
lambda表达式知识点补充

前言
截止到昨天,我们已经分享完了spring cloud的核心模块的相关知识点,下一步的想法是继续深挖spring相关的知识点,或者开始分享dubbo的知识点,或者分享Netty的相关知识点。
单从目前我对以上知识的掌握来看,分享前两种知识点的可能性比较大,但是后一种我觉得还有很有难度的,因为我对netty的积累还不够,所以暂时可能不会分享。目前我比较倾向于dubbo相关知识点的分享,主要有两个原因,一个是对于dubbo我的知识盲区点比较多,系统地学习一下dubbo刚好可以查漏补缺;另一个就是最近一直在分享spring相关知识点,有点上头,所以暂时换个频道。
好了,关于未来几天的内容分享计划,我们暂时就先说这么多,下面插播一期lambda相关的知识点。
lambda表达式
关于lambda表达式,我们之前也有分享过几期内容,但由于这一块的知识比较零散,而且内容比较多,很难一次分享完,所以今天我们在原来分享的基础上,再来做一些补充,下面我们直接开始吧。
parallelStream
可能很多小伙伴只知道stream,并不知道parallelStream,其实,我以前也只知道steam,后来有一次和一个同事讨论一个技术问题,他推荐我使用parallelStream。当然,当时只管着用,就没有仔细研究过,知道最近遇到了一个问题,我才真正去查了一些资料,了解了parallelStream的相关知识点。
parallelStream中文含义并发流、平行流,和stream相比,它效率更高,内部采用了 fork/join机制,即把一个大任务拆分(fork)成多个子任务,子任务之间还会继续拆分,然后以多线程的方式去运行,最后运行结束后,将子任务结果进行整合(join),生成最后的运行结果,整体运行流程大致如下:
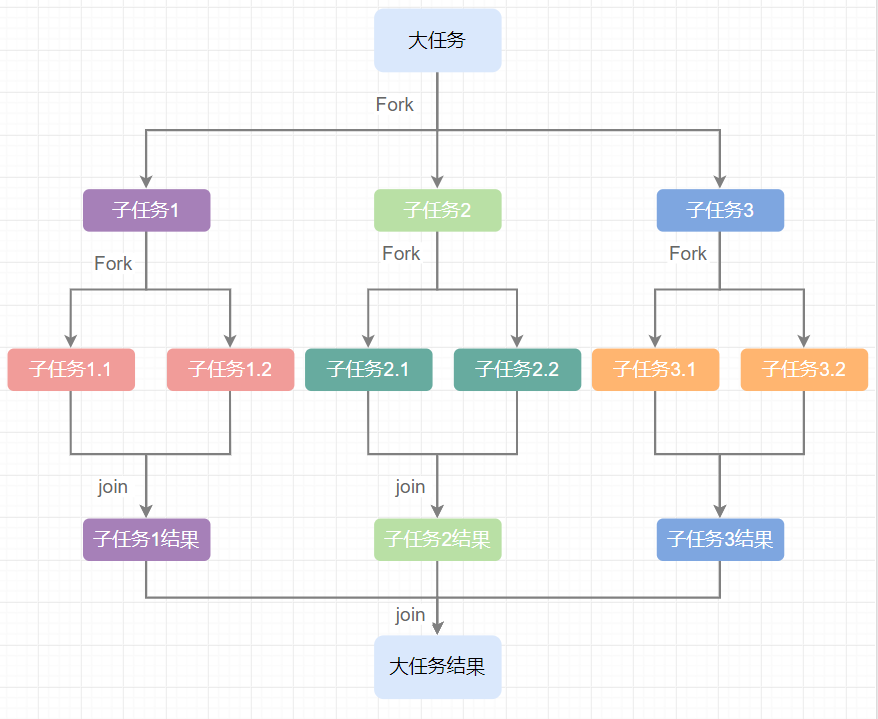
下面是一段示例代码,在代码中我们先初始化了一个长度为10000的List,然后分别通过普通的stream和 parallelStream分别遍历integers,然后把其中的值转换成string类型,放入一个新的集合中,这里用了map(String::valueOf),最后分别打印他们的运行时间,比较他们的性能
private static void parallelStreamTest2() {
List<Integer> integers = Lists.newArrayList();
Random random = new Random(100);
for (int i = 0; i < 10000; i++) {
integers.add(random.nextInt(100));
}
long start = System.currentTimeMillis();
List<String> collect1 = integers.parallelStream().map(String::valueOf).collect(Collectors.toList());
System.out.println("collect1 用时:" + (System.currentTimeMillis() - start));
long start2 = System.currentTimeMillis();
List<String> collect2 = integers.stream().map(String::valueOf).collect(Collectors.toList());
