
JUC并发编程之Volatile关键字详解
保证被volatile修饰的共享变量对所有线程总数可见的,也就是当一个线程修改了一个被volatile修饰共享变量的值,新值总是可以被其他线程立即得知。
禁止指令重排序优化。
@Slf4jpublic class Test01 {private static boolean initFlag = false;public static void refresh() {log.info("refresh data.......");initFlag = true;log.info("refresh data success.......");}public static void main(String[] args) {Thread threadA = new Thread(() -> {while (!initFlag) {}log.info("线程:" + Thread.currentThread().getName()+ "当前线程嗅探到initFlag的状态的改变");}, "threadA");threadA.start();try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}Thread threadB = new Thread(() -> {refresh();}, "threadB");threadB.start();}}
带着这个疑惑,将代码稍微改动一下,往 "initFlag" 变量加上"volatile",然后再来看看它的效果是如何?
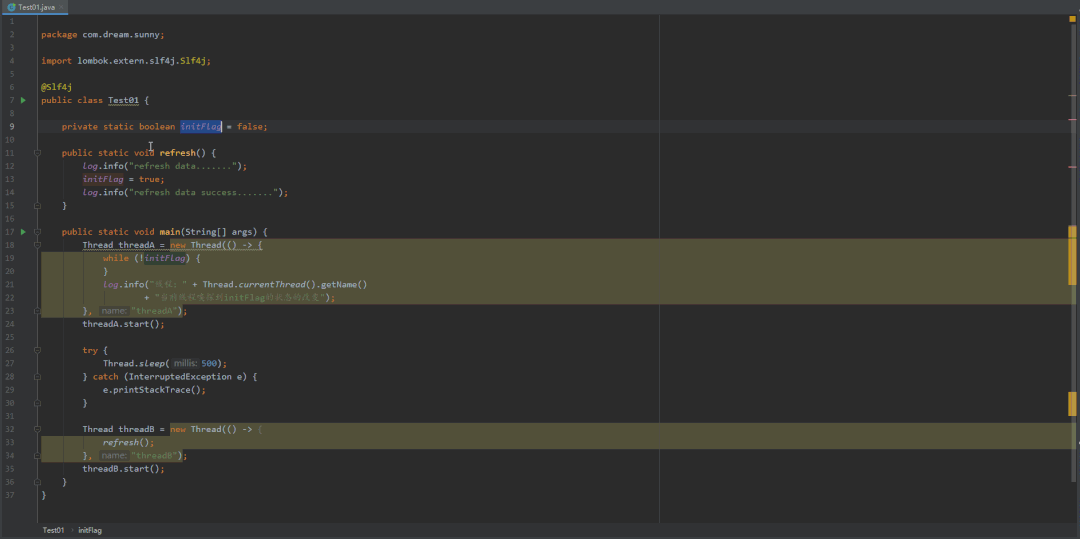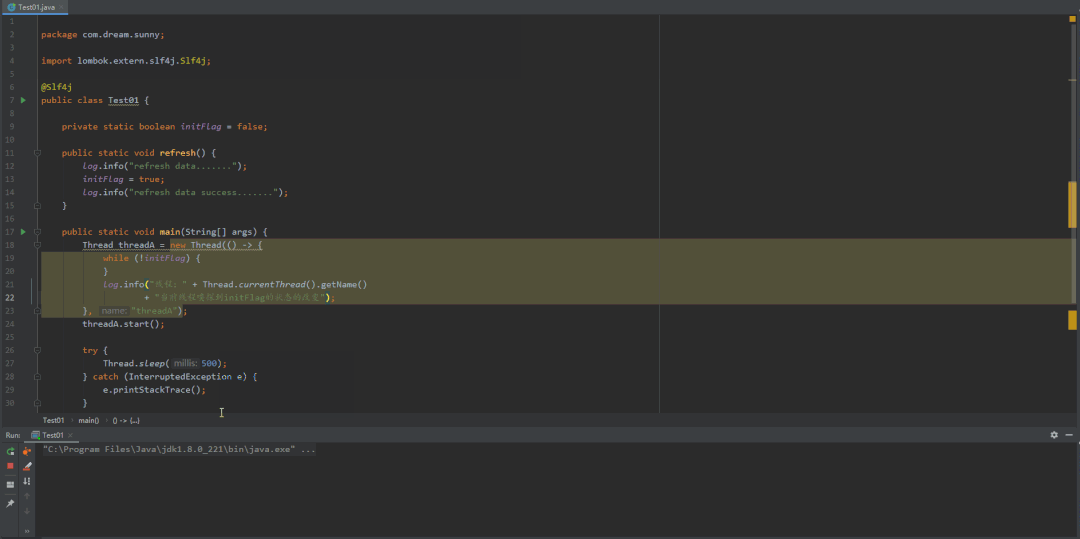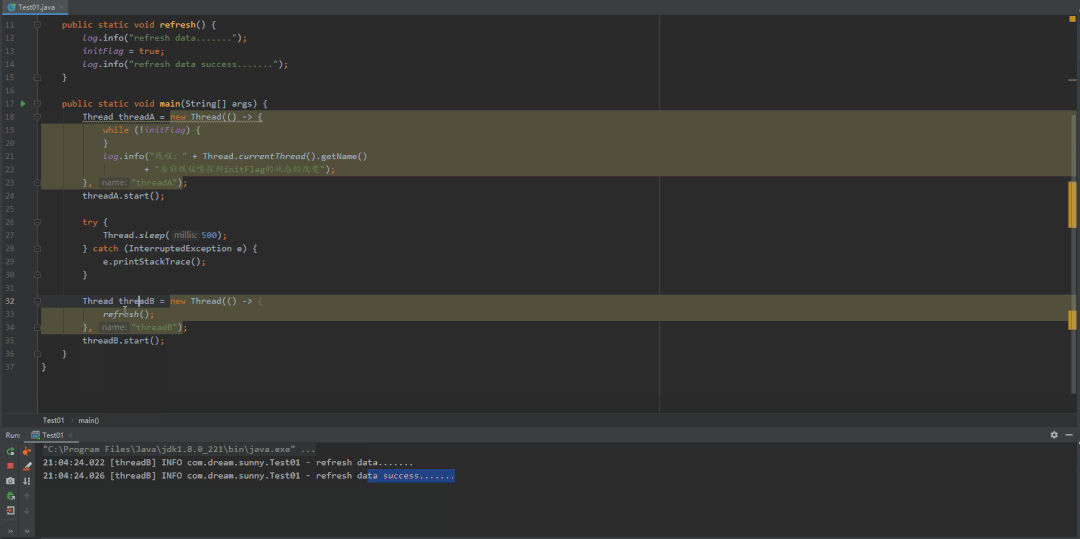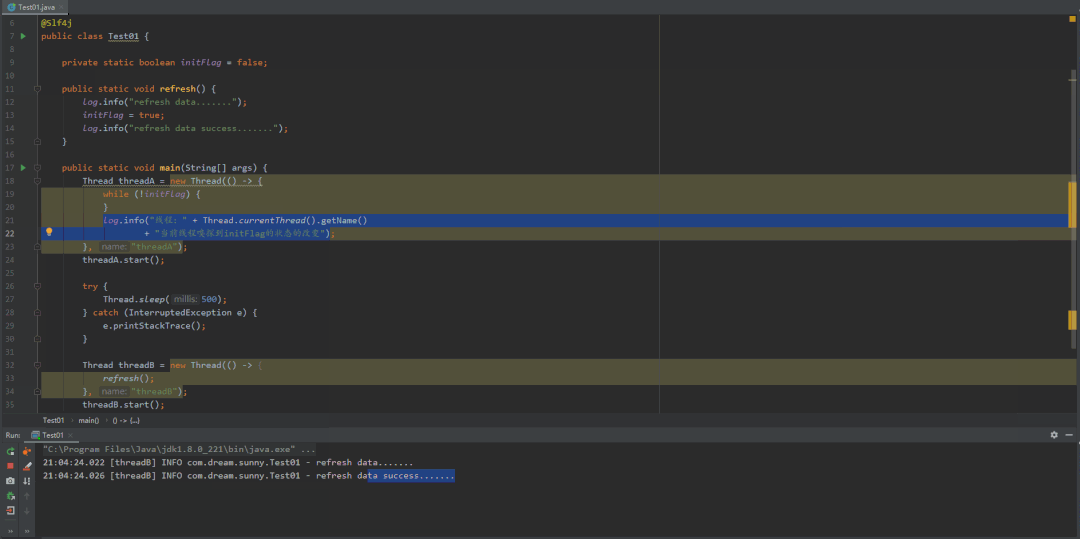
先来看看这种图,或许会更加的好理解一点
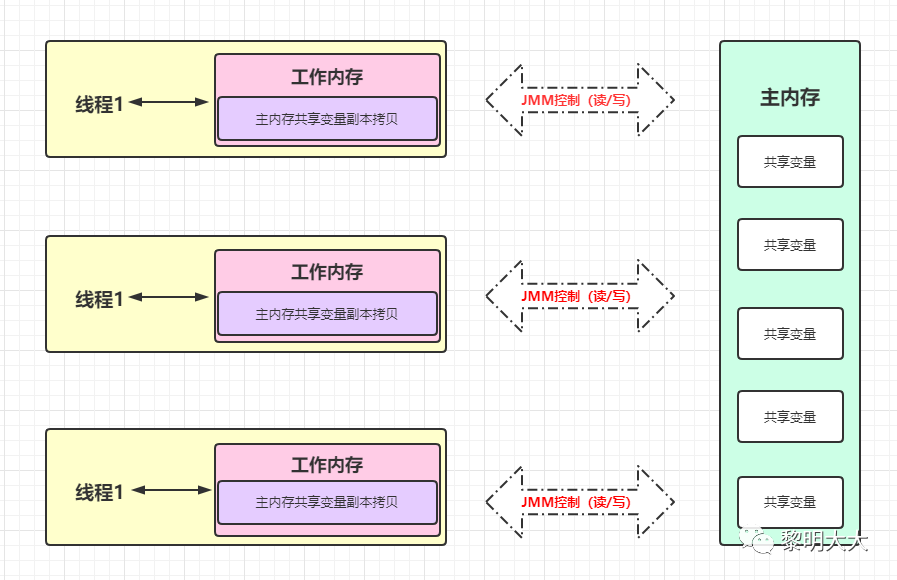
分析结论:先看到我红色标记的一段话,A线程内部的循环最终都会跳出来,只不过是时间长短的问题而已。
结合上图分析,initFlag作为成员变量,程序会将它存放在主内存中,当线程A和B启动后,如果线程需要用到主内存的initFlag,线程会从主内存中将变量复制一份到自己内部的工作内存中,然后再对变量进行操作。而不是直接在线程内部对主内存中的变量进行操作。那么这就会有一个问题,当线程B对工作内存中的initFlag值进行改变后,然后将initFlag值从工作内存中推回到主内存,这时候线程A可能不会立即知道主内存的值已经发生了改变,因为A线程中的空循环它的优先级是非常高的,它会一直占用CPU来执行这串代码,这就导致JVM无法让CPU分点时间去主内存中拉取最新的值。而加了volatile后,它会通知其他有用到initFlag变量的线程,强制它去拉取主内存中最新变量的值,然后重新刷回到内部的工作内存中。简单来说,加了volatile关键字会强制保证线程的可见性;而不加的话,JVM也会尽力的保证线程的可见性(也就是CPU空闲的时候),这也就是我前面为什么会说无论是否加了 "volatile" A线程内部的循环最终都会退出来原因。
看到这相信对volatile的可见性有了一定的了解,接着再继续来看看volatile它是否能够解决并发中的原子性呢?
