
使用 Rust 进行系统编程 — 第一部分
今天的文章是关于系统编程的。Rust 作为系统编程语言,自然是很适合进行系统编程。
现代计算机是一个非常复杂的创造物,经过几十年的研究和发展演变成现在的状态。有时它看起来像是黑魔法。这里面没有魔法,只有科学。然而,一些像 Alan Turing,Charles Babbage,Ada Lovelace,John von Neumann 和许多其他人的头脑是不可思议的,因为他们使计算机成为可能。
现在,让我们深入学习系统编程的基础知识:
进程是什么? 它们是如何创建和执行的? 查看 Rust 中的一些代码示例,并将它们与 C 进行比较
在开始编写代码之前,我们将从操作系统主要组件的最底层开始构建。如图 1 所示——任何计算机的最低级别是 Hardware,其次是运行在裸机上的 Kernel 模式。这就是像 Linux 这样的操作系统所在的位置。
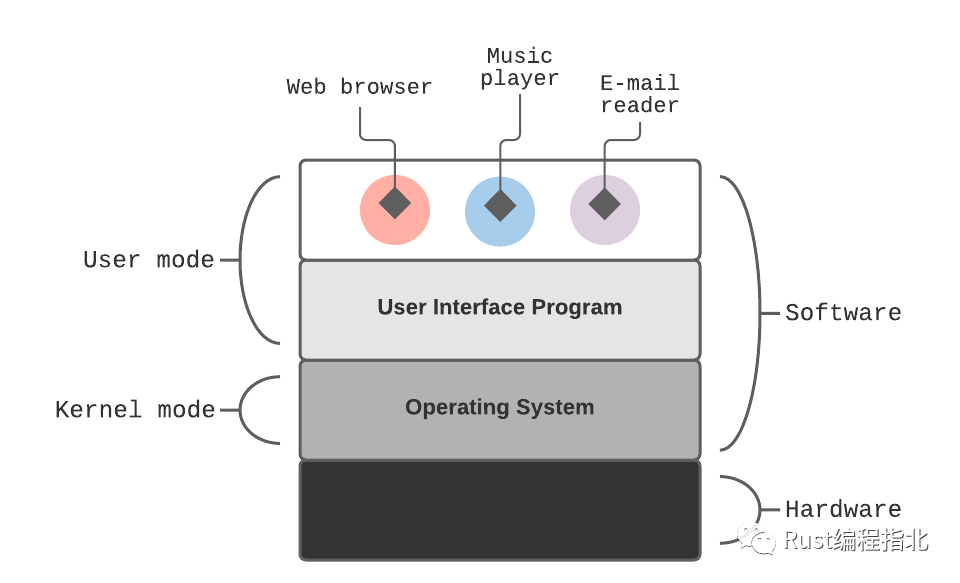
在内核模式之上,我们有一个用户模式。为了使用户能够与内核交互并使用其他更高级别的软件,如网页浏览器、电子邮件阅读器等,它需要一个用户界面程序。这可以是一个窗口,图形用户界面,也可以是一个 Shell,它是一个解释命令的命令,用于从终端读取命令并执行它们。
进程:父和子
所有操作系统的主要概念是进程。一个进程基本上是一个正在运行的程序。你可以把它想象成一个抽屉,里面包含有关这个特定程序的所有信息。有些进程在计算机启动时开始运行,有些在后台运行,有些由用户通过 Shell 调用和交互。
所有进程都有一个 id。当系统启动时,将启动第一个进程。这个进程的 id 为1,称为 init。在此之后,init 将调用其他进程等等。当我们在 shell 中键入一个命令供 OS 执行时,系统应该创建一个新的进程来运行编译器。当进程完成编译后,它将进行一个系统调用来终止自己。
在 UNIX 系统中,每个新进程都是某个父进程的子进程。进程创建是通过克隆父进程来完成的,这被称为 forking (图1-b)。每个进程有一个父进程,但可以有多个子进程。进程的结构类似于树,其中 init 是根,这意味着它位于层次结构的顶部。
在进程创建之后,除了父进程有一个非 0 ID 号,子进程的 ID 等于 0 外,其他方面父进程和子进程是相同的。接下来,系统用一个新程序替换子进程的执行。当进程完成其目的时,它将正常地终止并退出(自愿的)。该进程也可以由于一个错误退出或杀死另一个进程(非自愿)。

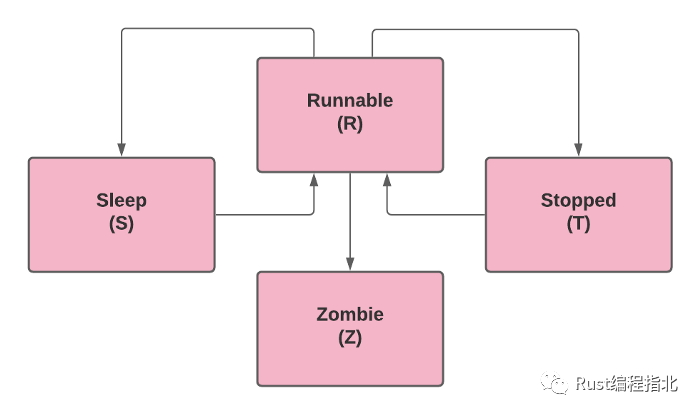
该系统还跟踪所有的进程,将它们的数据保存在所谓的进程表中。它包含诸如进程 id、进程所有者、进程优先级、每个进程的环境变量、父进程等信息。除此之外,它还保存特定进程处于何种状态的信息。每个进程可以处于以下四种状态之一:
RUNNABLE — 进程正在运行/主动使用 CPU SLEEPING — 该进程是可运行的,但是正在等待另一个进程先停止/完成 STOPPED — 此状态表示进程已暂停以便进一步运行。它可以通过信号重新启动再次运行 ZOMBIE — 当调用 “system exit” 或其他人终止进程时,进程将终止。但是,该进程尚未从进程表中删除
通常进程必须相互交互,并且可以改变状态,从 Running 到 Sleeping,然后回到 Running (图1-c)。这通常由 SIGSTOP 信号完成,该信号由 Ctrl + Z 发出(我们将在接下来的部分中深入讨论信号)。与停止的进程一样,它可以重新启动。一旦被杀死进入 Zombie 状态就不能重新启动或继续。
C VS Rust
在 C 语言中(这是目前 Linux 内核编程语言),进程创建首先通过 fork 新进程来完成,然后显式地要求系统在子进程上执行一个新指令。如果我们不这样做,父进程和子进程将执行相同的指令。下面是执行 ls 命令的一个例子,它列出了给定目录的文件:
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t pid;
switch (pid = fork()) {
case -1:
perror("fork failed");
break;
case 0:
printf("I'm child process and I will execute ls command");
