
删库后,咱除了跑路还能干什么?
小伙伴们大家好呀,我是小牛肉,今天分享一篇百度大佬的文章,删库跑路调侃归调侃,如果实际发生了咱能做些什么挽回损失呢~
目录:
前言
数据备份有哪些种?
实用的mysqldump备份方式
得先知道什么是GTID
看一条binlog长啥样
数据恢复
下一篇:两阶段提交和分布式事务
前言
看完本篇你将了解:常见的数据库备份方式、mysqldump实战、一条binlog长啥样、什么是gtid?什么是binlog位点?mysqlbinlog数据恢复实战。
数据备份有哪些种?
MySQL中数据备份的方式还是蛮多的,常见的有冷备份、逻辑备份、热备份、快照备份。
什么是冷备份?
所谓的冷备份,说白了就是在数据库停止运行的情况下,直接备份磁盘中MySQL用来存储数据的那些数据文件。
在前面的文章中,白日梦跟大家分享过MySQL的表空间。看过那篇文章的同学都知道,MySQL中的数据最终都存储在表空间中的。表空间 == 表空间文件。其实而所谓的空间,本质上对应着存在于操作系统磁盘上的肉眼能看到的物理文件。
下面你可以看一下我的MySQL的表空间文件都是怎么配置的,以及它们都在哪里。
MySQL版本:5.7 ,并且我在 my.cnf 配置文件中添加了如下的配置。
# 表示每一个数据库单独使用一个表空间
innodb_file_per_table=on
然后我创建数据库:stusy。
创建数据表:test_backup。
进入到如下的目录中,你可以看到MySQL为我们创建的数据库表创建出了单独的目录,而目录中的有 .frm、.idb文件就是冷备份需要备份的文件。

什么是逻辑备份?
逻辑备份指的是使用 mysqldump 工具去备份数据。使用mysqldump进行数据库的逻辑备份也是在做的各位RD需要掌握的技能。日常开发中难免会有将线上的数据备份到测试环境使用的场景。
为啥说mysqldump是逻辑备份?原因大概是:你使用mysqldump去备份最终得到的参数其实是一堆sql,再通过回放sql的形式完成数据的恢复。白日梦之前的文章中跟大家分享过(可自行查看历史文章哈)。在MySQL中数据表、数据行其实是逻辑存上的概念。像数据页这种概念是物理真实存在的。所以你用mysqldump得到一堆sql,自然称得上是逻辑备份喽。
下文中具体说,mysqldump实战。
什么是热备份?
所谓热备份其实是指:直接对运行中的数据库进行备份。相对于冷备份,热备份还是比较复杂的。你想啊,对处于运行过程中的数据库进行备份,肯定就得将一些增量的数据也备份进去。
通常人们会使用一款叫:xtraback 的工具完成数据库的热备份。
除此之外,我了解有一款Golang写的开源工具 ghost,在github上还是挺火的。它是一款支持做无损DDL的工具(后面会专门有一篇文章讲这个工具的原理)。这款工具在实现支持无损DDL功能时,有一部分逻辑本质上也是在支持增量数据的备份。
ghost的实现手段是:添加binlog监听事件,监听到binlog event后去解析binlog得到sql,再回放这个SQL。就像是从库使用主库对binlog进行数据恢复一样。
什么是快照备份?
