
突破速度极限|Group-Mix SAM参数减少37%,FLOPs减少42%,笔记本也可以白嫖SAM啦
共 5467字,需浏览 11分钟
· 2024-04-11
点击下方卡片,关注「AI视界引擎」公众号
自从大约一年前出现Segment Anything Model(SAM)以来,它引起了学术界极大的兴趣,并从各种角度引发了大量的研究和工作发表。
然而,由于SAM的大型图像编码器体积庞大,达到惊人的632M,其在实际生产线场景中的应用尚未实现。
在本次研究中,作者用轻量级的编码器替换了重型图像编码器,从而使SAM能够在实际生产线场景中部署。具体来说,作者在资源受限的环境下采用解耦蒸馏来训练MobileSAM的编码器。
整个知识蒸馏实验可以在一天内在单块RTX 4090上完成。由此产生的轻量级SAM,即Group-Mix SAM,与MobileSAM相比,参数减少了37.63%(2.16M),浮点运算减少了42.5%(15614.7M)。
然而,在作者构建的工业数据集MALSD上,其mIoU仅比MobileSAM低0.615。最后,作者进行了全面的比较实验,以证明Group-Mix SAM在工业领域的优越性。凭借其卓越的性能,作者的Group-Mix SAM更适合实际生产线应用。
1 Introduction
ChatGPT[1]彻底改变了NLP领域,并在大规模模型上取得了开创性的进展。在计算机视觉领域,SAM的作用无疑是突出的。SAM在零样本实例分割任务上取得了最先进的表现并取得了巨大成功。SAM与其他模型兼容,使得高级视觉应用成为可能,如文本引导的分割和细粒度的图像编辑。尽管有这些优势,但将SAM模型部署在实际装配线上却很困难。原因是使用SAM在实际部署中执行分割任务将导致无法承受的计算和内存成本。SAM可以看作两部分:基于ViT的图像编码器和提示引导的 Mask 解码器。基于ViT的图像编码器的参数规模比提示引导的 Mask 解码器大两个数量级,分别为632M和3.87M[2]。Mask 解码器是轻量级的,因此SAM不能在实际装配线上部署的根本原因是图像编码器的参数规模过大。
在实际的装配线上,是边缘计算机负责运行算法。这些边缘计算机的购买通常受到价格的限制,因此存在内存低和计算能力弱等问题。因此,要在实际的装配线场景中部署和使用,作者需要用轻量级的图像编码器替换重型的图像编码器,以减小SAM的大小。
在本文中,作者解决了MobileSAM因边缘计算机计算能力不足和过度内存使用而无法在装配线上部署的问题。作者 Proposal 用一种较小的图像编码器结构Groupmixformer[3]替换MobileSAM编码器中的原始ViT-T结构,取得了出色的成果。作者将生成的模型命名为Group-Mix SAM。正如Kirillov等人[4]所述,用ViT-H图像编码器训练一个SAM需要68小时的时间,使用256个A100 GPU。直接用小型图像编码器进行训练既耗时又费力,而且结果未必良好。因此,作者转向了知识蒸馏技术。解耦蒸馏(直接从原始SAM的ViT-H提取小型图像编码器而不依赖组合解码器)在时间和效果上都优于半耦合蒸馏(冻结 Mask 解码器并从 Mask 层优化图像编码器)和耦合蒸馏(直接从 Mask 层优化图像编码器)[2]。因此,作者选择了解耦蒸馏作为知识蒸馏的方法。具体来说,它将基于ViT-T的结构中的知识转移到具有较小图像编码器的Groupmixformer中。
