
地表最强VLP模型!谷歌大脑和CMU华人团队提出极简弱监督模型,多模态下达到SOTA

新智元报道
新智元报道
来源:arxiv
编辑:Priscilla 好困
【新智元导读】谷歌大脑与CMU华人团队提出全新图像+文本预训练模型SimVLM,在最简单的模型结构与训练方式下也能在6个多模态基准领域达到SOTA,与现有VLP模型相比泛化能力更强。


只使用了单一的预训练损失,是当前最简化的VLP模型; 只使用了弱监督,极大地降低了对预训练数据的要求; 使生成模型具备了极强的零样本能力,包含零样本跨模态迁移和开放式视觉问答(VQA)。
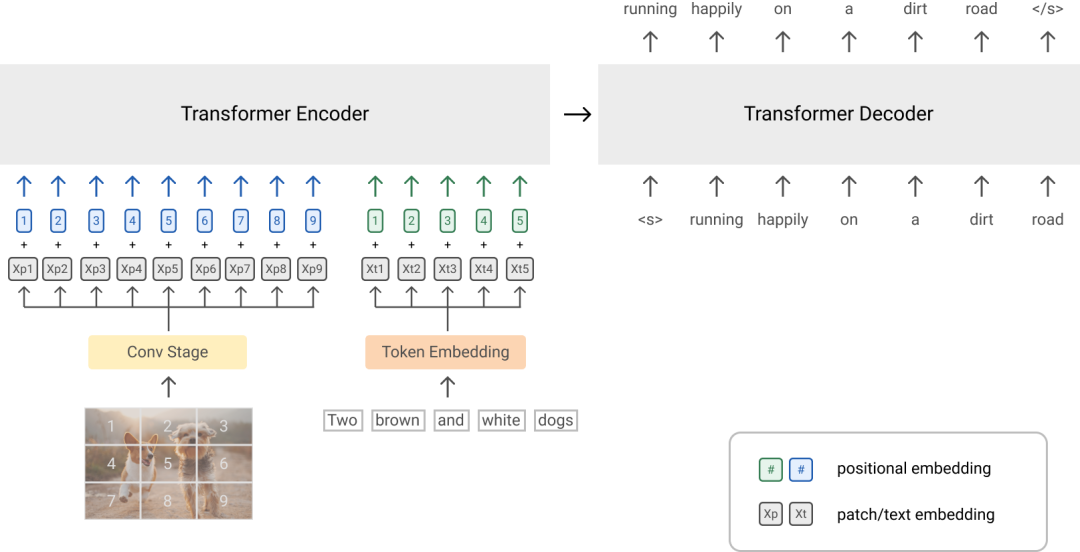
SimVLM
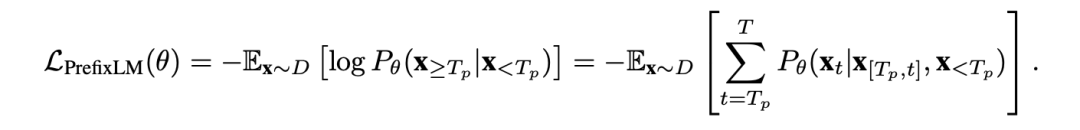
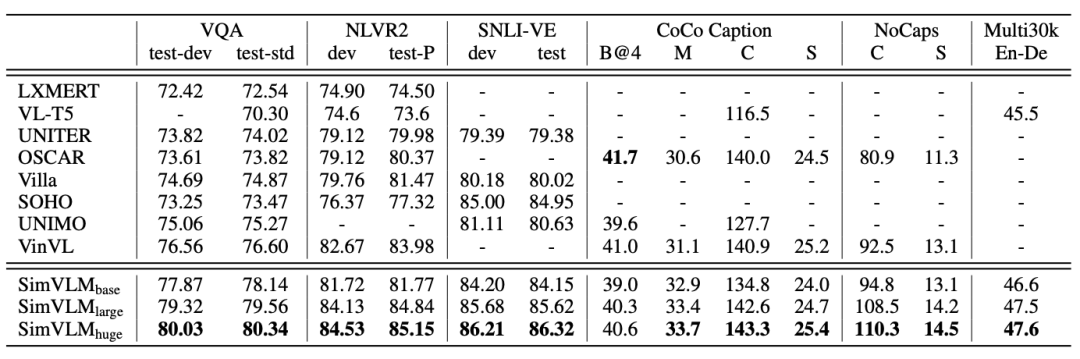
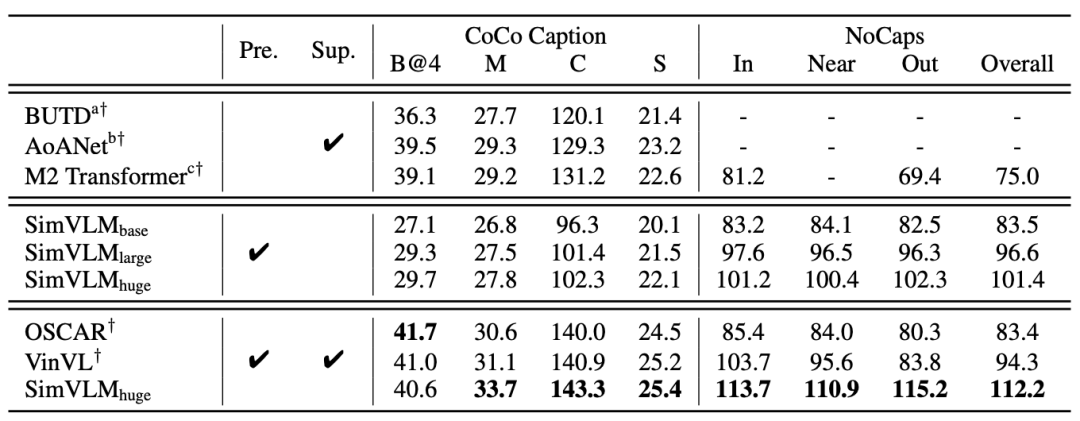
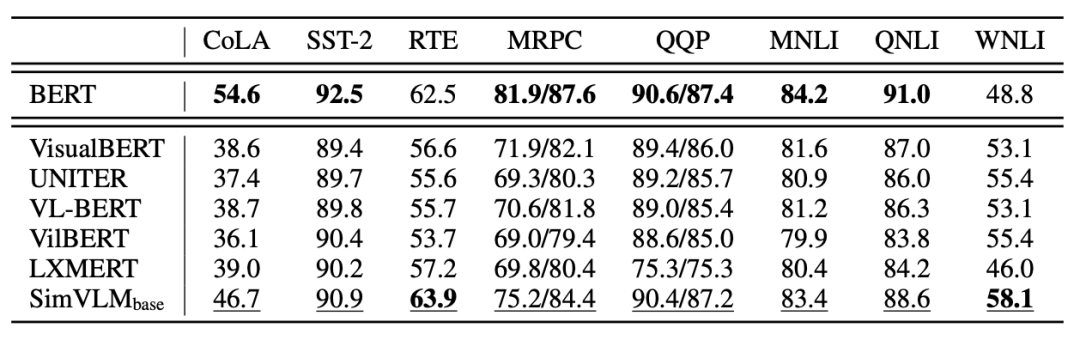
结果分析


团队介绍


参考资料:
https://arxiv.org/pdf/2108.10904.pdf

评论