
【竞赛总结】安全AI之人脸识别对抗
安全AI挑战赛
比赛名称:安全AI挑战者计划人脸识别对抗
近年来随着科技的蓬勃发展,AI逐步成为各类应用技术的驱动器,推动行业及技术发展。在安全领域,AI也正发挥越来越重要的作用,随着流量识别、人脸识别、动作识别、假货识别等应用场景的出现,AI与安全结合的成果愈加丰硕,但AI面临的安全问题也逐渐浮出水面。
AI安全性有诸多挑战,为了抵御未来AI面临的安全风险,阿里安全联合清华大学,以对抗样本为核心,假想未来作为安全AI防守者的身份,结合内容安全场景,从文字、图像、视频、声音等多个领域针对对抗样本技术资源赏金召集“挑战者”共同打磨AI模型安全,为打造更安全的AI共同努力。
赛题使用从著名的人脸识别评测集LFW(Labeled Faces in the Wild)中抽取了712张不同人脸图像子集,作为比赛的测试集。所有人脸图像都经过MTCNN对齐并缩放到112*112尺寸。
选手使用提供的712张人脸测试图像进行攻击,因评测端是根据dev.csv文件来读取图像,提交结果时必须保证图像尺寸(112*112)、原始命名方式(jpg格式)以及存放路径不变。



本次天池的人脸识别对抗竞赛的题目是,给定712张LFW中的人脸图片,要求生成对应的对抗样本,使得人脸识别算法给出错误的结果。评测标准是对抗样本对于原始样本的像素扰动值。由于本次比赛并没有提供人脸识别的API调用接口,黑盒攻击方法并不适用。因此,我们将问题转化为白盒攻击。通过对现有攻击方法的优化结合一些新的调优思路,我们的方法在此次比赛中获得第一名(score=1.20)。
具体的攻击框架图如图所示。首先,我们挑选了若干种常用的比对模型结构(包括inceptionV3,resnet family和VGG等)和其对应的预训练模型,并将他们的ensemble作为目标模型。其次,我们采用IPGD攻击和GAN-based攻击融合的方法(sample-wise ensemble),产出攻击样本。相比单一类型的方法,融合攻击能在相同扰动下,获得比单一方法更高的攻击成功功率。最后,我们提出了一种自动参数寻优(hyper-parameter search)和结果融合(dataset-wise ensemble)的方法,从而针对部分样本进一步降低像素扰动,提升比赛成绩。
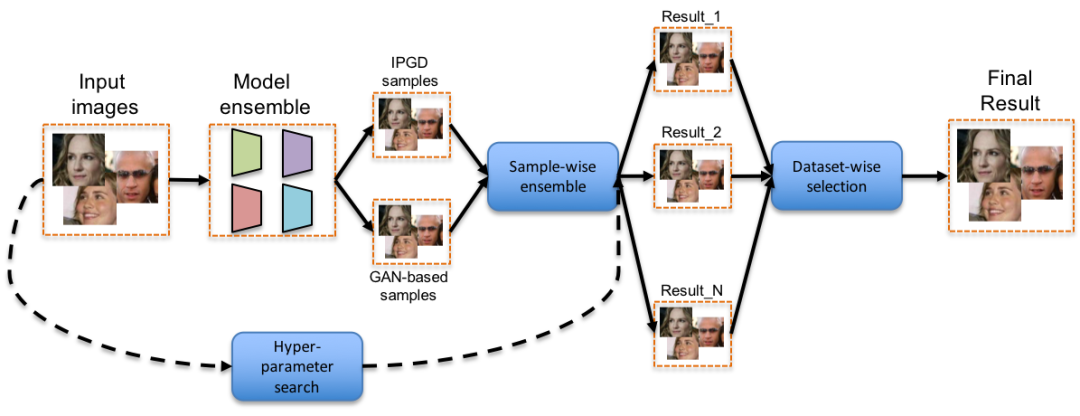
我们使用的攻击方法可以被分为三步。第一步,对于一张输入样本,我们分别利用IPGD和GAN-based进行攻击,得到若干对抗样本备选。对抗攻击过程中,经常会使用范数进行约束减小扰动量,在这里我们受[5]的启示使用l1 ball进行约束和投影达到了最好的效果。同时针对最小扰动,我们对梯度值进行了排序,只选择top10%的像素点进行扰动。在损失函数选择上,考虑到GAN-base等训练方式引入不确定性,我们选用Cosine Embedding Loss作为损失函数,通过margin的调整有效的控制干扰量。
最后,我们通过对不同样本的对抗噪声做若干种ensemble(加权相加、相乘或者直接选择最优)得到扰动最小且攻击效果最好的图作为这张输入的对抗样本。在对整个数据集完成第一步后,就可以得到一个对抗样本数据集。
