
使用PyTorch时,最常见的4个错误
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文总结了使用PyTorch时常见的4个错误,并给出了每一种错误出现的原因并给出了详细的修复方法及代码步骤:1.没有首先尝试过拟合单个batch。2.忘了为网络设置train/eval模式。3.在.backward()之前忘记了.zero_grad()。4.将softmaxed输出传递给了期望原始logits的损失。

最常见的神经网络错误:
1)你没有首先尝试过拟合单个batch。
2)你忘了为网络设置train/eval模式。
3)在.backward()之前忘记了.zero_grad()(在pytorch中)。
4)将softmaxed输出传递给了期望原始logits的损失,还有其他吗?
这篇文章将逐点分析这些错误是如何在PyTorch代码示例中体现出来的。
代码:https://github.com/missinglinkai/common-nn-mistakes
常见错误 #1 你没有首先尝试过拟合单个batch
Andrej说我们应该过拟合单个batch。为什么?好吧,当你过拟合了单个batch —— 你实际上是在确保模型在工作。我不想在一个巨大的数据集上浪费了几个小时的训练时间,只是为了发现因为一个小错误,它只有50%的准确性。当你的模型完全记住输入时,你会得到的结果是对其最佳表现的很好的预测。
可能最佳表现为零,因为在执行过程中抛出了一个异常。但这没关系,因为我们很快就能发现问题并解决它。总结一下,为什么你应该从数据集的一个小子集开始过拟合:
发现bug
估计最佳的可能损失和准确率
快速迭代
在PyTorch数据集中,你通常在dataloader上迭代。你的第一个尝试可能是索引train_loader。
# TypeError: 'DataLoader' object does not support indexing
first_batch = train_loader[0]
你会立即看到一个错误,因为DataLoaders希望支持网络流和其他不需要索引的场景。所以没有__getitem__方法,这导致了[0]操作失败,然后你会尝试将其转换为list,这样就可以支持索引。
# slow, wasteful
first_batch = list(train_loader)[0]
但这意味着你要评估整个数据集这会消耗你的时间和内存。那么我们还能尝试什么呢?
在Python for循环中,当你输入如下:
for item in iterable:
do_stuff(item)
你有效地得到了这个:
iterator = iter(iterable)
try:
while True:
item = next(iterator)
do_stuff(item)
except StopIteration:
pass
调用“iter”函数来创建迭代器,然后在循环中多次调用该函数的“next”来获取下一个条目。直到我们完成时,StopIteration被触发。在这个循环中,我们只需要调用next, next, next… 。为了模拟这种行为但只获取第一项,我们可以使用这个:
first = next(iter(iterable))
我们调用“iter”来获得迭代器,但我们只调用“next”函数一次。注意,为了清楚起见,我将下一个结果分配到一个名为“first”的变量中。我把这叫做“next-iter” trick。在下面的代码中,你可以看到完整的train data loader的例子:
for batch_idx, (data, target) in enumerate(train_loader):
# training code here
下面是如何修改这个循环来使用 first-iter trick :
first_batch = next(iter(train_loader))
for batch_idx, (data, target) in enumerate([first_batch] * 50):
# training code here
你可以看到我将“first_batch”乘以了50次,以确保我会过拟合。
常见错误 #2: 忘记为网络设置 train/eval 模式
为什么PyTorch关注我们是训练还是评估模型?最大的原因是dropout。这项技术在训练中随机去除神经元。
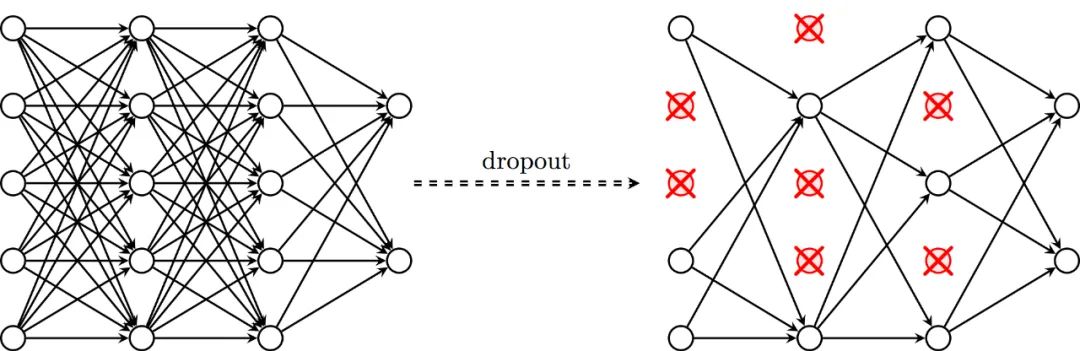
想象一下,如果右边的红色神经元是唯一促成正确结果的神经元。一旦我们移除红色神经元,它就迫使其他神经元训练和学习如何在没有红色的情况下保持准确。这种drop-out提高了最终测试的性能 —— 但它对训练期间的性能产生了负面影响,因为网络是不全的。在运行脚本并查看MissingLink dashobard的准确性时,请记住这一点。
在这个特定的例子中,似乎每50次迭代就会降低准确度。
如果我们检查一下代码 —— 我们看到确实在train函数中设置了训练模式。
def train(model, optimizer, epoch, train_loader, validation_loader):
model.train() # ????????????
