
实战 | Python模型分析B站优质up主
作者 | 远辰
来源 | 数据不吹牛
不管前浪还是后浪,能够浪起来的才算是好浪。
相信大家最近都被号称“浪里白条”的b站刷了不止一次屏。这次咱们先不谈价值观,主要从数据的角度,扒一扒让b站能够在浪里穿梭的资本——优质UP主。
本文在RFM模型基础上做了调整,尝试用更符合b站特性的IFL模型,找到各分区优质up主。整个过程以分析项目的形式展开,最终附上了完整源数据和代码,方便感兴趣的同学练手。

项目概览
分析目的
对2019年1月~2020年3月发布的视频进行分析,挑选出视频质量高,值得关注的up主。
数据来源
分析数据基于 bilibili 网站上的公开信息,主要爬取了以下数据维度:
2019年1月~2020年3月,科技区播放量过5w视频的分区名称、作者名称、作者id、发布时间、播放数、硬币数、弹幕数、收藏数、点赞数、分享数、评论数,共计50130行。
源数据下载链接
完整数据源和代码链接:https://pan.baidu.com/s/1RIxOxh-TFMey9sGvZLVuJg 提取码:bhh2

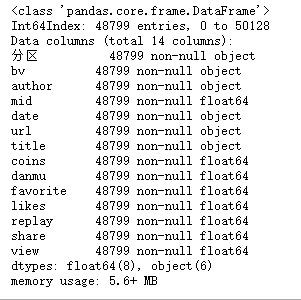
数据概览
视频信息表:
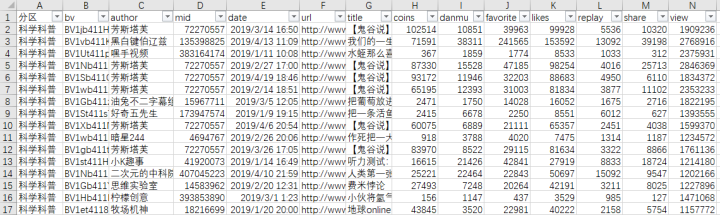
coins:投硬币数
danmu:弹幕数
favorite:收藏数
likes:点赞数
replay:评论数
share:分享数
view:播放量
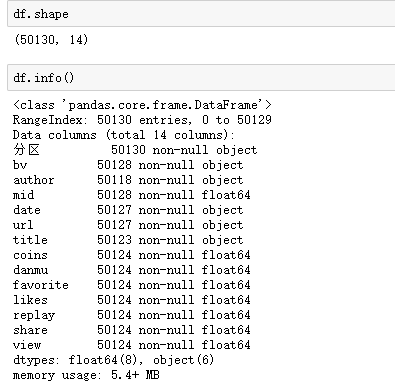
各字段数量:
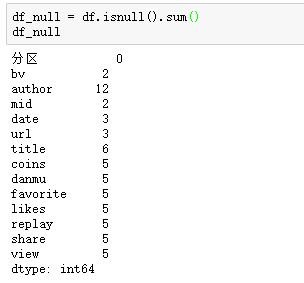
缺失值数量:

数据清洗
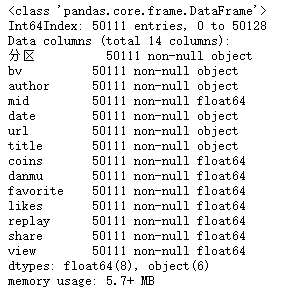
删除空值
df = df.dropna()
df.info()共删除了19行数据,剩余50111行数据
df = df.drop_duplicates()
df.info()删除了1312行重复的数据,剩余数据量48799行
提取所需关键词
df = df[['分区', 'author','date','coins','danmu','favorite','likes','replay','share','view']]
df.head()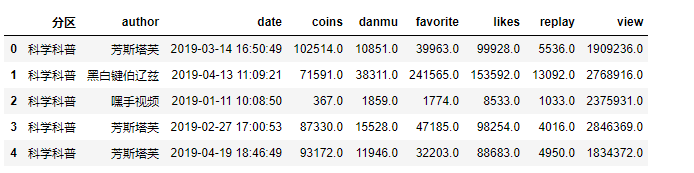

