
关系型数据库的瓶颈 与 优化
1. 数据库的分类
数据库大致可以分为两部分:
传统的关系型数据库, 如: MySQL, Oracle, SQLServer 以及 PostgreSQL; MySQL 是国内使用最广泛的数据库, Oracle 在传统行业应用最为广泛, PostgreSQL 性能和功能都比较完善, 但目前文档和社区还有待成长.
非关系型数据库, 如 HBase(列式数据库), MongoDB(文档型数据库), Redis(高性能 KV 存储), Lucene(搜索引擎) 等等.
2. 关系型数据库的瓶颈与优化
2.1 为什么数据库的架构需要调整
互联网的数据增长往往是指数型的;
读写分离, 分布式: 单机性能上存在瓶颈;
NoSQL, 搜索引擎: 特殊场景的需求无法满足;
分析系统: 无法满足大数据的分析需求;
部署要求: 同城容灾/异地容灾.
2.2 数据库会遇到什么问题
2.2.1 性能
查询性能
写入更新
并发, 数据量等
2.2.2 功能
新功能: LBS/JSON/特殊业务场景
数据安全性: 强一致性/非强一致性
大数据分析
搜索等
3. 不同业务场景的存储选型
3.1 一个简单的问题
MySQL 已经有 cache 了, 为何还需要加一层 Redis
3.2 数据库查询开销
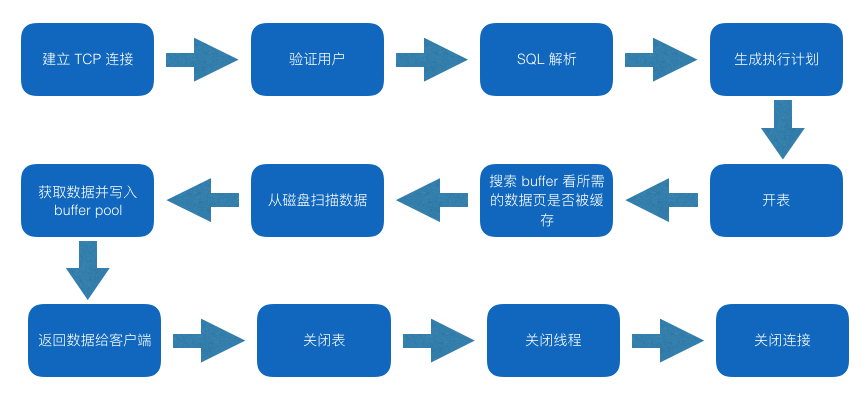
其中比较耗时的步骤有:
建立 TCP 连接
生成执行计划
开表
从磁盘扫描数据
关闭连接
3.2.1 SQL 解析
假设有如下三条语句, 均是根据主键的查询.
1 | # 1 |
造成第三条语句执行时间如此长的主要原因就是大量的 OR 语句会导致 SQL 解析非常耗时.
3.2.2 以 MySQL 的 InnoDB 存储引擎主键查询为例
1 | SELECT * FROM t WHERE id = ?; |
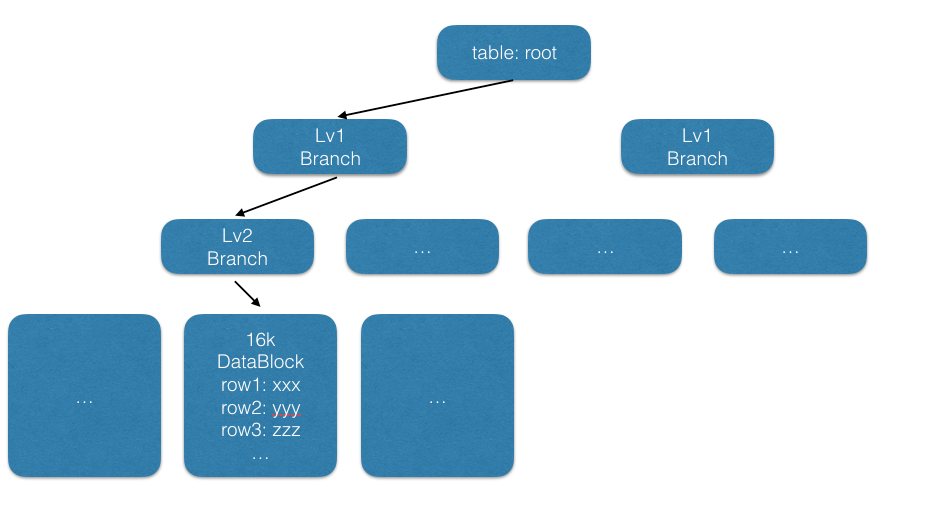
常规配置的服务器基本可以达到 400000 QPS.
