
React知识点梳理
本文适合对React知识点存在疑惑的小伙伴阅读
欢迎关注前端早茶,与广东靓仔携手共同进阶~
一、前言

二、正文
react 生命周期函数有哪些
React生命周期有哪些坑,如何避免
1. getDerivedStateFromProps 容易编写反模式代码,使受控组件与非受控组件区分模糊。
2. componentWillMount 在 React 中已被标记弃用,不推荐使用,主要原因是新的异步渲染架构会导致它被多次调用。所以网络请求及事件绑定代码应移至 componentDidMount 中。
3. componentWillReceiveProps 同样被标记弃用,被 getDerivedStateFromProps 所取代,主要原因是性能问题(componentWillReceiveProps 更新状态是同步进行的,而 getDerivedStateFromProps 的设计更适用于异步场景。)。
4. shouldComponentUpdate 通过返回 true 或者 false 来确定是否需要触发新的渲染。主要用于性能优化。
5. componentWillUpdate 同样是由于新的异步渲染机制,而被标记废弃,不推荐使用,原先的逻辑可结合
getSnapshotBeforeUpdate 与 componentDidUpdate 改造使用。
6. 如果在 componentWillUnmount 函数中忘记解除事件绑定,取消定时器等清理操作,容易引发 bug。
7. 如果没有添加错误边界处理,当渲染发生异常时,用户将会看到一个无法操作的白屏,所以一定要添加。
React 的请求应该放在哪里,why?
对于异步请求,应该放在 componentDidMount 中去操作。从时间顺序来看,除了 componentDidMount 还可以有以下选择:
componentWillMount:已被标记废弃,在新的异步渲染架构下会触发多次渲染,容易引发 Bug,不利于未来 React 升级后的代码维护。
所以React 的请求放在 componentDidMount 里是最好的选择。
hooks使用中有什么要注意的?
// initialState
const [visible, setVisible] = useState(false)
// modify the state
// bad
setVisible(!visible)
// good
setVisible(visible => !visible)
类组件与函数组件有什么区别?
共同点:
不同点:
基础认识
函数组件的根基是 FP,也就是函数式编程。它属于“结构化编程”的一种,与数学函数思想类似。也就是假定输入与输出存在某种特定的映射关系,那么输入一定的情况下,输出必然是确定的。
独特性
使用场景
但在 recompose 或 Hooks 的加持下,这样的边界就模糊化了,类组件与函数组件的能力边界是完全相同的,都可以使用类似生命周期等能力。
设计模式
性能优化
而函数组件一般靠 React.memo 来优化。
hooks中为什么不能使用if else 逻辑判断?
平时如何设计 React 组件?
组件分为:展示组件与灵巧组件
setState 是同步更新还是异步更新?
那么什么情况下 isBatchingUpdates 会为 true 呢?在 React 可以控制的地方,就为 true,比如在 React 生命周期事件和合成事件中,都会走合并操作,延迟更新的策略。
启用并发更新,完成异步渲染。
setState 是同步还是异步的核心关键点:更新队列。
如何面向组件跨层级通信?
在子与父的情况下,有两种方式,分别是回调函数与实例函数。回调函数,比如输入框向父级组件返回输入内容,按钮向父级组件传递点击事件等。实例函数的情况有些特别,主要是在父组件中通过 React 的 ref API 获取子组件的实例,然后是通过实例调用子组件的实例函数。这种方式在过去常见于 Modal 框的显示与隐藏。这样的代码风格有着明显的 jQuery 时代特征,在现在的 React 社区中已经很少见了,因为流行的做法是希望组件的所有能力都可以通过 Props 控制。
Virtual DOM 的原理是什么?
虚拟 DOM 的工作原理是通过 JS 对象模拟 DOM 的节点。在 Facebook 构建 React 初期时,考虑到要提升代码抽象能力、避免人为的 DOM 操作、降低代码整体风险等因素,所以引入了虚拟 DOM。
虚拟 DOM 在实现上通常是 Plain Object,以 React 为例,在 render 函数中写的 JSX 会在 Babel 插件的作用下,编译为 React.createElement 执行 JSX 中的属性参数。
React.createElement 执行后会返回一个 Plain Object,它会描述自己的 tag 类型、props 属性以及 children 情况等。这些 Plain Object 通过树形结构组成一棵虚拟 DOM 树。当状态发生变更时,将变更前后的虚拟 DOM 树进行差异比较,这个过程称为 diff,生成的结果称为 patch。计算之后,会渲染 Patch 完成对真实 DOM 的操作。
虚拟 DOM 的优点主要有三点:改善大规模 DOM 操作的性能、规避 XSS 风险、能以较低的成本实现跨平台开发。
虚拟 DOM 的缺点在社区中主要有两点。
内存占用较高,因为需要模拟整个网页的真实 DOM。
高性能应用场景存在难以优化的情况,类似像 Google Earth 一类的高性能前端应用在技术选型上往往不会选择 React。
React 的 diff 算法有什么不同?