for batch_idx, (data, target) in experiment.batch_loop(iterable=train_loader):
data, target = Variable(data), Variable(target)
# Inference
output = model(data)
loss_t = F.nll_loss(output, target)
# The iconic grad-back-step trio
optimizer.zero_grad()
loss_t.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
train_loss = loss_t.item()
train_accuracy = get_correct_count(output, target) * 100.0 / len(target)
experiment.add_metric(LOSS_METRIC, train_loss)
experiment.add_metric(ACC_METRIC, train_accuracy)
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx, len(train_loader),
100. * batch_idx / len(train_loader), train_loss))
with experiment.validation():
val_loss, val_accuracy = test(model, validation_loader) # ????????????
experiment.add_metric(LOSS_METRIC, val_loss)
experiment.add_metric(ACC_METRIC, val_accuracy)
这个问题不太容易注意到,在循环中我们调用了test函数。
def test(model, test_loader):
model.eval()
# ...
在test函数内部,我们将模式设置为eval!这意味着,如果我们在训练过程中调用了test函数,我们就会进eval模式,直到下一次train函数被调用。这就导致了每一个epoch中只有一个batch使用了drop-out ,这就导致了我们看到的性能下降。
修复很简单 —— 我们将model.train() 向下移动一行,让如训练循环中。理想的模式设置是尽可能接近推理步骤,以避免忘记设置它。修正后,我们的训练过程看起来更合理,没有中间的峰值出现。请注意,由于使用了drop-out ,训练准确性会低于验证准确性。
常用的错误 #3: 忘记在.backward()之前进行.zero_grad()
当在 “loss”张量上调用 “backward” 时,你是在告诉PyTorch从loss往回走,并计算每个权重对损失的影响有多少,也就是这是计算图中每个节点的梯度。使用这个梯度,我们可以最优地更新权值。
这是它在PyTorch代码中的样子。最后的“step”方法将根据“backward”步骤的结果更新权重。从这段代码中可能不明显的是,如果我们一直在很多个batch上这么做,梯度会爆炸,我们使用的step将不断变大。
output = model(input) # forward-pass
loss_fn.backward() # backward-pass
optimizer.step() # update weights by an ever growing gradient ????????????
为了避免step变得太大,我们使用 zero_grad 方法。
output = model(input) # forward-pass
optimizer.zero_grad() # reset gradient ????
loss_fn.backward() # backward-pass
optimizer.step() # update weights using a reasonably sized gradient ????
这可能感觉有点过于明显,但它确实赋予了对梯度的精确控制。有一种方法可以确保你没有搞混,那就是把这三个函数放在一起:
zero_gradbackwardstep
在我们的代码例子中,在完全不使用zero_grad的情况下。神经网络开始变得更好,因为它在改进,但梯度最终会爆炸,所有的更新变得越来越垃圾,直到网络最终变得无用。
调用backward之后再做zero_grad。什么也没有发生,因为我们擦掉了梯度,所以权重没有更新。剩下的唯一有变化的是dropout。
我认为在每次step方法被调用时自动重置梯度是有意义的。
在backward的时候不使用zero_grad的一个原因是,如果你每次调用step() 时都要多次调用backward,例如,如果你每个batch只能将一个样本放入内存中,那么一个梯度会噪声太大,你想要在每个step中聚合几个batch的梯度。另一个原因可能是在计算图的不同部分调用backward —— 但在这种情况下,你也可以把损失加起来,然后在总和上调用backward。
常见错误 #4: 你把做完softmax的结果送到了需要原始logits的损失函数中
logits是最后一个全连接层的激活值。softmax也是同样的激活值,但是经过了标准化。logits值,你可以看到有些是正的,一些是负的。而log_softmax之后的值,全是负值。如果看柱状图的话,可以看到分布式一样的,唯一的差别就是尺度,但就是这个细微的差别,导致最后的数学计算完全不一样了。但是为什么这是一个常见的错误呢?在PyTorch的官方MNIST例子中,查看forward 方法,在最后你可以看到最后一个全连接层self.fc2,然后就是log_softmax。
但是当你查看官方的PyTorch resnet或者AlexNet模型的时候,你会发现这些模型在最后并没有softmax层,最后得到就是全连接的输出,就是logits。
这两个的差别在文档中没有说的很清楚。如果你查看nll_loss函数,并没有提得输入是logits还是softmax,你的唯一希望是在示例代码中发现nll_loss使用了log_softmax作为输入。
下载1:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
