
ClickHouse在腾讯游戏营销效果分析中的探索实践
导读:营销活动作为游戏运营的一种重要手段,可以灵活快速的配合游戏各个运营节点的需要而推出,不受游戏版本节奏的影响。而面对数量众多的营销活动和不同的业务诉求,如何在海量日志中评价营销的效果是一个典型的多维分析问题,本次分享主要介绍腾讯游戏营销效果分析的一些概况以及ClickHouse的应用实践情况。通过实践表明,ClickHouse完美解决了查询瓶颈,20亿行以下的数据量级查询,90%可以在亚秒(1秒内)给到结果。
营销活动在游戏之外配合热点事件和用户深入交流,是拉回流、促活跃的重要手段。那么,大量营销活动如何快速进行效果分析,得到准确的营销效果?
我们先来看一个具体的营销行为路径:
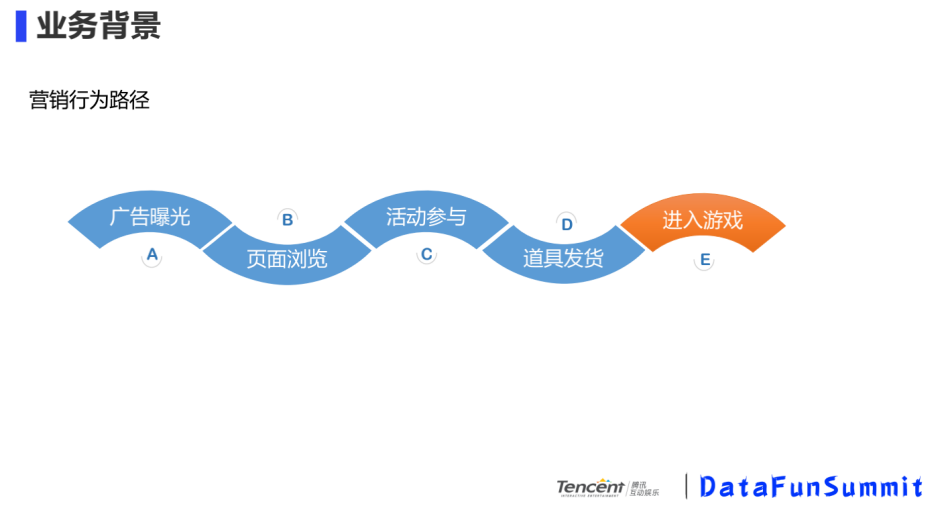
游戏玩家被营销活动投放的广告吸引过来,到营销活动的页面浏览,浏览的同时,如果玩家对营销活动感兴趣,会进行下一步的活动参与,参与达到条件后,会根据营销活动的规则,获得道具或者是装备的发放、领取,之后游戏玩家进入游戏。
对于上述场景,用户的每个行为阶段都会产生不同的指标,运营方往往有很多的分析诉求:
运营A:我的活动刚刚发布了,能不能看下现在实时的曝光和参与情况?
运营B:我的活动投入了一个新出的稀有道具,能看到这个道具的发放情况并提出用户包吗?
运营C:我在某投放平台买了广告位,能分析下这个广告位带给我的效果情况吗?
运营D:这次活动主要目的是拉回流,能看看我到底给游戏拉了多少回流吗?
运营E:这次活动是精细化挖掘推荐,能看看特定大R人群的参与情况吗?
