
Linux 原生 AIO 实现(Native AIO)
上一篇文章 主要分析了 Linux 原生 AIO 的原理和使用,而这篇要介绍的是 Linux 原生 AIO 的实现过程。
本文基于 Linux-2.6.0 版本内核源码
一般来说,使用 Linux 原生 AIO 需要 3 个步骤:
1) 调用
io_setup函数创建一个一般 IO 上下文。2) 调用
io_submit函数向内核提交一个异步 IO 操作。3) 调用
io_getevents函数获取异步 IO 操作结果。
所以,我们可以通过分析这三个函数的实现来理解 Linux 原生 AIO 的实现。
Linux 原生 AIO 实现在源码文件
/fs/aio.c中。
创建异步 IO 上下文
要使用 Linux 原生 AIO,首先需要创建一个异步 IO 上下文,在内核中,异步 IO 上下文使用 kioctx 结构表示,定义如下:
struct kioctx {atomic_t users; // 引用计数器int dead; // 是否已经关闭struct mm_struct *mm; // 对应的内存管理对象unsigned long user_id; // 唯一的ID,用于标识当前上下文, 返回给用户struct kioctx *next;wait_queue_head_t wait; // 等待队列spinlock_t ctx_lock; // 锁int reqs_active; // 正在进行的异步IO请求数struct list_head active_reqs; // 正在进行的异步IO请求对象struct list_head run_list;unsigned max_reqs; // 最大IO请求数struct aio_ring_info ring_info; // 环形缓冲区struct work_struct wq;};
在 kioctx 结构中,比较重要的成员为 active_reqs 和 ring_info。active_reqs 保存了所有正在进行的异步 IO 操作,而 ring_info 成员用于存放异步 IO 操作的结果。
kioctx 结构如 图1 所示:
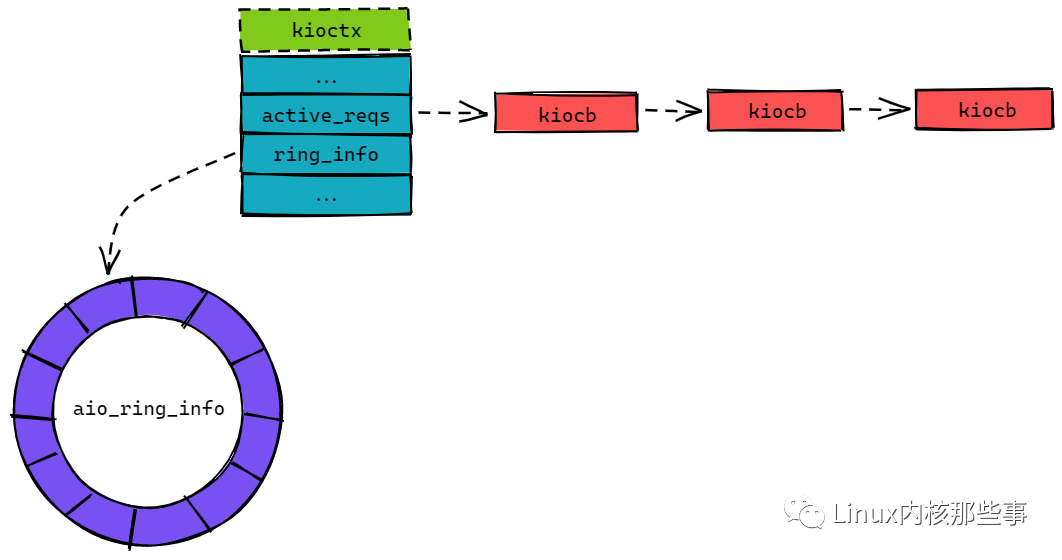
如 图1 所示,active_reqs 成员保存的异步 IO 操作队列是以 kiocb 结构为单元的,而 ring_info 成员指向一个类型为 aio_ring_info 结构的环形缓冲区(Ring Buffer)。
所以我们先来看看 kiocb 结构和 aio_ring_info 结构的定义:
struct kiocb {...struct file *ki_filp; // 异步IO操作的文件对象struct kioctx *ki_ctx; // 指向所属的异步IO上下文...struct list_head ki_list; // 用于连接所有正在进行的异步IO操作对象__u64 ki_user_data; // 用户提供的数据指针(可用于区分异步IO操作)loff_t ki_pos; // 异步IO操作的文件偏移量...};
kiocb 结构比较简单,主要用于保存异步 IO 操作的一些信息,如:
ki_filp:用于保存进行异步 IO 的文件对象。ki_ctx:指向所属的异步 IO 上下文对象。ki_list:用于连接当前异步 IO 上下文中的所有 IO 操作对象。ki_user_data:这个字段主要提供给用户自定义使用,比如区分异步 IO 操作,或者设置一个回调函数等。ki_pos:用于保存异步 IO 操作的文件偏移量。
而 aio_ring_info 结构是一个环形缓冲区的实现,其定义如下:
struct aio_ring_info {unsigned long mmap_base; // 环形缓冲区的虚拟内存地址unsigned long mmap_size; // 环形缓冲区的大小struct page **ring_pages; // 环形缓冲区所使用的内存页数组spinlock_t ring_lock; // 保护环形缓冲区的自旋锁long nr_pages; // 环形缓冲区所占用的内存页数unsigned nr, tail;// 如果环形缓冲区不大于 8 个内存页时// ring_pages 就指向 internal_pages 字段struct page *internal_pages[AIO_RING_PAGES];};
