
硬核干货 | 揭秘TDSQL新敏态引擎Online DDL技术原理
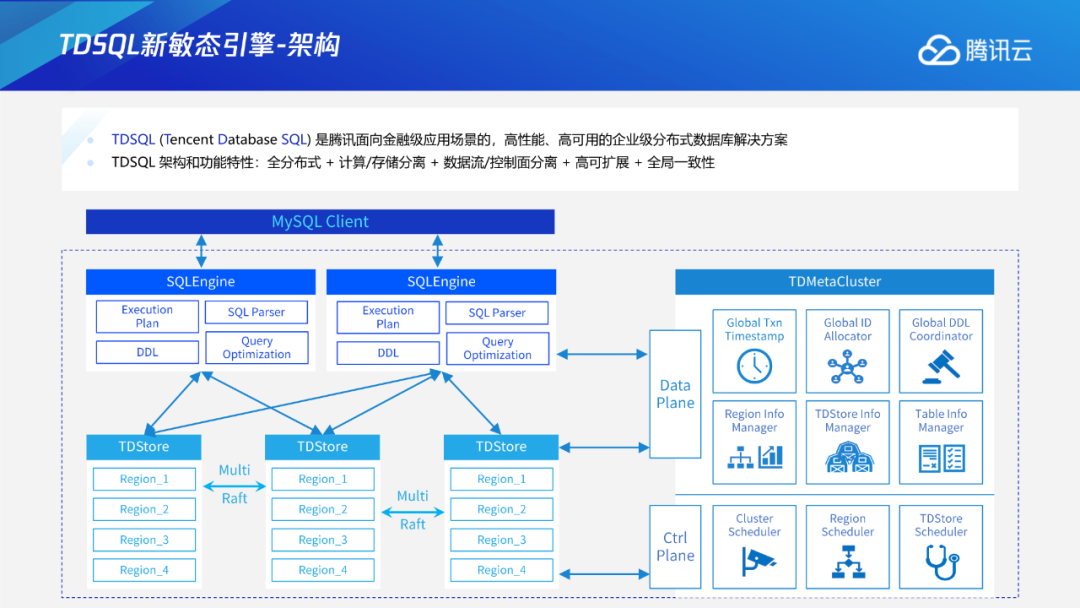
近日,TDSQL新敏态引擎重磅发布。该引擎可完美解决对于敏态业务发展过程中业务形态、业务量的不可预知性,实现PB级存储的Online DDL,可以实现大幅提升表结构变更过程中的数据库吞吐量,有效应对业务变化;其独有的数据形态自动感知特性,使数据能根据业务负载情况实现自动迁移,打散热点,降低分布式事务比例,获得极致的扩展性和性能。
