
Presto 原理 | 一文理解 Presto 两种 JOIN 算法实现
JOIN 的实现
几乎所有的数据库引擎一次只 JOIN 两个表。即使在 SQL 查询中有两个以上的表要联接,数据库也会联接前两个表并将输出与第三个表联接起来,然后对其余表继续这样做。数据库工程师将连接操作中涉及的这两个表称为构建表(Build Table)和探测表(Probe Table)。
Build Table
构建表是用于创建内存索引的表。通常,在读取探测表之前必须完整读取构建表。
Probe Table
一旦构建表被读取并存储在内存中,探测表就会被逐行读取。从探测表读取的每一行都将根据 join criteria 与构建表进行连接。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Presto 使用优化后的逻辑计划中的右表作为构建表,将逻辑计划中的左表作为探测表。请注意,逻辑计划中的表不必与它们在 SQL 查询中的顺序相同。Presto 有一些基于成本的优化器,它们可以重新排序连接以将最小的表(即构建表)保留在右侧,以便它可以放入内存中。如果连接重新排序优化器被禁用或连接器特定的统计信息(例如 Hive 统计信息)被禁用,则 Presto 将不会对连接查询重新排序。在这种情况下,建议将最小的表保留在连接的右侧,以便 Presto 可以将其用作构建表。
JOIN 算法
数据库根据数据类型和连接类型使用不同的算法来连接两个表。例如,SQL Server 使用 Nested Loop 算法、Merge Join 算法、Hash Join 算法和 Adaptive Join 算法。在撰写本文时,开源的 Presto SQL 引擎采用 Nested Loop 算法和 Hash Join 算法来支持 Presto 中所有不同联接类型。本节简要说明Nested Loop 算法和 Hash Join 算法,并讨论其他算法在 Presto 中的适用性以提高性能。
Nested Loop Algorithm
顾名思义,嵌套循环算法使用嵌套循环连接两个表。下面使用一个数组连接示例来解释嵌套循环连接算法。假设你有两个整数数组,并要求你打印这些数组的笛卡尔积,你会如何解决这个问题?下面给出了一种简单的方法来打印两个数组的笛卡尔积。
public class IteblogNestedLoop {public static void main(String[] args) {// Construct two arraysint[] tableA = {1, 2, 3, 4, 5, 6};int[] tableB = {10, 20, 30, 40};// Nested loop to print the Cartesian product of two arraysfor (int x : tableA) {for (int y : tableB) {System.out.println(x + ", " + y);}}}}
上面的代码使用两个循环来打印两个数组的笛卡尔积。嵌套循环算法的时间复杂度为 O(n²),因为它必须将探测表中的每一行与构建表中的每一行连接起来。由于需要每个组合,交叉连接操作的执行时间复杂度不能超过 O(n²)。Presto 使用嵌套循环算法来执行 cross join 操作,这就是为什么如果连接表非常大,cross join 需要很长时间。由于 O(n²) 时间复杂度,不建议在没有连接条件的情况下连接两个大表。
Hash Join Algorithm
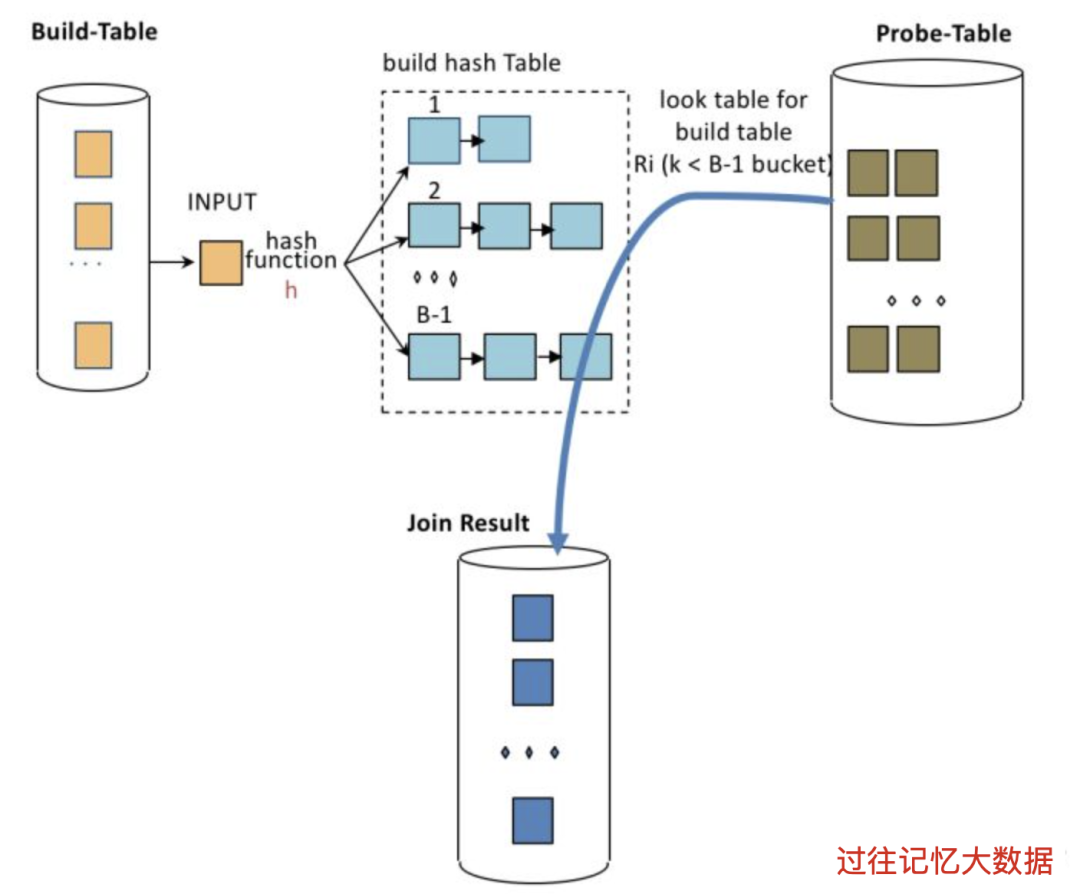
哈希连接算法为构建表中的列生成哈希键,这些列是用于 JOIN 条件中的,比如 left.x = right.y AND left.z = right.w。每个这样的相等条件称为连接相等条件(join equi criteria)。尽管 equi criteria 术语在数据库领域被广泛使用,但它们也被称为相等条件。为了使用哈希算法,让我们考虑一个打印所有客户及其订单信息的问题。这个问题中使用的 Customer 和 Order 类定义如下。请注意,这两个类都有一个共同的属性:custKey。