构建模型
RFM模型是衡量客户价值和创利能力的重要工具和手段。通过一个客户近期购买行为、购买的总体频率以及消费金额三项指标来描述客户的价值状况。
R:最近一次消费时间(最近一次消费到参考时间的间隔)
F:消费的频率(消费了多少次)
M:消费的金额 (总消费金额)
但RFM模型并不能评价视频的质量,所以在这里针对up主的视频信息构建了IFL模型,以评估视频的质量。
I(Interaction_rate):
I值反映的是平均每个视频的互动率,互动率越高,表明其视频更能产生用户的共鸣,使其有话题感。

F值表示的是每个视频的平均发布周期,每个视频之间的发布周期越短,说明内容生产者创作视频的时间也就越短,创作时间太长,不是忠实粉丝的用户可能将其遗忘。

L(Like_rate):
L值表示的是统计时间内发布视频的平均点赞率,越大表示视频质量越稳定,用户对up主的认可度也就越高。

提取需要的信息
根据不同的分区进行IFL打分,这里以科普区为例
sc = df.loc[df['分区']=='科学科普']
so = df.loc[df['分区']=='社科人文']
ma = df.loc[df['分区']=='机械']
tec = df.loc[df['分区']=='野生技术协会']
mi = df.loc[df['分区']=='星海'] # 一般发布军事内容
car = df.loc[df['分区']=='汽车']
sc.info()
关键词构造
F值:首先,先筛选出发布视频大于5的up主,视频播放量在5W以上的视频数少于5,说明可能是有些视频标题取得好播放量才高,而不是视频质量稳定的up主。
# 计算发布视频的次数
count = sc.groupby('author')['date'].count().reset_index()
count.columns =['author','times']
# 剔除掉发布视频少于5的up主
com_m = count[count['times']>5]
#com_m = pd.merge(count,I,on='author',how='inner')
com_m.info()

