
Meta最新文生图Emu技术,quality-tuning对齐人类,对标DALL·E 3
【新智元导读】可以说,Meta刚刚发布的Emu,在性能上毫不逊色于DALL·E 3!而Emu取得优异性能背后的原因是「质量调整」。
前几天,OpenAI刚刚推出DALL·E 3,文生图再次上升到一个新阶段,甚至有网友纷纷表示R.I.P. Midjourney。
在28号的Meta Connect大会上,小扎也推出了自家的人工智能图像生成模型——Emu(Expressive Media Universe)。
Emu最大的特点是,只用简单的文字,5秒即生图片。
比如:「一只在彩虹森林中的神仙猫咪」。

「徒步旅行者和北极熊」。

「水下的航天员」。

「在花丛中的一位女士」。

「如果恐龙是一只猫咪」。

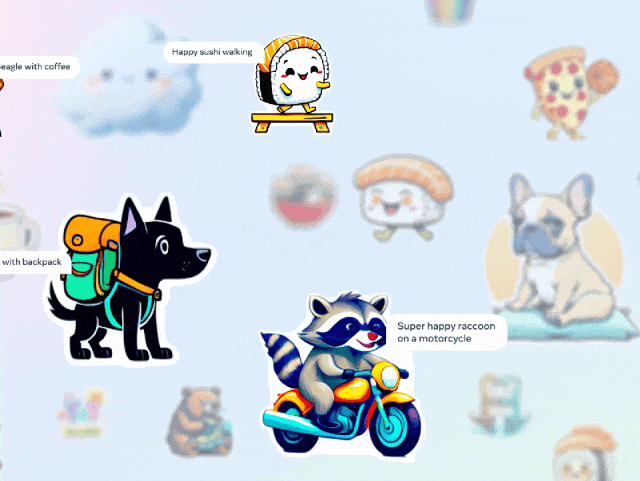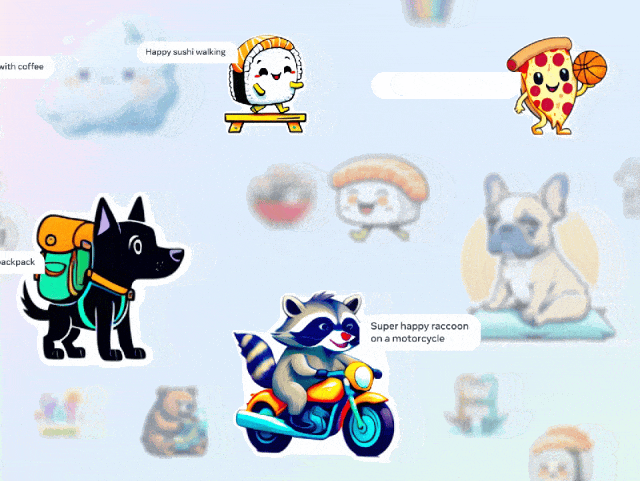