
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
一、说话人驱动(talking head)
1、Audio-Driven Emotional Video Portraits
尽管此前一些方法在基于音频驱动的说话人脸生成方面已取得不错的进展,但大多数研究都集中在语音内容与嘴形之间的相关性上。人脸的情感表现是很重要的特征,但此前的方法总忽视这一点。
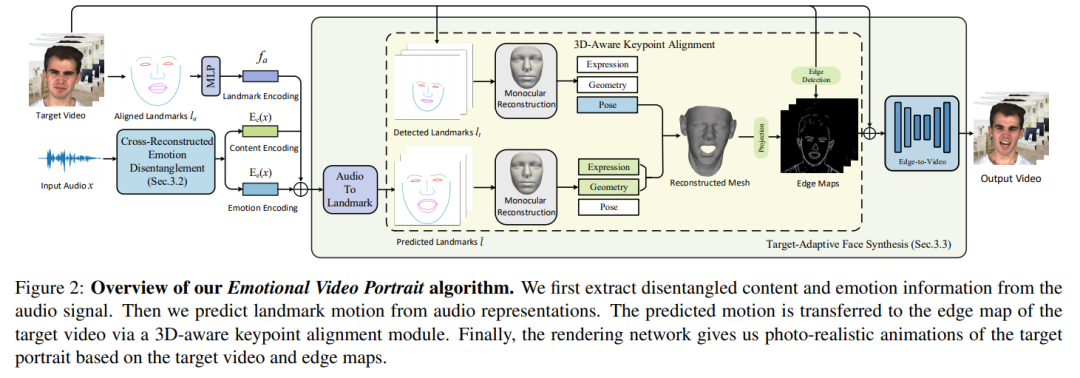
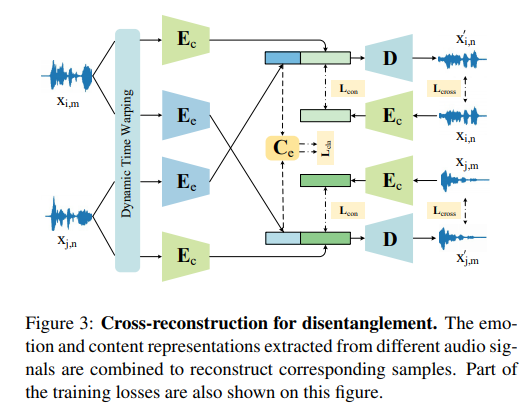
这项工作提出“表情视频肖像” (Emotional Video Portraits,EVP),一种由音频驱动、具有动态情感的肖像视频合成系统。具体来说,提出交叉重构式的表情解耦技术,将语音分解为两个解耦空间,即与时长无关的情感空间和与时长相关的内容空间。解开的特征可推断出动态2D表情人脸。
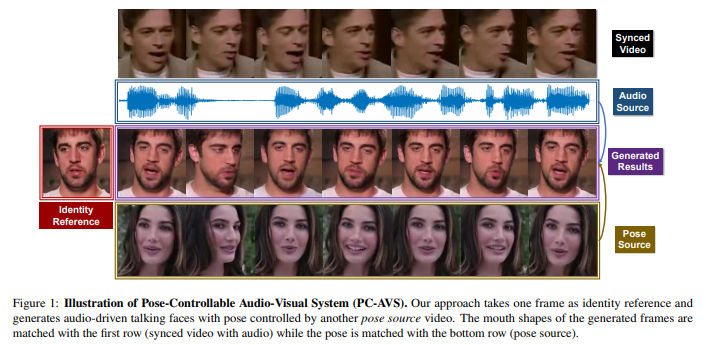
2、Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
针对任意人的、以其音频驱动的说话人脸生成研究方向,已实现了较准确的唇形同步,但头部姿势的对齐问题依旧不理想。
此前的方法依赖于预先估计的结构信息,例如关键点和3D参数。但极端条件下这种估计信息不准确则效果不佳。本文主要针对的是,如何生成姿势可控的说话人脸。
3、One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
提出一种说话人脸的视频合成模型,并展示在视频会议中的应用。
使用包含目标人物的源图像,以及驱动视频来合成源人物说话视频。运动信息基于一种关键点表示进行编码,其中特定于身份和运动相关的信息被无监督地解耦。