public class Test02 {private static int counter = 0;public static void main(String[] args) {for (int i = 0; i < 100; i++) {Thread thread = new Thread(()->{for (int j = 0; j < 1000; j++) {counter++;}});thread.start();}try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(counter);}}
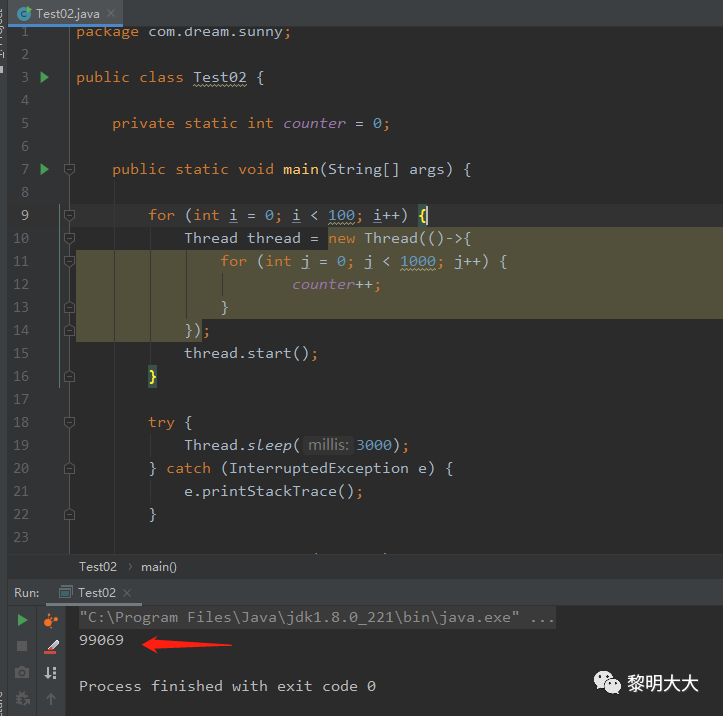
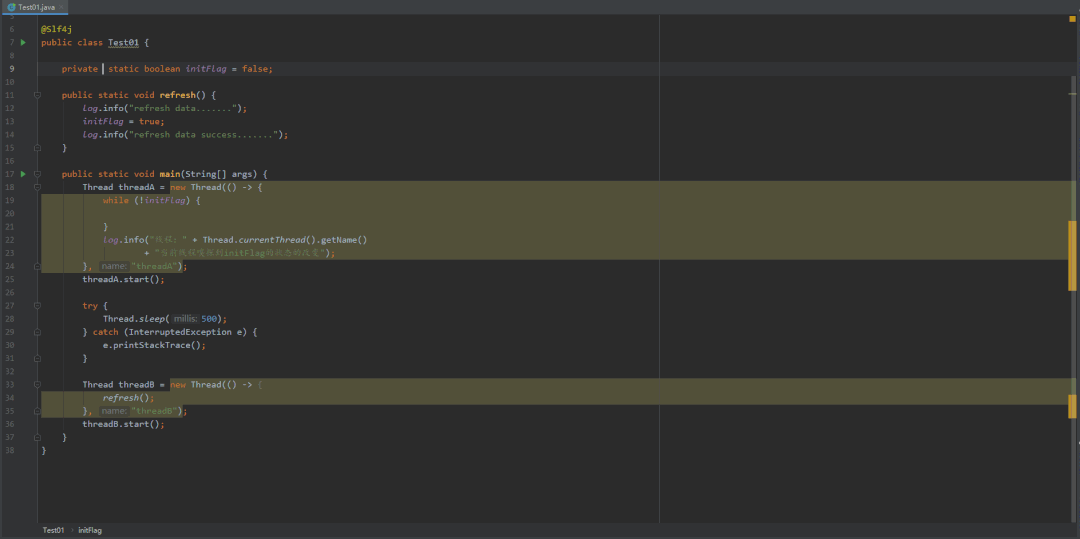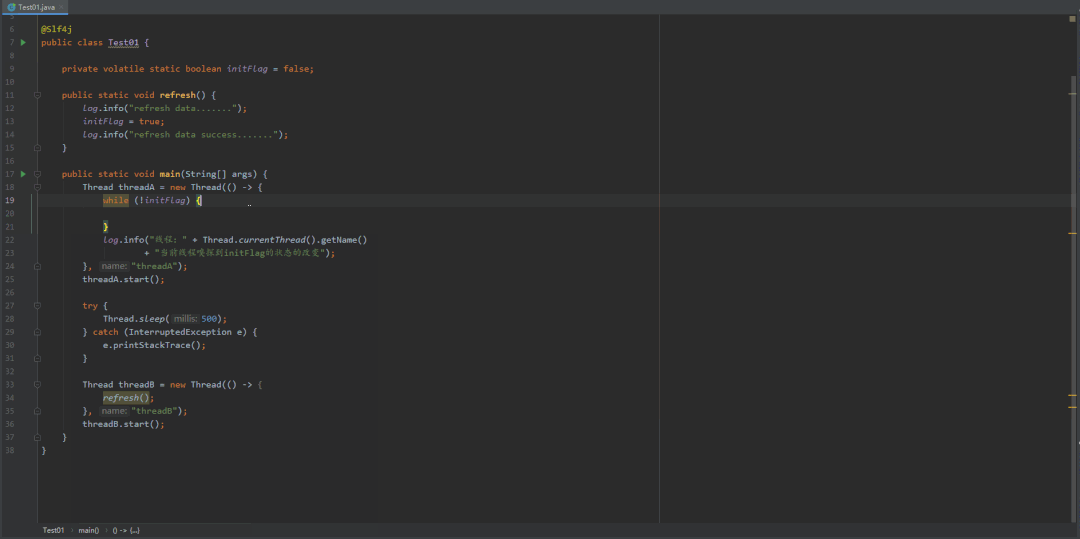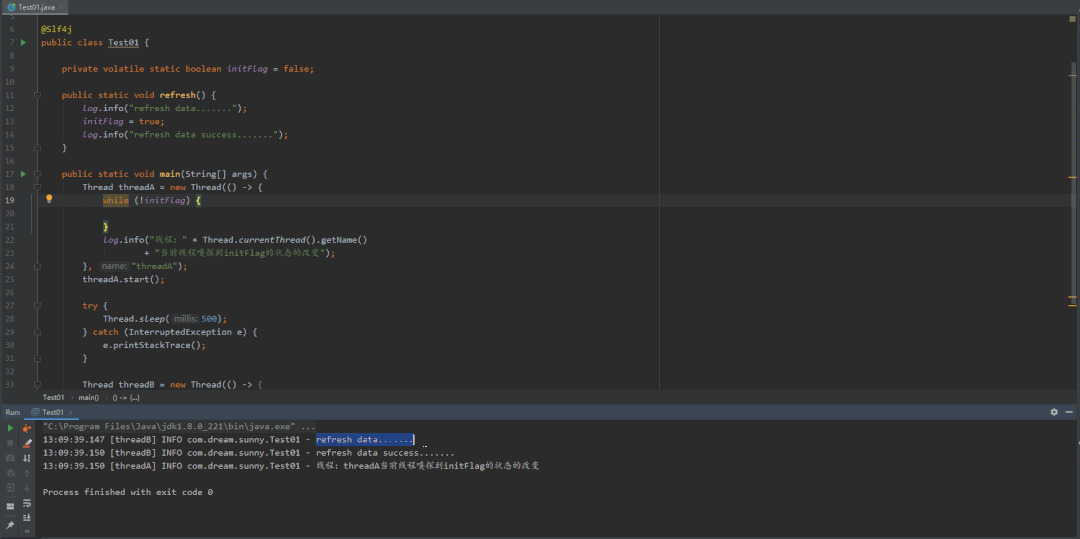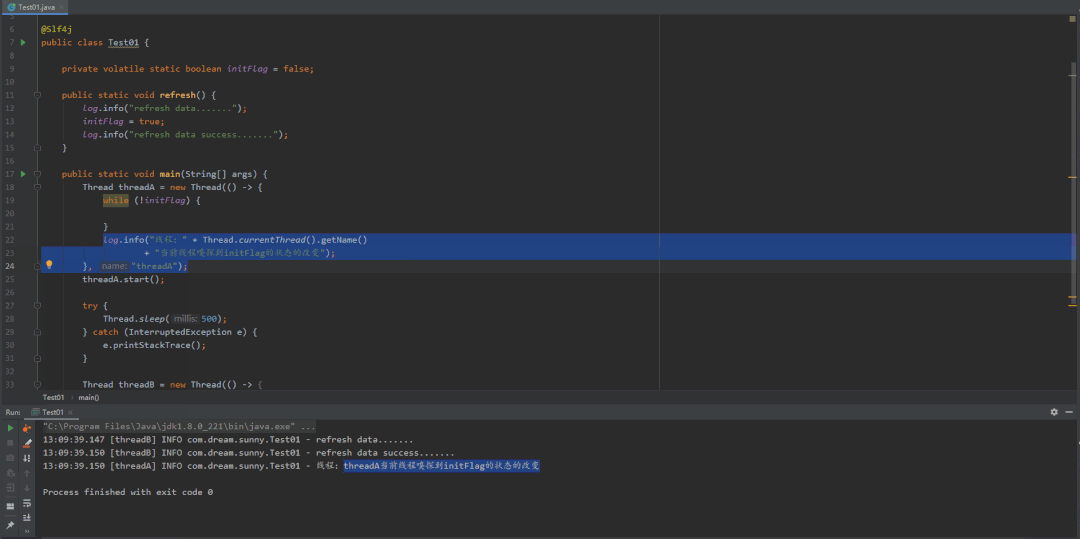
下图是在成员变量上加了volatile的效果图
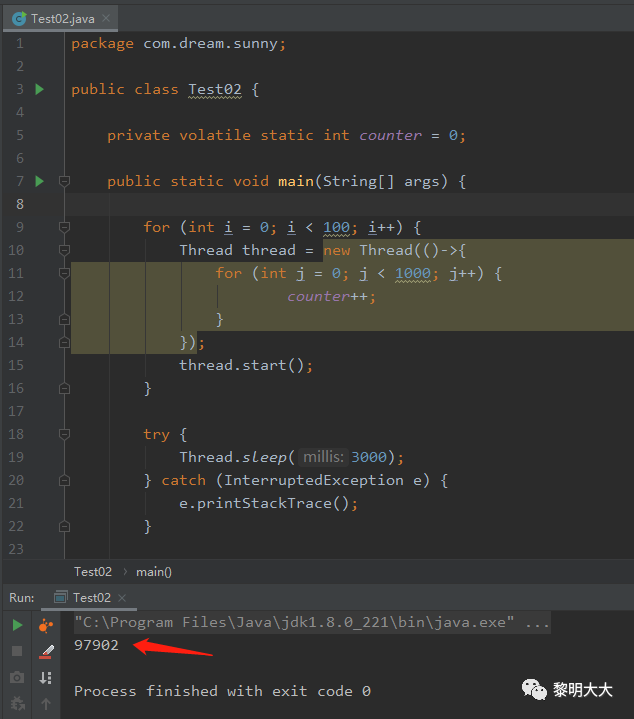