2 Related works
Vision Transformers
视觉 Transformer (ViTs)通过使用多头自注意力(MHSA)机制,在视觉应用中展现了惊人的性能,该机制有效地捕捉了全局依赖关系。与CNN相比,ViT模型展示了更高的上限和泛化能力,但也因其参数量高而带来了实际部署问题。因此,许多关于ViT的论文和项目都专注于高效部署,例如LeViT[5],MobileViT[6],Tiny-ViT[7],EfficientViT[8],GroupMixFormer[3]等。设计高效的ViT结构可以构建高效的SAM。
Segment Anything Model
SAM[4]在视觉任务中被广泛使用,因为它能够基于点或框提示对图像中的任何目标进行分割。它的零样本泛化是基于SA-1B数据集学习的,并在各种视觉任务中表现出卓越的性能。此外,SAM也被应用于医学图像分割和透明目标检测等领域。由于其广泛实际应用,SAM在实际生产线上的部署受到了越来越多的关注。近期研究提出了一些降低SAM计算成本的策略,例如EfficientSAM[9],它引入了一个名为SAMI的预训练框架,利用了SAM的 Mask 图像;edge SAM[10],它将基于原始ViT的SAM图像编码器提取到一个纯粹的CNN架构中;以及MobileSAM[2],它通过解耦蒸馏获得了一个轻量级的图像编码器,以替代SAM原始的庞大编码器。作者的关注点在于实现SAM在实际生产线上的部署。
Knowledge Distillation
知识蒸馏(KD)是一种用于转移模型能力的方法。根据转移方法的不同,它可以分为两个主要方向:目标蒸馏(逻辑斯蒂方法蒸馏)和特征蒸馏。在目标蒸馏方面,最经典的论文是[11],其中提出了软目标(soft-target)和温度(temperature)等概念。相比之下,特征蒸馏涉及学生模型学习教师网络结构的中间层特征。最早提出这种方法的是FitNets[12],它强制学生模型的中间层逼近教师对应中间层的特征,实现了特征蒸馏的目标。大多数关于知识蒸馏的研究都集中在分类、语义分割和目标检测[13][14][15][16][17]等任务上。
3 Methodology
在本节中,将介绍本文中使用的一些关键方法。首先,作者将介绍作者最终选择的图像编码器:Groupmixformer及其原理和优势,然后介绍作者使用的蒸馏方法:解耦蒸馏及其实现原理。
Groupmixformer
Groupmixformer[3] 提出了组混合注意力(Group-Mix Attention, GMA)作为传统自注意力机制的一种高级替代方案。与仅建模每个标记之间相关性的流行多 Head 自注意力不同,GMA 可以利用组聚合器同时捕捉标记到标记、标记到组以及组到组之间的相关性。Groupmixformer 在图像分类、目标检测和语义分割等下游任务中取得了优异的性能。