以上的诉求总结下来就是多指标、多维度、时效性、去重用户包。
技术难点:面对众多的营销活动,每个营销活动周期都不一样,维度众多,在这个基础上还会有多种指标,如何在海量日志下做多周期、多维度的去重分析?我们来看看我们的技术选型及演进。
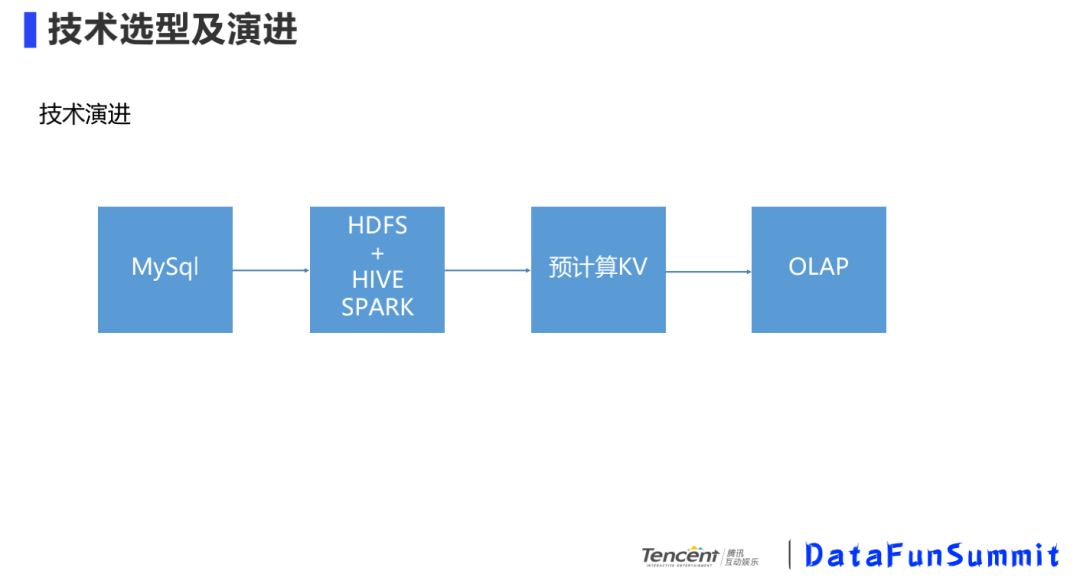
技术演进是每个公司都有的过程,一开始数据量较小,直接在DB数据库中就可以满足分析需求;随着数据规模越来越大,要借助hdfs、hive/spark的一些框架;再往后,随着实时性的要求越来越高,需要实时计算框架,对维度做预计算;随着维度爆炸,预计算就不太适用了,分析路径比较死,增加一个维度得改模型,这时就需要为OLAP专门量身打造分析型数据库。
① Mysql
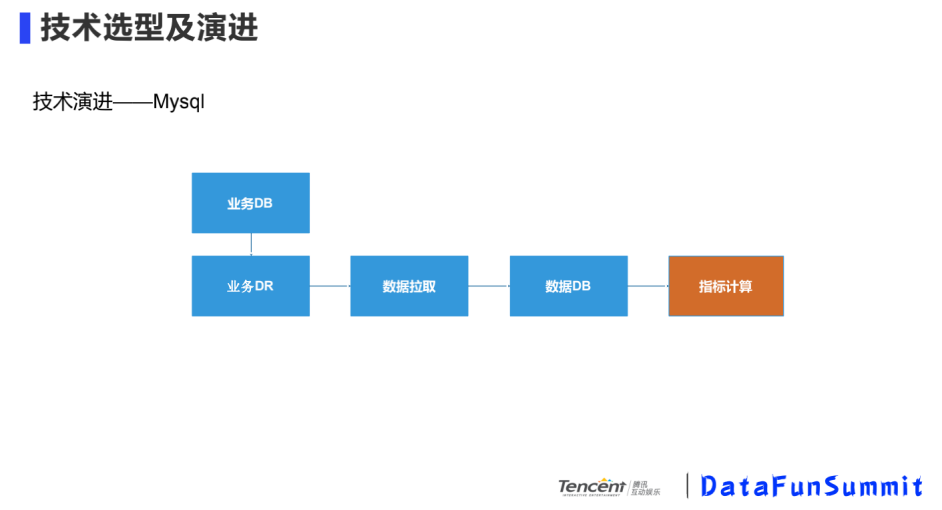
优点:直接从业务DB拉取数据,比较简单
缺点:支持数据规模小,和业务之间有耦合
② HDFS&HIVE/SPARK