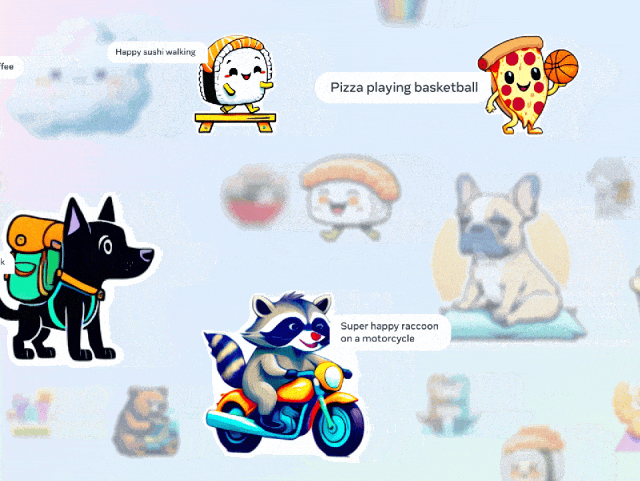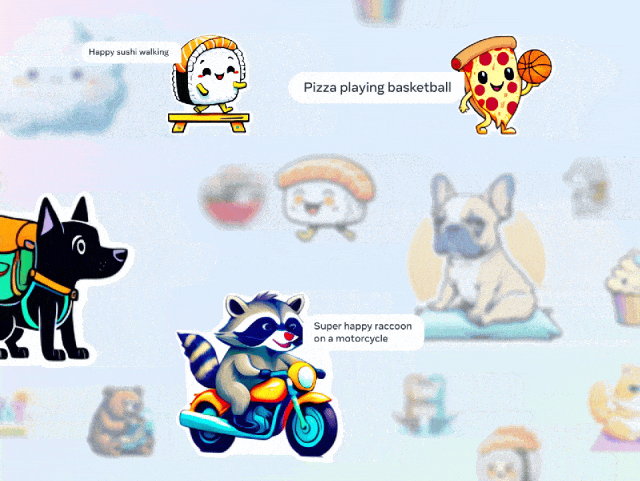
与其他文生图模型相比,Emu最有趣的是,可以一键生成表情包。
当你正和人聊天时,不用绞尽脑汁去翻找一个合适的表情包了。
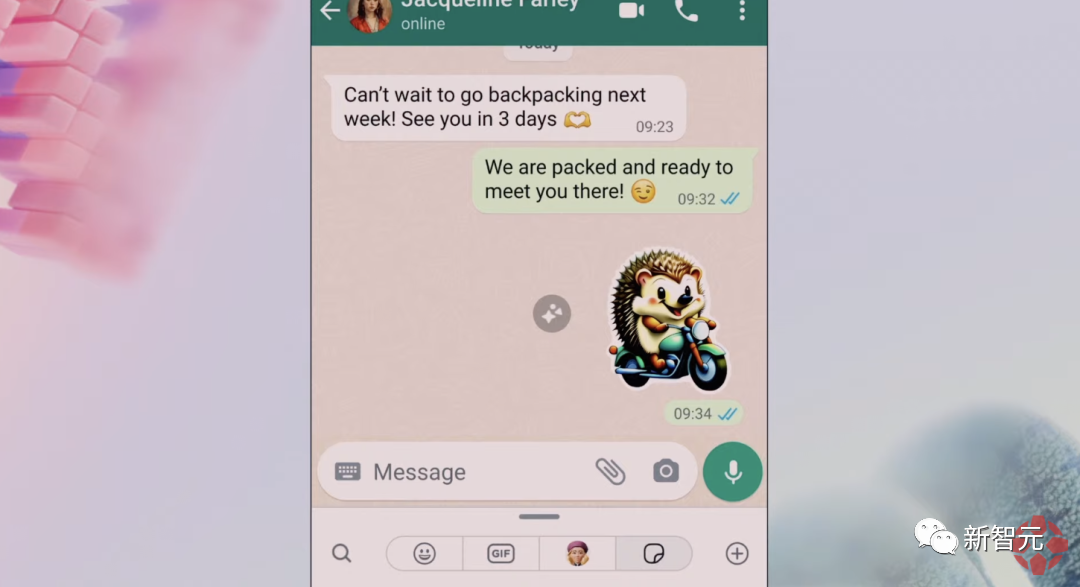
比如,和朋友约好了背包旅行,想要发一个生动的准备去旅行的表情包。
「一只快乐的刺猬骑着摩托车」
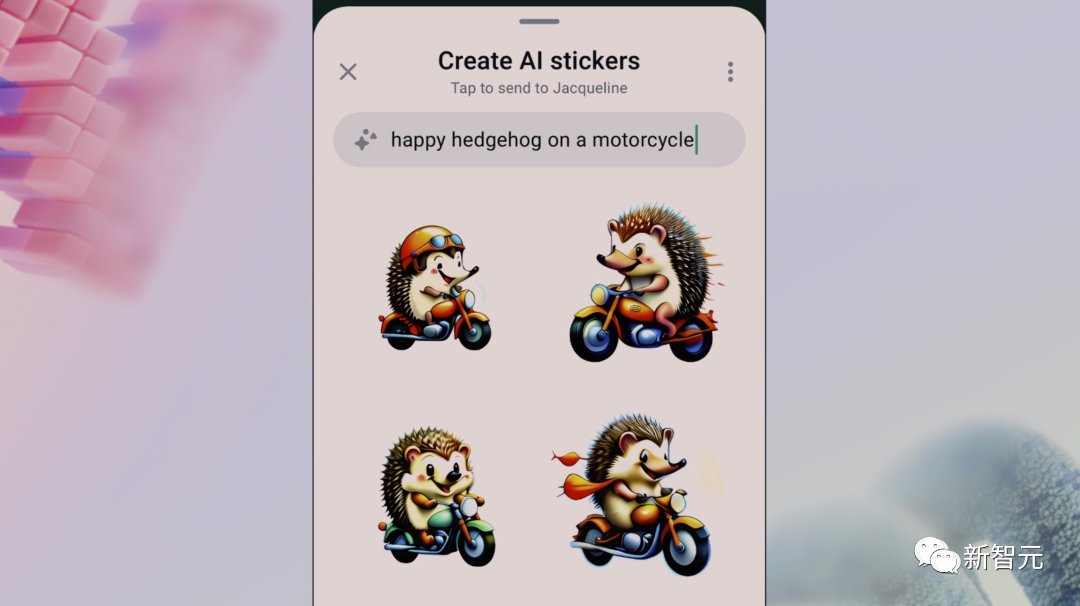
选择自己喜欢的一个,发送。
当然了,你可以生成各种各样的表情包,仅需要简单几个词。
很快,任何人都可以在Ins中进行图像编辑——重换风格和背景,背后就是由Emu和分割模型SAM加持。
重换风格,可以根据你所描述的风格,重构想像输出图片。
如下, 输入「水彩」,你的照片就立刻变成水彩画了。

