
Elasticsearch 生产环境集群部署最佳实践
在生产环境搭建或维护 Elasticsearch 集群和个人搭建集群的小打小闹有非常大的不同。
本文的最佳实践基于每天增量数亿+ 的线上环境。
少啰嗦,上干货。
1、内存
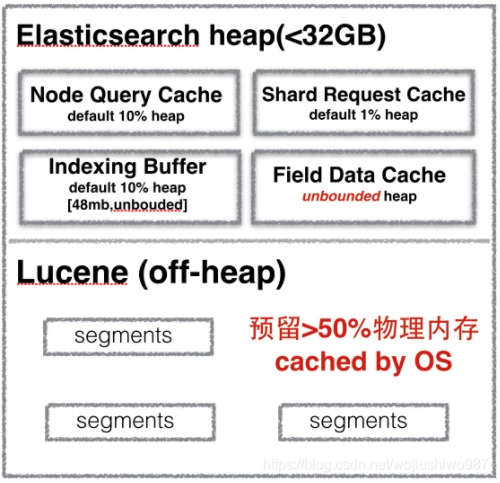
Elasticsearch 和 Lucene 都是 Java 语言编写,这意味着我们必须注意堆内存的设置。
Elasticsearch 可用的堆越多,它可用于过滤器(filter)和其他缓存的内存也就越多,更进一步讲可以提高查询性能。
但请注意,过多的堆可能会使垃圾回收暂停时间过长。请勿将堆内存的最大值设置为 JVM 用于压缩对象指针(压缩的 oops)的临界值之上,确切的临界值有所不同,但不要超过 32 GB。
常见内存配置坑 1:堆内存设置过大
举例:Elasticsearch 宿主机:64 GB 内存,堆内存恨不得设置为 64 GB。
但,这忽略了堆的另一部分内存使用大户:OS 文件缓存。
Lucene 旨在利用底层操作系统来缓存内存中的数据结构。Lucene 段存储在单独的文件中。
由于段是不可变的(immutable),因此这些文件永远不会更改。这使它们非常易于缓存,并且底层操作系统很乐意将热段驻留在内存中,以加快访问速度。
这些段包括倒排索引(用于全文搜索)和doc values 正排索引(用于聚合)。Lucene 的性能取决于与 OS 文件缓存的交互。
如果你将所有可用内存分配给 Elasticsearch 的堆,则 OS 文件缓存将不会剩下任何可用空间。这会严重影响性能。
官方标准建议是:将 50% 的可用内存(不超过 32 GB,一般建议最大设置为:31 GB)分配给 Elasticsearch 堆,而其余 50% 留给 Lucene 缓存。
图片来自网络
可以通过以下方式配置 Elasticsearch 堆:
方式一:堆内存配置文件 jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms16g
-Xmx16g
方式二:启动参数设置
ES_JAVA_OPTS="-Xms10g -Xmx10g" ./bin/elasticsearch
2、CPU
运行复杂的缓存查询、密集写入数据都需要大量的CPU,因此选择正确的查询类型以及渐进的写入策略至关重要。
一个节点使用多个线程池来管理内存消耗。与线程池关联的队列使待处理的请求得以保留(类似缓冲效果)而不是被丢弃。
由于 Elasticsearch会做动态分配,除非有非常具体的要求,否则不建议更改线程池和队列大小。
线程池和队列的设置,参见:
Elasticsearch 线程池和队列问题,请先看这一篇。
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
3、分片数
分片是 Elasticsearch 在集群内分发数据的单位。集群发生故障再恢复平衡的速度取决于分片的大小、分片数量、网络以及磁盘性能。
在 Elasticsearch 中,每个查询在每个分片的单个线程中执行。但是,可以并行处理多个分片。针对同一分片的多个查询和聚合也可以并行处理。
这意味着在不涉及缓存的情况下,最小查询延迟将取决于数据、查询类型以及分片的大小三个因素。
3.1 设置很多小分片 VS 设置很少大分片?
查询很多小分片,导致每个分片能做到快速响应,但是由于需要按顺序排队和处理结果汇集。因此不一定比查询少量的大分片快。
如果存在多个并发查询,那么拥有大量小分片也会降低查询吞吐量。
所以,就有了下面的分片数如何设定的问题?
3.2 分片数设定
选择正确数量的分片是一个复杂问题,因为在集群规划阶段以及在数据写入开始之前,一般不能确切知道文档数。
对于集群而言,分片数多了以后,索引和分片管理可能会使主节点超载,并可能会导致集群无响应,甚至导致集群宕机。
建议:为主节点(Master 节点)分配足够的资源以应对分片数过多可能导致的问题。
必须强调的是:主分片数是在索引创建时定义的,不支持借助 update API 实现类副本数更新的动态修改。创建索引后,更改主分片数的唯一方法是重新创建索引,然后将原来索引数据 reindex 到新索引。
官方给出的合理的建议:每个分片数据大小:30GB-50GB。
推荐1:Elasticsearch究竟要设置多少分片数?