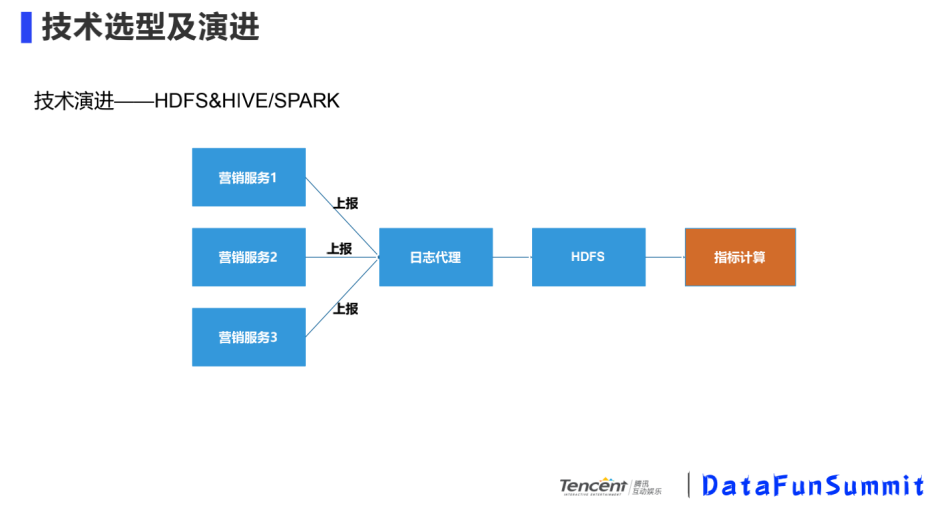
基于DB分析的缺点,我们支持了大规模数据和业务做解耦,选用HDFS&HIVE/SPARK的方案。我们统一了营销服务日志模型,当接到上报日志后,上传给HDFS。这个方案支持的数据量比较大,缺点是计算的速度比较慢,适用于T-1的计算效果。
③ 预计算KV
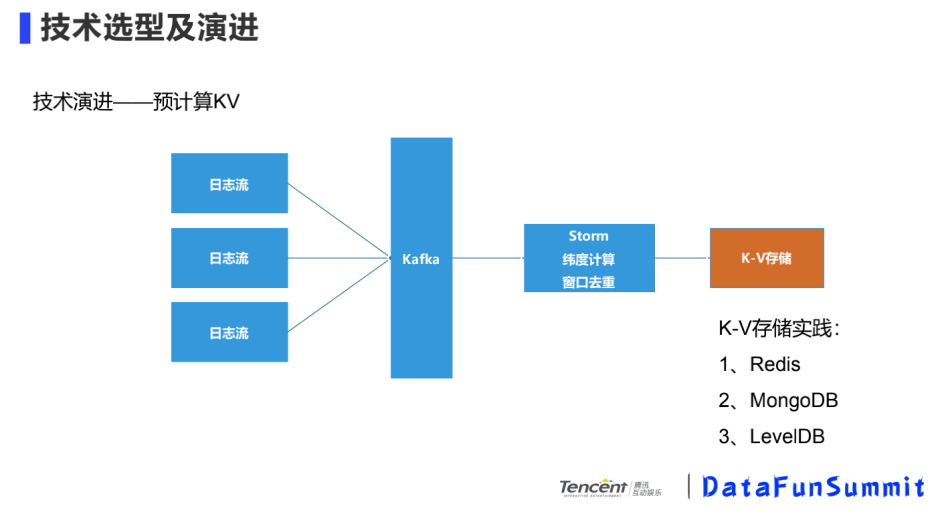
基于计算慢的问题,我们在日志流层面引入了实时计算框架,日志流经过Kafka,入到Storm,对预设的维度进行预计算,计算的结果存储到K-V数据库中,查询时去K-V库中查询。这里基于业务场景,想要快速的导出用户包,用文件数据库存储更方便,最大的缺点是新增维度要做一些处理,维度爆炸到一定程度,维护成本较高。
④ OLAP
面对纬度爆炸问题,我们开始调研OLAP。
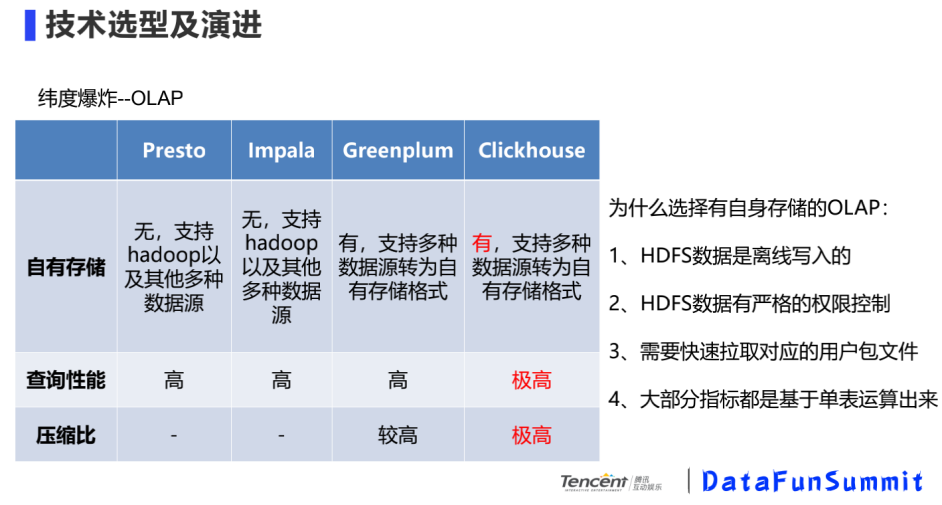
为什么选择有自身存储的OLAP?