char *argv_list[] = {NULL};
if (execv("ls", argv_list) == -1) {
perror("Error in execve");
exit(EXIT_FAILURE);
}
break;
default:
printf("I'm parent process and I'll just print this");
}
return 0;
}
正如你所看到的,我们必须手动管理进程,并监控执行是否成功。此外,我们还必须处理错误。如果我们希望一个命令只能由一个子进程执行,那么我们必须手动检查当前进程是否是一个子进程,这是按照 case 0 来完成的。在 Rust 中,标准库的进程模块[1]也可以做到这一点:
use std::process::Command;
fn main() {
let child = Command::new("ls")
.env("PATH", "/bin")
.output()
.expect("failed to execute process");
// if no error, program will continue..
}这里的 Command::new() 是一个进程构建器,负责生成和处理子进程。就像在 C 代码中一样,我们提供要执行的命令、环境变量、命令参数和调用输出方法。输出将以子进程的形式执行该命令,等待它完成,并返回收集到的输出。
除了 output() 之外,我们还可以使用 status() 或 spawn()。这些方法中的每一个都负责 fork 一个具有细微差异的子进程:
output():只有在子进程完成运行后,才运行程序并返回Output的结果;status():将运行程序并在进程编译后返回ExitStatus结果。这允许检查编译程序的状态;spawn():将运行程序并返回结果,该结果是一个子进程。这不需要等待程序编译。该选项允许wait和kill指令,或者我们可以获得该进程的 ID。
在这里,env() 是可选的,因为 Command 非常聪明,可以查找 /bin 文件夹的路径。最后,所有的错误处理都由 expect() 完成。如果 Ok 表示程序成功执行或者 Err 表示出现错误,进而 panic!)。如果遇到 Err,希望程序不要终止,可以这样做:
use std::process::Command;
main() {
let user_input = get_user_input(); // helper function to get user input
if let Err(_) = Command::new(&user_input)
.envs("PATH", "/bin")
.status() {
println!("{}: command not found!", &cmd);
}
// the rest of the program...
}
这里的 status() 更方便,如果用户提供合法命令并执行,则调用它将返回 Ok。但我们只对提供不可用命令时的处理感兴趣。这就是为什么我们只检查 Err 是否返回,如果返回,则在终端中打印 “command was not found” 并继续当前程序执行,而不是终止。
最后,spawn() 用于管理多个子进程和父进程之间的执行顺序。它包含 stdin stdout 和 stderr 字段,并且具有 c 程序员所熟悉的 wait() , kill() 和 id() 方法。我们将在下一部分中看到进程的这一部分,当两个或多个线程可以访问共享数据并且它们试图同时更改这些数据时,我们还将看到 Rust 是如何处理竞态条件的。
总结
在这个介绍性的部分中,我们回顾了什么是进程,它们是如何创建的,并将 Rust 对进程创建和命令执行的实现与 C 进行了比较。我们看到,Rust 代码不仅不容易出现人为错误,而且不那么冗长,很简洁。在接下来的部分中,我们将介绍如何管理进程执行时间和状态,以及处理系统信号。
原文链接:https://www.bexxmodd.com/post/systems-programming-with-rust-1
参考资料
进程模块: https://doc.rust-lang.org/std/process/struct.Command.html
推荐阅读
觉得不错,点个赞吧
扫码关注「Rust编程指北」