这个环形缓冲区主要用于保存已经完成的异步 IO 操作的结果,异步 IO 操作的结果使用 io_event 结构表示。如 图2 所示:
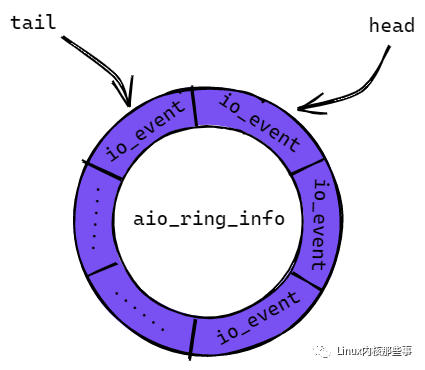
图2 中的 head 代表环形缓冲区的开始位置,而 tail 代表环形缓冲区的结束位置,如果 tail 大于 head,则表示有完成的异步 IO 操作结果可以获取。如果 head 等于 tail,则表示没有完成的异步 IO 操作。
环形缓冲区的 head 和 tail 位置保存在 aio_ring 的结构中,其定义如下:
struct aio_ring {unsigned id;unsigned nr; // 环形缓冲区可容纳的 io_event 数unsigned head; // 环形缓冲区的开始位置unsigned tail; // 环形缓冲区的结束位置...};
上面介绍了那么多数据结构,只是为了接下来的源码分析更加容易明白。
现在,我们开始分析异步 IO 上下文的创建过程,异步 IO 上下文的创建通过调用 io_setup 函数完成,而 io_setup 函数会调用内核函数 sys_io_setup,其实现如下:
asmlinkage long sys_io_setup(unsigned nr_events, aio_context_t *ctxp){struct kioctx *ioctx = NULL;unsigned long ctx;long ret;...ioctx = ioctx_alloc(nr_events); // 调用 ioctx_alloc 函数创建异步IO上下文ret = PTR_ERR(ioctx);if (!IS_ERR(ioctx)) {ret = put_user(ioctx->user_id, ctxp); // 把异步IO上下文的标识符返回给调用者if (!ret)return 0;io_destroy(ioctx);}out:return ret;}
sys_io_setup 函数的实现比较简单,首先调用 ioctx_alloc 申请一个异步 IO 上下文对象,然后把异步 IO 上下文对象的标识符返回给调用者。
所以,sys_io_setup 函数的核心过程是调用 ioctx_alloc 函数,我们继续分析 ioctx_alloc 函数的实现:
static struct kioctx *ioctx_alloc(unsigned nr_events){struct mm_struct *mm;struct kioctx *ctx;...ctx = kmem_cache_alloc(kioctx_cachep, GFP_KERNEL); // 申请一个 kioctx 对象...INIT_LIST_HEAD(&ctx->active_reqs); // 初始化异步 IO 操作队列...if (aio_setup_ring(ctx) < 0) // 初始化环形缓冲区goto out_freectx;...return ctx;...}
ioctx_alloc 函数主要完成以下工作:
调用
kmem_cache_alloc函数向内核申请一个异步 IO 上下文对象。初始化异步 IO 上下文各个成员变量,如初始化异步 IO 操作队列。
调用
aio_setup_ring函数初始化环形缓冲区。
环形缓冲区初始化函数 aio_setup_ring 的实现有点小复杂,主要涉及内存管理的知识点,所以这里跳过这部分的分析,有兴趣的可以私聊我一起讨论。
提交异步 IO 操作
提交异步 IO 操作是通过 io_submit 函数完成的,io_submit 需要提供一个类型为 iocb 结构的数组,表示要进行的异步 IO 操作相关的信息,我们先来看看 iocb 结构的定义:
struct iocb {__u64 aio_data; // 用户自定义数据, 可用于标识IO操作或者设置回调函数...__u16 aio_lio_opcode; // IO操作类型, 如读(IOCB_CMD_PREAD)或者写(IOCB_CMD_PWRITE)操作__s16 aio_reqprio;__u32 aio_fildes; // 进行IO操作的文件句柄__u64 aio_buf; // 进行IO操作的缓冲区(如写操作的话就是写到文件的数据)__u64 aio_nbytes; // 缓冲区的大小__s64 aio_offset; // IO操作的文件偏移量...};