HDFS数据是离线写入的
HDFS数据由严格的权限控制
需要快速拉取对应的用户包文件
大部分指标是基于单标运算出来
根据业务场景,对比上诉三个性能,最看重自有存储。因为在一张大宽表下,查询性能很重要。
1. ClickHouse介绍
ClickHouse是Yandex开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快100-1000倍。
ClickHouse的性能超过了目前市场上可比的面向列的DBMS,每台服务器每秒可处理数亿至十亿行的数据。
OLAP的特点:
读多于写:不同于事务处理(OLTP)的场景,数据分析(OLAP)场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。
大宽表:读大量行但是少量列,结果集较小。在OLAP场景中,通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。对数据分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。而聚合计算的结果集相比于动辄数十亿的原始数据,也明显小得多。
数据批量写入:OLTP类业务数据不更新或少更新,对于延时要求更高,要避免让客户等待造成业务损失;而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐量。
无需事务,数据一致性要求低:OLAP类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。
灵活多变,不适合预先建模:分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。
从自身的场景出发,我们关注到的ClickHouse优缺点:

对于业务场景中去重类的聚合查询,最终的查询结果落到一台机器上,对单机性能影响比较大。后面会具体讲到这些缺点的解决方案。
我们的系统架构如下:
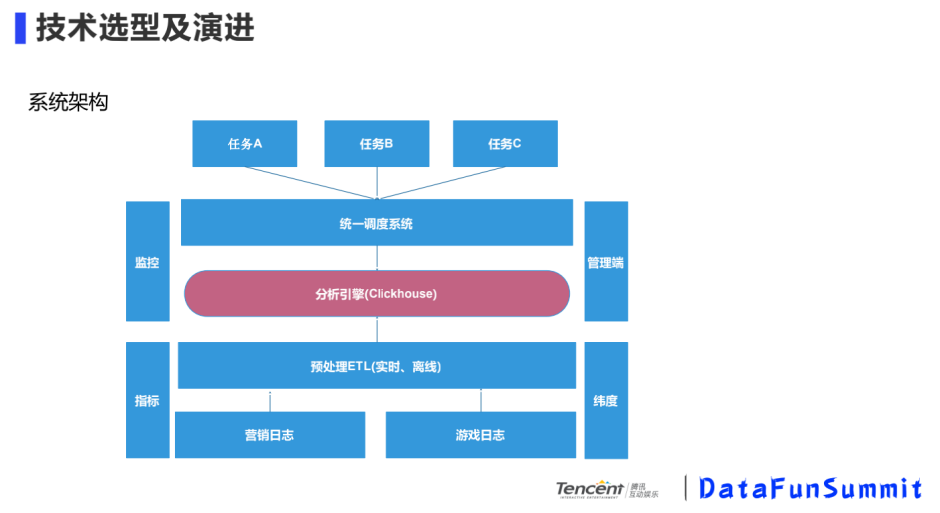
使用定位:高效的计算引擎
统一调度:缓存结果、限流、对一些很大的查询逻辑加速