System.out.println("collect2 用时:" + (System.currentTimeMillis() - start2));
System.out.println("collect1: " + collect1);
System.out.println("collect2: " + collect2);
}
运行结果如下:

根据本次示例运行结果,我们可以发现parallelStream比普通的stream快了32倍,这数据就足以说明parallelStream比stream性能要好,当然具体的数据还是取决于你的电脑性能。
但是需要注意的是,由于parallelStream是多个子任务同时运行的,所以它本身是线程不安全的,而stream是串行运行所以线程是安全的。下面我们通过一段代码来说明parallelStream的线程安全问题:
private static void parallelStreamTest() {
List<Integer> integers = Lists.newArrayList();
Random random = new Random(100);
for (int i = 0; i < 10000; i++) {
integers.add(random.nextInt(100));
}
AtomicInteger index = new AtomicInteger(0);
List<Integer> integersList = Lists.newArrayList();
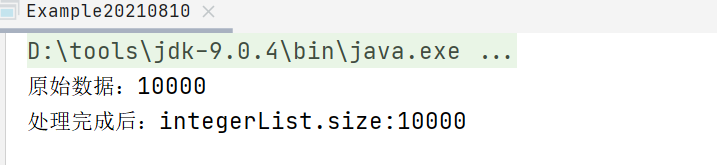
System.out.println("原始数据:" + integers.size());
integers.stream().forEach(i -> {
// integers.parallelStream().forEach(i -> {
index.incrementAndGet();
integersList.add(i);
});
System.out.println("处理完成后:integerList.size:" + integersList.size());
}
同样的代码,如果用stream(),返回结果就是正常的:
但如果用parallelStream,这结果就有点离谱了,数据一半都被弄丢了:

如果parallelStream内部如果多加一行打印,结果会稍微好一点,但是也是有问题的:
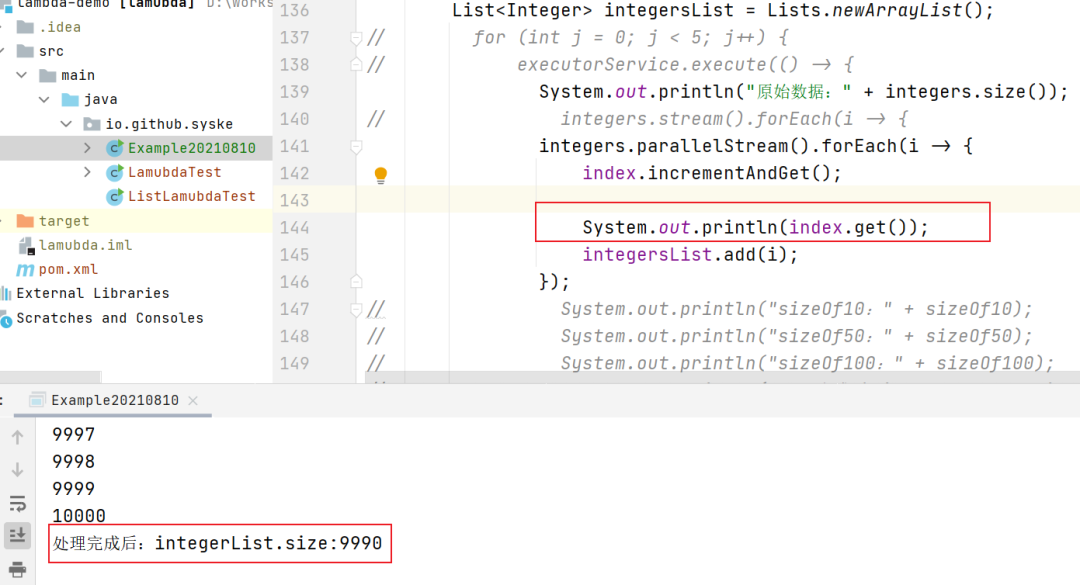
导致线程不安全问题的原因是因为我们parallelStream内部用到了integersList这个共享变量,如果你的parallelStream内部没有写相关的操作,那应该是不存在线程安全问题的,总之,慎用parallelStream。
另外还有一点需要注意,那就是parallelStream无法确保运行结果的有序性,虽然在本次运行结果中,它和stream的运行结果是一致的,但是在某些情况下,它的结果是无序的,如果你对顺序有要求,那可能需要你自己重新排序。
groupBy
groupBy也算是一个比较常用的lambda表达式了,我们经常用它来对List分组,然后生成一个Map,map的key是我们分组的字段,value就是我们分组后的List,下面我们先通过一个实例简单演示下:
List<TestVo> testVoList = Lists.newArrayList();