再了解一下什么是快照备份:
快照备份不是数据库本身提供的能力,本质上它是借助于文件系统的快照功能来实现的对数据库的备份。
我们知道的Linux服务器本质上也是电脑的,它会有自己的磁盘,无论是固态硬盘,还是机械磁盘。反正会有这种固态存储。还需要进一步对磁盘进行分区。然后才有将Linux文件系统中的目录都会挂载在不同的分区上。这么做的目的,简单来说就像你的window有C盘、D盘、E盘。D盘中的出问题后不会影响E盘一样。
快照备份要求:数据库的所有数据文件都要放在一个数据分区中。
常见的支持快照工具的文件系统和设备有:FreeBSD、UFS文件系统、Solaris的ZFS文件系统。GNU/Linux的LVM(Logical Volume Manager)
实用的mysqldump备份方式
本小节看几个实战mysqldump备份case。
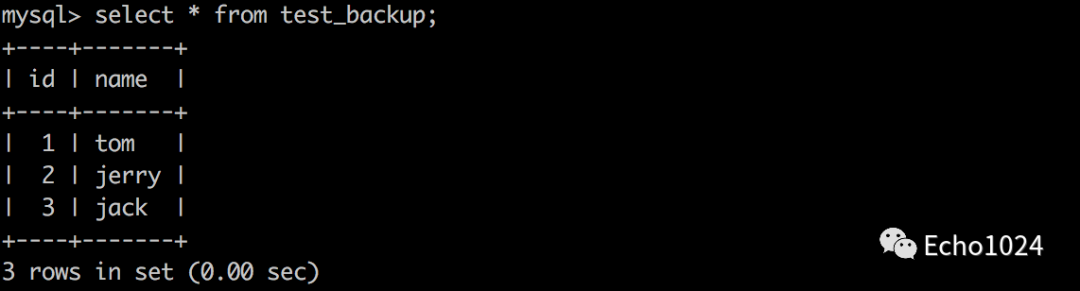
测试环境:创建如下表
CREATE TABLE `test_backup2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据表中写入3条数据
mysqldump语法
mysqldump [arguments] > file_name;
1、备份指定的数据库
通过参数--databases 指定你要备份的数据库
# mysqldump -uroot -p --databases db1 db2 db3 > 自定义名.sql;
./mysqldump -uroot -p --databases stusy > test_backup.sql;

因为我开启了GTID,所以直接执行如上的命令行有报错提示说:如果我只想完成数据的dump,需要在命令行中添加上它提示的那些参数。