二、3D人脸相关
4、Inverting Generative Adversarial Renderer for Face Reconstruction
给定单目人脸图像作为输入,3D 人脸几何重建旨在恢复相应的 3D 人脸网格mesh。这项工作引入一种生成对抗渲染器 (GAR),以面部法线贴图和潜码作为输入,渲染出逼真的人脸图像。

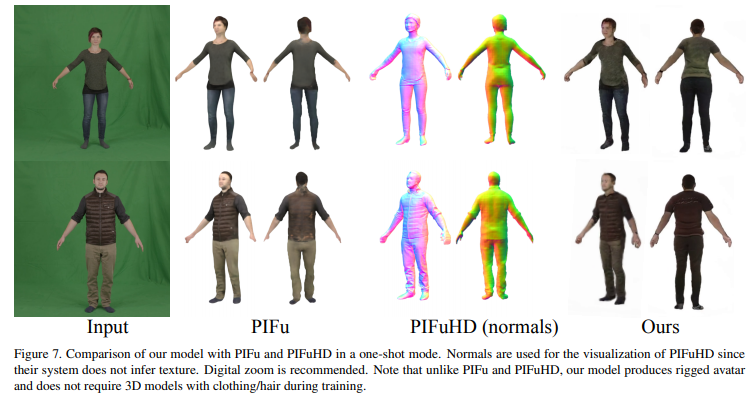
5、Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
引入一个基于 GAN 的框架,将照片中人脸数字化成标准3D形象。
输入图像可以是一个微笑的人,也可以是在极端光照条件下拍摄的,作者声称所提方法均可生成高质量的人脸纹理模型。

6、pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
提出π-GAN/pi-GAN,用于高质量的 3D 感知的图像合成。

7、StylePeople: A Generative Model of Fullbody Human Avatars
提出一种全身人体数字化的“化身”形象(full-body human avatars)方法。
saic-violet.github.io/style-people
三、人体运动合成
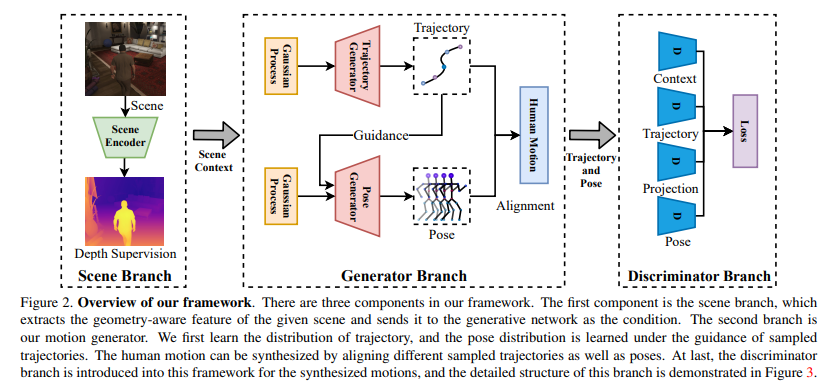
8、Scene-aware Generative Network for Human Motion Synthesis
关注的是人体运动合成,此前方法往往有两方面局限:1)专注于姿势,却忽视了位置运动方面的因素,2)忽略了环境对人体运动的影响。
本文考虑场景和人体运动之间的相互作用,目标是生成以场景和人体初始位置为条件的合理人体运动。基于GAN,使用判别器来保证人体运动与上下文场景、3D 到 2D 投影约束的兼容性。
上述论文可在 计算机视觉GAN 知识星球 打包下载
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论