与此同时,TDSQL 新敏态引擎还具有对分布式事务完整支持的特性,支撑了上层计算引擎多主读写架构的实现,并与计算引擎结合实现了计算下推、分布式事务一阶段优化等多维度优化,进一步实现分布式数据库系统性能极致提升,有效适配企业新敏态业务需求。在腾讯内部业务实践中,TDSQL新敏态引擎可支撑业务在保持高性能且连续服务的基础上,一个月内完成高达1000次表结构在线变更。
在高频的表结构变更过程中,如何减少对在线业务请求的影响,甚至使得用户能够以原生、不阻塞业务的方式进行,这就成为了TDSQL新敏态引擎面对的技术挑战。本期将由腾讯云数据库高级工程师赵东志,为大家深度解读TDSQL新敏态引擎OnlineDDL的原理与实现。以下是分享实录:
Instant DDL
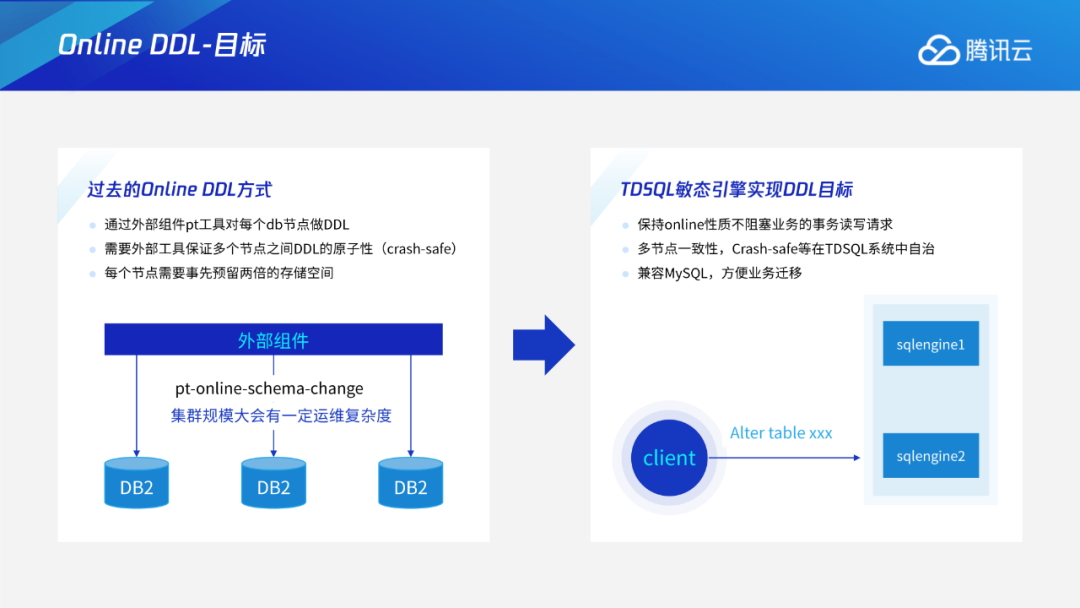
