
Pandas中的几个不常用的函数功能
Pandas 是我们常用的一个Python数据分析库。其中有不少操作是我们平时很少用到的。如下:
数据源:
df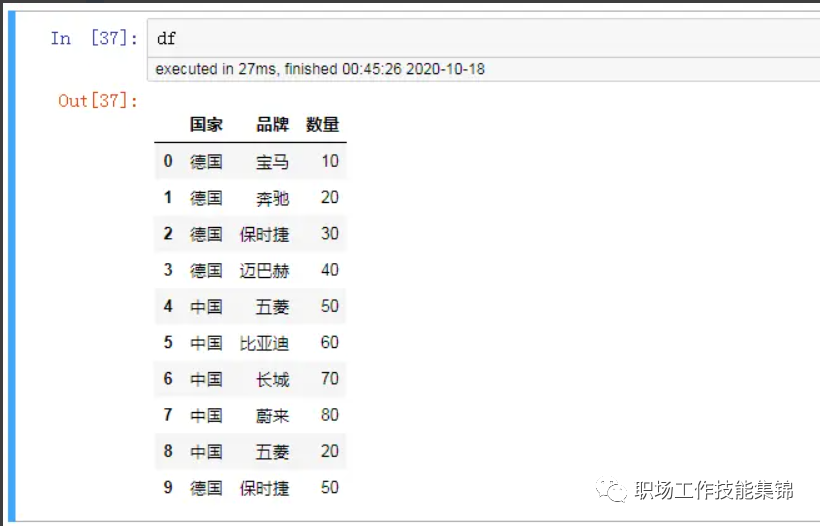
一、 获取最大或最小值所对应对象的名称
获取某列的最小值:
df["数量"].min()
获取最小值所对应的汽车品牌:
df[df["数量"] == df["数量"].min()]["品牌"].values[0]
获取最大值同理。
然而,我们可以使用.idxmax() 或 idxmin() 函数来更优雅得实现以上功能:
df.loc[df["数量"].idxmin()]["品牌"]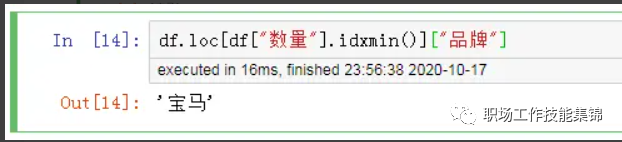
可见,所得结果一致,并且语句显得更加简短优雅。
二、 数据切片
用 .cut() 函数将数据区间 [10,80] 均等地分成10份,等差为 (80 - 10) / 10 = 7.
pd.cut(df["数量"],10)
查看当前数据所属的划分区间:
pd.cut(df["数量"],10,labels = False)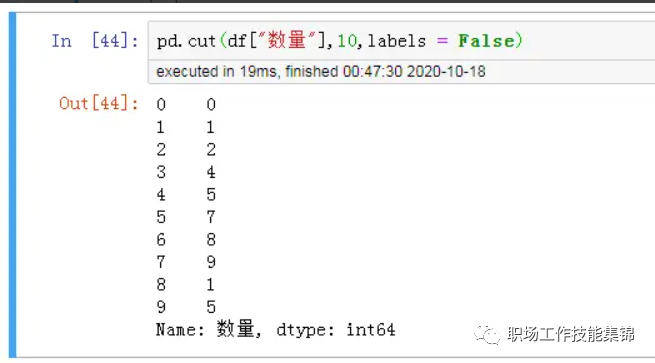
三、 用 .nsmallest() 或 .nlargest() 获取前几的最小或最大值。
比如获取数量最小的前3条记录:
df[["国家", "品牌", "数量"]].nsmallest(3, "数量")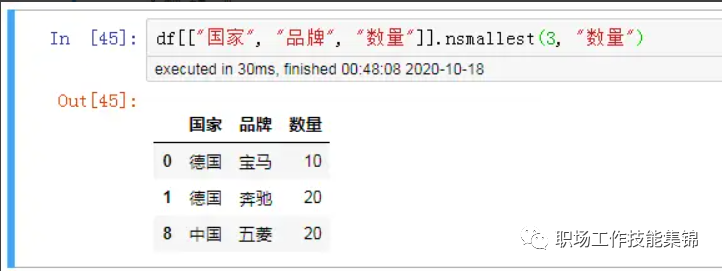
再跟常用的方法对比一下,如下:
df.sort_values(by = "数量",ascending = True).head(3)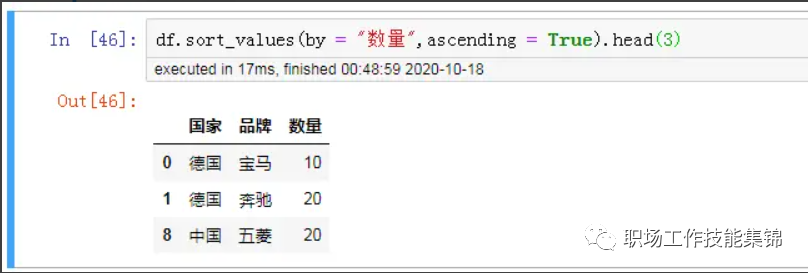
注意事项:.nsmallest() 或 .nlargest() 参数里的筛选条件一定要包好在所抽取出来的DataFrame里面。
四、 数据透视表
4.1 普通的筛选求和:
df[(df["国家"] == "中国") & (df["品牌"] == "五菱")]["数量"].sum()
4.2 pivot_table
pd.pivot_table(df, values = "数量", index = "品牌", columns = "国家", aggfunc = "sum").fillna(0)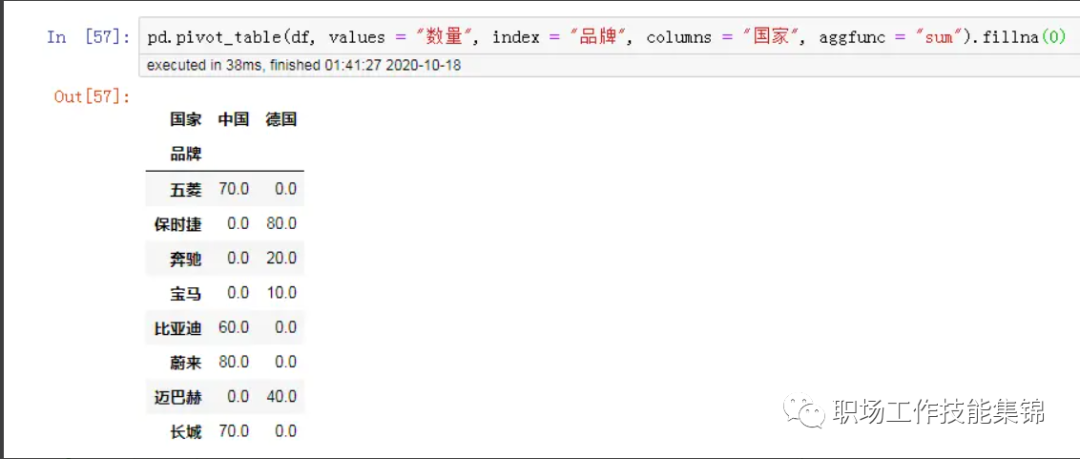
4.2 pivot_table + unstack
pd.pivot_table(df, values = "数量", index = "品牌", columns = "国家", aggfunc = "sum").fillna(0).unstack()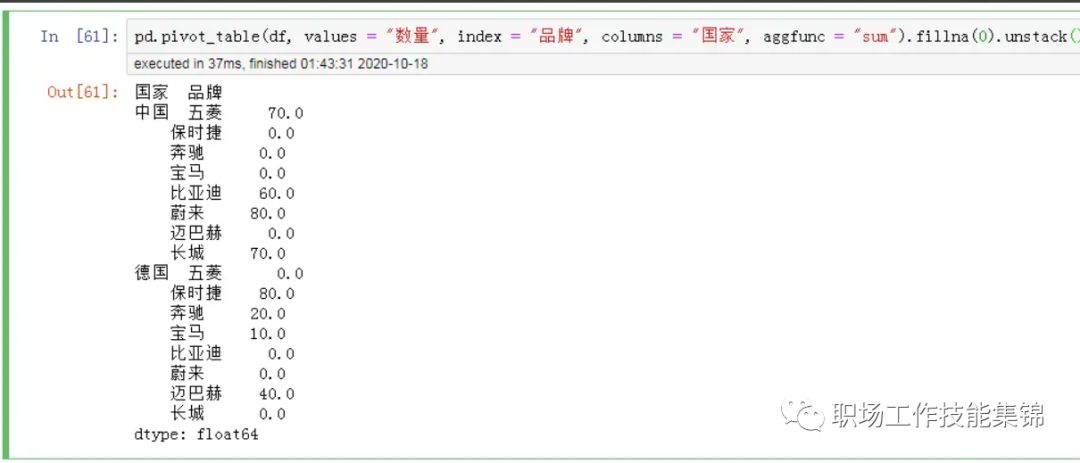

相关阅读:
评论