
数据结构快速盘点 - 线性结构
PS: 由于公众号本身的限制,有些链接无法给出,需要的可以阅读原文查看。
这篇文章不是讲解数据结构的文章,而是结合现实的场景帮助大家 理解和复习数据结构与算法,
如果你的数据结构基础很差,建议先去看一些基础教程,再转过来看。
本篇文章的定位是侧重于前端的,通过学习前端中实际场景的数据结构,从而加深大家对数据结构的理解和认识。
线性结构
数据结构我们可以从逻辑上分为线性结构和非线性结构。线性结构有
数组,栈,链表等, 非线性结构有树,图等。
其实我们可以称树为一种半线性结构。
需要注意的是,线性和非线性不代表存储结构是线性的还是非线性的,这两者没有任何关系,它只是一种逻辑上的划分。比如我们可以用数组去存储二叉树。
一般而言,有前驱和后继的就是线性数据结构。比如数组和链表。其实一叉树就是链表。
数组
数组是最简单的数据结构了,很多地方都用到它。比如有一个数据列表等,用它是再合适不过了。其实后面的数据结构很多都有数组的影子。
我们之后要讲的栈和队列其实都可以看成是一种 受限的数组, 怎么个受限法呢?我们后面讨论。
我们来讲几个有趣的例子来加深大家对数组这种数据结构的理解。
React Hooks
Hooks的本质就是一个数组, 伪代码:

那么为什么hooks要用数组?我们可以换个角度来解释,如果不用数组会怎么样?
function Form() {
// 1. Use the name state variable
const [name, setName] = useState('Mary');
// 2. Use an effect for persisting the form
useEffect(function persistForm() {
localStorage.setItem('formData', name);
});
// 3. Use the surname state variable
const [surname, setSurname] = useState('Poppins');
// 4. Use an effect for updating the title
useEffect(function updateTitle() {
document.title = name + ' ' + surname;
});
// ...
}
基于数组的方式,Form的hooks就是 [hook1, hook2, hook3, hook4],
我们可以得出这样的关系, hook1就是[name, setName] 这一对,
hook2就是persistForm这个。
如果不用数组实现,比如对象,Form的hooks就是
{
'key1': hook1,
'key2': hook2,
'key3': hook3,
'key4': hook4,
}
那么问题是key1,key2,key3,key4怎么取呢?
关于React hooks 的本质研究,更多请查看React hooks: not magic, just arrays
React 将 如何确保组件内部hooks保存的状态之间的对应关系这个工作交给了
开发人员去保证,即你必须保证HOOKS的顺序严格一致,具体可以看React 官网关于 Hooks Rule 部分。