class Order {String orderKey;String custKey;double totalPrice;public Order(String orderKey, String custKey, double totalPrice) {this.orderKey = orderKey;this.custKey = custKey;this.totalPrice = totalPrice;}@Overridepublic String toString() {return "Order: " + orderKey + ", " + custKey + ", " + totalPrice;}}class Customer {String custKey;String name;public Customer(String custKey, String name) {this.custKey = custKey;this.name = name;}@Overridepublic String toString() {return "Customer: " + name + ", " + custKey;}}
回到问题:我们如何打印所有客户及其订单?了解嵌套循环算法后,可以简单地在循环内应用带有 if 条件的嵌套循环算法,如下所示:
import java.util.*;public class IteblogHashJoin {public static void main(String[] args) {List<Customer> probe = List.of(new Customer("c_001", "Alice"),new Customer("c_002", "Bob"),new Customer("c_003", "David"));List<Order> build = List.of(new Order("o_01", "c_001", 100.0),new Order("o_01", "c_001", 100.0),new Order("o_02", "c_001", 150.0),new Order("o_03", "c_002", 90.0),new Order("o_04", "c_003", 120.0));// Nested loop joinfor (Customer customer : probe) {for (Order order : build) {if (Objects.equals(customer.custKey, order.custKey)) {System.out.println(customer + " -> " + order);}}}}}
尽管嵌套循环连接可以达到我们的要求,但它的效率很低,因为它在给定 n 个客户和 n 个订单的情况下迭代 n² 次。一个有效的解决方案可以使用一个 Hashtable 来存储所有订单,使用相同的连接条件:custKey 作为哈希键。然后在遍历 Customer 列表时,可以生成 Customer 的散列值。获取具有相同custKey 的订单列表,如下所示:
import java.util.*;public class IteblogHashJoin {public static void main(String[] args) {List<Customer> probe = List.of(new Customer("c_001", "Alice"),new Customer("c_002", "Bob"),new Customer("c_003", "David"));List<Order> build = List.of(new Order("o_01", "c_001", 100.0),new Order("o_01", "c_001", 100.0),new Order("o_02", "c_001", 150.0),new Order("o_03", "c_002", 90.0),new Order("o_04", "c_003", 120.0));// Build the hash map indexMap<Integer, List<Order>> index = new Hashtable<>();for (Order order : build) {int hash = Objects.hash(order.custKey);index.putIfAbsent(hash, new