3.2.3 如果查询条件不是主键
1 | SELECT * FROM t WHERE name = ?; |
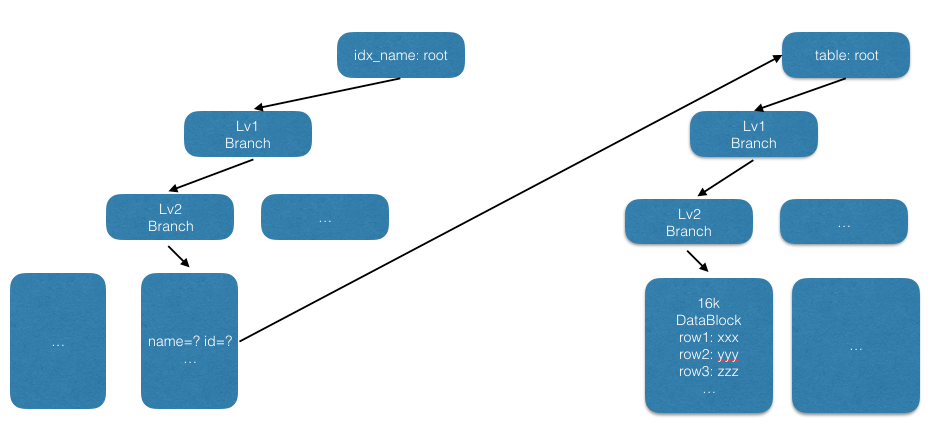
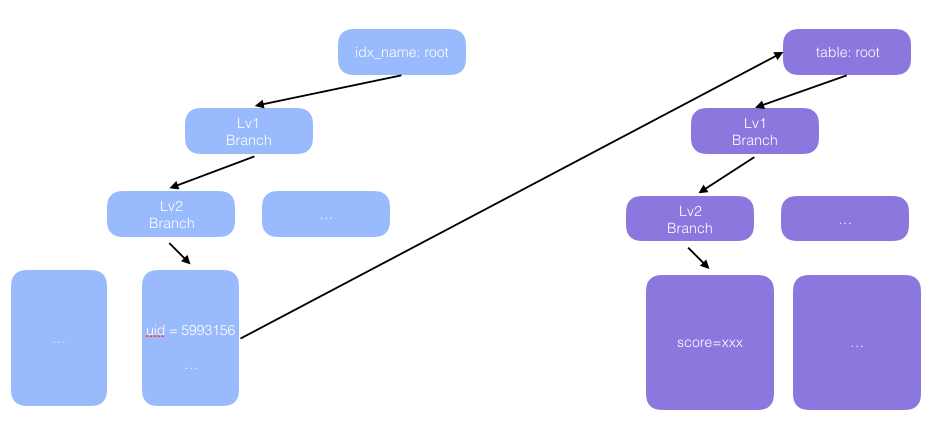
对于非主键的查询, MySQL 会根据二级索引查询到主索引对应节点的位置. 按照图中的情况, 会首先通过三次 IO 找到对应主键, 在二级索引的叶子节点会同时保存索引字段的值以及主键的值, 再回到主索引通过主键查询到整条记录.