队列
队列是一种受限的序列,它只能够操作队尾和队首,并且只能只能在队尾添加元素,在队首删除元素。
队列作为一种最常见的数据结构同样有着非常广泛的应用, 比如消息队列
"队列"这个名称,可类比为现实生活中排队(不插队的那种)
在计算机科学中, 一个 队列(queue) 是一种特殊类型的抽象数据类型或集合。集合中的实体按顺序保存。
队列基本操作有两种:
向队列的后端位置添加实体,称为入队
从队列的前端位置移除实体,称为出队。
队列中元素先进先出 FIFO (first in, first out)的示意:
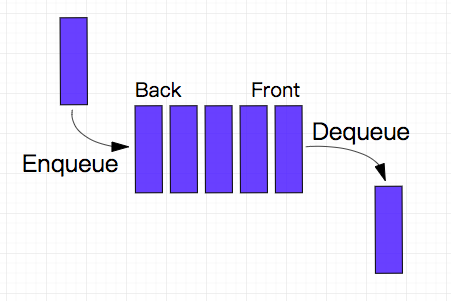
(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/queue/README.zh-CN.md)
我们前端在做性能优化的时候,很多时候会提到的一点就是“HTTP 1.1 的队头阻塞问题”,具体来说
就是HTTP2 解决了 HTTP1.1 中的队头阻塞问题,但是为什么HTTP1.1有队头阻塞问题,HTTP2究竟怎么解决的很多人都不清楚。
其实“队头阻塞”是一个专有名词,不仅仅这里有,交换器等其他都有这个问题,引起这个问题的根本原因是使用了 队列这种数据结构。
对于同一个tcp连接,所有的http1.0请求放入队列中,只有前一个 请求的响应收到了,然后才能发送下一个请求,这个阻塞主要发生在客户端。
这就好像我们在等红绿灯,即使旁边绿灯亮了,你的这个车道是红灯,你还是不能走,还是要等着。
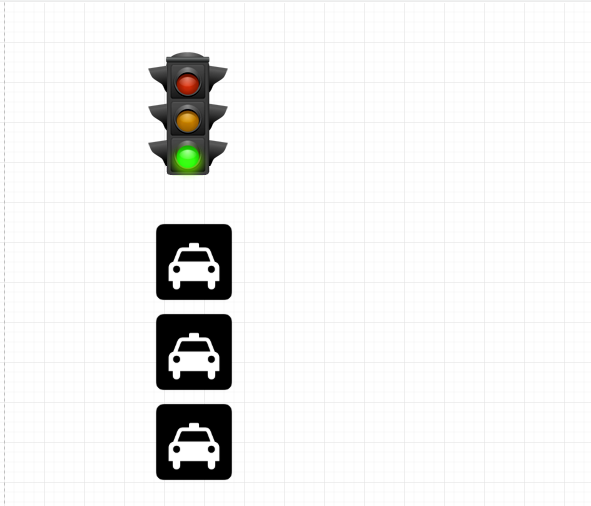
HTTP/1.0 和 HTTP/1.1:
在 HTTP/1.0 中每一次请求都需要建立一个TCP连接,请求结束后立即断开连接。在 HTTP/1.1 中,每一个连接都默认是长连接(persistent connection)。对于同一个tcp连接,允许一次发送多个http1.1请求,也就是说,不必等前一个响应收到,就可以发送下一个请求。这样就解决了http1.0的客户端的队头阻塞,而这也就是 HTTP/1.1中 管道(Pipeline)的概念了。但是, http1.1规定,服务器端的响应的发送要根据请求被接收的顺序排队,也就是说,先接收到的请求的响应也要先发送。这样造成的问题是,如果最先收到的请求的处理时间长的话,响应生成也慢,就会阻塞已经生成了的响应的发送。也会造成队头阻塞。可见,http1.1的队首阻塞发生在服务器端。
如果用图来表示的话,过程大概是:
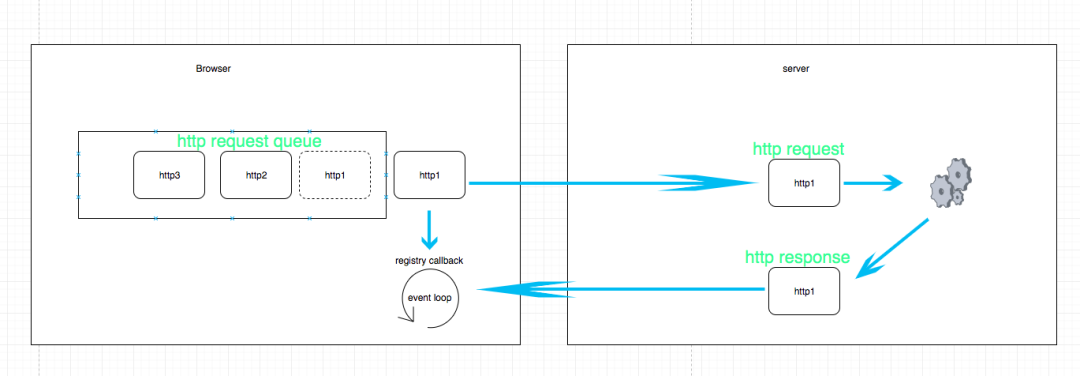
HTTP/2 和 HTTP/1.1:
为了解决 HTTP/1.1中的服务端队首阻塞, HTTP/2采用了 二进制分帧 和 多路复用 等方法。二进制分帧中,帧是 HTTP/2数据通信的最小单位。在 HTTP/1.1数据包是文本格式,而 HTTP/2的数据包是二进制格式的,也就是二进制帧。采用帧可以将请求和响应的数据分割得更小,且二进制协议可以更高效解析。HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。多路复用 用以替代原来的序列和拥塞机制。在HTTP/1.1 中,并发多个请求需要多个TCP链接,且单个域名有6-8个TCP链接请求限制。在HHTP/2`中,同一域名下的所有通信在单个链接完成,仅占用一个TCP链接,且在这一个链接上可以并行请求和响应,互不干扰。