在4.1节中,作者对适合工业生产线场景的编码器进行了彻底的对比实验,Groupmixformer表现最为出色。因此,作者选择它作为知识蒸馏的学生模型。
Distillation
在知识蒸馏中,教师和学生架构作为知识传递的载体。换句话说,教师到学生之间知识传递的质量取决于教师和学生网络结构的设计。基于以往经验,作者选择了解耦蒸馏方法,并以MobileSAM[2]中的编码器vit-t作为教师模型,Groupmixformer作为学生模型。对于蒸馏框架,作者采用了nanosam1,它使用NVIDIA TensorRT来大幅提高蒸馏过程中教师模型的推理速度。此外,它还使用教师和学生通过前向推理得到的特征图来计算最终的损失,这种简单的机制也加快了蒸馏过程。因此,作者的完整蒸馏过程可以低成本地在单个RTX 4090上再现,并且在不到一天的时间内完成。
4 Experiments and Analysis
在本节中,作者将介绍论文的实验过程、结果和分析。首先,作者将介绍选择适合实际工业生产线场景的编码器的实验过程和结果。然后,作者将介绍用于知识蒸馏的 数据集和实验设置,并呈现蒸馏实验的结果。最后,作者将比较Group-Mix SAM和MobileSAM的性能。
Experiments on selecting image encoders
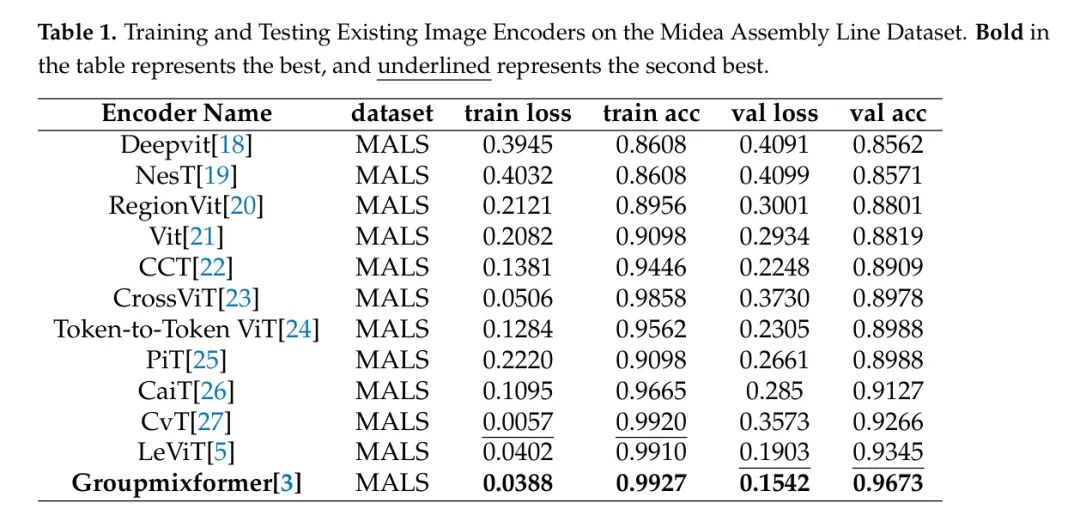
作者需要选择一个适合实际工业生产线场景的编码器。为此,作者通过收集美的实际生产线的视频数据创建了美的生产线场景数据集(MALSD)。如图1所示,MALSD只有两个类别:Act0和NG。Act0指的是工人手持产品说明书的图片,而NG指的是其他杂项图片。训练集中,Act0和NG分别有533和668张图片,测试集中,Act0和NG分别有144和238张图片。如表1所示,作者在MALSD上训练和测试了现有的最先进的图像编码器。作者观察到,groupmixformer[3]在MALSD上的表现最好,它比排名第二的模型LeViT在验证集上的表现高出3.28%。因此,作者得出结论,Groupmixformer[3]更适合作者的工业场景。


Experimental setup for knowledge distillation
作者选择了Nanosam作为蒸馏框架。使用了COCO 2017[28]数据集,其中 未标注 的图像用于训练,标记的图像用于测试。在蒸馏过程中,输入给学生的图像大小为1024,批处理大小为8,学习率为3e-4,所有实验均统一设置了13个周期。所使用的损失函数是Huber损失。为了减少蒸馏所需的时间,作者使用TensorRT加速了教师模型。因此,整个蒸馏过程在不到一天的时间内就在一台RTX 4090上完成了。
Experimental results of knowledge distillation