io_submit 函数最终会调用内核函数 sys_io_submit 来实现提供异步 IO 操作,我们来分析 sys_io_submit 函数的实现:
asmlinkage longsys_io_submit(aio_context_t ctx_id, long nr,struct iocb __user **iocbpp){struct kioctx *ctx;long ret = 0;int i;...ctx = lookup_ioctx(ctx_id); // 通过异步IO上下文标识符获取异步IO上下文对象...for (i = 0; i < nr; i++) {struct iocb __user *user_iocb;struct iocb tmp;if (unlikely(__get_user(user_iocb, iocbpp+i))) {ret = -EFAULT;break;}// 从用户空间复制异步IO操作到内核空间if (unlikely(copy_from_user(&tmp, user_iocb, sizeof(tmp)))) {ret = -EFAULT;break;}// 调用 io_submit_one 函数提交异步IO操作ret = io_submit_one(ctx, user_iocb, &tmp);if (ret)break;}put_ioctx(ctx);return i ? i : ret;}
sys_io_submit 函数的实现比较简单,主要从用户空间复制异步 IO 操作信息到内核空间,然后调用 io_submit_one 函数提交异步 IO 操作。我们重点分析 io_submit_one 函数的实现:
int io_submit_one(struct kioctx *ctx,struct iocb __user *user_iocb,struct iocb *iocb){struct kiocb *req;struct file *file;ssize_t ret;char *buf;...file = fget(iocb->aio_fildes); // 通过文件句柄获取文件对象...req = aio_get_req(ctx); // 获取一个异步IO操作对象...req->ki_filp = file; // 要进行异步IO的文件对象req->ki_user_obj = user_iocb; // 指向用户空间的iocb对象req->ki_user_data = iocb->aio_data; // 设置用户自定义数据req->ki_pos = iocb->aio_offset; // 设置异步IO操作的文件偏移量buf = (char *)(unsigned long)iocb->aio_buf; // 要进行异步IO操作的数据缓冲区// 根据不同的异步IO操作类型来进行不同的处理switch (iocb->aio_lio_opcode) {case IOCB_CMD_PREAD: // 异步读操作...ret = -EINVAL;// 发起异步IO操作, 会根据不同的文件系统调用不同的函数:// 如ext3文件系统会调用 generic_file_aio_read 函数if (file->f_op->aio_read)ret = file->f_op->aio_read(req, buf, iocb->aio_nbytes, req->ki_pos);break;...}...// 异步IO操作或许会在调用 aio_read 时已经完成, 或者会被添加到IO请求队列中。// 所以, 如果异步IO操作被提交到IO请求队列中, 直接返回if (likely(-EIOCBQUEUED == ret)) return 0;aio_complete(req, ret, 0); // 如果IO操作已经完成, 调用 aio_complete 函数完成收尾工作return 0;}
上面代码已经对 io_submit_one 函数进行了详细的注释,这里总结一下 io_submit_one 函数主要完成的工作:
通过调用
fget函数获取文件句柄对应的文件对象。调用