因为volatile它并不能够解决并发中的原子性问题,看到这是不是又懵逼了?代码中的counter++就一行代码,为什么不是原子操作呢??其实这里是有一个坑的,其实counter++并非是一步操作,它在底层是被拆分为三个步骤进行执行的,且看,counter++操作是counter = counter + 1的简写操作对吧,那么我们可以简单的思考一下,counter的值是怎么来的呢?
根据这个思考,再来拆分一下它三个细致的步骤:
我们都知道,线程是基于时间片进行执行的,在多线程下,假如线程内部刚好执行完第一步或者第二步操作,这个时候CPU发生中断操作,它并没有去执行该线程内的第三步操作(意思是暂停执行第三步操作,等到时间片轮询到该线程再回来继续执行接下来的操作),转而去执行另外一个线程的一个自增操作,这个时候就会出现问题,第一个线程执行完第二步操作后发生暂停,转而执行第二个线程自增操作,回看前面所说的volatile可见性特性, 因为加了volatile的原因,第二个线程改变完值后,会通知第一个线程现有的counter变量已经过期,需要重新去拉取主内存最新的值,这个时候就会造成,我两个线程都发生了自增操作,但是只有一个线程自增成功了,那么结果自然就不对,这也就造成了线程安全的问题。
从上面例子我们可以确定volatile是不能保证原子性的,要保证运算的原子性可以使用java.util.concurrent.atomic包下的一些原子操作类,或者使用synchronized同步块和Lock锁来解决该问题。
我前面有提到过线程是基于时间片执行的,从时间的维度上来讲,在线程内,上一行代码总会比下一行代码优先执行,但是在CPU里面它又不同了,它可能会将下一行的代码放到上一行先去执行,看到这估计有小伙伴有点懵了?啥玩意儿?这不是逗我玩吗?代码上中是从上往下执行,结果到你CPU又给我乱序执行?说着这,就不得不说到指令重排的概念了。
什么是指令重排
为什么要指令重排
下图为从源码到最终执行的指令序列示意图:

@Slf4jpublic class Test03 {private static int x = 0, y = 0;private static int a = 0, b = 0;public static void main(String[] args) throws InterruptedException {int i = 0;for (; ; ) {i++;x = 0;y = 0;a = 0;b = 0;Thread t1 = new Thread(()->{shortWait(10000);a = 1;x = b;});Thread t2 = new Thread(()->{b = 1;y = a;});t1.start();t2.start();t1.join();t2.join();String result = "第" + i + "次 (" + x + "," + y + ")";if (x == 0 && y == 0) {System.out.println(result);break;} else {log.info(result);}}}/*** 等待一段时间,时间单位纳秒** @param interval*/public static void shortWait(long interval) {long start = System.nanoTime();long end;do {end = System.nanoTime();} while (start + interval >= end);}}
第一种结果:先排除指令重排,当这段代码以我们视觉效果的从上往下执行,结果就是x=0,y=1(因为t1线程已经执行完了,t2线程才来执行)
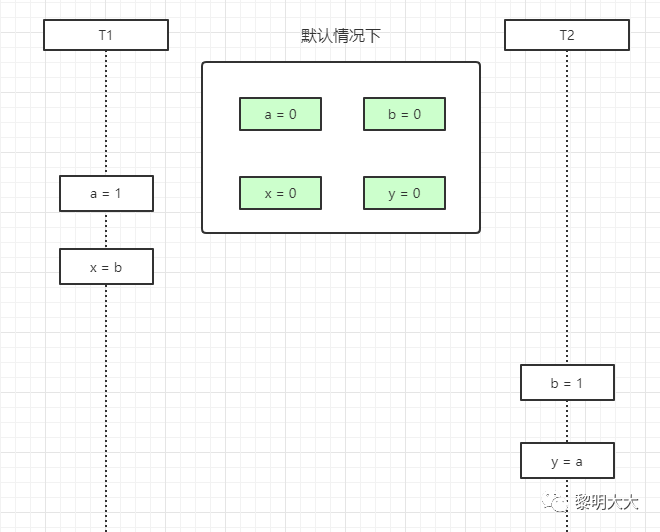

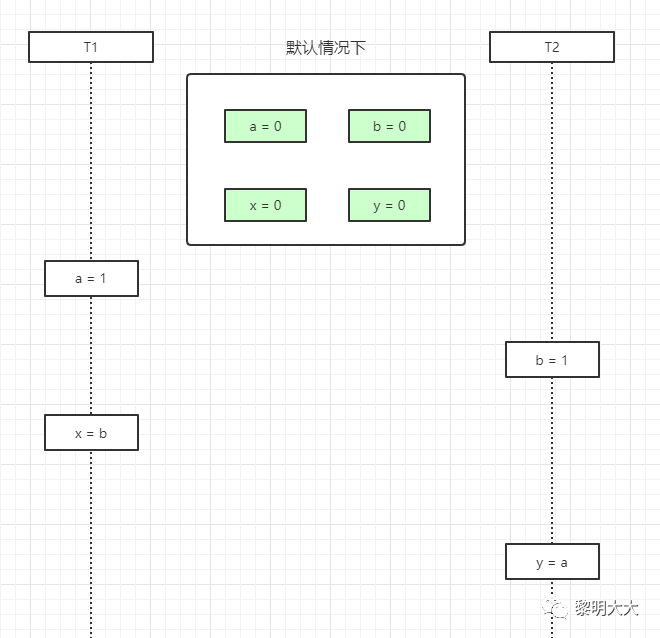
