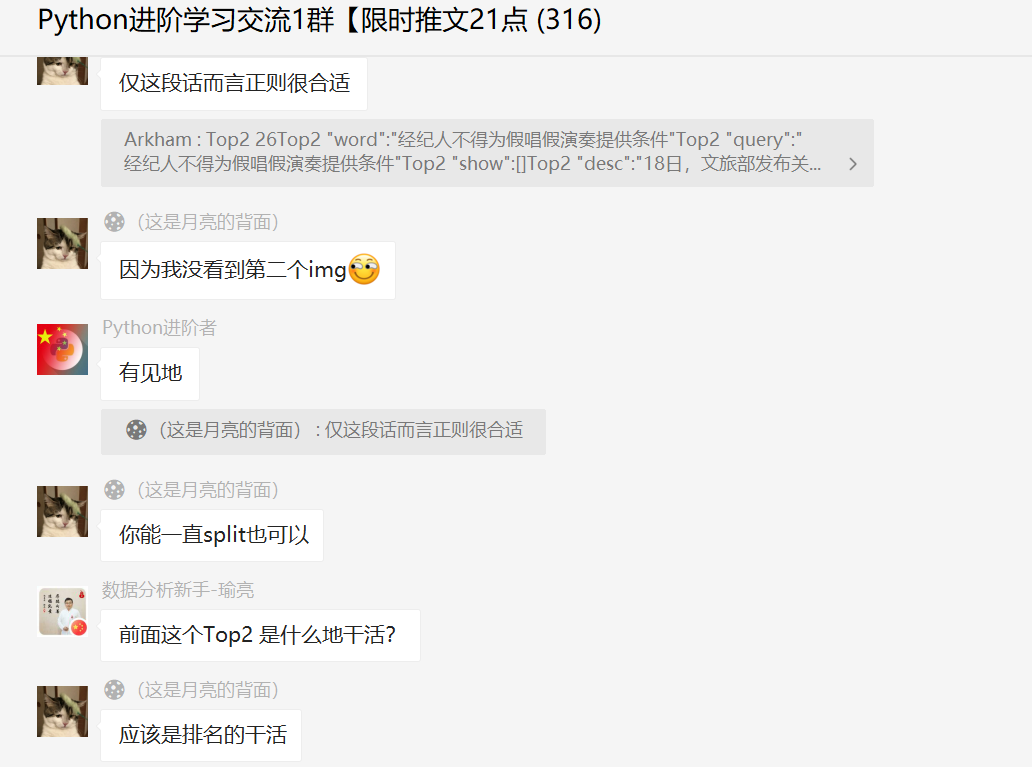
这里给出了两个方法,感谢【🌑(这是月亮的背面)】和【数据分析新手-瑜亮】两位大佬提供的思路。
三、项目实现
这里给大家安排两种方法,一起来看看吧!文本信息就放这里,大家回头拿到也可以尝试练练手。
Top2 26Top2 "word":"经纪人不得为假唱假演奏提供条件"Top2 "query":"经纪人不得为假唱假演奏提供条件"Top2 "show":[]Top2 "desc":"18日,文旅部发布关于《演出经纪人员管理办法(征求意见稿)》公开征求意见的公告。征求意见稿指出,演出经纪人员不得为演员假唱、假演奏提供条件。"Top2 "img":"https://fyb-1.cdn.bcebos.com/fyb-1//5b4bc1de60744e69f34225af1452a395"Top2 "url":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv_dl=fyb_news"Top2 "rawUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6"Top2 "hotScore":"2325661"Top2 "hotChange":"same"Top2 "hotTag":"0"Top2 "appUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA90%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv"
1、正则表达式
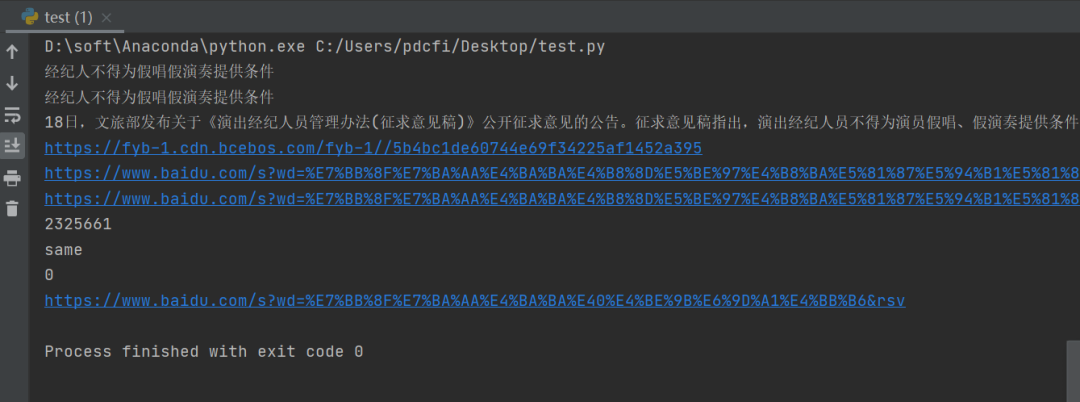
这个方法十分奏效,代码如下。
# -*- coding: utf-8 -*-import retext = """Top2 26Top2 "word":"经纪人不得为假唱假演奏提供条件"Top2 "query":"经纪人不得为假唱假演奏提供条件"Top2 "show":[]Top2 "desc":"18日,文旅部发布关于《演出经纪人员管理办法(征求意见稿)》公开征求意见的公告。征求意见稿指出,演出经纪人员不得为演员假唱、假演奏提供条件。"Top2 "img":"https://fyb-1.cdn.bcebos.com/fyb-1//5b4bc1de60744e69f34225af1452a395"Top2 "url":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv_dl=fyb_news"Top2 "rawUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6"Top2 "hotScore":"2325661"Top2 "hotChange":"same"Top2 "hotTag":"0"Top2 "appUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E40%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv""""regex = re.findall(r'":"(.*?)"', text)for data in regex:print(data)
运行之后,可以得到想要的结果,如下图所示。