在 MySQL 中, 主键查询是最为高效的一类查询.
DBA 往往希望所有的 SQL 语句都是 KV 查询, 但是往往是不现实的.
主键查询有限, 有些主键没有业务含义;
设计表结构时, 并没有考虑过主键问题.
SQL 语句允许开发人员用各种方式从表中获取数据, 但 DBA 却不会希望我们这么做.
3.2.3 数据库的大字段
1 | content varchar(2046) NOT NULL COMMENT '原始消息'; |
以 InnoDB 存储引擎为例:
TinyText/Text/Mediumtext
varchar(256)/varchar(500)/varchar(20000)
tinyBlob/blob/mediumBlob
text 类型本质上和 varchar 类型没有区别.
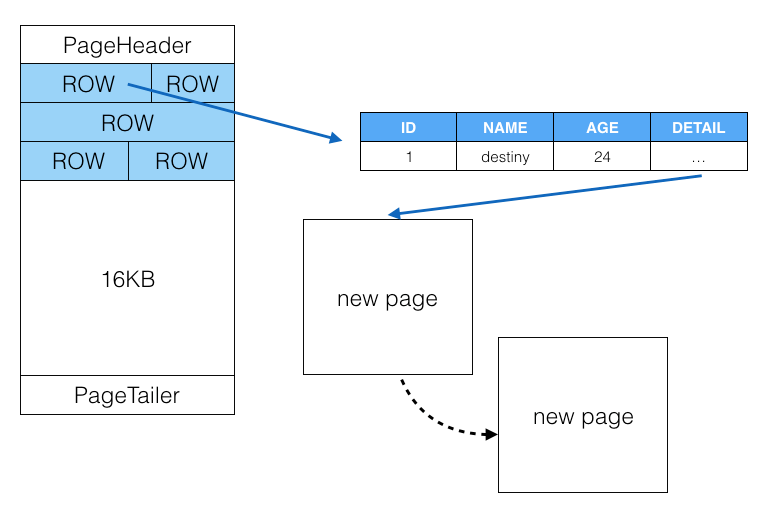
MySQL 中, 数据是以页的方式来组织的, 每个数据页默认大小 16 KB, 其中包括页头, 页尾, 中间是一行一行的记录.
图中的每条记录包括 ID, NAME, AGE 和 DETAIL. 假设 DETAIL 是一个大字段, 达到超过了单页的大小, 此时 DB 会新开一个数据页, 当前页通过指针指向该页. 如果一页依然不够, MySQL 就会不断新加数据页直到能够存下为止.
一旦存在这样的大字段, 会带来如下问题:
查询开销大;
查询影响大, 严重时会触发热页换出, 引起系统抖动. MySQL 将记录从磁盘读取出来的时候, 可能会有很多数据页, MySQL 自带缓存时非常宝贵的, 会导致真正使用频率高的数据页被替换成大字段的数据页. 此外, 对 MySQL 来说, 即便只查记录中的某几个字段, 数据库依然会把整条记录取出, 读进内存, 再进行指定字段的筛选
对于大字段场景可以尝试的优化方案:
是否适合存储关系型数据库;
是否所有数据都需要存数据库;
是否可以新建一张表存储大字段.