或者,把扎克伯格小时候的照片变成「摇滚朋克风格」。

又或者给金毛换一个「长头发」,就得到了:

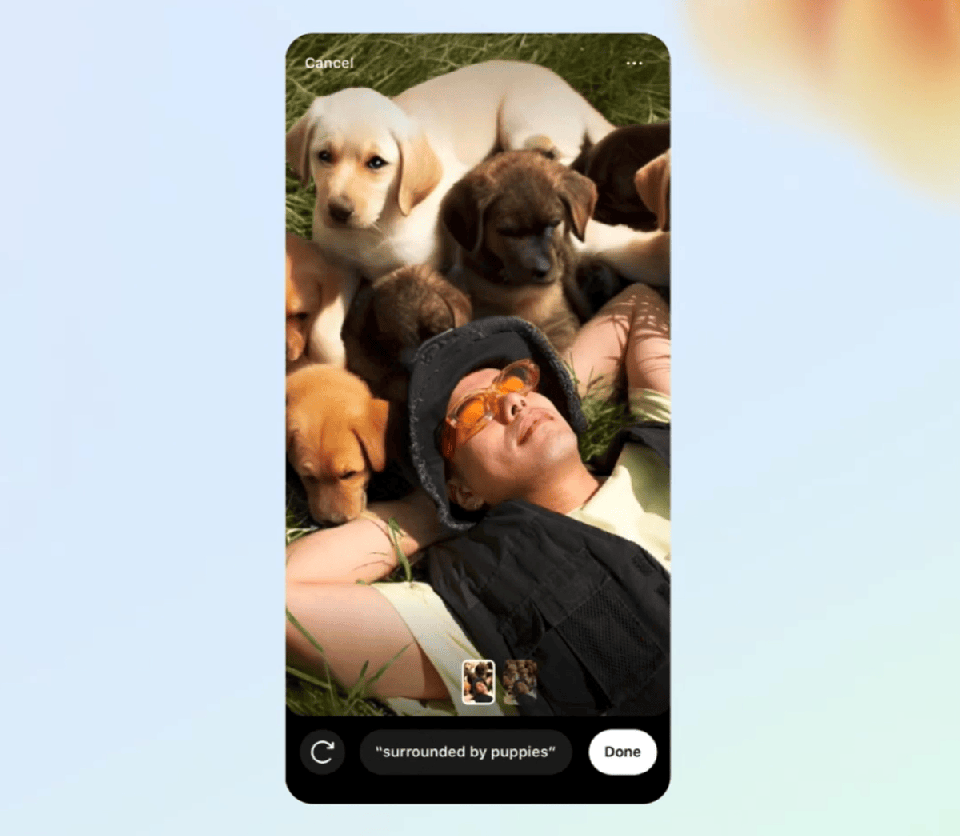