
聊聊最近的技术之路
大家好,我是Leo。
2月22号又是被群友催更的一天,今天28号了。已经 11-12天没更了。今晚决定熬夜更一篇。顺便聊一下我最近忙的事情。
最近做了啥
Andon项目 重构电商微服务系统 重构电商底层的数据结构 手撸微服务从0-1,不过最后因为很多地方写不好,暂时放弃了 白天的话肯定是工作嘛,我是认真工作的小青年 理财
Andon的话让我重温了一下C#。
电商微服务的话只能给你们看这个图了,直接吃我98的内存,我开发的时候申请IO都搞不了
重构底层数据结构的话主要就是数据字段性能优化技巧了,这篇文章下面也是主要介绍的这个。
手撸微服务的话就看这张图吧
工作的话,不方便发,我怕再碰点什么商业机密,说不清,之前英诺激光就那么恶心人。
理财的话上图吧

聊正事吧
这篇主要聊一下我在做优化数据结构的一些想法。
优化的第一点
也是最要命的就是数据字段的设计问题,我这里主要考虑四点
冷热分离 应用中主从表可以出现重复字段为了减少回表 常用字段全部加上索引,以及考虑联合索引,索引失效,最左匹配原则,索引下推问题 MySQL的缓存机制问题。
从这四点出发。冷热分离的话我们举一个商品表的例子,我把修改量比较大的单独放一张表,改动量不大的给他放在了主表,同时考虑到查询一个商品的时候往往会带上 名称+分类 我给他加了联合索引,这样就可以减少回表了。
冷热分离的话还涉及到另外一点就是MySQL的缓存机制,当一个表没出现修改的时候,下一次查询,不会产生磁盘IO的开销了,MySQL会直接读缓存中的数值然后返给客户端。
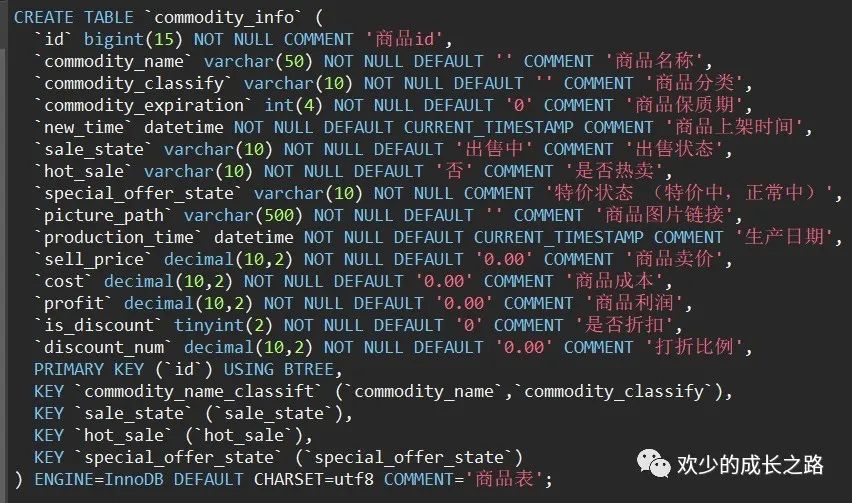
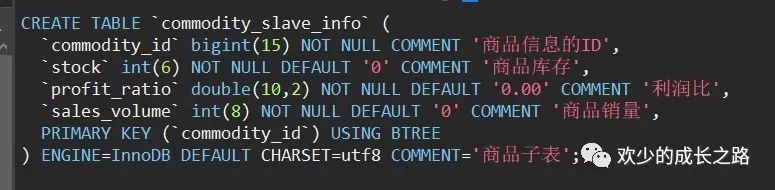
索引失效的话,主要考虑的是数据类型不一致导致失效,常见的就是下面四种。一定要留意你们的状态是int类型还是varchar类型。
出售状态 热卖状态 特价状态 订单号
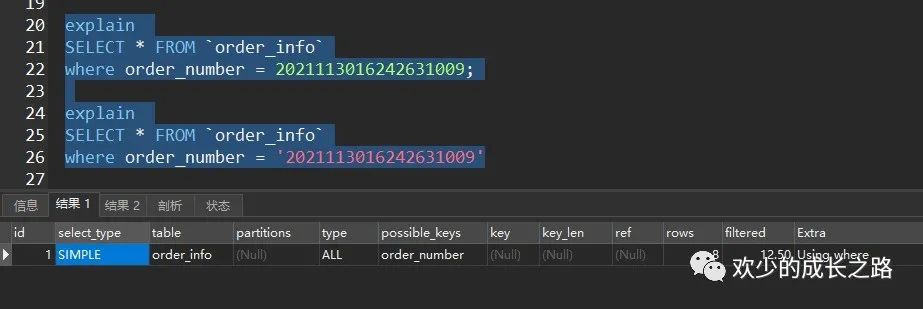