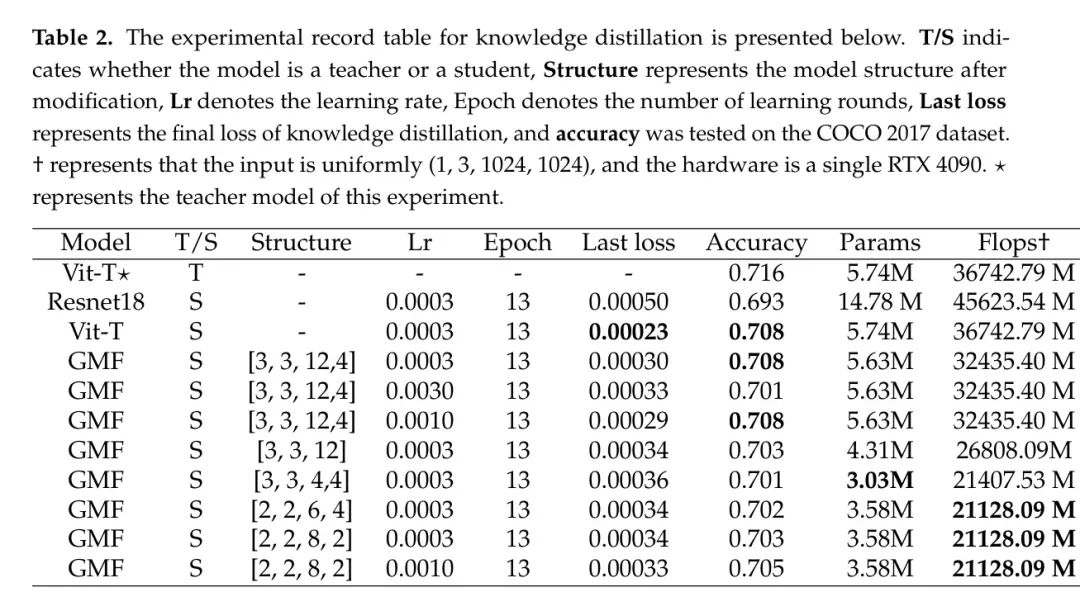
结果显示如 Tab 2 所示。作者选择了 MobileSAM 的编码器 Vit-T 作为教师模型,该模型的参数量为5.74M,浮点运算量为36742.79M。它在 coco 数据集上的性能为72.8%,展示了如下表现。
Performance of Group-Mix SAM
图像编码器GMF,一种适用于工业生产线场景的蒸馏版本,被用于图像分割,从而形成了Group-Mix SAM。作者定性地比较了蒸馏的教师模型、GMF、Vit-T和Resnet18 Backbone 网络,这些网络替换了Mobile SAM中的编码器,使用了COCO公共数据集。在实验中,作者将边界框作为提示。如图3所示,Group-Mix SAM似乎在一些细节上表现更好,比如在第一行和第三行的马尾和背部,而教师模型、Resnet18和Vit-T都存在一些缺陷。

作者随后重复了上述实验,并在作者自己构建的数据集MALSD上进行了定性比较:这次使用工人手部的中心点作为提示。如图4所示,尽管GMF具有最小的参数和浮点运算计数,但其表现仍然出色。例如,在第一行和第四行工人手持说明书的情况下,以及在第二行工人手持条码扫描器的情况下,与另外三种方法相比,GMF能够准确清晰地分割手部。

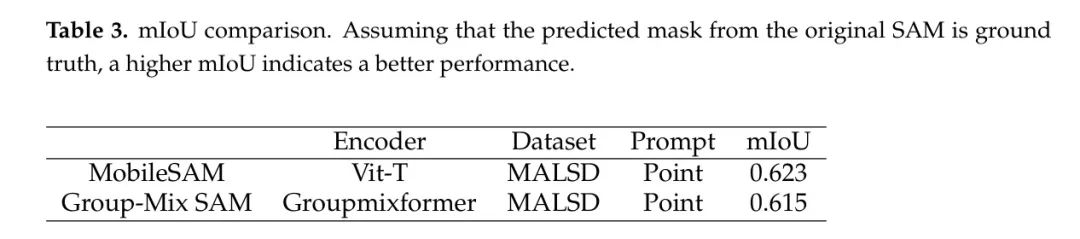
最终,作者使用上述四种方法对MALSD进行了Group-Mix SAM的详细测试,结果展示在表3中。作者可以看到,在MALSD中,mIoU低于在传统数据集上测量的结果(MobileSAM在传统数据集上可以达到超过70%) ,因为工业数据集中存在许多干扰和噪声。尽管Group-Mix SAM所使用的编码器是从MobileSAM精简而来的(参数减少了37.63%(2.16M),浮点运算减少了42.5%(15614.7M)),但在工业数据集上并没有太大的差别。
5 Conclusion
作者从自建的工业数据集MALSD中选取了一个适合实际工业生产线场景的编码器。随后,作者使用解耦蒸馏方法将MobileSAM的编码器蒸馏到Gounpmixformer架构中。通过用轻量级的图像编码器替换重型的编码器,作者使得SAM能够在实际的生产线场景中部署。凭借其卓越的性能,作者的Group-Mix SAM更适合于实际的生产线应用。
Author Contributions
资金支持: 本研究得到了东北大学法学院研究生院启动基金(编号200076421002)、广东省自然科学基金(编号2020A1515011170)以及2020年李嘉诚基金会跨学科研究资助(编号2020LKSFG05D)的支持。
数据可用性声明: 在当前研究中生成和分析的数据集及源代码,可在向相应作者提出合理请求后获得。
参考
[1].Group-Mix SAM: Lightweight Solution for Industrial Assembly Line Applications.
点击上方卡片,关注「AI视界引擎」公众号