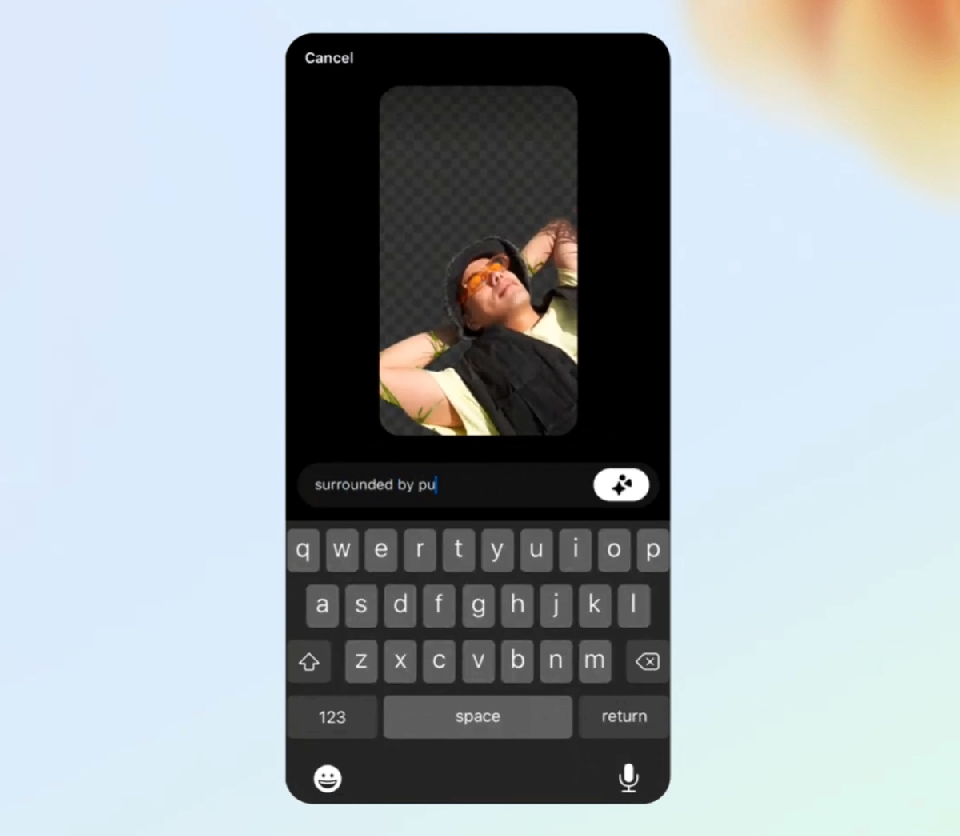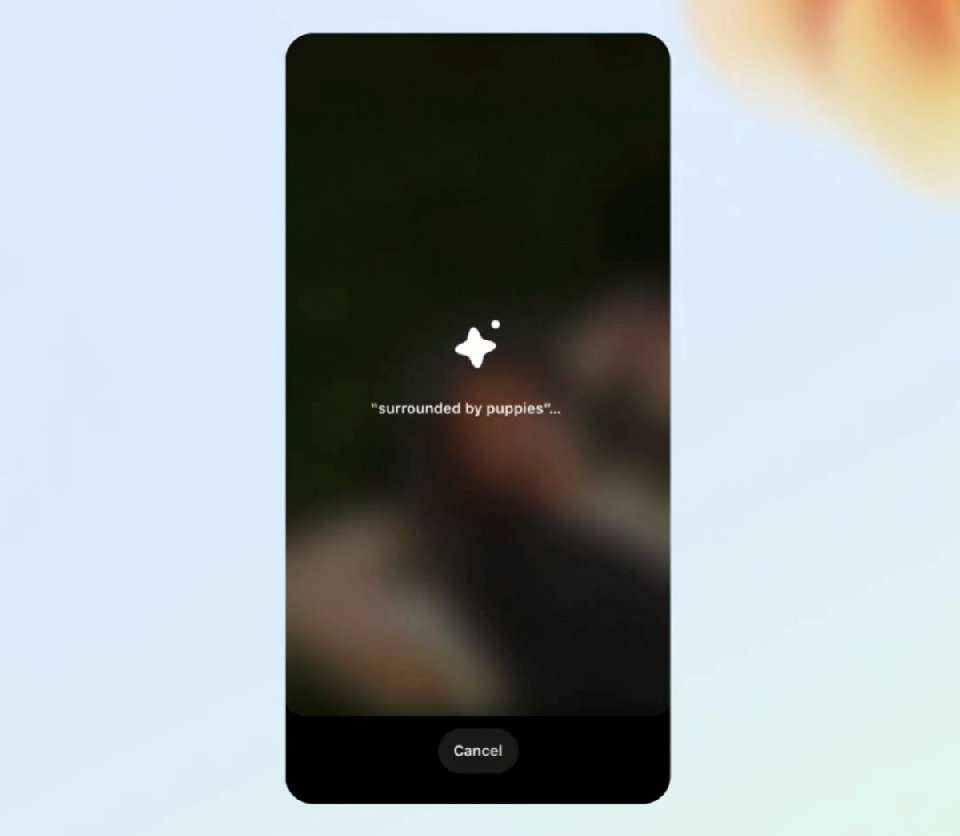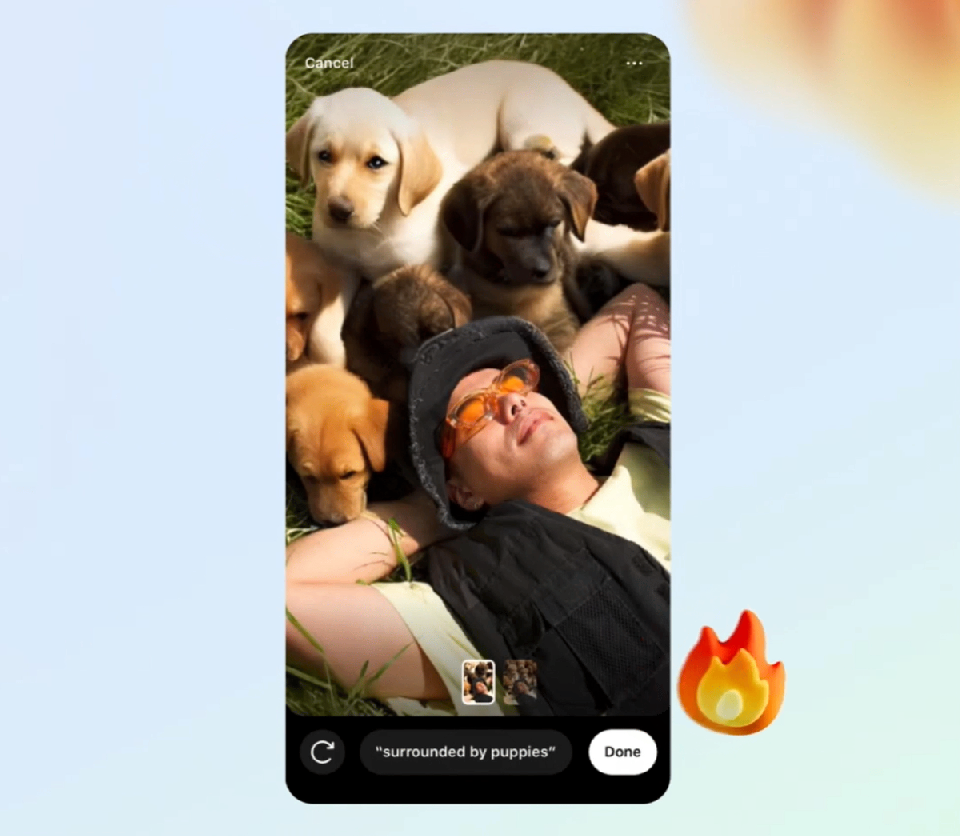
你甚至可以为图片更换背景。
找到一张自己躺在草坪中的照片,输入「被小狗包围」,一群可爱的小狗就伴你左右了。
又或者,家庭合照中,背景也可以随意切换。