保证Online性质,做到不阻塞业务读写请求。 保证多节点缓存一致性,使得Crash-safe等在TDSQL系统中自治。 兼容MySQL,方便业务迁移。
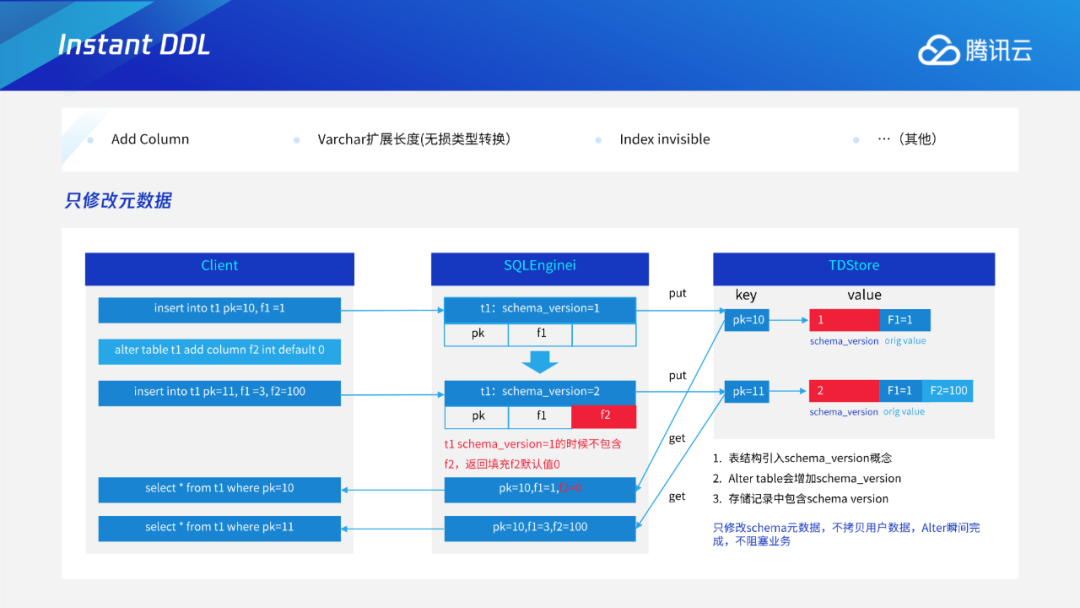
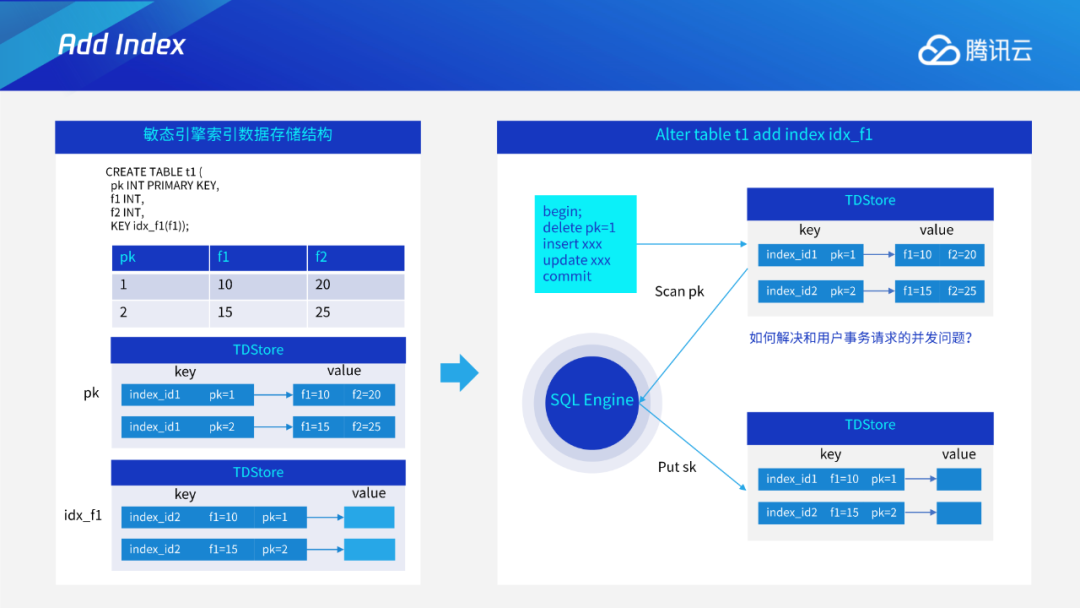
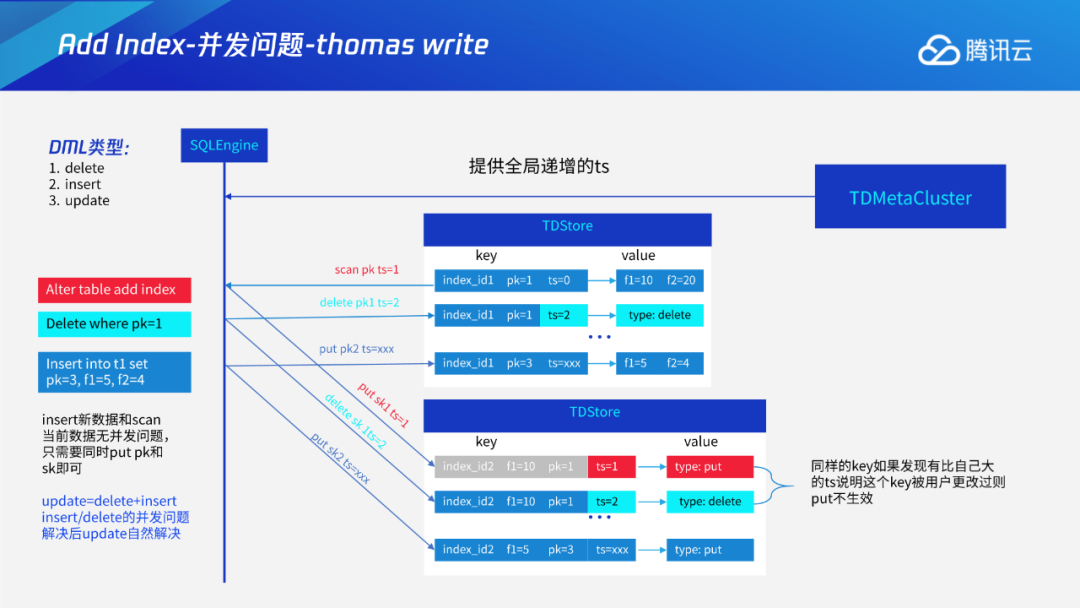
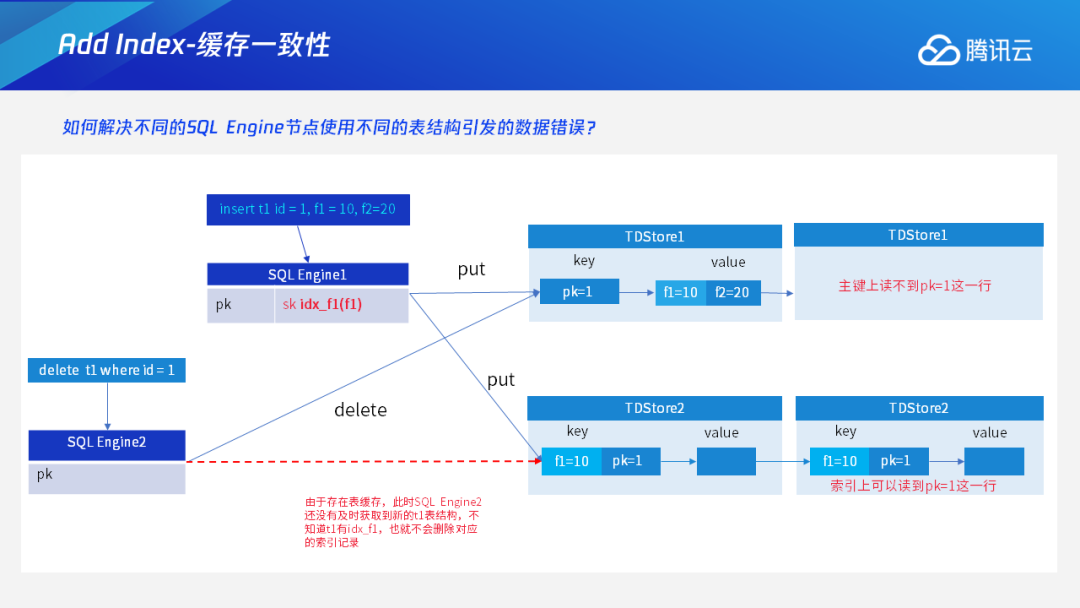