此网站可以直观感受
HTTP/1.1和HTTP/2的性能对比。
栈
栈也是一种受限的序列,它只能够操作栈顶,不管入栈还是出栈,都是在栈顶操作。
在计算机科学中, 一个 栈(stack) 是一种抽象数据类型,用作表示元素的集合,具有两种主要操作:
push, 添加元素到栈的顶端(末尾);
pop, 移除栈最顶端(末尾)的元素.
以上两种操作可以简单概括为“后进先出(LIFO = last in, first out)”。
此外,应有一个 peek 操作用于访问栈当前顶端(末尾)的元素。(只返回不弹出)
"栈"这个名称,可类比于一组物体的堆叠(一摞书,一摞盘子之类的)。
栈的 push 和 pop 操作的示意:
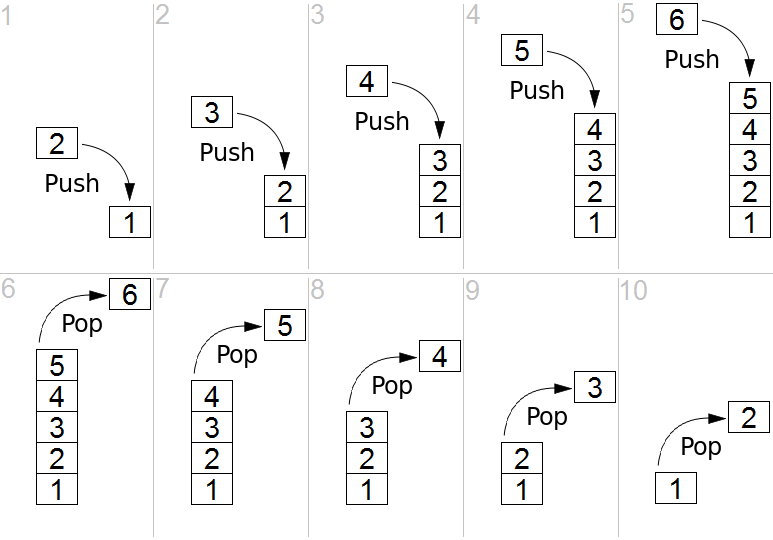
(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
栈在很多地方都有着应用,比如大家熟悉的浏览器就有很多栈,其实浏览器的执行栈就是一个基本的栈结构,从数据结构上说,它就是一个栈。这也就解释了,我们用递归的解法和用循环+栈的解法本质上是差不多。
比如如下JS代码:
function bar() {
const a = 1
const b = 2;
console.log(a, b)
}
function foo() {
const a = 1;
bar();
}
foo();
真正执行的时候,内部大概是这样的:
我画的图没有画出执行上下文中其他部分(this和scope等), 这部分是闭包的关键,而我这里不是将闭包的,是为了讲解栈的。
社区中有很多“执行上下文中的scope指的是执行栈中父级声明的变量”说法,这是完全错误的, JS是词法作用域,scope指的是函数定义时候的父级,和执行没关系
栈常见的应用有进制转换,括号匹配,栈混洗,中缀表达式(用的很少),后缀表达式(逆波兰表达式)等。
合法的栈混洗操作,其实和合法的括号匹配表达式之间存在着一一对应的关系,
也就是说n个元素的栈混洗有多少种,n对括号的合法表达式就有多少种。感兴趣的可以查找相关资料
链表
链表是一种最基本数据结构,熟练掌握链表的结构和常见操作是基础中的基础。
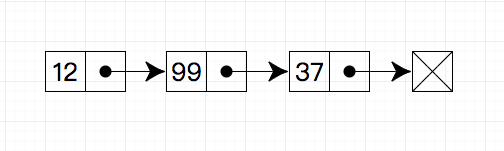
(图片来自:https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/linked-list/traversal)
React Fiber
很多人都说 fiber 是基于链表实现的,但是为什么要基于链表呢,可能很多人并没有答案,那么我觉得可以把这两个点(fiber 和链表)放到一起来讲下。
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。

图片来自 Lin Clark 在 ReactConf 2017 分享
上面已经指出了引入 fiber 之前的问题,就是 react 会阻止优先级高的代码(比如用户输入)执行。因此 fiber