Emu在发布会上可算是风光了一把,但其实在现场演示的前一天,Meta就在arXiv更新了Emu模型的论文。

论文地址:https://arxiv.org/abs/2309.15807
在这篇论文中,Meta介绍了Emu的训练方法:质量调整(quality-tuning),一种有监督的微调。
质量调整解决了在利用网络规模的图像-文本训练文本-图像模型时,生成高度美观的图像面临的挑战:美学对齐。
通过质量调整,可以有效指导预训练模型专门生成具有高度视觉吸引力的图像,同时保持视觉概念的通用性。
研究人员还将其泛用到其他模型架构中,如pixel diffusion和masked generative transformer,证明了质量调整方法的通用性。
在知识学习阶段,目标是获得从文本生成几乎任何内容的能力,这通常需要在数以亿计的图像-文本对上进行预训练。
而在质量学习阶段,模型将被限制输出高质量和美观的图片。
Meta研究人员将以提高质量和促进审美一致性为目的的微调过程称为质量调整。

经质量调整的Emu生成的图像
但质量调整有三个关键:
(1)微调数据集可以小得出奇,大约只有几千张图片;
(2)数据集的质量非常高,这使得数据整理难以完全自动化,需要人工标注;
(3)即使微调数据集很小,质量调整不仅能显著提高生成图片的美观度,而且不会牺牲通用性,因为通用性是根据输入提示的忠实度来衡量的。
整个质量调整过程有以下几个步骤:
潜在扩散架构
研究人员设计了一种可输出1024 X1024分辨率图像的潜在扩散模型。遵循标准的潜在扩散架构设计,模型有一个自动编码器(AE)将图像编码为潜在嵌入,并有一个U-Net学习去噪过程。
研究发现,常用的4通道自动编码器(AE-4)架构由于压缩率高,往往会导致所构建图像的细节丢失。
而这一问题在小物体中尤为明显。
为了进一步提高重建性能,研究人员使用了对抗性损失,并使用傅里叶特征变换对RGB图像进行了不可学习的预处理,将输入通道维度从3(RGB)提升到更高维度,以更好地捕捉精细结构。
用于不同通道尺寸的自动编码器的定性结果见下图。