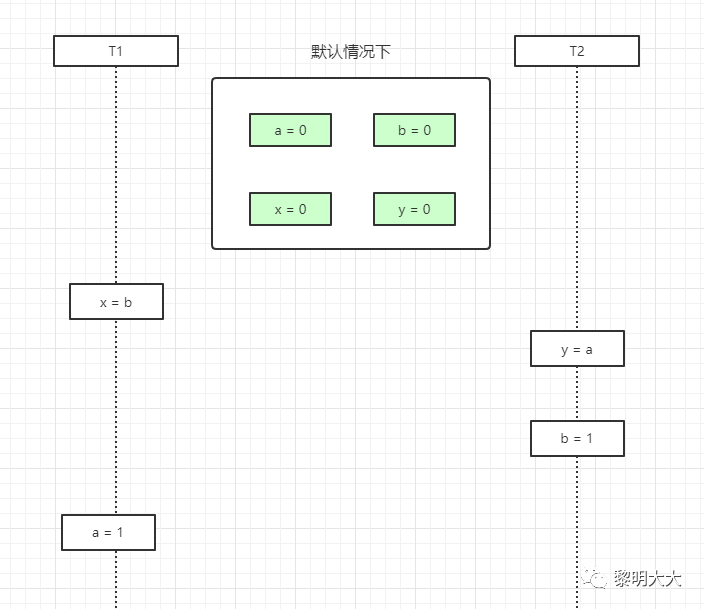
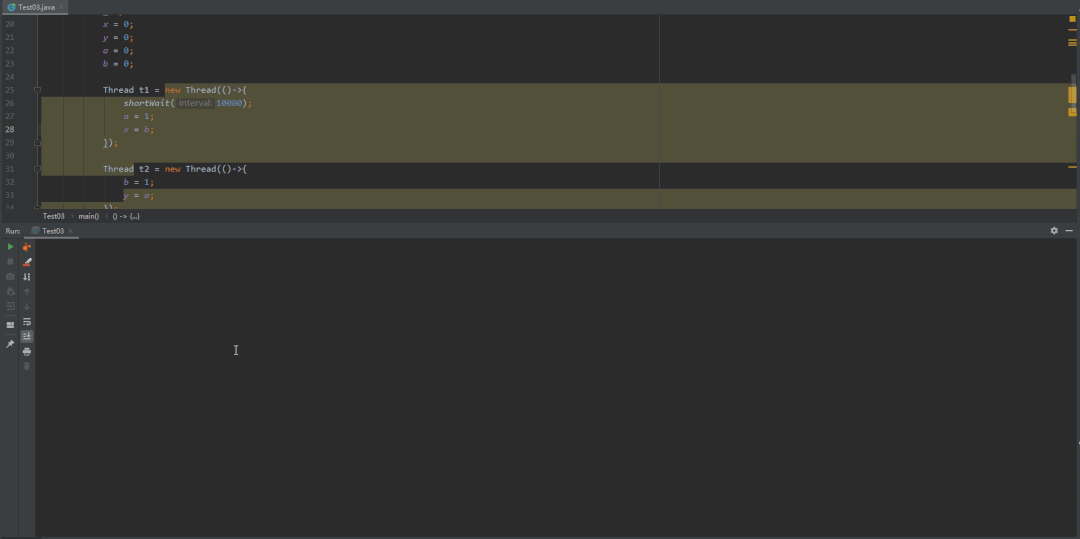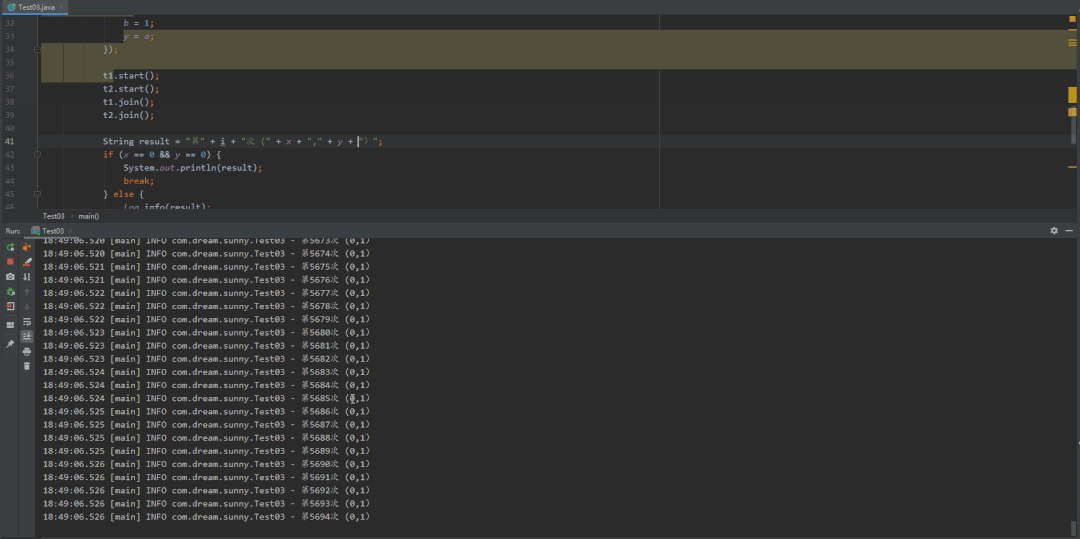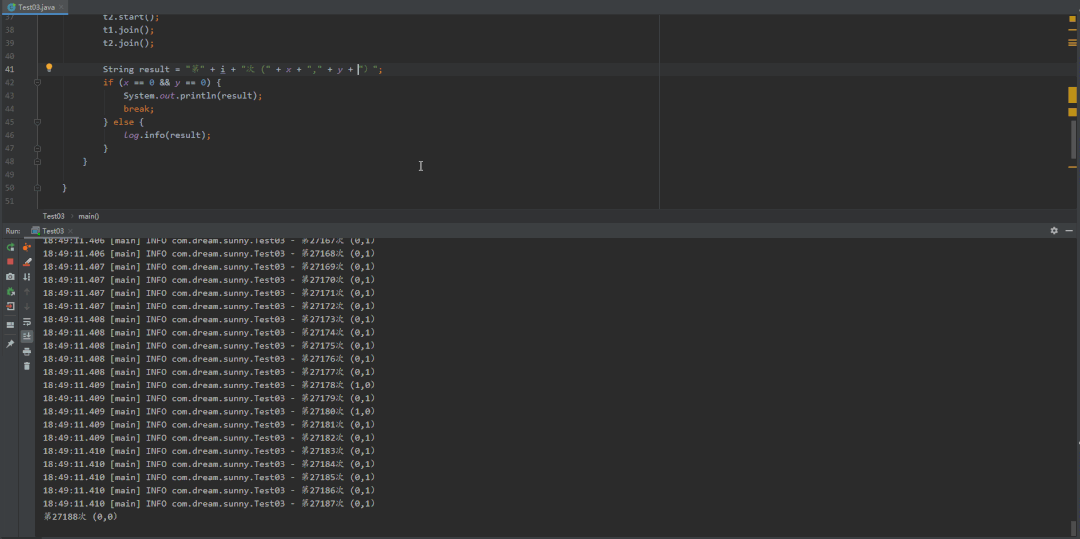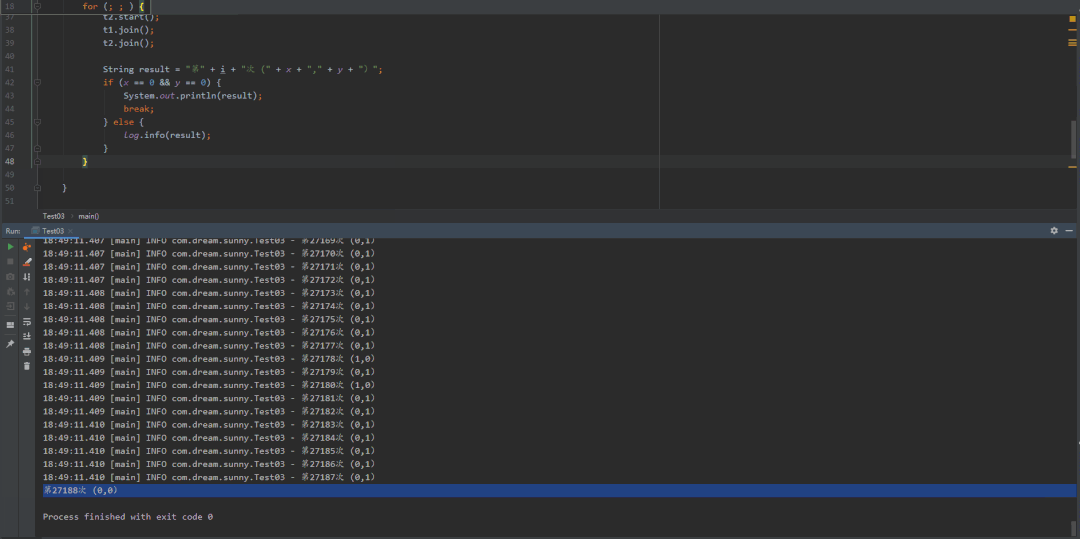
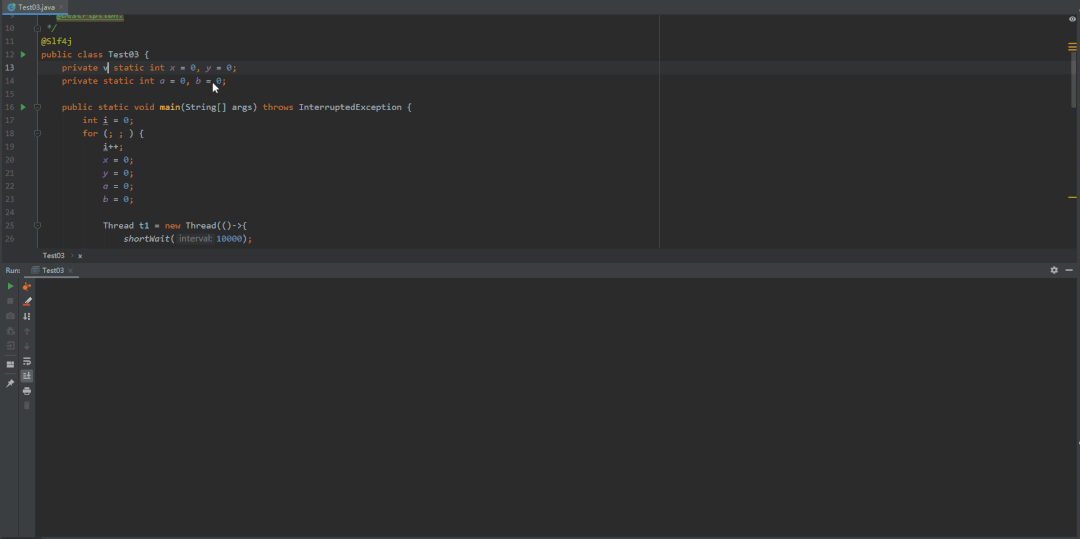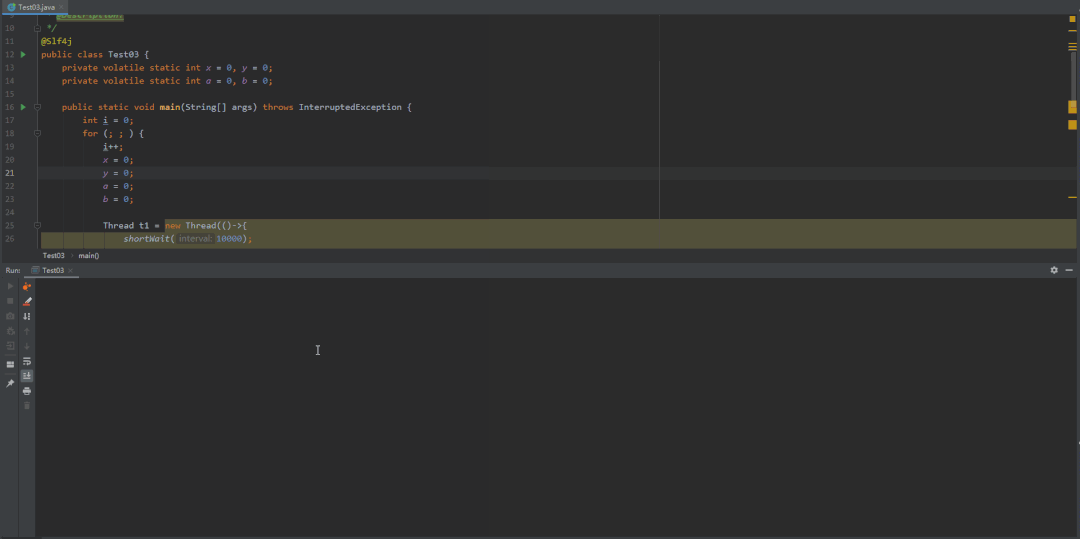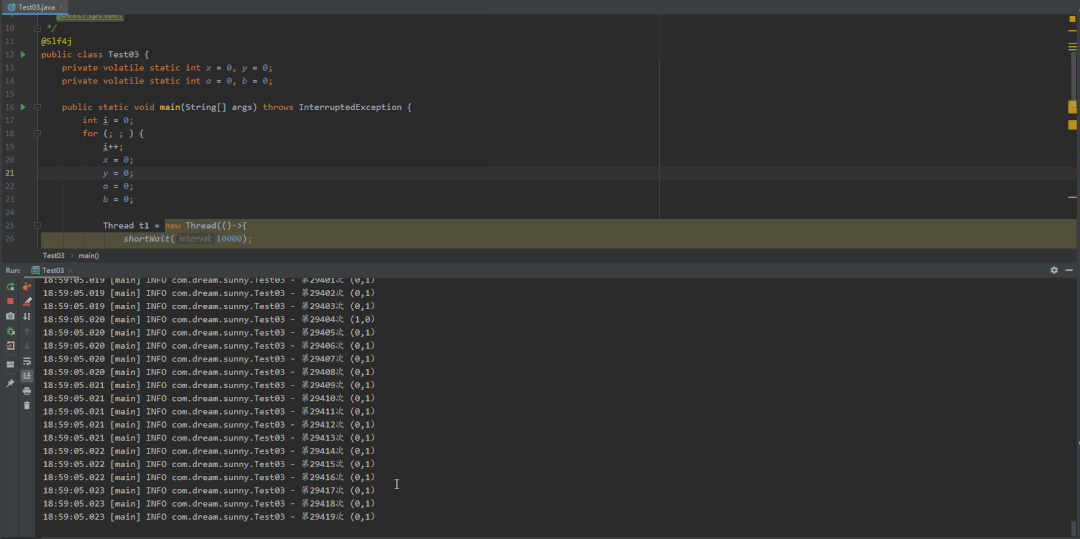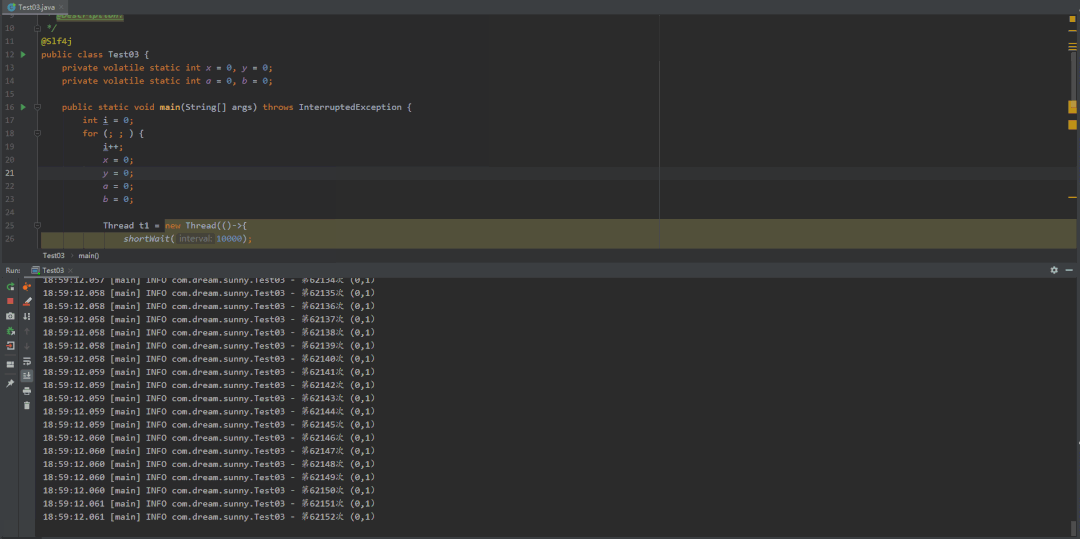
volatile禁止重排优化
内存屏障其实简单理解的话,假如代码中有两行代码,这两行代码在底层可能会发生指令重排,那么我不想让他发生重排怎么办呢?内存屏障的作用就体现出来啦,我们可以将内存屏障插在两行代码中间,告诉编译器或者CPU等,不让它进行重排,当然内存屏障是关于硬件层面的一些知识了,其实JVM也帮我们基于硬件层面的内存屏障封装好了软件层面的内存屏障,先来看看硬件层的内存屏障有哪些?