testVoList.add(new TestVo(1L, 1, 111L, 10L, "test1"));
testVoList.add(new TestVo(2L, 2, 111L, 20L, "test2"));
testVoList.add(new TestVo(3L, 3, 111L, 30L, "test3"));
testVoList.add(new TestVo(4L, 1, 112L, 10L, "test4"));
testVoList.add(new TestVo(5L, 2, 112L, 20L, "test5"));
testVoList.add(new TestVo(6L, 3, 112L, 30L, "test6"));
testVoList.add(new TestVo(7L, 1, 113L, 10L, "test7"));
testVoList.add(new TestVo(8L, 2, 113L, 20L, "test8"));
testVoList.add(new TestVo(9L, 3, 113L, 30L, "test9"));
testVoList.add(new TestVo(10L, 4, 113L, 40L, "test10"));
System.out.println("初始化后:testVoList = " + testVoList);
Map<Long, List<TestVo>> typeIdTestVoMap = testVoList.stream().collect(Collectors.groupingBy(TestVo::getTypeId));
System.out.println("typeIdTestVoMap = " + typeIdTestVoMap);
public static class TestVo {
Long id;
Integer sort;
Long projectNum;
Long typeId;
String name;
}
在上面的代码中,我们先初始化了一个testVoList,然后先通过groupingBy对TypeId分组,最终结果如下:
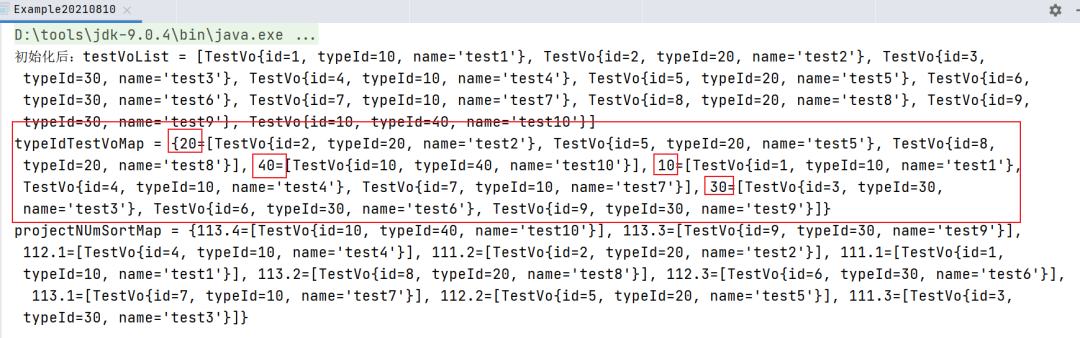
可以看到,最后生成的map就是以TypeId为key进行分组的。
下面的代码是多字段分组的写法:
Map<String, List<TestVo>> projectNUmSortMap = testVoList.stream().collect(Collectors.groupingBy(t -> String.format("%s.%s", t.getProjectNum(), t.getSort())));
System.out.println("projectNUmSortMap = " + projectNUmSortMap);
运行结果如下:

根据运行结果可以看出,我们的map已经按ProjectNum.Sort的形式为我们分组了,我觉得这种方式最常用,特别是在复杂业务中,数据关系比较复杂的话,用这种方式可以很方便地构建出我们需要的数据格式。
总结
lambda表达式用起来确实很方便,也确实很爽,使用它不仅可以让我们的代码更简洁,而且还提升我们系统性能,当然,它也有一些弊端,比如不便于问题排查(解决方式也很简单,增加一些必要的日志),但是我觉得只要你用好了lambda表达式,那它只会让你受益无穷。好了,今天内容就到这里吧,又是忙碌的一天 ,大家晚安!
,大家晚安!