筛选完只剩下208个up主的视频数在5个以上:
last = sc.groupby('author')['date'].max()
late = sc.groupby('author')['date'].min()
# 最晚发布日期与最早之间的天数/发布次数,保留整数,用date重新命名列F =round((last-late).dt.days/sc.groupby('author')['date'].count()).reset_index()
F.columns =['author', 'F']
F = pd.merge(com_m, F,on='author', how='inner')
F.describe()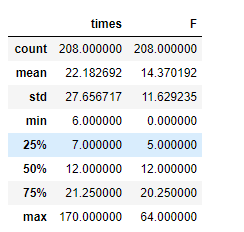
通过describe()方法发现,最晚发布日期与最早发布日期为0的现象,猜测是在同一天内发布了大量的视频。
# 查找的一天内发布视频数大于5的人F.loc[F['F'].idxmin()]
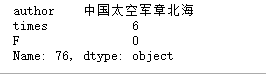
其视频皆为转载,将其剔除统计范围内。
F = F.loc[F['F']>0]
F.describe()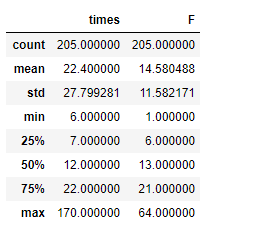
I值
# 构建I值danmu = sc.groupby('author')['danmu'].sum()
replay = sc.groupby('author')['replay'].sum()
view = sc.groupby('author')['view'].sum()
count = sc.groupby('author')['date'].count()
I =round((danmu+replay)/view/count*100,2).reset_index() #
I.columns=['author','I']
F_I = pd.merge(F,I,on='author',how='inner')
F_I.head()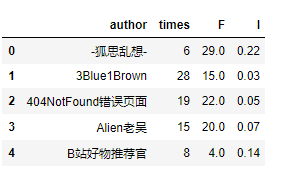
L值
# 计算出点赞率计算出所有视频的点赞率sc['L'] =(sc['likes']+sc['coins']*2+sc['favorite']*3)/sc['view']*100
sc.head()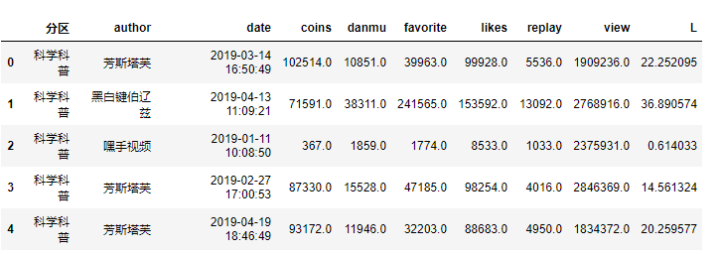
# 构建L值L =(sc.groupby('author')['L'].sum()/sc.groupby('author')['date'].count()).reset_index()
L.columns =['author', 'L']
IFL = pd.merge(F_I, L, on='author',how='inner')
IFL = IFL[['author', 'I','F','L']]
IFL.head()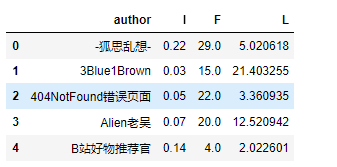
维度打分
维度确认的核心是分值确定,按照设定的标准,我们给每个消费者的I/F/L值打分,分值的大小取决于我们的偏好,即我们越喜欢的行为,打的分数就越高:
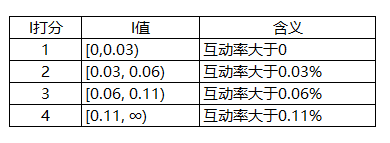
I值,I代表了up主视频的平均评论率,这个值越大,就说明其视频越能使用户有话题,当I值越大时,分值越大。
F值表示视频的平均发布周期,我们当然想要经常看到,所以这个值越大时,分值越小。
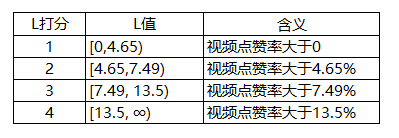
L值表示发布视频的平均点赞率,S值越大时,质量越稳定,分值也就越大。I/S值根据四分位数打分,F值根据更新周期打分。
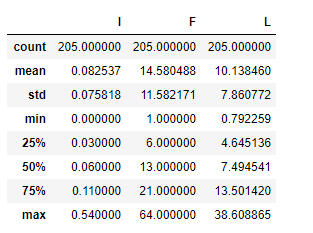
IFL.describe()
I值打分:
L值打分:
F值根据发布周期打分:
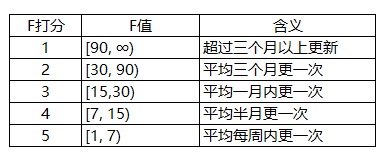
分值计算
# bins参数代表我们按照什么区间进行分组# labels和bins切分的数组前后呼应,给每个分组打标签# right表示了右侧区间是开还是闭,即包不包括右边的数值,如果设置成False,就代表[0,30)IFL['I_SCORE'] = pd.cut(IFL['I'], bins=[0,0.03,0.06,0.11,1000],
labels=[1,2,3,4], right=False).astype(float)
IFL['F_SCORE'] = pd.cut(IFL['F'], bins=[0,7,15,30,90,1000],
labels=[5,4,3,2,1], right=False).astype(float)
IFL['L_SCORE'] = pd.cut(IFL['L'], bins=[0,5.39,9.07,15.58,1000],
labels=[1,2,3,4], right=False).astype(float)
IFL.head()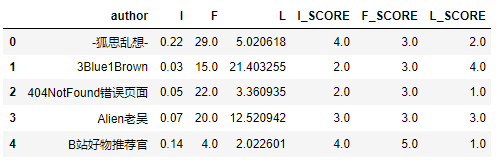
判断用户的分值是否大于平均值:
# 1为大于均值 0为小于均值IFL['I是否大于平均值'] =(IFL['I_SCORE'] > IFL['I_SCORE'].mean()) *1
IFL['F是否大于平均值'] =(IFL['F_SCORE'] > IFL['F_SCORE'].mean()) *1
IFL['L是否大于平均值'] =(IFL['L_SCORE'] > IFL['L_SCORE'].mean()) *1
IFL.head()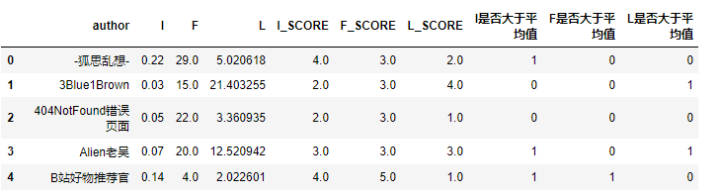
客户分层
RFM经典的分层会按照R/F/M每一项指标是否高于平均值,把用户划分为8类,我们根据根据案例中的情况进行划分,具体像下面表格这样:
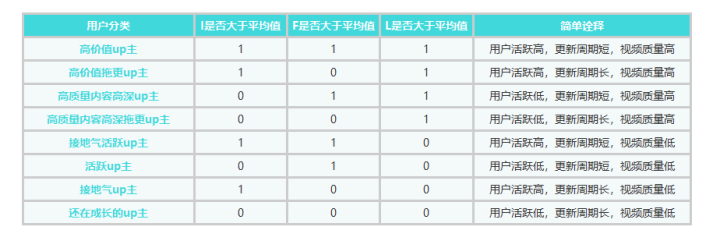
引入人群数值的辅助列,把之前判断的I\F\S是否大于均值的三个值串联起来:
IFL['人群数值'] =(IFL['I是否大于平均值'] *100) +(IFL['F是否大于平均值'] *10) +(IFL['L是否大于平均值'] *1)
IFL.head()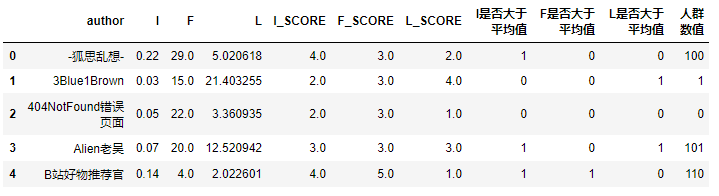
构建判断函数,通过判断人群数值的值,来返回对应标签:

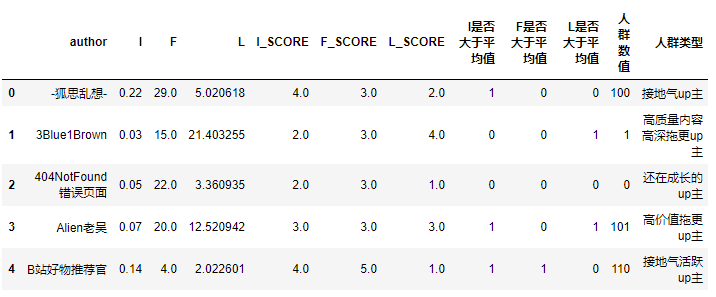
将标签分类函数应用到人群数值列:
IFL['人群类型'] = IFL['人群数值'].apply(transform_label)
IFL.head()
各类用户占比
cat = IFL['人群类型'].value_counts().reset_index()
cat['人数占比'] = cat['人群类型'] / cat['人群类型'].sum()
cat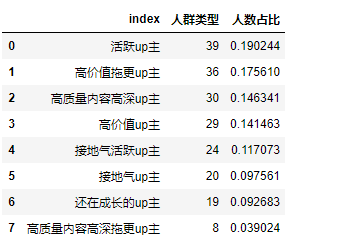
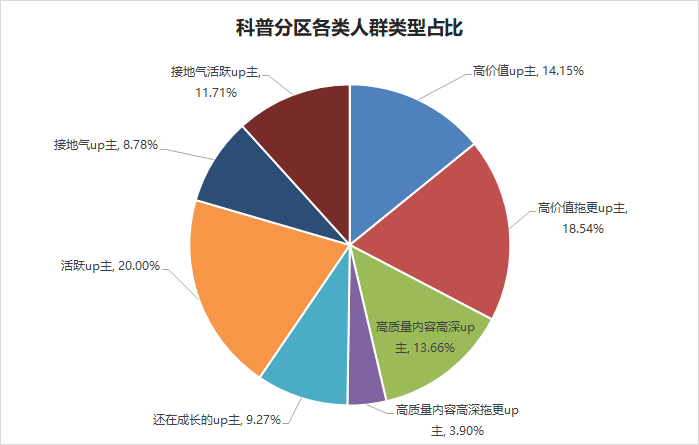