此外,研究人员还增加了每个阶段的通道大小和堆叠残差块数量,以提高模型容量。
并且,此研究使用CLIP ViT-L和T5-XXL的文本嵌入作为文本条件。
预训练
研究人员策划了一个由11亿张图像组成的大型内部预训练数据集来训练模型,训练过程中模型的分辨率逐步提高。
在预训练的最后阶段,研究人员还使用了0.02的噪声偏移,这有利于生成高对比度的图像,从而提高生成图像的美感。
构建高质量对齐数据
从最初的数十亿张图片开始,使用一系列自动过滤器将图片数量减少到几亿张。
这些过滤器包括但不限于去除攻击性内容、美学分数过滤器、光学字符识别(OCR)字数过滤器(用于去除覆盖过多文字的图片)以及 CLIP 分数过滤器(用于去除图片与文字对齐度较差的样本)。
然后,通过图像大小和纵横比进行额外的自动过滤。
并且,为了平衡来自不同领域和类别的图片,研究人员利用视觉概念分类来获取特定领域的图片(如肖像、食物、动物、风景、汽车等)。
最后,通过基于专有信号(如点赞数)的额外质量过滤,这样可以将数据进一步减少到200K Human Filtering。
接下来,将数据集分两个阶段进行人工过滤,只保留极具美感的图片。
在第一阶段,训练通用注释器将图片库缩减到20K张。这一阶段的主要目标是优化召回率,确保排除通过自动过滤的中低质量图片。
在第二阶段,聘请精通摄影原理的专业注释员,筛选出高审美质量的图片,如下图。

这一阶段的重点是优化精确度,即只选择最好的图片。数据集遵循高质量摄影的基本原则,在各种风格的图像中普遍获得更具美感的图像,并通过人工评估进行验证。
质量调整
将视觉效果极佳的图像视为所有图像的子集,这些图像具有一些共同的统计数据。
研究人员使用64个小批量数据集对预训练模型进行微调。
在此阶段使用0.1的噪声偏移。但需要注意的是,尽早停止微调非常重要,因为在小数据集上微调时间过长会导致明显的过拟合,降低视觉概念的通用性。
但微调迭代次数不能超过5K,这个总迭代次数是根据经验确定的。
研究人员将经过质量调整的Emu模型与预先训练的模型进行比较。
质量调整前后的随机定性测试结果见下图。