# 如果你没有开启GTID选项,它提示我加的这些参数你都没有必要添加的。
# --triggers 备份触发器
# --routines 备份存储过程和函数
# --events 备份事件调度器
./mysqldump --set-gtid-purged=OFF --databases stusy --triggers --routines --events -uroot -p > test_backup.sql;
查看产出的SQL文件:
注意点:使用参数 --databases 参数。最终产出的SQL中为你创建数据库了。
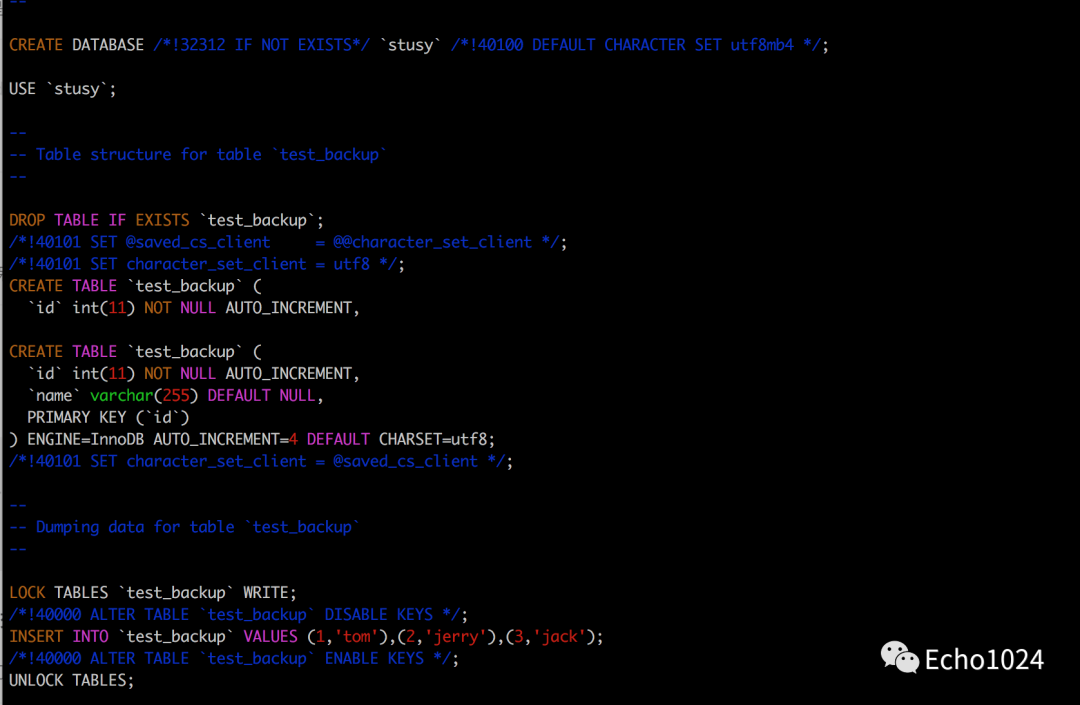
文件开始和结束的部分有很多注释,这些注释可以用来设置MYSQL数据的各项参数。一般用来保证还原数据时可以更加有效准确的工作。
2、备份指定数据库中的指定数据表:通过参数 `--tables` 指定你要备份的数据表。
# mysqldump -uroot -p --databases db1 db2 db3 --tables t1 t2 > 自定义名.sql;
./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events -uroot -p > test_backup.sql;
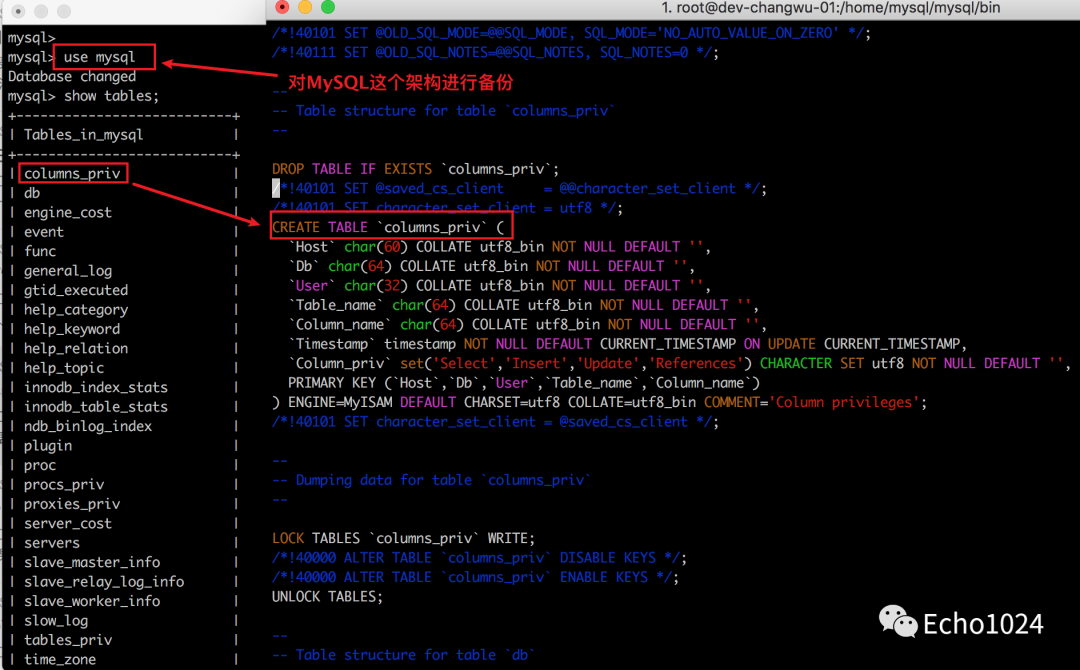
3、对一个架构进行备份
不使用--databases,直接写数据库名。对整库架构进行备份
./mysqldump --set-gtid-purged=OFF --triggers --routines --events -uroot -p mysql> mysql_backup.sql;
查看备份的结果
注意点:相对于使用 --databases 参数来说。最终产出的SQL中!!没有!!为你创建数据库。
4、重点理解参数:--single-transaction
如果你想获得一份“一致性备份”可以使用该参数。那什么是一致性备份呢?