2、split()
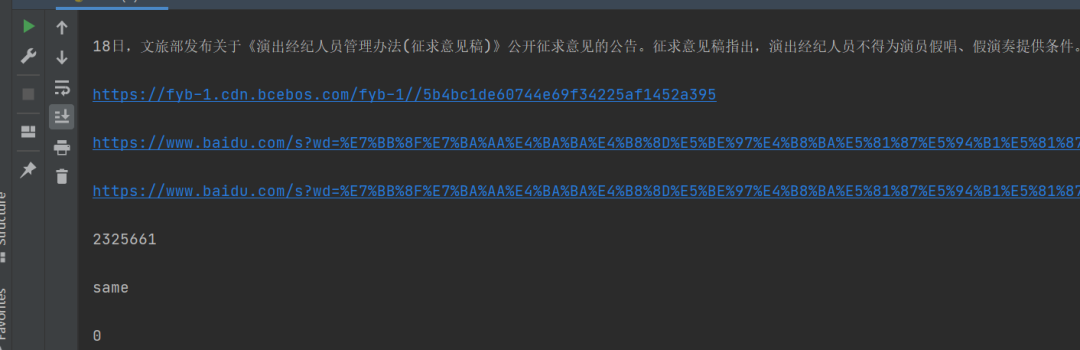
这个方法是来自【🌑(这是月亮的背面)】大佬的思路,后来我自己写了小代码如下。
# -*- coding: utf-8 -*-import retext = """Top2 26Top2 "word":"经纪人不得为假唱假演奏提供条件"Top2 "query":"经纪人不得为假唱假演奏提供条件"Top2 "show":[]Top2 "desc":"18日,文旅部发布关于《演出经纪人员管理办法(征求意见稿)》公开征求意见的公告。征求意见稿指出,演出经纪人员不得为演员假唱、假演奏提供条件。"Top2 "img":"https://fyb-1.cdn.bcebos.com/fyb-1//5b4bc1de60744e69f34225af1452a395"Top2 "url":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv_dl=fyb_news"Top2 "rawUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E4%B8%8D%E5%BE%97%E4%B8%BA%E5%81%87%E5%94%B1%E5%81%87%E6%BC%94%E5%A5%8F%E6%8F%90%E4%BE%9B%E6%9D%A1%E4%BB%B6"Top2 "hotScore":"2325661"Top2 "hotChange":"same"Top2 "hotTag":"0"Top2 "appUrl":"https://www.baidu.com/s?wd=%E7%BB%8F%E7%BA%AA%E4%BA%BA%E40%E4%BE%9B%E6%9D%A1%E4%BB%B6&rsv""""raw_text = text.strip('\n').split('Top2 ')for text in raw_text:print(text.split('":"')[-1].replace('"', ''))
处理起来还是相对费劲的,而且不那么智能,针对文本定制的,比较“死板”,虽然勉强可以实现,可是还是不太建议。
四、总结
本文从实际工作出发,基于Python编程,针对网络爬虫过程中得到的字符串,使用正则表达式和字符串处理函数split(),完成了字符串的处理,满足粉丝的要求。如果你有其他的方法,也欢迎尝试,记得分享给我噢!
最后感谢粉丝【Arkham】的提问,感谢【🌑(这是月亮的背面)】、【数据分析新手-瑜亮】等大佬在代码实现过程中提供的思路、代码、建议和指导,感谢粉丝【冫马讠成】、【多隆ᯤ⁶ᴳ】、【AA】等人的参与探讨学习,让我们共同进步!
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~