打算自己自建一个 虚拟执行栈来解决这个问题,这个虚拟执行栈的实现是链表。
Fiber 的基本原理是将协调过程分成小块,一次执行一块,然乎将运算结果保存起来,并判断是否有时间(react 自己实现了一个类似 requestIdleCallback 的功能)继续执行下一块。如果有时间,则继续。否则跳出,让浏览器主线程歇一会,执行别的优先级高的代码。
当协调过程完成(所有的小块都运算完毕), 那么就会进入提交阶段, 真正的进行副作用(side effect)操作,比如更新DOM,这个过程是没有办法取消的,原因就是这部分有副作用。
问题的关键就是将协调的过程划分为一块块的,最后还可以合并到一起,有点像Map/Reduce。
React 必须重新实现遍历树的算法,从依赖于 内置堆栈的同步递归模型,变为 具有链表和指针的异步模型。
Andrew 是这么说的:如果你只依赖于[内置]调用堆栈,它将继续工作直到堆栈为空。。。
如果我们可以随意中断调用堆栈并手动操作堆栈帧,那不是很好吗?这就是 React Fiber 的目的。Fiber是堆栈的重新实现,专门用于React组件。你可以将单个 Fiber 视为一个 虚拟堆栈帧。
react fiber 大概是这样的:
let fiber = {
tag: HOST_COMPONENT,
type: "div",
return: parentFiber,
children: childFiber,
sibling: childFiber,
alternate: currentFiber,
stateNode: document.createElement("div"),
props: { children: [], className: "foo"},
partialState: null,
effectTag: PLACEMENT,
effects: []
};
从这里可以看出fiber本质上是个对象,使用parent,child,sibling属性去构建fiber树来表示组件的结构树,
return, children, sibling也都是一个fiber,因此fiber看起来就是一个链表。
细心的朋友可能已经发现了, alternate也是一个fiber, 那么它是用来做什么的呢?它其实原理有点像git, 可以用来执行git revert ,git commit等操作,这部分挺有意思,我会在我的《从零开发git》中讲解
想要了解更多的朋友可以看这个文章
如果可以翻墙, 可以看英文原文
这篇文章也是早期讲述fiber架构的优秀文章
我目前也在写关于《从零开发react系列教程》中关于fiber架构的部分,如果你对具体实现感兴趣,欢迎关注。
另外最近也发布了前端领域的数据结构与算法解读 - fiber 感兴趣的可以看一下
❤️看完三件事
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点赞,让更多的人也能看到介绍内容(收藏不点赞,都是耍流氓-_-) 关注公众号“前端劝退师”,不定期分享原创知识。 也看看其他文章
劝退师个人微信:huab119
也可以来我的GitHub博客里拿所有文章的源文件:
前端劝退指南:https://github.com/roger-hiro/BlogFN一起玩耍呀。