第二步,我们通过grid-search来进行hyper-parameter的遍历。对于每一次遍历,我们都可以得到一个对抗样本数据集。因此,第二步就会得到N个对抗样本数据集,即图中的Result_1 - Result_N。
最后一步,我们通过Dataset-wise Selection,在N个对抗样本数据集中挑选最优的样本集合。具体来说,就是对每个输入样本,选取扰动最小且攻击效果最好的对抗样本。最后,这些最优的样本组成了最终的结果。
在实验的过程中,我们还尝试了用1:N(targeted)top1检索与1:1(non-targeted)两种对应的攻击思路。实验结果表明,1:1的方法更具有泛化性及迁移性,因此我们选择了1:1。但同时1:N的攻击在现实的人脸识别系统里显得风险更为高。另外,在对对抗样本的观察,我们同时发现了有趣的现象,主要的干扰区域都集中在鼻子和眼睛。这个结论也符合我们对人脸识别模型的认知,主要的区分区域为鼻子和双眼。
第1名分享原文:
https://tianchi.aliyun.com/forum/postDetail?postId=79472
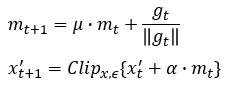
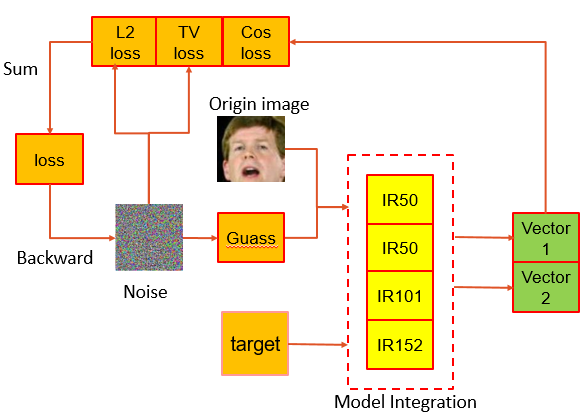
由于人脸识别是比对不同人脸特征的相似度,所以我们直接增大对抗样本与原图的距离,这里我们选用余弦距离(即降低余弦相似度),则 为了最小化对原图的扰动,加入对扰动图的约束
为了最小化对原图的扰动,加入对扰动图的约束 最终loss为
最终loss为

距离度量
我们需要尝试不同的损失函数(余弦距离、L2距离等)来验证最终的效果,在这里我们采用了MSE作为损失函数,因为MSE比余弦距离约束更强一些。
模型选择
我们尝试了很多模型集成的方案,其中有人脸识别模型IR-152,ResNet50, ResNet101,IR-50,最终我们采用了开源的IR-50作为替代模型。
算法设计
我们采用多步迭代的FGSM算法,用L2范数对梯度进行归一化。这里有一个细节,我们对三个通道分别进行L2范数的归一话,效果比,所有像素点进行归一化要来的好。
除此之外,我们的模型还是用了多进程多显卡加速,在实际测试中是用两块1080Ti多进程计算,生成712张对抗样本所花费的时间不到1小时。
干扰噪声区域限制
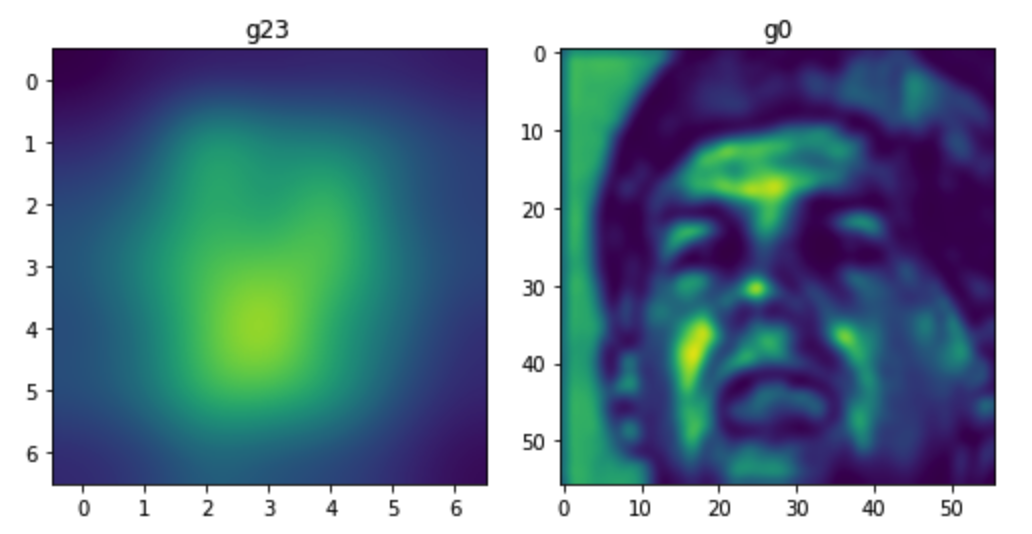
因此我们添加的噪声时只针对人脸的五官。具体的实现过程,我们使用dlib标定人脸的68个landmark,选取了17个点连接组成一个非mask区域,对于很少的无法用dlib标定landmark的图片,我们手动框出人脸范围。

TV loss
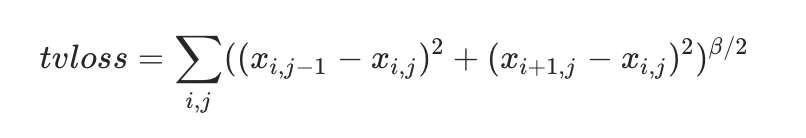
高斯滤波
高斯滤波在图像处理概念下,将图像频域处理和时域处理相联系,作为低通滤波器使用,可以将低频能量(比如噪声)滤去,起到图像平滑作用。
