
快问快答!
之前图解了两篇 Redis 持久化技术,分别是:
有些读者在评论区里提了一些问题,然后这些问题是他们自己延伸想出来的,我觉得问题具有代表性,就在这篇回答下这些问题。
AOF 日志篇的问题
问题一

这位读者的意思是,他认为 Redis 是单线程的,但是他在文章里看到 Redis 在 AOF 重写日志的时候,会创建子进程来重写日志,他就觉得不对劲。
Redis 确实是以单线程架构被大家所知,但是这个单线程指的是「从网络 IO 处理到实际的读写命令处理」都是由单个线程完成的,并不是说整个 Redis 里只有一个主线程。
有些命令操作可以用后台子进程执行(比如快照生成、AOF 重写)。
严格意义上说的话,Redis 4.0 之后并不是单线程架构了,除了主线程外,它也有后台线程在处理一些耗时比较长的操作,例如清理脏数据、无用连接的释放、大 Key 的删除等等。
你可能听到 Redis 6.0 版本支持了多线程技术,不过这个并不是指多个线程同时在处理读写命令,而是使用多线程来处理 Socket 的读写,最终执行读写命令的过程还是只在主线程里。
之所以采用多线程 IO 是因为Redis 处理请求时,网络处理经常是瓶颈,通过多个 IO 线程并行处理网络操作,可以提升整体处理性能。
那为什么处理操作命令的过程只在单线程里呢?
因为 Redis 不存在 CPU 成为瓶颈的情况,主要受限于内存和网络。
而且使用单线程的好处在于,可维护性高、实现简单。
如果采用多线程模型来处理读写命令,虽然能提升并发性能,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
关于 Redis 单线程的问题就介绍这么多,后续在写一篇详细点的文章。
问题二

这个读者的意思是,AOF 重写缓冲区占满了会发生什么?
其实重写缓冲区并不是一个很大块的内存空间,而是一些内存块的链表,每个内存块的大小为 10MB,这样就组成了一个重写缓冲区。
AOF 重写缓冲区块的数据结构如下:
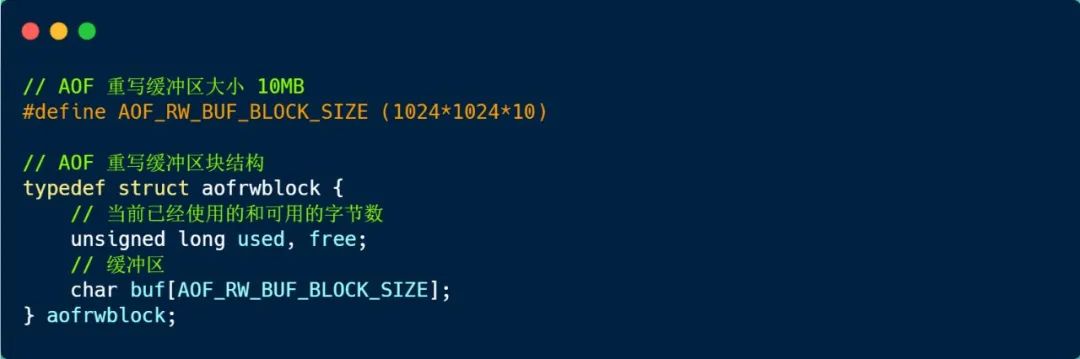
细心的同学可能发现,aofrwblock 结构里没有 prev 和 next 指针呀,那怎么组成链表的呢?