https://elastic.blog.csdn.net/article/details/78080602
推荐2:Elasticsearch之如何合理分配索引分片
https://qbox.io/blog/optimizing-elasticsearch-how-many-shards-per-index
4、副本
Elasticsearch 通过副本实现集群的高可用性,数据在数据节点之间复制,以实现主分片数据的备份,因此即便部分节点因异常下线也不会导致数据丢失。
默认情况下,副本数为 1,但可以根据产品高可用要求将其增加。副本越多,数据的容灾性越高。
副本多的另一个优点是,每个节点都拥有一个副本分片,有助于提升查询性能。
铭毅提醒:
实际副本数增多提高查询性能建议结合集群做下测试,我实测过效果不明显。
副本数增多意味着磁盘存储要加倍,也考验硬盘空间和磁盘预算。
建议:根据业务实际综合考虑设置副本数。普通业务场景(非精准高可用)副本设置为 1 足够了。
5、冷热集群架构配置
根据产品业务数据特定和需求,我们可以将数据分为热数据和冷数据,这是冷热集群架构的前提。
访问频率更高的索引可以分配更多更高配(如:SSD)的数据节点,而访问频率较低的索引可以分配低配(如:机械磁盘)数据节点。
冷热集群架构对于存储诸如应用程序日志或互联网实时采集数据(基于时间序列数据)特别有用。
数据迁移策略:通过运行定时任务来实现定期将索引移动到不同类型的节点。
具体实现:curator 工具或借助 ILM 索引生命周期管理。
5.1 热节点
热节点是一种特定类型的数据节点,关联索引数据是:最近、最新、最热数据。
因为这些热节点数据通常倾向于最频繁地查询。热数据的操作会占用大量 CPU 和 IO 资源,因此对应服务器需要功能强大(高配)并附加 SSD 存储支持。
针对集群规模大的场景,建议:至少运行 3 个热节点以实现高可用性。
当然,这也和你实际业务写入和查询的数据量有关系,如果数据量非常大,可能会需要增加热节点数目。
5.2 冷节点(或称暖节点)
冷节点是对标热节点的一种数据节点,旨在处理大量不太经常查询的只读索引数据。
由于这些索引是只读的,因此冷节点倾向于使用普通机械磁盘而非 SSD 磁盘。
与热节点对标,也建议:最少 3 个冷节点以实现高可用性。
同样需要注意的是,若集群规模非常大,可能需要更多节点才能满足性能要求。
甚至需要更多类型,如:热节点、暖节点、冷节点等。
强调一下:CPU 和 内存的分配最终需要你通过使用与生产环境中类似的环境借助 esrally 性能测试工具测试确定,而不是直接参考各种最佳实践拍脑袋而定。
有关热节点和热节点的更多详细信息,请参见:
https://www.elastic.co/blog/hot-warm-architecture-in-elasticsearch-5-x
6、节点角色划分
Elasticsearch 节点核心可分为三类:主节点、数据节点、协调节点。
6.1 主节点
主节点:如果主节点是仅是候选主节点,不含数据节点角色,则它配置要求没有那么高,因为它不存储任何索引数据。
如前所述,如果分片非常多,建议主节点要提高硬件配置。
主节点职责:存储集群状态信息、分片分配管理等。
同时注意,Elasticsearch 应该有多个候选主节点,以避免脑裂问题。
6.2 数据节点
数据节点职责:CURD、搜索以及聚合相关的操作。
这些操作一般都是IO、内存、CPU 密集型。
6.3 协调节点
协调节点职责:类似负载平衡器,主要工作是:将搜索任务分发到相关的数据节点,并收集所有结果,然后再将它们汇总并返回给客户端应用程序。
6.4 节点配置参考
下表参见官方博客 PPT
| 角色 | 描述 | 存储 | 内存 | 计算 | 网络 |
|---|---|---|---|---|---|
| 数据节点 | 存储和检索数据 | 极高 | 高 | 高 | 中 |
| 主节点 | 管理集群状态 | 低 | 低 | 低 | 低 |
| Ingest | 节点 转换输入数据 | 低 | 中 | 高 | 中 |
| 机器学习节点 | 机器学习 | 低 | 极高 | 极高 | 中 |
| 协调节点 | 请求转发和合并检索结果 | 低 | 中 | 中 | 中 |
6.5 不同节点角色配置如下
必须配置到:elasticsearch.yml 中。
主节点
node.master:true
node.data:false
数据节点
node.master:false
node.data:true
协调节点
node.master:false
node.data:false
7、故障排除提示
Elasticsearch 的性能在很大程度上取决于宿主机资源情况。
CPU、内存使用率和磁盘 IO 是每个Elasticsearch节点的基本指标。
建议你在CPU使用率激增时查看Java虚拟机(JVM)指标。
7.1 堆内存使用率高
高堆内存使用率压力以两种方式影响集群性能:
7.1.1 堆内存压力上升到75%及更高
剩余可用内存更少,并且集群现在还需要花费一些 CPU 资源以通过垃圾回收来回收内存。
在启用垃圾收集时,这些 CPU 周期不可用于处理用户请求。结果,随着系统变得越来越受资源约束,用户请求的响应时间增加。
7.1.2 堆内存压力继续上升并达到接近100%
将使用更具侵略性的垃圾收集形式,这将反过来极大地影响集群响应时间。
索引响应时间度量标准表明,高堆内存压力会严重影响性能。
7.2 非堆内存使用率增长
JVM 外非堆内存的增长,吞噬了用于页面缓存的内存,并可能导致内核级OOM。