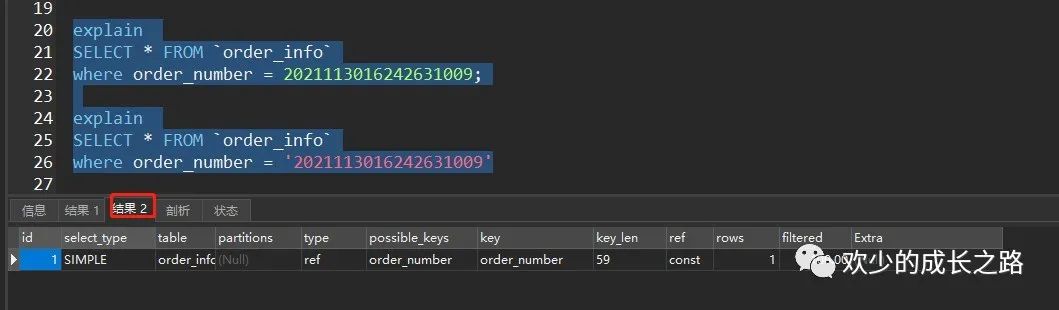
这里如果还想优化细一些的话,可以考虑把固定的字段改成char类型,不需要使用varchar。
顺着在聊一下char和varchar的区别
char是固定的类型,varchar是可变的类型, 插入char字段时,多余当前字段的大小的自动舍去,varchar相反,他会可以变动 char查找效率会很高,varchar查找效率会更低 char和varchar类型的字段在计算索引长度时,char会+1,varchar会+2
其实就是空间换时间的一个说法,到底是性能最重要还是存储空间最重要了。
优化第二点
主要考虑一些主从表的问题
如果是一对一,可以采用 inner join 如果是一对多,可以采用 left join
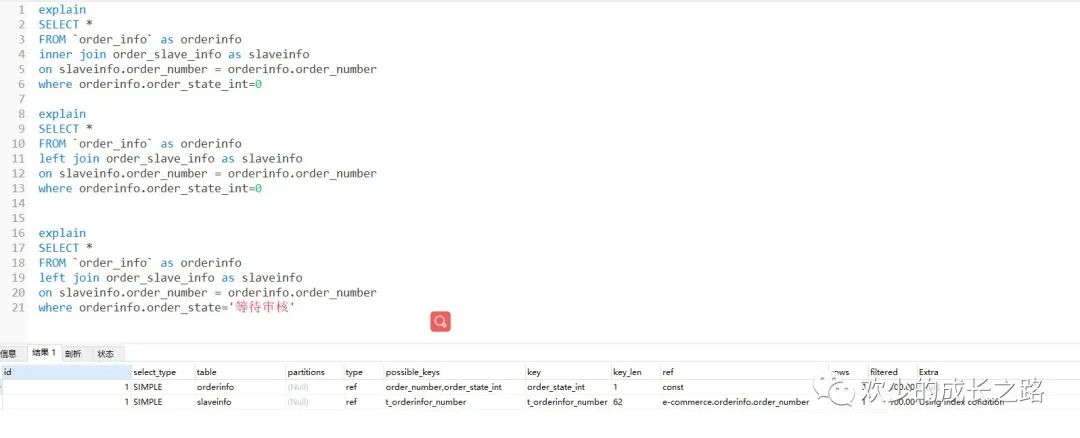
一对一的话 这个地方我今天踩了一个坑,我一直以为多表操作left join搞定,偶尔间发现了不一样的操作不一样的说法,下面我们介绍一下
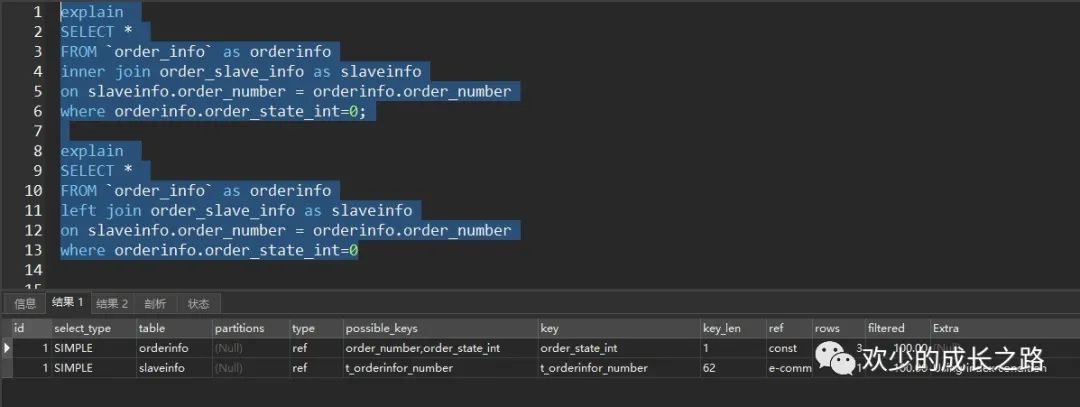
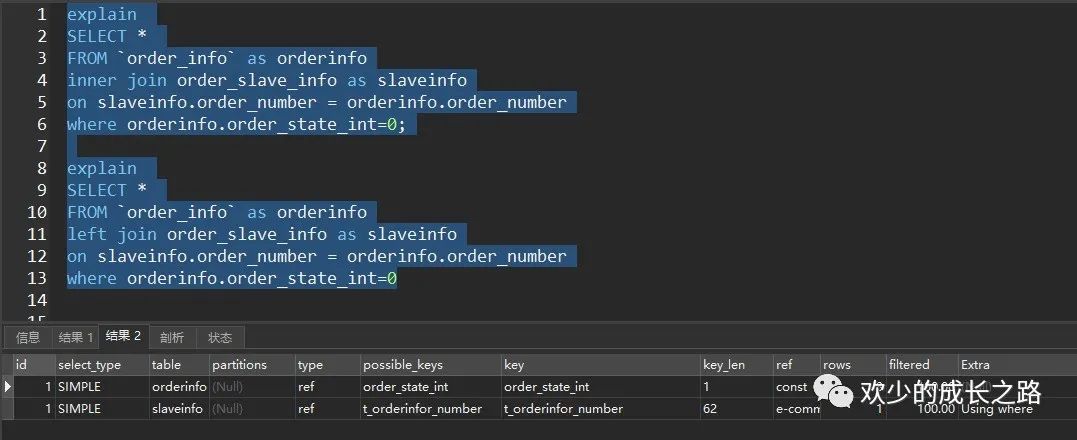
很清晰的看出一样的语句,不同的关联方式查出来不同的结果。这里不同点主要有两块 possible_keys 和 Extra。possible_keys没啥好说的,主要说一下 Extra 。
Using where:表示优化器需要通过索引回表查询数据 Using index:表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表 Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
