
一手好 SQL 是如何炼成的?

阅读本文大概需要 7 分钟。
来自:cnblogs.com/xiaoyangjia/p/11267191.html
MySQL性能
最大数据量

最大并发数
max_used_connections / max_connections * 100% = 3/100 *100% ≈ 3%
show variables like '%max_connections%';show variables like '%max_user_connections%';
[mysqld]max_connections = 100max_used_connections = 20
查询耗时0.5秒
实施原则
充分利用但不滥用索引,须知索引也消耗磁盘和CPU。 不推荐使用数据库函数格式化数据,交给应用程序处理。 不推荐使用外键约束,用应用程序保证数据准确性。 写多读少的场景,不推荐使用唯一索引,用应用程序保证唯一性。 适当冗余字段,尝试创建中间表,用应用程序计算中间结果,用空间换时间。 不允许执行极度耗时的事务,配合应用程序拆分成更小的事务。 预估重要数据表(比如订单表)的负载和数据增长态势,提前优化。
数据表设计
数据类型
如果长度能够满足,整型尽量使用tinyint、smallint、medium_int而非int。 如果字符串长度确定,采用char类型。 如果varchar能够满足,不采用text类型。 精度要求较高的使用decimal类型,也可以使用BIGINT,比如精确两位小数就乘以100后保存。 尽量采用timestamp而非datetime。

避免空值
text类型优化
索引优化
索引分类
普通索引:最基本的索引。 组合索引:多个字段上建立的索引,能够加速复合查询条件的检索。 唯一索引:与普通索引类似,但索引列的值必须唯一,允许有空值。 组合唯一索引:列值的组合必须唯一。 主键索引:特殊的唯一索引,用于唯一标识数据表中的某一条记录,不允许有空值,一般用primary key约束。 全文索引:用于海量文本的查询,MySQL5.6之后的InnoDB和MyISAM均支持全文索引。由于查询精度以及扩展性不佳,更多的企业选择Elasticsearch。
索引优化
分页查询很重要,如果查询数据量超过30%,MYSQL不会使用索引。 单表索引数不超过5个、单个索引字段数不超过5个。 字符串可使用前缀索引,前缀长度控制在5-8个字符。 字段唯一性太低,增加索引没有意义,如:是否删除、性别。
select login_name, nick_name from member where login_name = ?
SQL优化
分批处理
update status=0 FROM `coupon` WHERE expire_date <= #{currentDate} and status=1;
int pageNo = 1;int PAGE_SIZE = 100;while(true) {ListbatchIdList = queryList('select id FROM `coupon` WHERE expire_date <= #{currentDate} and status = 1 limit #{(pageNo-1) * PAGE_SIZE},#{PAGE_SIZE}'); if (CollectionUtils.isEmpty(batchIdList)) {return;}update('update status = 0 FROM `coupon` where status = 1 and id in #{batchIdList}')pageNo ++;}
操作符<>优化
select id from orders where amount != 100;
(select id from orders where amount > 100)union all(select id from orders where amount < 100 and amount > 0)
OR优化
select id,product_name from orders where mobile_no = '13421800407' or user_id = 100;
(select id,product_name from orders where mobile_no = '13421800407')union(select id,product_name from orders where user_id = 100);
IN优化
select id from orders where user_id in (select id from user where level = 'VIP');
select o.id from orders o left join user u on o.user_id = u.id where u.level = 'VIP';
select id from order where date_format(create_time,'%Y-%m-%d') = '2019-07-01';
select id from order where create_time between '2019-07-01 00:00:00' and '2019-07-01 23:59:59';
避免Select all
Like优化
SELECT column FROM table WHERE field like '%keyword%';
SELECT column FROM table WHERE field like 'keyword%';
Join优化
Limit优化
select * from orders order by id desc limit 100000,10
select * from orders order by id desc limit 1000000,10
select * from orders where id > (select id from orders order by id desc limit 1000000, 1) order by id desc limit 0,10
select id from orders where id between 1000000 and 1000010 order by id desc
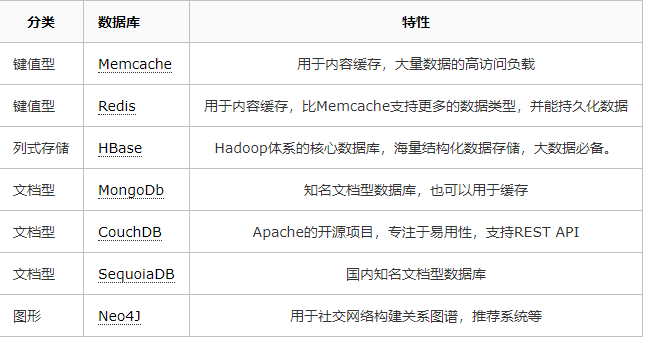
其他数据库
推荐阅读:
一款直击痛点的优秀http框架,让我超高效率完成了和第三方接口的对接
微信扫描二维码,关注我的公众号
朕已阅 
评论