aio_get_req函数获取一个类型为kiocb结构的异步 IO 操作对象,这个结构前面已经分析过。另外,aio_get_req函数还会把异步 IO 操作对象添加到异步 IO 上下文的active_reqs队列中。根据不同的异步 IO 操作类型来进行不同的处理,如
异步读操作会调用文件对象的aio_read方法来进行处理。不同的文件系统,其aio_read方法的实现不一样,如 Ext3 文件系统的aio_read方法会指向generic_file_aio_read函数。如果异步 IO 操作被添加到内核的 IO 请求队列中,那么就直接返回。否则就代表 IO 操作已经完成,那么就调用
aio_complete函数完成收尾工作。
io_submit_one 函数的操作过程如 图3 所示:
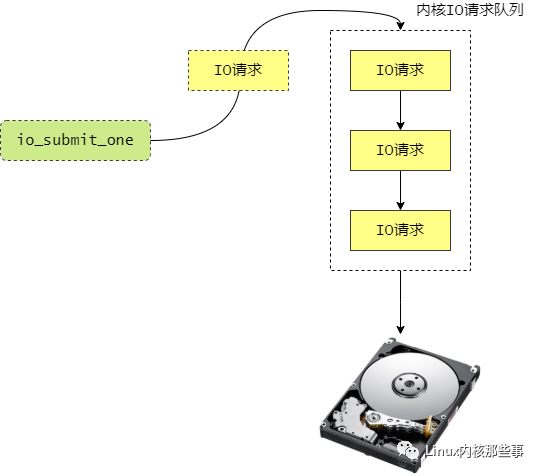
所以,io_submit_one 函数的主要任务就是向内核提交 IO 请求。
异步 IO 操作完成
当异步 IO 操作完成后,内核会调用 aio_complete 函数来把处理结果放进异步 IO 上下文的环形缓冲区 ring_info 中,我们来分析一下 aio_complete 函数的实现:
int aio_complete(struct kiocb *iocb, long res, long res2){struct kioctx *ctx = iocb->ki_ctx;struct aio_ring_info *info;struct aio_ring *ring;struct io_event *event;unsigned long flags;unsigned long tail;int ret;...info = &ctx->ring_info; // 环形缓冲区对象spin_lock_irqsave(&ctx->ctx_lock, flags); // 对异步IO上下文进行上锁ring = kmap_atomic(info->ring_pages[0], KM_IRQ1); // 对内存页进行虚拟内存地址映射tail = info->tail; // 环形缓冲区下一个空闲的位置event = aio_ring_event(info, tail, KM_IRQ0); // 从环形缓冲区获取空闲的位置保存结果tail = (tail + 1) % info->nr; // 更新下一个空闲的位置// 保存异步IO结果到环形缓冲区中event->obj = (u64)(unsigned long)iocb->ki_user_obj;event->data = iocb->ki_user_data;event->res = res;event->res2 = res2;...info->tail = tail;ring->tail = tail; // 更新环形缓冲区下一个空闲的位置put_aio_ring_event(event, KM_IRQ0); // 解除虚拟内存地址映射kunmap_atomic(ring, KM_IRQ1); // 解除虚拟内存地址映射// 释放异步IO对象ret = __aio_put_req(ctx, iocb);spin_unlock_irqrestore(&ctx->ctx_lock, flags);...return ret;}
aio_complete 函数的 iocb 参数是我们通过调用 io_submit_once 函数提交的异步 IO 对象,而参数 res 和 res2 是用内核进行 IO 操作完成后返回的结果。
aio_complete 函数的主要工作如下:
根据环形缓冲区的
tail指针获取一个空闲的io_event对象来保存 IO 操作的结果。对环形缓冲区的
tail指针进行加一操作,指向下一个空闲的位置。
当把异步 IO 操作的结果保存到环形缓冲区后,用户层就可以通过调用 io_getevents 函数来读取 IO 操作的结果,io_getevents 函数最终会调用 sys_io_getevents 函数。
我们来分析 sys_io_getevents 函数的实现:
asmlinkage long sys_io_getevents(aio_context_t ctx_id,long min_nr,long nr,struct io_event *events,struct timespec *timeout){struct kioctx *ioctx = lookup_ioctx(ctx_id);long ret = -EINVAL;...if (likely(NULL != ioctx)) {// 调用 read_events 函数读取IO操作的结果ret = read_events(ioctx, min_nr, nr, events, timeout);put_ioctx(ioctx);}return ret;}