3.2.4 数据库缓存利用率
以 InnoDB 存储引擎为例:
MySQL 默认数据页为
16KB, 哪怕只读一行记录, 也需要从磁盘中取出16KB数据取出;MySQL 是以页为最小的缓存单位;
如果每行数据 1kb, 256kb 内存空间能缓存多少行有效数据, 最好的情况是每条数据整齐排列在一个数据页中, 那么可以缓存256条记录, 最坏的情况下每一页只存在一条数据, 那么就只能缓存16条;
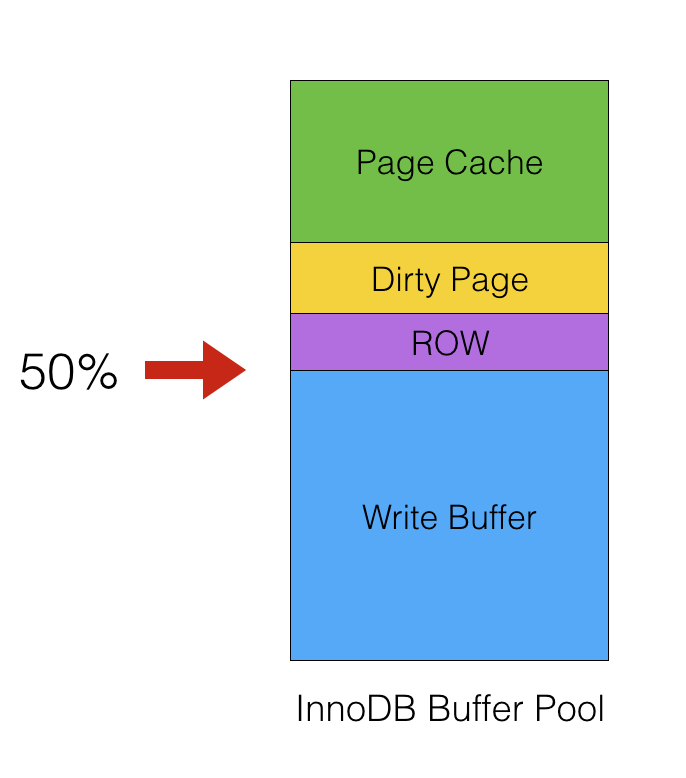
在 256KB 的 Buffer Pool 中, 并不是所有空间都用来做数据页缓存, 有很大的一块在 Write Buffer(MySQL 为了优化写操作, 会将一段时间内的写操作先放在 Write Buffer, 再由后台线程定时异步刷新到磁盘上). 然而剩下的
128KB中还存在一部分脏页.
缓存为什么如此重要:
互联网产品往往读多写少;
扩展缓存远比扩展 DB 简单;
数据库缓存利用率很低;
互联网应用对 DB 响应时间比较敏感, 缓存系统一般性能比较好
只要符合条件的数据都应该走缓存:
修改不频繁的数据;
非实时的数据, 一致性要求不严的数据;
查询频率较高, 带有明显热点请求的数据;
3.2.5 缓存带来的问题
用了缓存并不一定代表没有问题
缓存命中
缓存穿透
缓存失效
缓存一致
3.2.6 选择正确的索引
降低扫描数据量还是降低排序代价
大多数查询只能使用一个索引, 因此在需要对多个列进行操作的 SQL 语句中, 我们需要准确评估每个索引的开销.
key idx_create_time(createTime)
key idx_price(price)
1SELECT * FROM tb_order WHERE createTime > xxx AND createTime < xxx ORDER BY price DESC;
3.2.7 索引的使用
3.2.7.1 索引字段过长, 超过索引支持
1 | # name varchar(512) |
上面的例子在实际场景中执行非常慢, 使用 EXPLAIN 打印查询计划:
select_type: SIMPLE
table: comment
type: range
possible_keys: id_name
key: uk_sess
key_len: 403
ref: NULL
rows: 462642
Extra:Using where; Using filesort
1 row in set(0.00sec)
其中需要重点关注的是: Extra:Using where; Using filesort
Using where: 表用到了索引
Using filesort: MySQL 自带的磁盘排序, 并没有用到索引的排序
问题是为什么使用了索引, 查询效率依然非常慢?