diff 算法是指生成更新补丁的方式,主要应用于虚拟 DOM 树变化后,更新真实 DOM。所以 diff 算法一定存在这样一个过程:触发更新 → 生成补丁 → 应用补丁。
React 的 diff 算法,触发更新的时机主要在 state 变化与 hooks 调用之后。此时触发虚拟 DOM 树变更遍历,采用了深度优先遍历算法。但传统的遍历方式,效率较低。为了优化效率,使用了分治的方式。将单一节点比对转化为了 3 种类型节点的比对,分别是树、组件及元素,以此提升效率。
树比对:由于网页视图中较少有跨层级节点移动,两株虚拟 DOM 树只对同一层次的节点进行比较。
组件比对:如果组件是同一类型,则进行树比对,如果不是,则直接放入到补丁中。
元素比对:主要发生在同层级中,通过标记节点操作生成补丁,节点操作对应真实的 DOM 剪裁操作。
以上是经典的 React diff 算法内容。自 React 16 起,引入了 Fiber 架构。为了使整个更新过程可随时暂停恢复,节点与树分别采用了 FiberNode 与 FiberTree 进行重构。fiberNode 使用了双链表的结构,可以直接找到兄弟节点与子节点。
整个更新过程由 current 与 workInProgress 两株树双缓冲完成。workInProgress 更新完成后,再通过修改 current 相关指针指向新节点。
然后拿 Vue 和 Preact 与 React 的 diff 算法进行对比。
Preact 的 Diff 算法相较于 React,整体设计思路相似,但最底层的元素采用了真实 DOM 对比操作,也没有采用 Fiber 设计。Vue 的 Diff 算法整体也与 React 相似,同样未实现 Fiber 设计。
然后进行横向比较,React 拥有完整的 Diff 算法策略,且拥有随时中断更新的时间切片能力,在大批量节点更新的极端情况下,拥有更友好的交互体验。
Preact 可以在一些对性能要求不高,仅需要渲染框架的简单场景下应用。
Vue 的整体 diff 策略与 React 对齐,虽然缺乏时间切片能力,但这并不意味着 Vue 的性能更差,因为在 Vue 3 初期引入过,后期因为收益不高移除掉了。除了高帧率动画,在 Vue 中其他的场景几乎都可以使用防抖和节流去提高响应性能。
react更新的流程是怎样的?
React在props或state发生改变时,会调用render()方法,创建一棵不同的树。
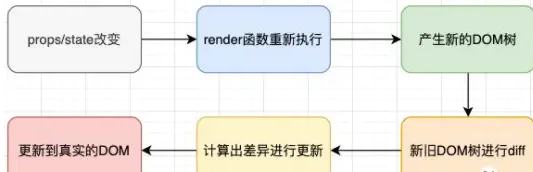
同层节点之间相互比较,不会垮节点比较 不同类型的节点,产生不同的树结构 通过key来指定哪些节点在不同的渲染下保持稳定
Diffing算法(调和算法):
详细描述下React 的渲染流程
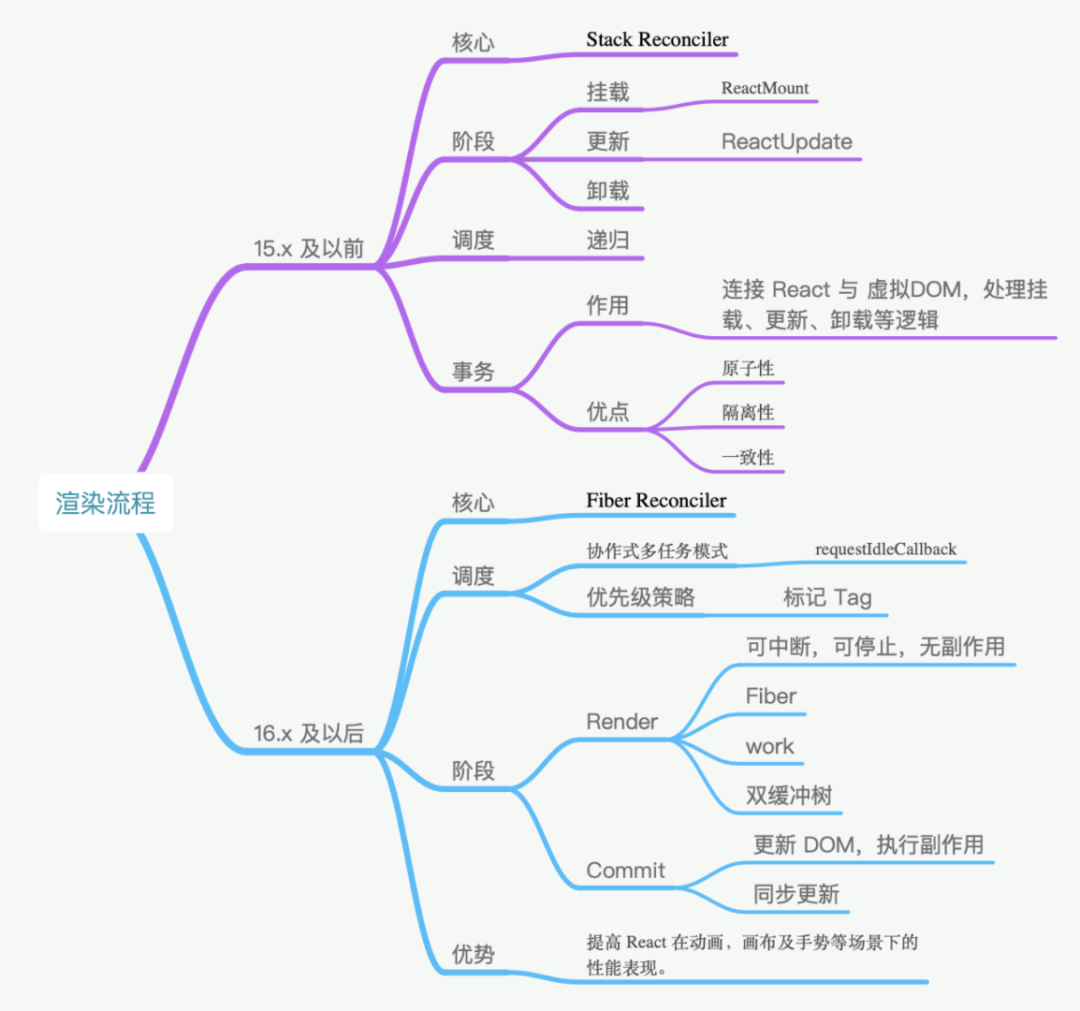
图片来源网络
React 的渲染过程大致一致,但协调并不相同,以 React 16 为分界线,分为 Stack Reconciler 和 Fiber Reconciler。这里的协调从狭义上来讲,特指 React 的 diff 算法,广义上来讲,有时候也指 React 的 reconciler 模块,它通常包含了 diff 算法和一些公共逻辑。