添加--single-transaction参数后,mysqldump会自动帮你执行 start transaction 开启事务的SQL。如果你看过白日梦之前写的 “我劝!这位年轻人不讲MVCC,耗子尾汁!”,想必你一定了解,MVCC的实现原理,回到现在的这个问题中,也就是说,只要你执行开启事务的语句就会得到一个一致性可重复读的视图(read view)。说白了:此次执行mysqldump得到的SQL文件中的数据,就是你执行的该命令的那个瞬间,打下的快照的数据。
注意:如果你不使用--single-transaction参数,会自动添加上--lock-all-tables。此外,还需要知道当我们使用参数--single-transaction获取到的那个一致性实图并不能隔离DDL(表级别的操作,比如添加列)。所以你要确保在备份时没有其他的DDL语句执行。
5、重点理解参数:--master-data
# 当值为1时,转存文件中会有change master 语句。
--master-data = 1
# 当值为2时,转存文件中当 change master 语句会被注释。
--master-data = 2
下面分别让 --master-data 为不同的值。查看产出。
./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events --master-data=2 -uroot -p > test_backup.sql;
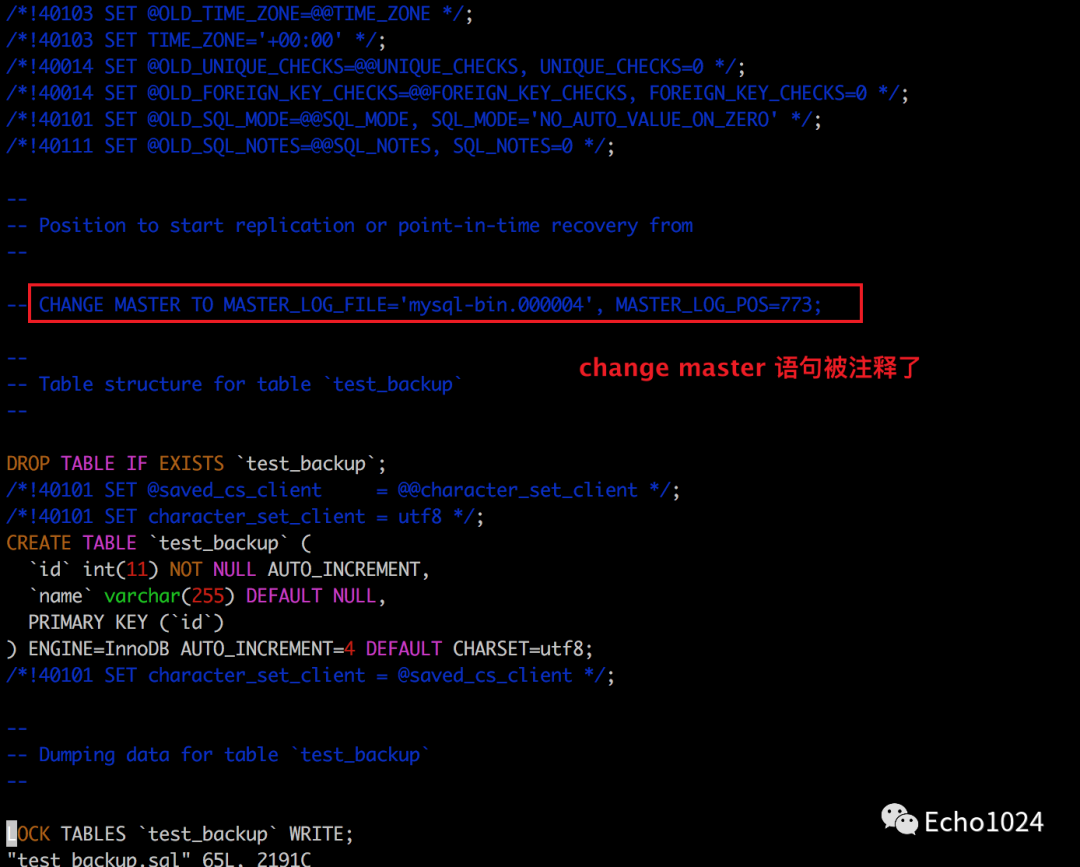
./mysqldump --set-gtid-purged=OFF --databases stusy --tables test_backup --triggers --routines --events --master-data=1 -uroot -p > test_backup.sql;
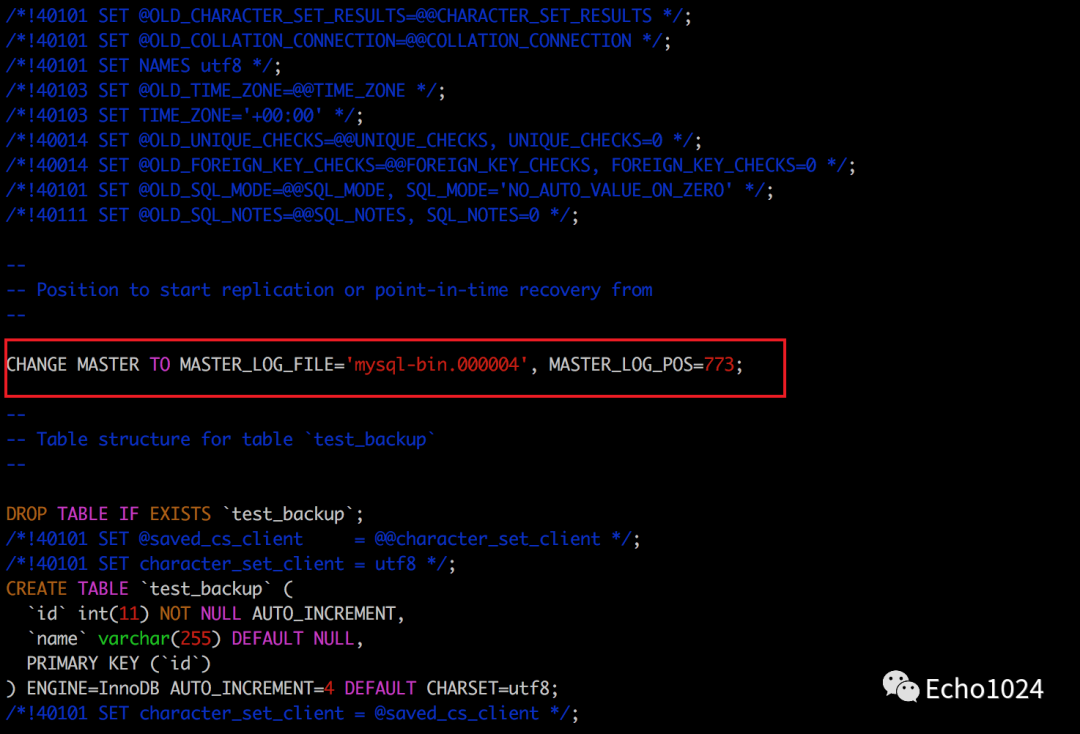
一般搭建过mysql集群的同学都知道这条change master sql语句的作用是:从库认主库的命令。
是的,使用参数--master-data=1得到的备份文件通常主要作用是创建一个replication(从库)。
上面介绍了工作中常用的几种用法和注意点。
其实mysqldump支持的参数多达几十个。你可以使用 --help查看它们。
