
彻底搞懂 select/poll/epoll,就这篇了!
之前已经把网络 I/O 相关要点都盘了,还剩 select/poll/epoll 这几个区别没说,这篇就来搞搞它们,并且是从完全理解原理的角度来区分它们。
本来是要上源码的,但是感觉没啥必要,身为应用开发我觉得理解原理就行了,源码反正看了就忘了,理解才是最重要!所以我就尽量避免代码且用大白话来盘一盘这三个玩意。
话不多说,发车。
小思考
首先,我们知道 select/poll/epoll 是用来实现多路复用的,即一个线程利用它们即可 hold 住多个 socket。
按照这个思路,线程不可被任何一个被管理的 Socket 阻塞,且任一个 Socket 来数据之后都得告知 select/poll/epoll 线程。
想想看,这应该如何实现呢?
我们拿 select 的逻辑来分析下
按照我们的理解,select 管理多个 Socket 的模型如下图所示:

这里要注意一下内核态和用户态的交互,用户程序访问不了内核空间。
所以,我们调用 select 会把所有要管理的 socket 的 fd (文件描述符,Linux下皆为文件,简单理解就是通过 fd 能找到这个 socket)传到内核中。
此时,要遍历所有 socket,看看是否有感兴趣的事件发生。如果没有一个 socket 有事件发生,那么 select 的线程就需要让出 cpu 阻塞等待,这个等待可以是不设置超时时间的死等,也可以是设置 timeout 的有超时时间的等待。
假设此时客户端发送了数据,网卡接收到的数据塞到对应的 socket 的接收队列中,此时 socket 知道来数据了,那如何唤醒 select 呢?
其实每个 socket 有个属于自己的睡眠队列,select 会安排一个内应,即在被管理的 socket 的睡眠队列里面塞入一个 entry。

当 socket 接收到网卡的数据后,就会去它的睡眠队列里遍历 entry,调用 entry 设置的 callback 方法,这个 callback 方法里就能唤醒 select !
所以 select 在每个被它管理的 socket 的睡眠队列里都塞入一个与它相关的 entry,这样不论哪个 socket 来数据了,它立马就能被唤醒然后干活!
但是,select 的实现不太好,因为唤醒的 select 此时只知道来活了,并不知道具体是哪个 socket 来数据了,所以只能傻傻地遍历所有 socket ,看看到底是哪个 scoket 来活了,然后把所有来活的 socket 封装成事件返回。
这样用户程序就能获得发生的事件,然后进行 I/O 和业务处理了。
这就是 select 的实现逻辑,理解起来应该不难。
这里再提一嘴 select 的限制,因为被管理的 socket fd 需要从用户空间拷贝到内核空间,为了控制拷贝的大小而做了限制,即每个 select 能拷贝的 fds 集合大小只有1024。
然后要改的话只能修改宏..再重新编译内核。网上很多文章都是这样说的,但是(没错有个但是)。
我看了一篇文章,确实有这个宏,值也是 1024,但内核根本没有限制 fds 集合的大小。然后托人问了个内核大佬,大佬说内核确实没做限制,glibc那层做了。
所以..重新编译内核?那篇文章放文末。
poll
poll 这玩意相比于 select 主要就是优化了 fds 的结构,不再是 bit 数组了,而是一个叫 pollfd 的玩意,反正就是不用管啥 1024 的限制了。
不过现在也没人用 poll,我就不多说了。
epoll
这个就是重点了。
相信看了 select 的实现,我们稍微思考下,就能想出几个可以优化的点。
比如,为什么每次 select 需要把监控的 fds 传输到内核里?不能在内核里维护个?
为什么 socket 只唤醒 select,不能告诉它是哪个 socket 来数据了?
epoll 主要就是基于上面两点做了优化。
首先,搞了个叫 epoll_ctl 的方法,这方法就是用来管理维护 epoll 所监控的哪些 socket。
如果你的 epoll 要新加一个 socket 来管理,那就调用 epoll_ctl,要删除一个 socket 也调用 epoll_ctl,通过不同的入参来控制增删改。