预处理ETL:压缩日志、对日志清洗、对热点数据逻辑分片
2. CK实践优化
① CK实践优化-集群限流

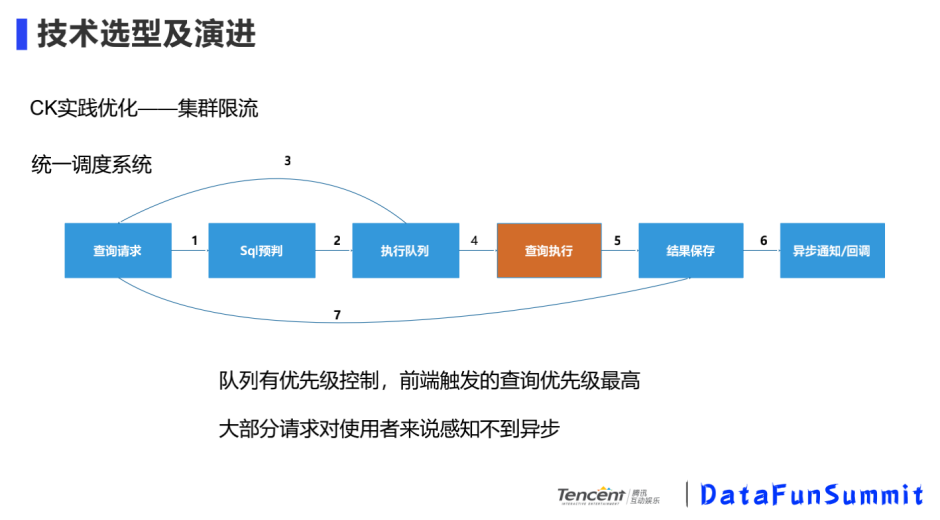
当接到SQL查询请求,我们做了一个SQL预判,将SQL放进执行队列里,队列里有优先级控制,前端触发的查询优先级最高,大部分请求对使用者来说感知不到异步,前端会做loading几秒钟,一般是可以接受,感知不到这个时间。
② CK实践优化-BadSQL检测

不是说SQL本身语法或者逻辑不正确,而是指一些很大的SQL,比如说查询的数据的时间段间隔很大,数据量较多,查询可能会对集群安全性造成影响,会做些预判。
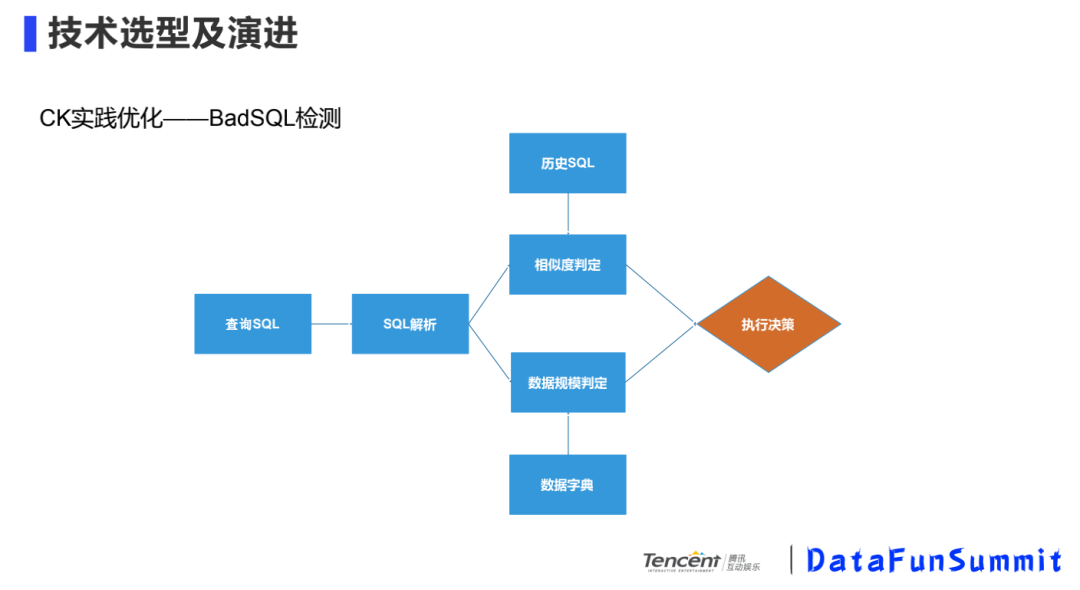
我们会对查询SQL进行解析,然后和历史SQL进行对比,看一下之前的SQL是怎么样的,做一个相似度的判断,结合数据字典,判断扫描数据的规模。如果判断这条SQL查询的数据规模很大,会把一次查询分成很多次查询,将结果聚合起来得到最终结果。我们也会对一些较大的SQL做一些事后分析,对以后查询提供历史的SQL。
③ CK实践优化-数据预处理

CK本身有写入并发不高的缺点,而且在营销活动的场景中,热点的营销活动数据会有倾斜现象,如何避免热点数据倾斜问题,需要在写入的时候做一些预处理。
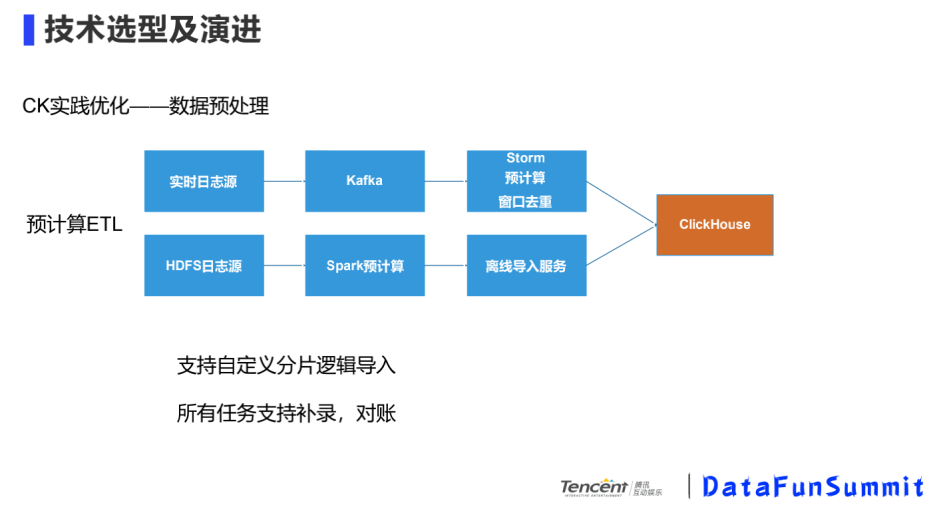
我们的业务场景有实时和离线的HDFS数据源,实时的数据源经过Kafka,写入到Storm中做一些预计算,去重工作;HDFS离线数据源,通过Spark做离线的预计算,在写入时通过配置Hash Key将数据写入到相应的分片中。

目前营销活动产生的数据量压缩前50+TB,效果指标100+,效果维度1000+,请求耗时85%以上都小于800ms,经过历史统计自定义去重比Hive提速500倍左右。
1. 热点数据的处理

热点数据是数据组件通用的问题,对数据写入时进行预分片,保证数据分散到每个计算node上,对事先分片的数据进行分批查询,一个shard一个shard的查询。
对一些热点数据也可以采用单独部署的方式,避免受一些其他业务的影响。
2. zookeeper的使用