真正的原因是字段太长, 而索引的长度只能覆盖 256 字节, 导致 ORDER BY 无法在内存中完成排序
3.2.7.2
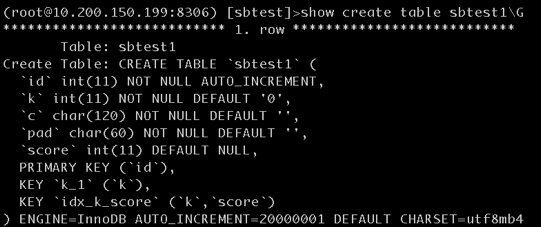
查询某个用户 id 的分值总和
1 | -- uid varchar(190) NOT NULL DEFAULT '' COMMENT '用户 id', |
这条 SQL 的执行顺序:
根据二级索引 uid 找到所有主键 id
再根据主键逐行找到 score
对 score 进行聚合
这个 SQL 的问题在于需要进行大量的回表操作(从二级索引回到一级索引), 然后将全部符合过滤条件的记录放在内存中完成聚合操作.
改进的方法其实很简单, 可以尝试使用 (uid, score) 建立联合索引, 这样只需要查询二级索引就可以获得全部数据.
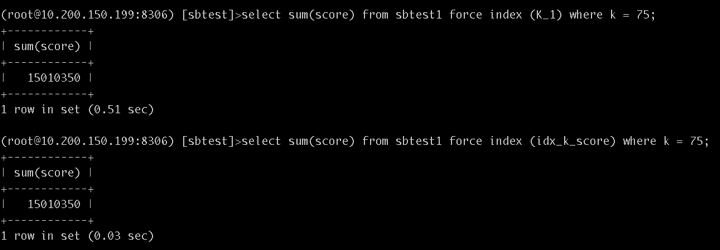
随机插入 100W 条数据, 现在对比下两条索引的开销.
3.3 数据库写开销
对持久化要求严格, 写操作代价大
日志文件需要 fsync, 硬件存在瓶颈
数据库写操作很难扩展
主从要求一致场景下还要算上网络开销
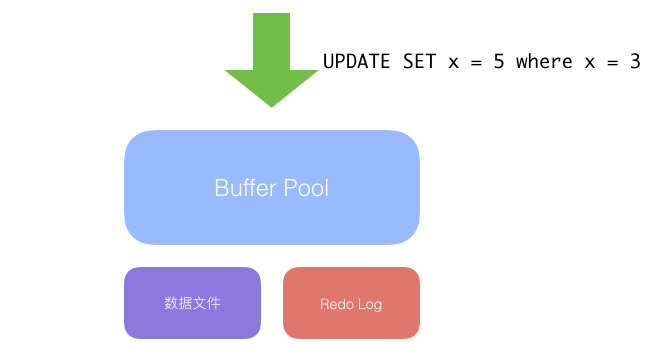
将 3 所在的数据页读到缓存中;
在内存中将 3 改成 5, 提交事务, 触发 Redo Log 的刷新;
向用户返回操作成功;
3.4 业务场景触发的高并发写入
3.4.1 秒杀
高并发写入的极端情况
业务优化(缓存/令牌通/排队/Java 信号量/乐观锁)
热点资源隔离
引入数据库线程池
InnoDB 内核层优化: AliSQL
3.4.2 私信/站内信消息推送
高并发写入
伴随大量的读请求
系统消息/个人消息区分对待
消息内容单独对待
延迟写入, 通过队列/缓存达到限流目的
3.4.3 听歌量

业务原因导致写入量非常大
插入更新比不确定, 更新能力强
数据库需要具备自动扩展的能力
数据非强一致
3.5 死锁和超时
InnoDB 锁超时默认需要 5s 等待
死锁马上就能被发现, 然后被 DB 自动回滚
锁超时一般是索引不对, 或者 SQL 语句执行性能较差