这样,在内核里面就维护了此 epoll 管理的 socket 集合,这样就不用每次调用的时候都得把所有管理的 fds 拷贝到内核了。
对了,这个 socket 集合是用红黑树实现的。
然后和 select 类似,每个 socket 的睡眠队列里都会加个 entry,当每个 socket 来数据之后,同样也会调用 entry 对应的 callback。
与 select 不同的是,引入了一个 ready_list 双向链表,callback 里面会把当前的 socket 加入到 ready_list 然后唤醒 epoll。
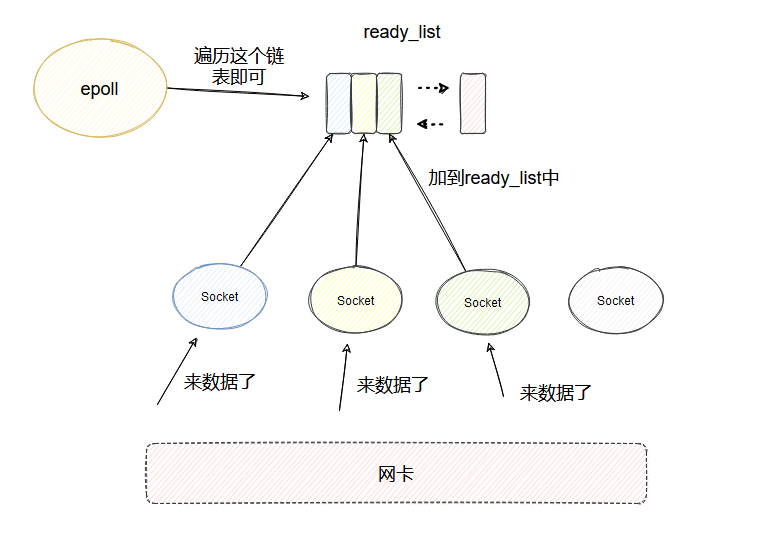
这样被唤醒的 epoll 只需要遍历 ready_list 即可,这个链表里一定是有数据可读的 socket,相比于 select 就不会做无用的遍历了。
同时收集到的可读的 fd 按理是要拷贝到用户空间的,这里又做了个优化,利用了 mmp,让用户空间和内核空间映射到同一块内存中,这样就避免了拷贝。
完美啊~
这就是 epoll 基于 select 所作的优化,还有一些差别没细说,比如 epoll 是阻塞睡眠在一个 single_epoll_wait_list 而不是 socket 的睡眠队列等等,我就不提了,理解上面的这些已经够了。
ET<
都谈到 epoll 了,避免不了要扯扯 ET 和 LT 两个模式。
ET,边沿触发。
按照上面的逻辑就是 epoll 遍历 ready_list 的时候,会把 socket 从 ready_list 里面移除,然后读取这个 scoket 的事件。
而 LT,水平触发,有点不一样。
在这个模式下 epoll 遍历 ready_list 的时候,会把 socket 从 ready_list 里面移除,然后读取这个 scoket 的事件,如果这个 socket 返回了感兴趣的事件,那么当前这个 socket 会再被加入到 ready_list 中,这样下次调用 epoll_wait 的时候,还能拿到这个 socket。
这就是这两者最本质的区别了。
看到这有人会问,这两种模式的使用会造成哪种不一样的结果?
如果此时一个客户端同时发来了 5 个数据包,按正常的逻辑,只需要唤醒一次 epoll ,把当前 socket 加一次到 ready_list 就行了,不需要加 5 次。然后用户程序可以把 socket 接收队列的所有数据包都读完。
但假设用户程序就读了一个包,然后处理报错了,后面不读了,那后面的 4 个包咋办?
如果是 ET 模式,就读不了了,因为没有把 socket 加入到 ready_list 的触发条件了。除非这个客户端发了新的数据包过来,这样才会再把当前 socket 加入到 ready_list,在新包过来之前,这 4 个数据包都不会被读到。
而 LT 模式不一样,因为每次读完有感兴趣的事件发生之后,会把当前 socket 再加入到 ready_list,所以下次肯定能读到这个 socket,所以后面的 4 个数据包会被访问到,不论客户端是否发送新包。
至此,我想你应该理解什么是 ET ,什么是 LT 了,而不用对着一些什么状态变更触发这些不易理解的名词而发晕。
最后
好了,今天的分析到此完毕,我个人觉得对 select/poll/epoll 的理解到这个程度就差不多了,当然还有很多细节,需要自行去看源码探究,问我我也不懂,这些都是阅读网上的源码分析文章得出的结论。
我也不建议读的那么深,毕竟人的精力有限对吧,有涉及到相关底层优化的时候,再去研究也不迟。
参考:
https://blog.csdn.net/dog250/article/details/105896693(select真的受1024限制吗?) https://blog.csdn.net/dog250/article/details/50528373