Redis 是这样做的,用 listNode 结构包裹着 aofrwblock 结构,会将 listNode 结构里的 value 指针指向 aofrwblock。

接下来,我们看看 Redis 是如何使用申请和使用 aofrwblock 结构的。
下面这个函数,就是将操作命令追加到 AOF 重写缓冲区的实现:
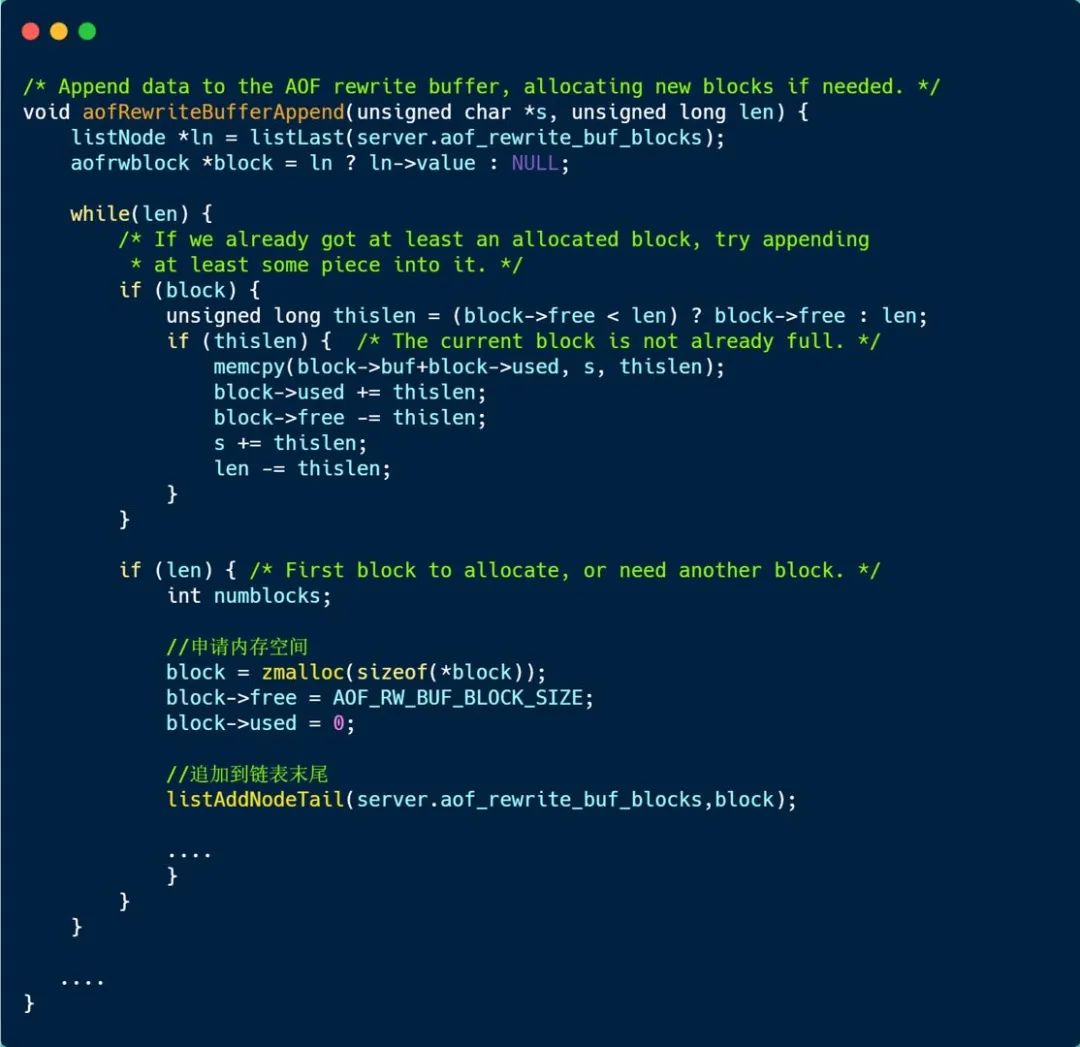
可以看到,当一个内存块 10MB 大小用完后,就会通过 zmalloc() 在申请一个内存块,并将其追加到链表的末尾。
如果遇到系统内存紧张,导致申请内存失败时会发生什么呢?