可以看到非写实图像也具有很高的美感,这验证研究提出的假设:在质量调整数据集中遵循某些摄影原则,可以提高各种风格的美感。

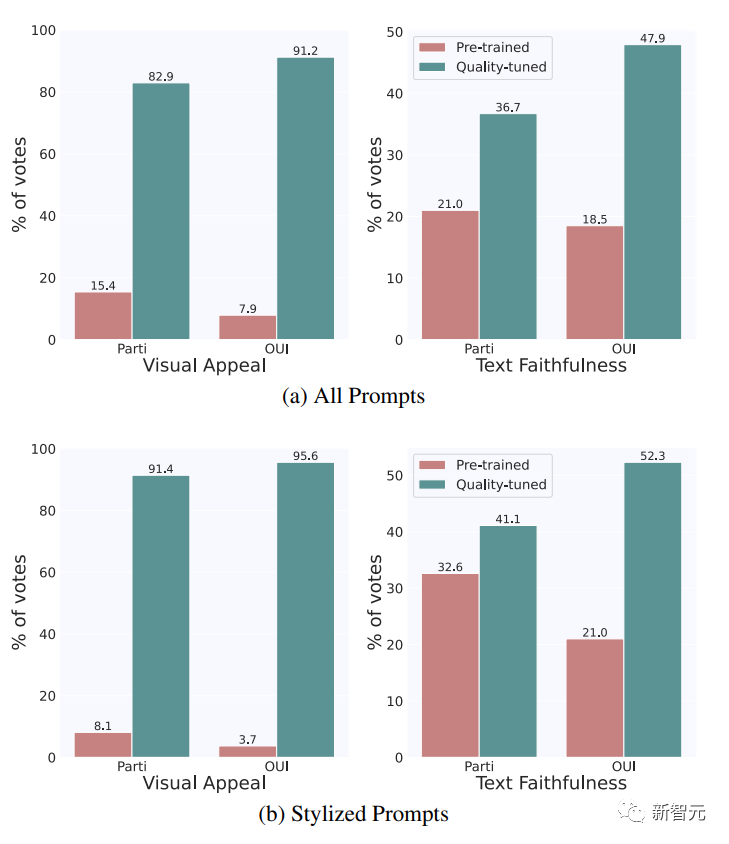
从数量上看,经过质量调整后,Emu在视觉吸引力和文本可信度方面都有显著优势。
具体来说,在Par-tiPrompts和OUl Prompts上,分别有 82.9% 和 91.2% 的视觉吸引力以及 36.7% 和 47.9% 的文本忠实度首选Emu。
相比之下,在视觉吸引力方面,预训练模型分别只有15.4% 和 7.9%的时间受到青睐,而在文字忠实性方面,PartiPrompts和OUl Prompts分别有 21.0% 和 18.5% 的时间受到青睐。
其余案例的结果均为平局。从这两组涵盖不同领域和类别的大量评估数据中视觉概念的通用性没有下降。
相反,这些改进广泛适用于各种风格。
SoTA 背景下的视觉吸引力
为了将Emu生成的图像的视觉吸引力与当前最先进的技术进行比较,研究人员将Emu与SDXLV1.0进行了比较。
可以看到,Emu比 SDXLv1.0 的视觉吸引力高出很多,包括在风格化(非写实)提示上。
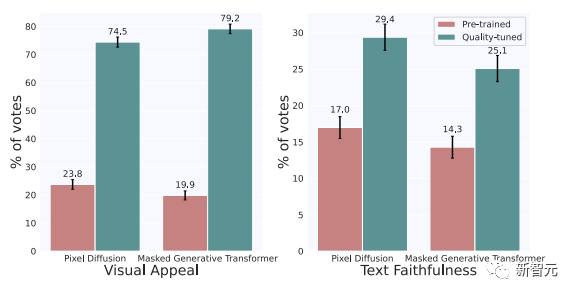
并且,Meta证实了质量调整也可以改进其他流行的架构,如pixel diffusion和masked generative transformer。
研究人员从头开始重新实现和训练一个pixel diffusion和masked generative transformer,然后在 2000 张图像上对它们进行质量调整。
之后,研究人员在1/3随机抽样的PartiPrompts上对这两种经过质量调整的模型进行了评估。
如下图所示,经过质量调整后,两种架构在视觉吸引力和文本忠实度指标上都有显著改善。
消融研究
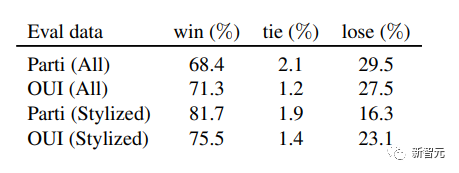
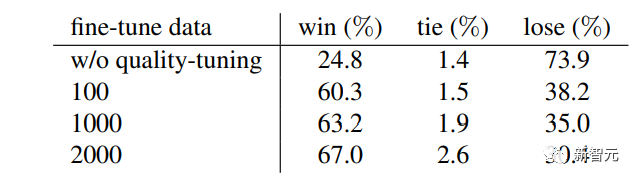
最后,Meta对微调数据集进行了消融研究,重点关注视觉吸引力,主要对数据集大小的影响进行研究。
下表中报告了在不同大小的随机抽样子集上进行的质量微调的结果,包括100、1000和2000的大小。
可以看到,即使只有100个微调图像,模型也能够被引导生成视觉上吸引人的图像。
与SDXL相比,微调后的胜率从24.8%跃升至了60%。
https://arxiv.org/abs/2309.15807
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~! 附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!