对生成的干扰噪声进行高斯滤波,使得生成的每个像素的噪声与周围像素具有相关性,降低了不同模型生成的干扰噪声之间的差异,(因为不同模型有相似的分类边界),有效提升对抗样本攻击成功率。同时考虑到线上测试可能会有高斯滤波这种防御机制因而在算法生成噪声的时候加入高斯滤波一定程度上也能使防御机制失效从而提高样本攻击率。使用高斯核函数进行卷积就能完成上述操作,高斯核如下:
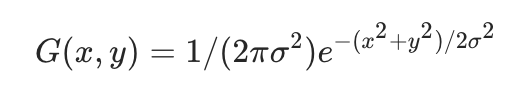
动量项
通过将动量项集成到攻击的迭代过程中,加入动量项之后可以稳定更新方向并在迭代期间从较差的局部最大值中离开,从而产生更多迁移性更强的的对抗样本。为了进一步提高黑盒攻击的成功率,我们将动量迭代算法应用于集成,实验表明加入动量项之后黑盒攻击的效果更好。计算的公式如下:

第4名分享链接:
本次竞赛形式在对抗机器学习领域属于黑盒非定向攻击。根据相关领域知识,我们知道黑盒攻击成功的关键就在于替代模型以及相关损失函数的选择,这也是我们首先需要做的。我们就需要通过不断的尝试选择与目标模型(victim model)相近的模型结构和损失。找到合适的模型和损失后就是要设计合适的攻击算法,我们认为此次竞赛的目的就是找2-范数意义下的鲁棒下界,即攻击者需要找到2-范数度量下的最小对抗扰动。
在模型和损失搜索阶段,我们首先采用Project Gradient Desent (PGD)作为基础攻击算法,然后通过尝试不同的模型结构以及损失来估计目标模型的结构和损失.选择PGD的原因是PGD作为一种迭代攻击方法,结合了基于梯度攻击算法的简单以及优化攻击方法效果好的特点. 在此过程中我们尝试了基于传统分类的结构(卷积,池化加全连接)以及backbone+head的结构。传统分类器结构一般采用cross-entropy等统计相关损失,backbone+head(backbone就是深度模型分类器来提取人脸特征,head结构完成识别任务主要采用余弦相似度,arcface等损失)。
最终在固定攻击算法为PGD的情况下我们选择攻击效果最好的模型作为我们的攻击模型。 所以我们最终选择的本地模型为backbone+head结构backbone结构为IFR-50。损失为余弦相似度。
首先根据我们的知识我们知道基于优化的攻击算法最有可能实现最小范数攻击,所以我们就把攻击算法设计为一种基于优化的攻击方法,可以形式化描述为:
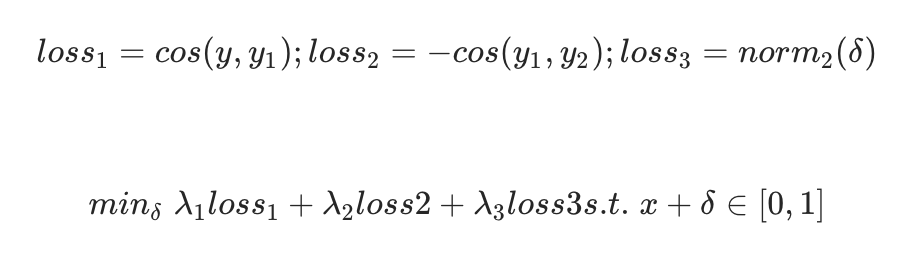
第5名分享原文:
https://tianchi.aliyun.com/forum/postDetail?postId=79275
https://tianchi.aliyun.com/forum/postDetail?postId=79439
https://tianchi.aliyun.com/forum/postDetail?postId=79473
http://tianchi.aliyun.com/forum/postDetail?postId=76834
https://tianchi.aliyun.com/forum/postDetail?postId=79273
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):