我们直接看下 zmalloc() 的实现:
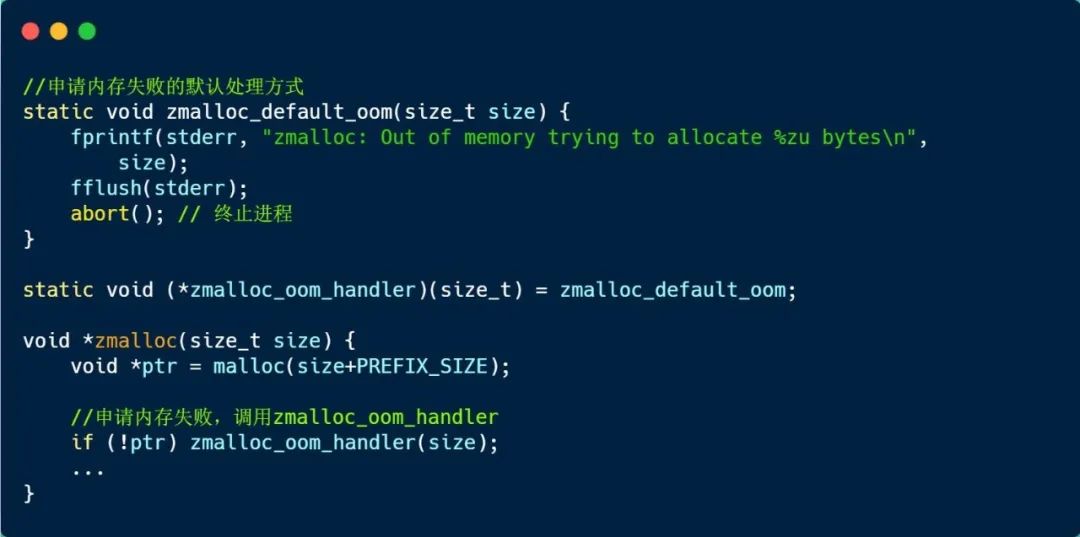
可以看到,当 zmalloc() 申请内存失败的时候,就会打印一条日志,并调用 abort() 终止 Redis 进程。
现在就可以回答读者的问题了,重写缓冲区占满了会发生什么?
重写缓冲区是边用边申请的,也就是说是动态申请的,并不是一次性就分配好的。
如果一直分配内存,当耗尽系统的内存资源的时候,zmalloc() 就无法申请成功,就会打印一条日志,随后就 Redis 进程就退出了。
RDB 日志篇的问题
问题一

这位读者的意思是,为什么执行 bgsave 命令来生成快照文件的时候,是创建子进程而不是线程。
AOF 重写日志和 bgsave 快照生成都是通过创建子进程来负责的,这里使用子进程而不是线程,是因为如果是使用线程,多线程之间会共享内存,那么在修改共享内存数据的时候,需要通过加锁来保证数据的安全,而这样就会降低性能。
而使用子进程,创建子进程时,父子进程是共享内存数据的,不过这个共享的内存只能以只读的方式,而当父子进程任意一方修改了该共享内存,就会发生「写时复制」,于是父子进程就有了各自独立的数据副本,就不用加锁来保证数据安全,减少了锁的开销和避免死锁的发生。
问二

bgsave 和 save 的区别就在于:
bgsave 会使用 fork() 系统调用创建子进程,创建快照的工作在子进程里;
save 不会创建子进程,创建快照的工作在主线程里。
创建子进程时,有两个阶段会导致阻塞父进程:
创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