对于存储性的组件,经过优化,正在逐步对zookeeper降低依赖程度:
自己保证数据一致性,不用走zookeeper,特别是临时性的需求
ck集群对zk使用是表级别的,表的数量扩张,znode数量也会急剧的扩张,所以要控制集群中表的数量
搭建zk集群时,使用性能较好的机器
快照及时清理
搭建多zk集群,每一个zk集群指定不同的表,减少zk的压力
3. 单机瓶颈

数据分析到最后一步聚合、去重,导出用户包最终会落到一台机器上,这对一台机器的压力就比较大,要提升硬件,增加内存,cpu使用限制的配置,不然有可能将集群崩溃或者某个节点挂掉。
根据业务逻辑进行拆分表,分shard根据不同的节点查询。
4. 数据迁移


促进ck在更多地业务场景落地,更多业务的接入:比如用户的行为分析,实时数仓,实时报表,ck实时明细类报表的引入,能够使得用户更加实时,方便地进行报表分析。
更加完善的周边工具建设:比如说ck支持更多的数据源,可以从多个数据源导入到ck中或者从ck中一键导出到其他数据源;再比如说安全、运维的一些工具建设,能更好的支持运维。
容器化部署:容器化部署更高拥有更好的弹性伸缩能力,也能和其他的服务进行混合部署节省成本。此外,有写业务的导入数据量非常巨大。但是其实查询量并不大,就是因为读写不分离,这时导入的数据量反而决定了集群的规模。因此希望将读写进行分离,写入部分通过容器化技术临时构建集群来完成。
Q:在扩容时数据如何做Rebalance?
A:目前ck的最大痛点就是扩容/缩容后的数据无法自平衡,如果说数据是无状态的,和业务数据逻辑无关的,直接从shard级别复制就好。如果说是业务逻辑有关的热点数据,比如用户ID切成100个分片,10台机器扩容到20台,100个分片如何分布,目前基本上处于原始的一个阶段。有逻辑的数据,看一下之前的数据是怎样分布的,逻辑的Rebalance,用remote函数,如果数据量大的利用clickhouse-copier工具帮助运维。
Q:Clickhouse的结果是怎么保存起来的?
A:做缓存的有一定要求,如果数据集在一定规模以下,就可以直接缓存在redis中,如果说是取包的操作,这个是没办法缓存的,后台计算好load到一台机器上,去什么地方拉取就可以。