7.3 监控磁盘IO
由于Elasticsearch大量使用存储设备,磁盘 IO 的监视是所有其他优化的基础,发现磁盘 IO 问题并对相关业务操作做调整可以避免潜在的问题。
应根据引起磁盘 IO 的情况评估对策,常见优化磁盘 IO 实战策略如下:
优化分片数量及其大小 段合并策略优化 更换普通磁盘为SSD磁盘 添加更多节点
7.5 合理设置预警
对于依赖搜索的应用程序,用户体验与搜索请求的等待时间长短相关。
有许多因素会影响查询性能,例如:
构造查询方式不合理 Elasticsearch 集群配置不合理 JVM 内存和垃圾回收问题 磁盘 IO 等
查询延迟是直接影响用户体验的指标,因此请确保在其上放置一些预警操作。
举例:线上实战问题:

如何避免? 以下两个核心配置供参考:
PUT _cluster/settings
{
"transient": {
"search.default_search_timeout": "50s",
"search.allow_expensive_queries": false
}
}
需要强调的是:"search.allow_expensive_queries" 是 7.7+ 版本才有的功能,早期版本会报错。
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-your-data.html
7.6 合理配置缓存
默认情况下,Elasticsearch中的大多数过滤器都是高速缓存的。
这意味着在第一次执行过滤查询时,Elasticsearch 将查找与过滤器匹配的文档,并使用该信息构建名为“bitset”的结构。
存储在 bitset 中的数据包含文档标识符以及给定文档是否与过滤器匹配。
具有相同过滤器的查询的后续执行将重用存储在bitset中的信息,从而通过节省 IO 操作和 CPU 周期来加快查询的执行速度。
建议在查询中使用 filter 过滤器。
有关更多详细信息,请参见:
7.7 合理设置刷新频率
刷新频率(refresh_interval)和段合并频率与索引性能密切相关,此外,它们还会影响整个集群的性能。
刷新频率需要根据业务需要合理设置,尤其频繁写入的业务场景。
7.8 启动慢查询日志
启用慢查询日志记录将有助于识别哪些查询慢,以及可以采取哪些措施来改进它们,这对于通配符查询特别有用。
推荐:
7.9 增大ulimit大小
增加ulimit大小以允许最大文件数,这属于非常常规的设置。
在 /etc/profile 下设置:
ulimit -n 65535
7.10 合理设置交互内存
当操作系统决定换出未使用的应用程序内存时,ElasticSearch 性能可能会受到影响。
通过 elasticsearch.yml 下配置:
bootstrap.mlockall: true
7.11 禁用通配符模糊匹配删除索引
禁止通过通配符查询删除所有索引。
为确保某人不会对所有索引(* 或 _all)发出 DELETE 操作,设置如下:
PUT /_cluster/settings
{
"persistent": {
"action.destructive_requires_name": true
}
}
此时如果我们再使用通配符删除索引,举例执行如下操作:
DELETE join_*
会报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Wildcard expressions or all indices are not allowed"
}
],
"type" : "illegal_argument_exception",
"reason" : "Wildcard expressions or all indices are not allowed"
},
"status" : 400
}
8、常用指标监视 API
8.1 集群健康状态 API
GET _cluster/health?pretty
8.2 索引信息 API
GET _cat/indices?pretty&v
8.3 节点状态 API
GET _nodes?pretty
8.4 主节点信息 API
GET _cat/master?pretty&v
8.5 分片分配、索引信息统计 API
GET _stats?pretty
8.6 节点状态信息统计 API
统计节点的jvm,http,io统计信息。
GET _nodes/stats?pretty
大多数系统监视工具(如kibana、cerebro 等)都支持 Elasticsearc h的指标聚合。
建议使用此类工具持续监控集群状态信息。
9、小结
ElasticSearch 具有很好的默认配置以供新手快速上手、入门。但是,一旦到了线上业务实战环境,就必须花费一些时间来调整设置以满足实际业务功能要求以及性能指标要求。
建议你参考本文建议并结合官方文档修改相关配置,以使得集群整体部署最优。
加微信:elastic6,一起探讨部署最佳实践。
参考
https://medium.com/@abhidrona/elasticsearch-deployment-best-practices-d6c1323b25d7
https://t.zsxq.com/UVbQbee
推荐:
中国最大的 Elastic 非官方公众号
点击查看“阅读原文”,更短时间更快习得更多干货。和全球 1000 位+ Elastic 爱好者(含中国 50%+ Elastic 认证工程师)一起每日精进 ELK 技能!