硬件层的内存屏障
看到这,针对上面的几个表格看的是不是还有点懵圈,没关系,我接下来会对上面的表格的内容做一个简单总结,以及通过代码演示。相信大家伙应该会收获很多。
public class ReadAndWrithe {int a = 1;int c = 0;private static volatile int d = 5;/*** 第一个操作普通读写 第二个操作普通读写 可以重排*/public void test1() {//第一个操作:普通读写//读取的a变量是成员变量但是没有被volatile所修饰,所以为普通读操作//定义的b变量是局部变量,所以为普通写操作int b = a + 1;//第二个操作:普通读写//读取的a变量和b变量都没有被volatile所修饰,所以为普通读操作//定义的c变量是成员变量没有被volatile所修饰,所以为普通写操作c = 2;//该结论则是可以重排}/*** 第一个操作普通读写 第二个操作volatile读 可以重排*/public void test2() {//第一个操作:普通读写//读取的a变量是成员变量但是没有被volatile所修饰,所以为普通读操作//定义的b变量是局部变量,所以为普通写操作int b = a + 1;//第二个操作:volatile读(准确来说:volatile读,普通写)//读取的d变量是成员变量且是被volatile所修饰,所以为volatile读操作//定义的c变量是成员变量没有被volatile所修饰,所以为普通写操作c = d;//该结论则是可以重排}/*** 第一个操作普通读 第二个操作volatile写 不可以重排*/public void test3() {//第一个操作:普通读写//读取的a变量是成员变量但是没有被volatile所修饰,所以为普通读操作//定义的b变量是局部变量,所以为普通写操作int b = a + 1;//第二个操作:volatile写(准确来说:volatile写,普通读)//读取的c变量是成员变量但是没有被volatile所修饰,所以为普通读操作//赋值d变量是成员变量且是被volatile所修饰,所以为volatile写操作d = c;//该结论则是不可以重排}}
public class ReadAndWrithe {int a = 1;int c = 0;private static volatile int d = 5;/*** 第一个操作为volatile读,第二个操作为普通读写 不允许重排*/public void test1() {//第一个操作:volatile读(准确来说:volatile读,普通写)//读取的d变量是成员变量是被volatile所修饰,所以为volatile读//定义的j变量为成员变量,所以为普通写int j = d;//第二个操作:普通读写a = 5;}/*** 第一个操作为volatile读,第二个操作为volatile读 不允许重排*/public void test2() {//第一个操作:volatile读//读取的d变量是成员变量是被volatile所修饰,所以为volatile读//定义的j变量为成员变量,所以为普通写int j = d;//第二个操作:volatile读//读取的d变量是成员变量是被volatile所修饰,所以为volatile读//定义的f变量为成员变量,所以为普通写int f = d;}/*** 第一个操作为volatile读,第二个操作为volatile写 不允许重排*/public void test3() {//第一个操作:volatile读//读取的d变量是成员变量是被volatile所修饰,所以为volatile读//定义的j变量为成员变量,所以为普通写int j = d;//第二个操作:volatile写//读取的a变量是成员变量但不是被volatile所修饰,普通读//赋值的d变量为volatile所修饰,所以为volatile写d = a;}}
public class ReadAndWrithe {int a = 1;int c = 0;private static volatile int d = 5;private static volatile int d2 = 2;/*** 第一个操作为volatile写,第二个操作为普通读写 可以重排*/public void test1() {//第一个操作:volatile写(准确来说:volatile写,普通读)//3:普通读//赋值的d是volatile所修饰的,所以为volatile写d = 3;//第二个操作:普通读写a = 5;}/*** 第一个操作为volatile写,第二个操作为volatile读 不允许重排*/public void test2() {//第一个操作:volatile写//3:普通读//赋值的d是volatile所修饰的,所以为volatile写d = 3;//第二个操作:volatile读//读取的d变量是成员变量是被volatile所修饰,所以为volatile读//定义的f变量为成员变量,所以为普通写int f = d;}/*** 第一个操作为volatile写,第二个操作为volatile写 不允许重排*/public void test3() {//第一个操作:volatile写//3:普通读//赋值的d是volatile所修饰的,所以为volatile写d = 3;//第二个操作:volatile写//读取的a变量是成员变量但不是被volatile所修饰,普通读//赋值的d2变量为volatile所修饰,所以为volatile写d2 = a;}}
当然jvm虚拟机也不会随意将我们的代码进行指令重排,还需要遵守以下规则
happens-before 原则
1.程序顺序原则,即在一个线程内必须保证语义串行性,也就是说按照代码顺序执行。
2.锁规则 解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)。
3.volatile规则 volatile变量的写,先发生于读,这保证了volatile变量的可见性,简单的理解就是,volatile变量在每次被线程访问时,都强迫从主内存中读该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时刻,不同的线程总是能够看到该变量的最新值。
4.线程启动规则 线程的start()方法先于它的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见
5.传递性 A先于B ,B先于C 那么A必然先于C
6.线程终止规则 线程的所有操作先于线程的终结,Thread.join()方法的作用是等待当前执行的线程终止。假设在线程B终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见。
7.线程中断规则 对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否中断。
8.对象终结规则对象的构造函数执行,结束先于finalize()方法
我是黎明大大,我知道我没有惊世的才华,也没有超于凡人的能力,但毕竟我还有一个不屈服,敢于选择向命运冲锋的灵魂,和一个就是伤痕累累也要义无反顾走下去的心。
如果您觉得本文对您有帮助,还请关注点赞一波,后期将不间断更新更多技术文章