死锁一般是业务实现有问题
锁超时一般影响较为可控
死锁情况比较严重, 会导致全站崩溃
3.6 数据库并发事务, 锁
业务流程中的锁: 减库存, 发优惠券
悲观锁实现:
1 | BEGIN; |
乐观锁实现:
1 | BEGIN; |
4. 数据库的模块化拆分
4.1 单机服务器的局限
虽然硬件配置越来越高, 但是总有瓶颈(e.g. CPU/内存/网络/IO/容量)
为了后续业务的可扩展性
单机系统崩溃风险较高
优化性能
读写分离
冷热分离, 创建归档库
关键链路和非关键链路隔离
系统层面做好降级
4.2 常见拆分方案
4.2.1 读写分离
读写分离的原理就是将数据库读写操作分散到不同的节点上
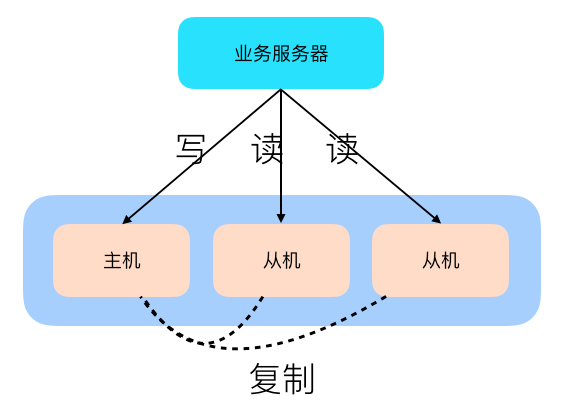
读写分离的基本原理就是:
数据库服务器搭建主从集群;
数据库主机负责写操作, 从机只负责读操作;
数据库主机通过复制将数据同步到从机, 每台数据库服务器都存储了所有业务数据.
业务服务器将写操作发给数据库主机, 将读操作发给数据库从机.
使用读写分离之后, 可能会引入两个问题:
主从复制延迟
分配机制
4.2.1.1 复制延迟
主从复制的延迟可能达到秒级, 如果有大量数据短时间需要完成同步, 延迟甚至可能达到分钟.
主从复制所带来的问题:
如果业务服务器将数据写入到主库后进行读取, 此时读操作访问从库, 而主库的数据没有完全复制过来, 从库是无法读取到最新数据的.
解决方案:
写操作后的读操作指定发给主库, 逻辑会和业务强绑定, 对业务侵入较大.
读从库失败后再读一次主库, 如果有大量没有命中从库的读请求, 会给主库带来较大压力.
关键业务读写操作全部走主库, 非关键业务采用读写分离.
4.2.1.2 分配机制
将读写操作区分开来, 然后访问不同的数据库服务器, 一般有两种方式: 程序代码封装和中间件封装
1. 程序代码封装
在代码中抽象一个数据访问层, 实现读写操作分离和数据库服务器连接的管理.
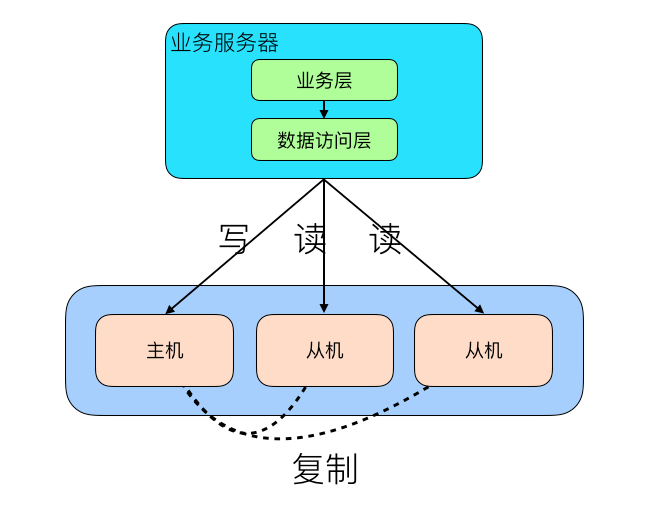
特点:
实现简单, 可以根据业务定制化;
无法做到多语言通用, 容易重复开发;
故障情况下, 如果主从发生切换, 需要将系统配置手动修改.