我对 Using index condition 的理解是:首先 mysql 服务端(server) 和 存储引擎(storage engine) 是两个组件, server 负责 sql的parse执行; storage engine 去真正的 做 数据/index的 读取/写入. 以前是这样: server 命令 storage engine 按 index 把相应的 数据 从 数据表读出, 传给server, server来按 where条件 做选择; 现在 ICP则是在 可能的情况下, 让storage engine 根据index 做判断, 如果不符合 条件 则无须 读 数据表. 这样 节省了disk IO.。
这里阐述一下这两种SQL,因为关联查询输出那里我都用了全部列,为了读者方便观察。我们可以清晰的看到结果1 的性能查询优于 结果2 。所以一对一查询时可以优先考虑 inner join
一对多的话 肯定还是优先考虑 left join的,但是我用的比较多的是主从表查询完之后,列表需要做一次order by create_time 排序


很清晰的发现做了一次order by之后,索引就失效了,这里出现了上文的 Using index condition 的原因是我们公司的前辈给 create_time 也加了索引。如果不加索引的话就会失效,加了索引的话部分生效。具体怎么解决后面会继续聊的,这里先透露一下 可以根据 key_len 解决。key_len又是有该字段的类型长度和null值决定的。
name3 varchar(20) NOT NULL DEFAULT
name1 char(20) DEFAULT NULL,
上面是2个字段的定义,1个允许NULL,一个NOT NULL,一个char,一个varchar
所以key_len=(20*3 + 1)+(20 * 3 + 2)= 123相信有人会问了,+1是干嘛,+2是干嘛。这就告诉大家,+1是因为MySQL需要1个字节标识NULL,+2是因为name3字段为varchar,是变长字段需要+2。
非常欢迎大家加我个人微信有关后端方面的问题我们在群内一起讨论! 我们下期再见!
长按上方扫码二维码,加我微信,拉你进群