从上面的代码可以看出,sys_io_getevents 函数主要调用 read_events 函数来读取异步 IO 操作的结果,我们接着分析 read_events 函数:
static int read_events(struct kioctx *ctx,long min_nr, long nr,struct io_event *event,struct timespec *timeout){long start_jiffies = jiffies;struct task_struct *tsk = current;DECLARE_WAITQUEUE(wait, tsk);int ret;int i = 0;struct io_event ent;struct timeout to;memset(&ent, 0, sizeof(ent));ret = 0;while (likely(i < nr)) {ret = aio_read_evt(ctx, &ent); // 从环形缓冲区中读取一个IO处理结果if (unlikely(ret <= 0)) // 如果环形缓冲区没有IO处理结果, 退出循环break;ret = -EFAULT;// 把IO处理结果复制到用户空间if (unlikely(copy_to_user(event, &ent, sizeof(ent)))) {break;}ret = 0;event++;i++;}if (min_nr <= i)return i;if (ret)return ret;...}
read_events 函数主要还是调用 aio_read_evt 函数来从环形缓冲区中读取异步 IO 操作的结果,如果读取成功,就把结果复制到用户空间中。
aio_read_evt 函数是从环形缓冲区中读取异步 IO 操作的结果,其实现如下:
static int aio_read_evt(struct kioctx *ioctx, struct io_event *ent){struct aio_ring_info *info = &ioctx->ring_info;struct aio_ring *ring;unsigned long head;int ret = 0;ring = kmap_atomic(info->ring_pages[0], KM_USER0);// 如果环形缓冲区的head指针与tail指针相等, 代表环形缓冲区为空, 所以直接返回if (ring->head == ring->tail)goto out;spin_lock(&info->ring_lock);head = ring->head % info->nr;if (head != ring->tail) {// 根据环形缓冲区的head指针从环形缓冲区中读取结果struct io_event *evp = aio_ring_event(info, head, KM_USER1);*ent = *evp; // 将结果保存到ent参数中head = (head + 1) % info->nr; // 移动环形缓冲区的head指针到下一个位置ring->head = head; // 保存环形缓冲区的head指针ret = 1;put_aio_ring_event(evp, KM_USER1);}spin_unlock(&info->ring_lock);out:kunmap_atomic(ring, KM_USER0);return ret;}
aio_read_evt 函数的主要工作就是判断环形缓冲区是否为空,如果不为空就从环形缓冲区中读取异步 IO 操作的结果,并且保存到参数 ent 中,并且移动环形缓冲区的 head 指针到下一个位置。
总结
本文主要分析了 Linux 原生 AIO 的实现,但为了不陷入太多的实现细节中,本文并没有涉及到磁盘 IO 相关的知识点。然而磁盘 IO 也是 AIO 实现中不可或缺的一部分,所以有兴趣的朋友可以继续通过阅读 Linux 的源码来分析其实现原理。