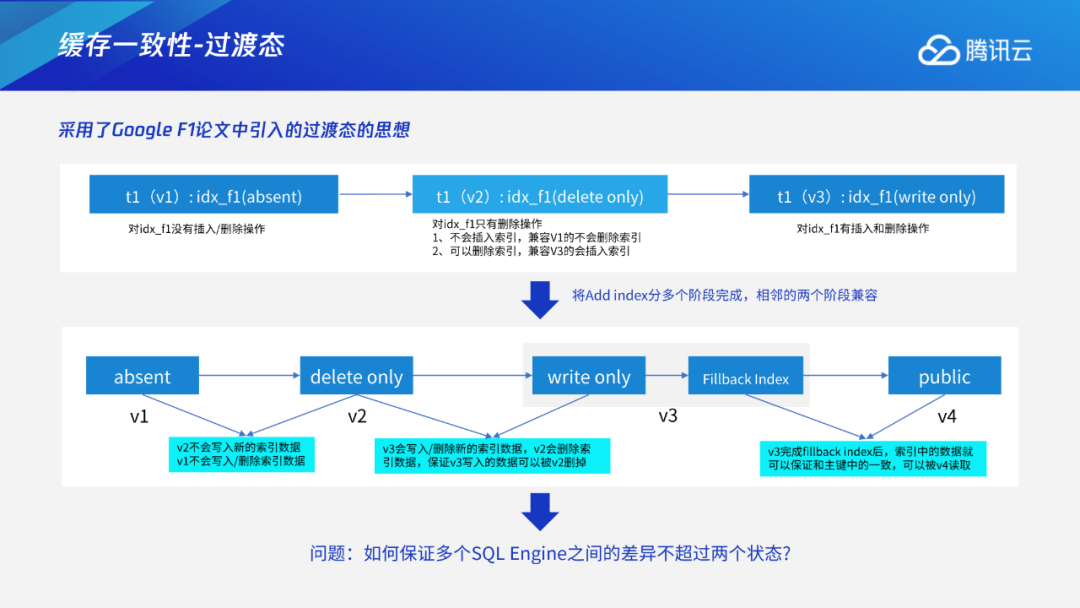
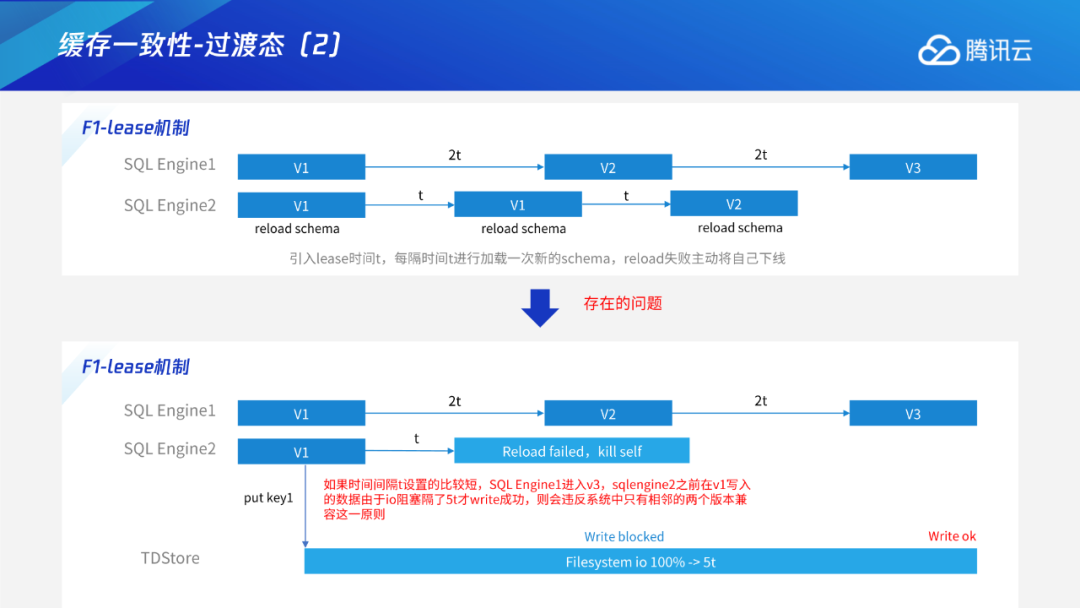
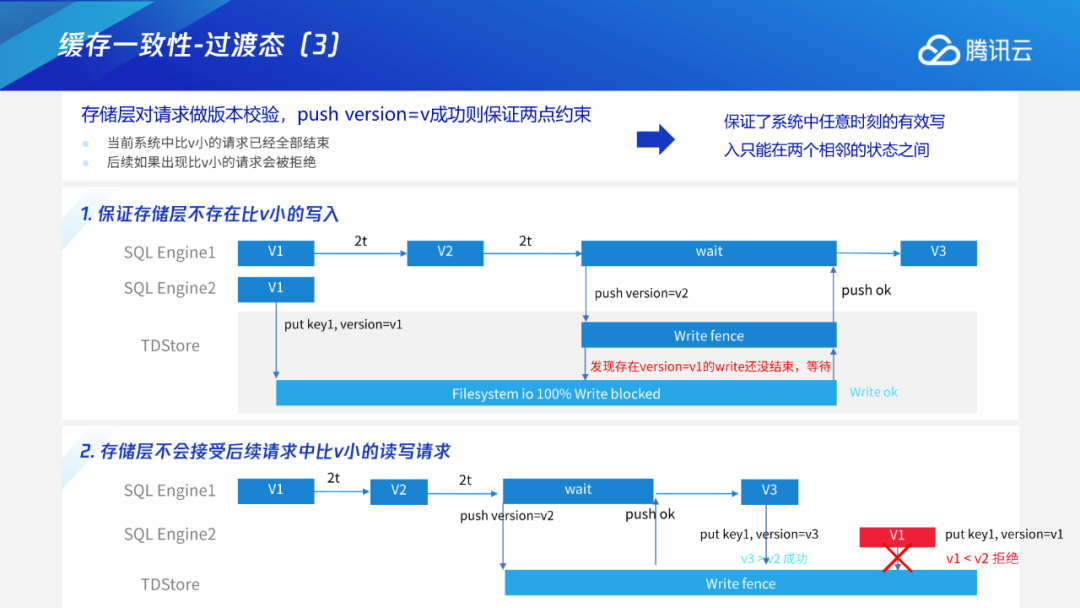
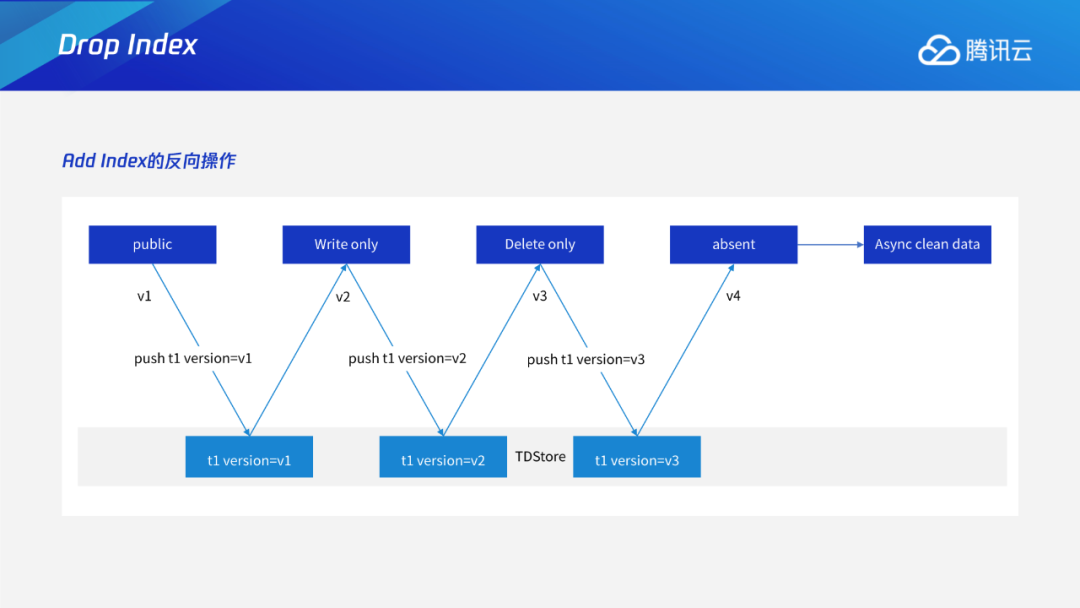
Add/Drop Index

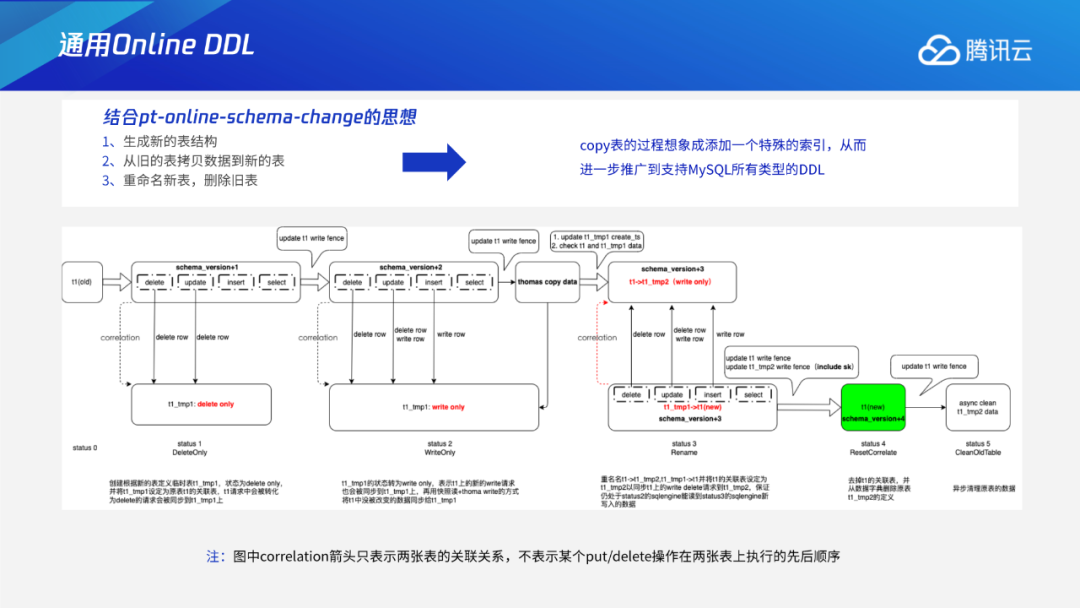