2. 中间件封装
独立一套系统出来, 实现读写分离和数据库服务器连接的管理, 中间件对业务服务器提供 SQL 兼容的协议, 业务服务器无需自己进行读写分离, 对于业务服务器来说, 访问中间件和访问数据库没有区别
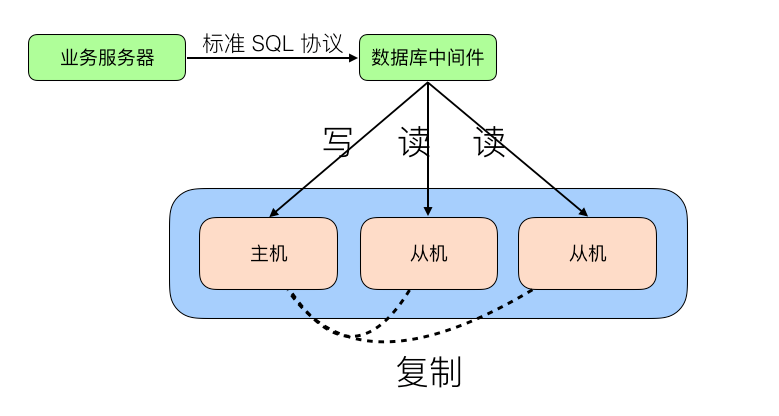
特点:
能够支持多种编程语言, 因为数据库中间件对业务提供的是标准的 SQL 接口.
实现较为复杂, 需要完整支持 SQL 语法和数据库服务器的协议.
性能要求很高, 容易成为瓶颈.
数据库主从切换对业务服务器无感知, 数据库中间件可以探测数据库服务器的主从状态(e.g. 向某个测试库写入一条数据, 成功的是主机, 失败的是从机)
4.2.2 分布式
读写分离分散了读写操作的压力, 但没有分散存储的压力, 当数据量达到千万级以上的时候, 单台数据库服务器的存储能力就会成为瓶颈:
数据量太大, 读写的性能会大幅下降.
数据文件备份和恢复都会很困难.
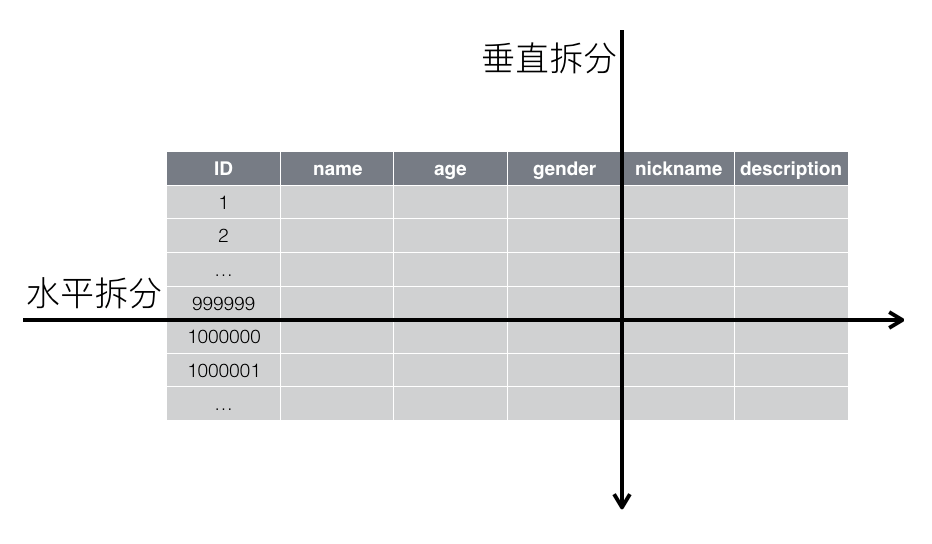
垂直分表: 适合将某些表中不常用且占用大量空间的列拆分出去. 代价是操作表的数量增加.
水平拆分: 适合行数较大的表, 会引入更多的复杂度:
路由,join 操作,count 操作等
https://destinywang.github.io/blog/2019/01/19/关系型数据库的瓶颈与优化

喜欢,在看