各分区up主排行top15
科学科普分区
high = IFL.loc[IFL['人群类型']=='高价值up主']
rank = high[['author','L','I','F']].sort_values('L',ascending=False)
rank.to_excel('rank.xlsx', sheet_name='科学科普',encoding='utf-8')
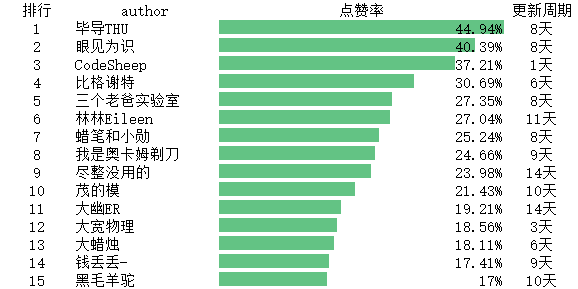
社科人文分区
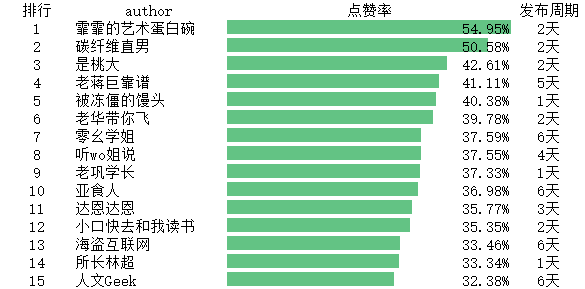
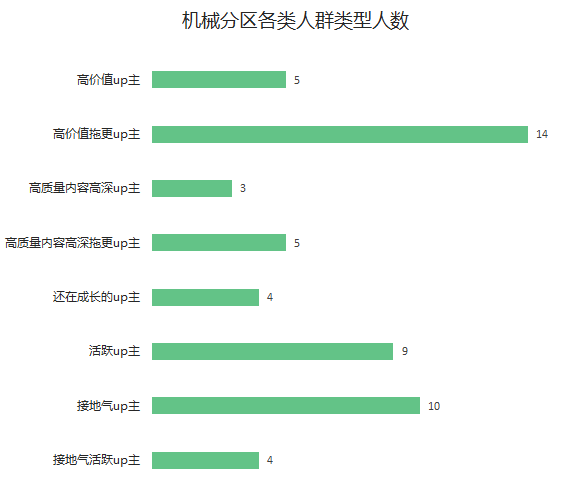
机械分区

机械分区高价值up主只有5位,因为机械分区在科技区是个小分区,发布视频的up主仅有54位。
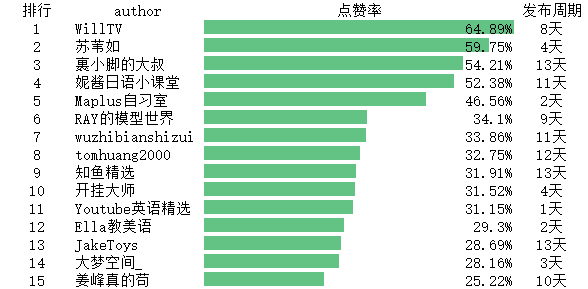
野生技术协会分区
星海
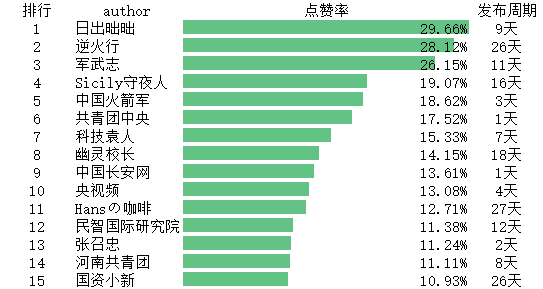
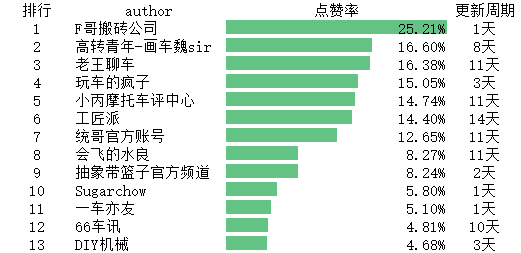
汽车
参考文章:
1.数据不吹牛:《不到70行Python代码,轻松玩转RFM用户分析模型》
2.Crossin:《B站用户行为分析非官方报告》
3.https://github.com/Vespa314/bilibili-api/blob/master/api.md
今天为大家提供了一种数据分析的模型,用于发掘优质up主,大家完全可以参照这种方式去发掘其他事物。
完整数据源和代码链接:https://pan.baidu.com/s/1RIxOxh-TFMey9sGvZLVuJg 提取码:bhh2
End