回到 Stack Reconciler 中,Stack Reconciler 的核心调度方式是递归。调度的基本处理单位是事务,它的事务基类是 Transaction,这里的事务是 React 团队从后端开发中加入的概念。在 React 16 以前,挂载主要通过 ReactMount 模块完成,更新通过 ReactUpdate 模块完成,模块之间相互分离,落脚执行点也是事务。
在 React 16 及以后,协调改为了 Fiber Reconciler。它的调度方式主要有两个特点,第一个是协作式多任务模式,在这个模式下,线程会定时放弃自己的运行权利,交还给主线程,通过requestIdleCallback 实现。第二个特点是策略优先级,调度任务通过标记 tag 的方式分优先级执行,比如动画,或者标记为 high 的任务可以优先执行。Fiber Reconciler的基本单位是 Fiber,Fiber 基于过去的 React Element 提供了二次封装,提供了指向父、子、兄弟节点的引用,为 diff 工作的双链表实现提供了基础。
在新的架构下,整个生命周期被划分为 Render 和 Commit 两个阶段。Render 阶段的执行特点是可中断、可停止、无副作用,主要是通过构造 workInProgress 树计算出 diff。以 current 树为基础,将每个 Fiber 作为一个基本单位,自下而上逐个节点检查并构造 workInProgress 树。这个过程不再是递归,而是基于循环来完成。
在执行上通过 requestIdleCallback 来调度执行每组任务,每组中的每个计算任务被称为 work,每个 work 完成后确认是否有优先级更高的 work 需要插入,如果有就让位,没有就继续。优先级通常是标记为动画或者 high 的会先处理。每完成一组后,将调度权交回主线程,直到下一次 requestIdleCallback 调用,再继续构建 workInProgress 树。
在 commit 阶段需要处理 effect 列表,这里的 effect 列表包含了根据 diff 更新 DOM 树、回调生命周期、响应 ref 等。
但一定要注意,这个阶段是同步执行的,不可中断暂停,所以不要在 componentDidMount、componentDidUpdate、componentWiilUnmount 中去执行重度消耗算力的任务。
React Hook 限制了哪些内容?
主要有两条:
1、不要在循环、条件或嵌套函数中调用 Hook;
2、在 React 的函数组件中调用 Hook。
了解React18哪些内容
react-dom/client中的createRoot
自动批量处理 Automatic Batching
transition
Suspense
SuspenseList
useId
useSyncExternalStore
useInsertionEffect
推荐阅读:


面试题库推荐


三、最后
希望本文对小伙伴们寻找新机会有所帮助~加油
欢迎关注前端早茶,与广东靓仔携手共同进阶~