如果上面的参数不能满足你的需求。你可去官网查阅:https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
得先知道什么是GTID
GTID (global transcation identifier)它是MySQL5.6版本中添加进来的新特性 ,使用GTID可以唯一的标识一个事物。
我用大白话描述一下GTID常见的作用:
比如一条update有语句进入MySQL之后经历如下过程:
1. 写undolog
2. 写redolog(prepare)
3. 写binlog
4. 写redolog(commit)
# 这也是所谓的两阶段提交
不管你有没有自己搭建过MySQL集群,你一定听说过MySQL集群!主库将自己成功执行过的事物都写在binlog,然后集群中的从库会dump主库记录的binlog回放出数据,完成数据同步。当我们将GTID相关的配置打开后,update语句经历如下过程:
1. 写undolog # 回滚
2. 写redolog(prepare)# 保证提交的不会丢失
3. 写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID
4. 写binlog # 主从同步事物使用
5. 写redolog(commit)
也就是说mysql会在binlog中多为我们记录一行gtid。这个gtid和当前事物唯一对应。不会重复。
这时当从库向主库发送同步数据的请求时:bin-log和gtid都会传送到slave端,从库在回放日志同步数据时,同样会使用gtid写bin-log,这样主库和从库之间的数据,就通过GTID强制性的关联并且保持同步了。
下图截取自binlog一条事务,你可以看到里面会记录gtid。
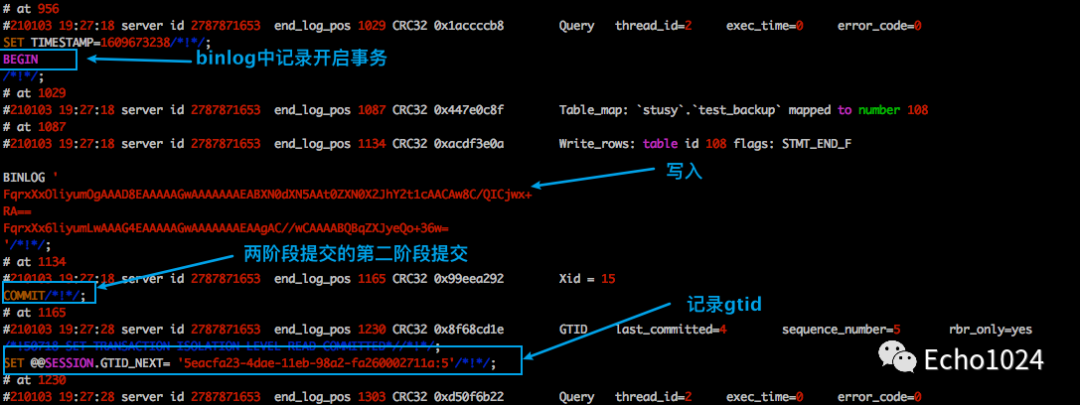
这时如果从库想在主库同步数据,只需要告诉主库自己有哪些gtid就好了,主库会把从库没有的gtid对应的事务日志给从库让它去同步数据。
而在这种方式出现之前,主从之间同步数据时,从库需要告诉主库自己已经同步到binlog.0000x,position=yyy的地方了。这个binlog.0000x,position=yyy需要人为的去查看一下。不能说查看这两个信息比较麻烦,但是肯定不如GTID来的方便。
