
270亿参数、刷榜CLUE,达摩院神作!
经历「大炼模型」后,人工智能领域正进入「炼大模型」时代。自去年 OpenAI 发布英文领域超大规模预训练语言模型 GPT-3 后,中文领域同类模型的训练进程备受关注。今日,阿里达摩院发布了 270 亿参数、1TB + 训练数据的全球最大中文预训练语言模型 PLUG,并以 80.614 的分数刷新了中文语言理解评测基准 CLUE 分类榜单历史纪录。
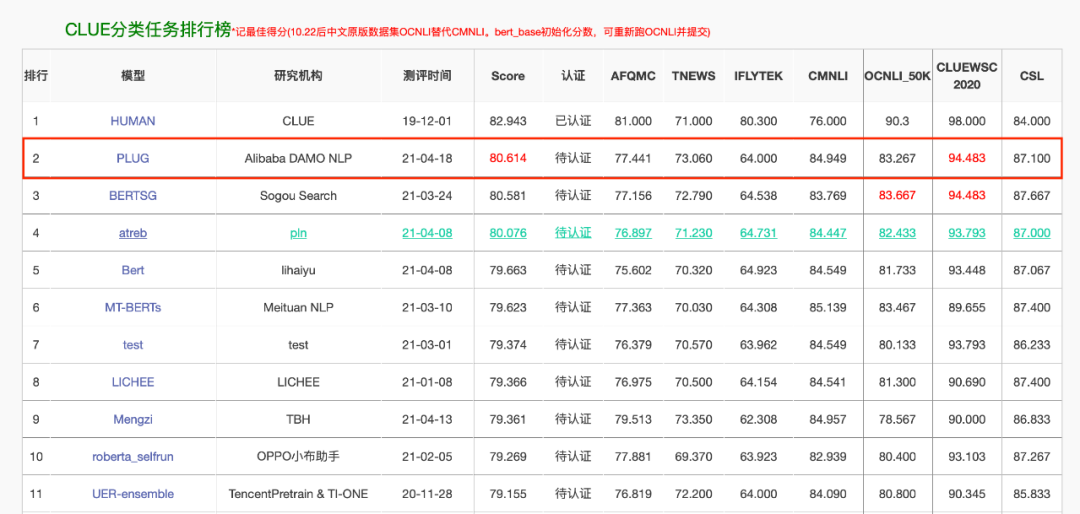
PLUG 是目前中文社区最大规模的纯文本预训练语言模型;
PLUG 集语言理解与生成能力于一身,在语言理解(NLU)任务上,以 80.614 的得分刷新了 Chinese GLUE 分类榜单的新记录排名第一;在语言生成(NLG)任务上,在多项业务数据上较 SOTA 平均提升 8% 以上;
PLUG 可为目标任务做针对性优化,通过利用下游训练数据微调模型使其在特定任务上生成质量达到最优,弥补之前其它大规模生成模型 few-shot inference 的生成效果不足,可应用于实际生成任务上;
PLUG 采用了大规模的高质量中文训练数据(1TB 以上),同时,PLUG 采用 encoder-decoder 的双向建模方式,因此,在传统的 zero-shot 生成的表现上,无论是生成的多样性、领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
首先在第一阶段,达摩院团队训练了一个 24 layers/8192 hidden size 的标准 StructBERT 模型作为 encoder。这个过程共计训练了 300B tokens 的训练数据,规模与 GPT-3 的训练规模相当;
在第二阶段,达摩院团队将这个 encoder 用于生成模型的初始化,并外挂了一个 6 layers / 8192 hidden size 的 decoder,在训练生成模型的过程中,在 encoder 端和 decoder 端均随机确定长度 [32, 512] 进行数据采样,确保适应下游广泛的生成任务。这一阶段共计训练了 100B tokens 的训练数据,前 90% 的训练中,团队保留了 Masked LM 任务以保持模型的 NLU 能力,后 10% 的训练中,去掉 MLM 任务进行微调,以使得生成的 PPL 降到更低,能取得更好的生成效果。

© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!