LinkedList<>());index.get(hash).add(order);}// Hash Join algorithmfor (Customer customer : probe) {int hash = Objects.hash(customer.custKey);List<Order> orders = index.get(hash);if (orders != null) {for (Order order : orders) {if (Objects.equals(customer.custKey, order.custKey)) {System.out.println(customer + " -> " + order);}}}}}}
在上述算法中,使用单独的 LinkedList 来避免哈希冲突,因为同一客户下多个订单的可能性很高。使用 equijoin criteria 里面列的哈希值用于将构建表存储在存储桶中。然后将相同的散列算法应用于探测表的 equijoin criteria 列以查找包含匹配项的桶。尽管 Hash Join 算法的最坏情况时间复杂度是 O(n²),但平均情况下预计为 O(n)。
上述问题可以定义为下面给出的 SQL 查询,以将 Customer 表与 Orders 表连接起来。
SELECT *FROM iteblog.customer cLEFT JOIN iteblog.orders oON c.custkey=o.orderkey;
具有等连接条件的所有连接操作都使用Presto中的哈希连接算法执行。然而,连接操作并不局限于等效连接标准。例如,如果列值大于或小于另一列的值,则可以连接两个表,如下查询所示:
所有具有 equijoin criteria 的连接操作都使用 Presto 中的哈希连接算法执行。但是,连接操作不限于 equijoin criteria。例如,如果列值大于或小于另一列的值,则可以连接两个表,如下面的查询:
SELECT o.orderkey, l.linenumberFROM iteblog.orderkey oLEFT JOIN iteblog.lineitem lON o.orderdate < l.shipdate;
Hash Join 算法不适用于具有不等式约束的 join 条件。首先,很难提出一个完美的散列算法来保持输入的不等式属性(即给定 x > b 并不能保证 hash(a) > hash(b))。其次,即使我们提出了一个满足不等式要求的散列函数,我们也不能简单地连接一个桶中的所有值。要加入不相等的行,应该匹配大于/小于给定列的每一行。因此,Presto 使用带 filter 的嵌套循环算法而不是散列连接算法来执行具有非等连接条件的连接。
尽管开源的 Presto SQL 仅使用 Nested Loop 算法和 Hash Join 算法进行连接操作,但 Merge Join 是关系数据库中使用的另一种众所周知的算法,有一些大数据计算引擎也支持 Merge Join ,比如 Spark。以下部分介绍了 Merge Join 算法,并解释了 Presto 社区为何不考虑添加对 Merge Join 算法的支持。
Merge Join
Merge Join 算法来自著名的 Merge-Sort 算法。归并排序算法有两个阶段:排序和合并。假设两个数组已经排序,它们可以以 O(n) 的时间复杂度合并。Presto 可以通过使用 equijoin criteria 中使用的列对构建表和探测表进行排序,然后通过执行合并操作来实现该算法。忽略排序部分,merge join 算法的性能有望优于上述算法,但 Presto 社区发现它需要在内存中对两个表进行排序,这在大数据世界中很耗时,考虑到有限的内存,甚至可能是不可行的。但是,如果有机会在底层数据源中对数据进行排序,则合并连接算法可能是一个更好的候选算法。
在我看来,如果构建表足够小可以容纳在内存中,那么对它进行排序并使用二分搜索算法将探测表行与构建表进行比较不会是一个糟糕的选择。它可以改进具有不等式条件(例如大于或小于)的连接操作。Presto 还支持关系数据库,与大数据存储相比,这些数据库的数据量通常较少。如果连接来自关系数据库的两个表,或者来自关系数据库的表与来自 Hadoop 文件存储的表连接,则有机会要求底层关系数据库返回排序结果。因此,我觉得即使在大数据领域,Merge Join 仍然是一个值得考虑的候选。