看一条binlog长啥样
为了对小白友好一点,再看一下这张图:
首先你得知道,像select这种查询类型的sql,是不会被记录进binlog中的,binlog中只会记录对数据库作出修改的写入或者更新的sq。就像上图中,你可以看我图中begin、xxx、commit。
另外binlog中是有位点的,人们一般把称它叫:position。其实所谓的位点就是上图中的at xxx中的xxx。
每一个事物都有自己的开启、结束位点,换句话说我们可以通过开始和结束的位点找到一个或者是好多和事物。就上图来说,这个事物的start-positon=956,stop-position=1230。
这个位点有啥用呢?
作用1:搭建主从集群时,通过下面的命令告诉从库,应该从主库的哪个binlog的哪个位点开始同步数据
CHANGE MASTER TO
MASTER_HOST='10.157.23.158',
MASTER_USER='mysqlsync',
MASTER_PASSWORD='mysqlsync123',
MASTER_PORT=8882,
MASTER_LOG_FILE='mysql-bin.000008',
MASTER_LOG_POS=1013; # 这就是位点
作用2:数据恢复时,指定从哪个位点恢复到哪个位点。或者跳过哪个位点,下面我们一起看下基于binlog的数据恢复。
如果你不曾搭建过集群,没关系,欢迎关注白日梦,我后面会分享基于 binlog+position、基于gtid、基于docker+gtid搭建MySQL集群的方法。
数据恢复
不知道你有没有误删过数据库中的数据,之前我就误删过。不过还好是测试环境的。
其实误删数据后是可以通过binlog将数据恢复出来的。既然是使用binlog恢复数据,前提是你的MySQL开启了binlog(默认情况下mysql不会帮你记录binlog,如果你还不知道什么是binlog也没关系,白日梦前面的文章有分享,你可以去看下)。
大部分情况下,DBA同学会将你使用的MySQL binlog打开。你可以像下面这样验证一下自己使用的数据库binlog是否打开了。如果没有打开binlog,数据可能真的没办法恢复。
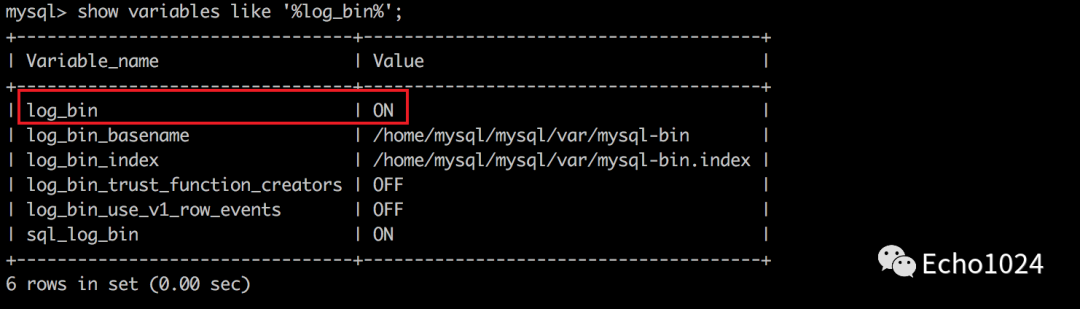
线上的数据库不断承接流量,binlog会不断滚动变大,你要赶在binlog被清理之前去恢复数据。