通用Online DDL
Online DDL原子性

总结
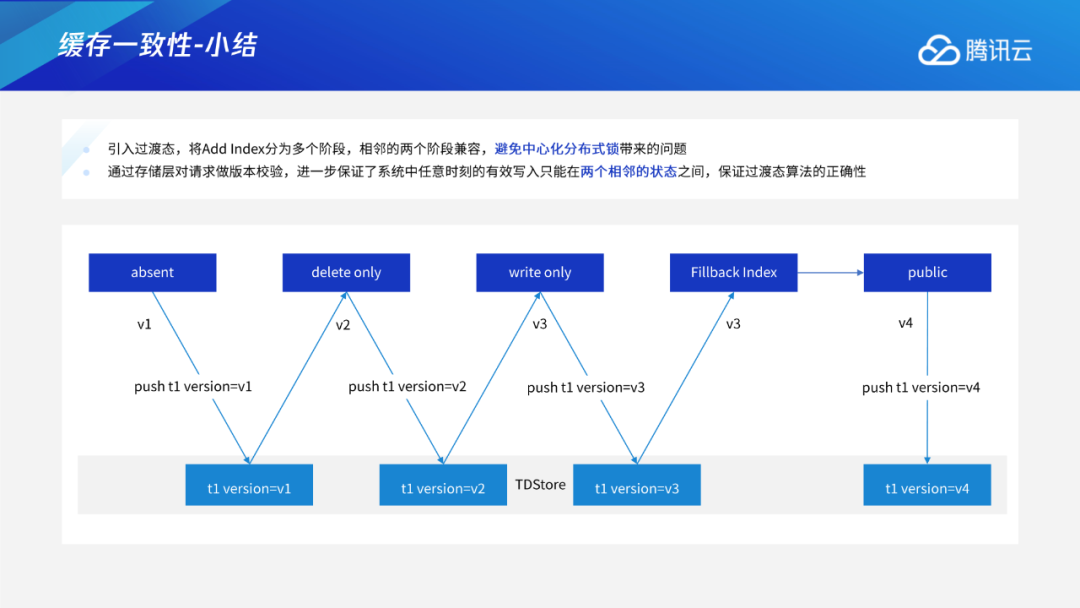
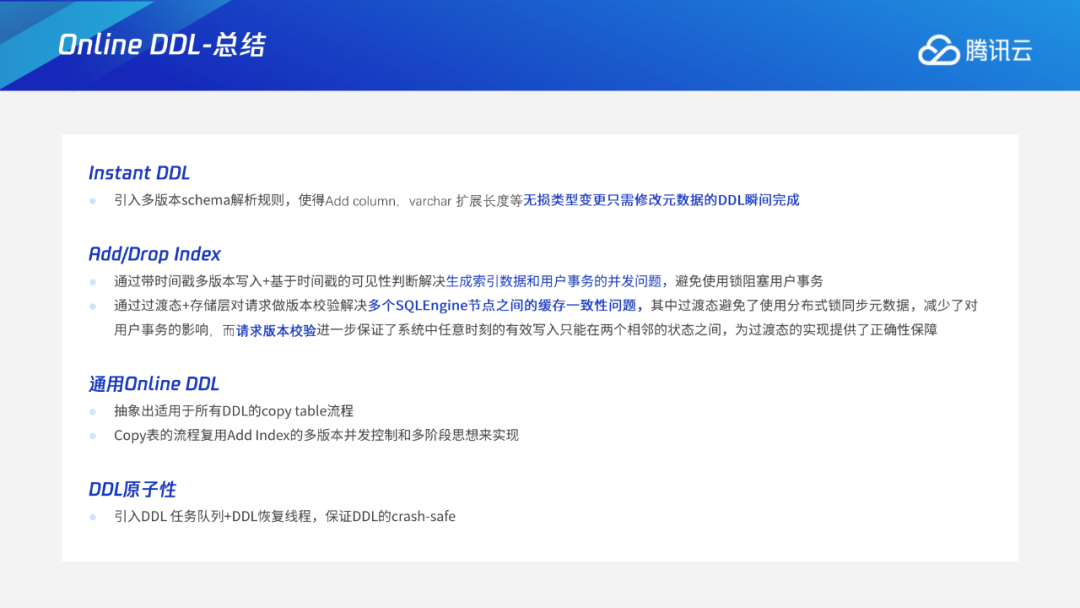
Instant DDL:通过多版本的解析规则,使得加列或varchar扩展长度等无损类型变更这些只需修改元数据的DDL瞬间完成。 Add/Drop Index:通过托马斯写机制,解决生成索引数据和用户事务的并发问题;采用F1过渡态+存储层版本交验机制,解决多个节点间缓存一致性问题。 通用Online DDL:抽象出适用于所有DDL的copy table流程,进一步将Online DDL推广到可支持绝大多数MySQL的DDL。 DDL原子性:通过任务队列+恢复线程的工作机制,保证DDL整体的原子性。
﹀
﹀
﹀

一文详解TDSQL PG版Oracle兼容性实践

云原生数据库TDSQL-C关键技术内核解密
评论