下面一起看看如何使用binlog恢复数据,下面看我的实验步骤:
先查看我的所有的binlog:
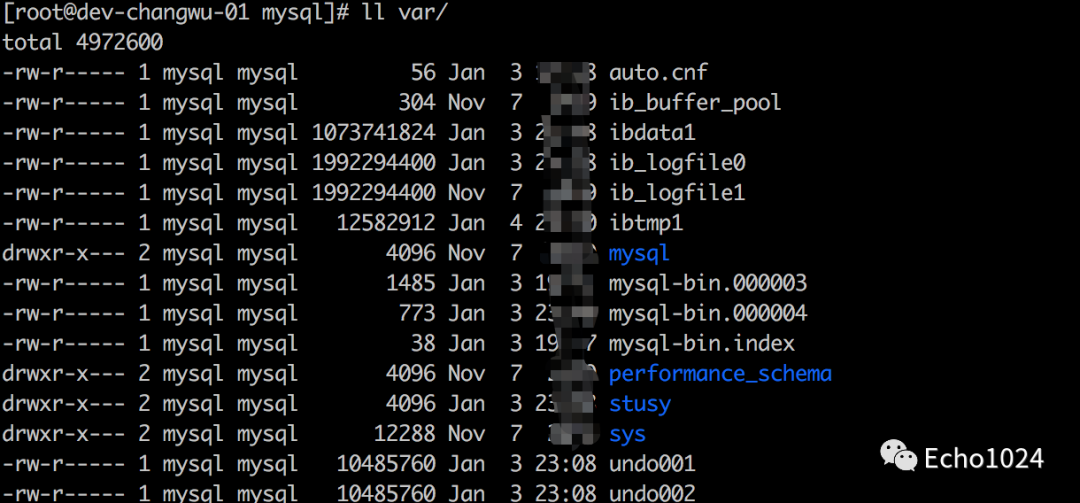
然后我把数据库中的数据全部删除。

情况一:没有开启GITD
如果你的MySQL没有开启GTID。直接使用下面的命令,就能把你指定的binlog中指定范围的positon的数据回放出来。
./mysqlbinlog start-positon=956,stop-position=1230 ../var/mysql-bin.000003 | ./mysql-uroot -p
除了用位点缩小范围,还可以指定开始时间和结束时间来缩小范围。
思考这样的情况:
假设你没有赶在binlog被清理之前去恢复数据,当你去恢复数据时上图中delete sql之前的binlog已经被删除了。那怎么办?
这时你可以通过最近的全量备份把delete之前的数据恢复出来,然后delete之后的增量数据,通过mysqlbinlog工具恢复出来,注意别忘了通过positon跳过这个delete,不然一执行会放出来delete语句,数据又全被删除了。
如果你没有全量备份,binlog也不全了。那估计就悬了!
情况二:开启GITD
开启GTID的MySQL,同样执行这行命令恢复数据会遇到下面的错误。
./mysqlbinlog start-positon=956,stop-position=1230 ../var/mysql-bin.000003 | ./mysql-uroot -p

如果你看了前面白日梦跟你介绍的什么是GTID,想必你已经知道为啥报错了。因为你用binlog回放数据,其实就是让mysql重新执行一下binlog中记录的逻辑,问题就出在binlog中记录了set next_gtid=xxx,因为gtid唯一的,是不能重复的。
所以需要添加参数--skip-gtids=true
[root@dev-changwu-01 bin]# ./mysqlbinlog --skip-gtids=true --start-position=684 --stop-position=1485 ../var/mysql-bin.000003 | ./mysql -uroot -p
Enter password:在准备面试或者有想要发布内推信息的小伙伴,可以加我微信,我拉你进【互联网春|秋招交流群】,大家一起吐槽信息共享呀~