创建完子进程后,如果子进程或者父进程修改了共享数据,就会发生写时复制,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长;
那么当 Redis 内存数据高达几十 G,甚至上百 G 的时候,如果用 bgsave 进行 RDB 快照的话,在创建子进程的时候,会因为复制太大的页表而导致 Redis 阻塞在 fork() 函数,主线程无法继续执行,相当于停顿了。
所以针对这种情况建议用 sava。
虽然 save 会一直阻塞 Redis 直到快照生成完毕,但是它这个阻塞并不是意味着停顿了,而是在执行生成快照的程序,只是期间主线程无法处理接下来的读写命令。
并且因为不需要创建子进程,所以不会像 bgsave 一样因为创建子进程而导致 Redis 停顿,并且因为没有子进程在争抢资源,所以 sava 创建快照的速度比 bgsave 创建快照的速度要快一些。
问题三

这两个看一下源码就知道了呀。
先看回答第一个问题,我们直接看 Redis 加载 AOF 文件函数实现:
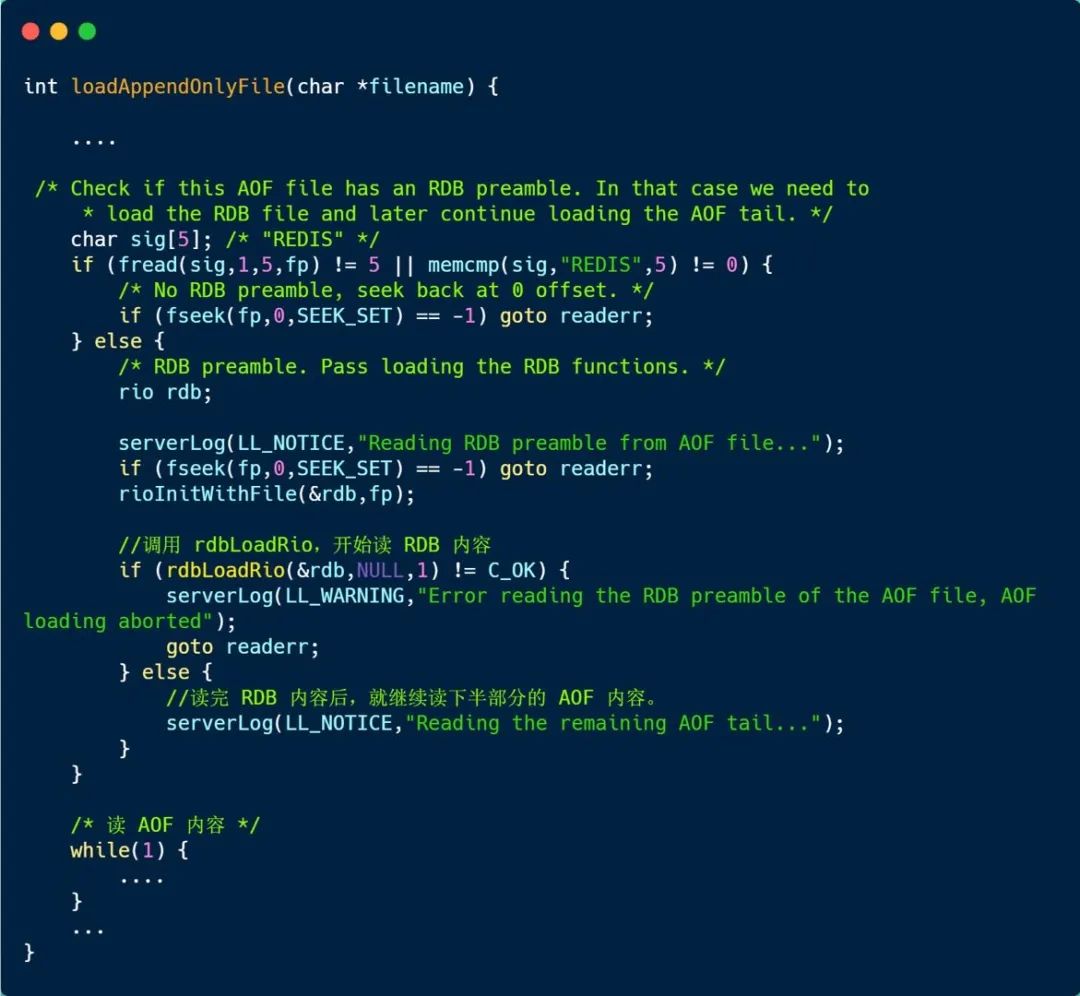
打开 AOF 文件之后,首先读取 5 个字符如果是「REDIS」,那么就说明这是一个混合持久化的 AOF 文件,因为 RDB 格式一定是以「REDIS」开头,而纯 AOF 格式则一定以「*」开头。
所以如果开头的 5 个字符是 「REDIS」 会先进入 rdbLoadRio() 函数来加载 RDB 内容。
rdbLoadRio() 函数就不详细展开了,就是按约定好的格式解析文件内容直到遇到 RDB_OPCODE_EOF 结束标记后返回。
接着 loadAppendOnlyFile() 函数继续以 AOF 格式解析文件直到结束整个加载过程完成。
再来看第二个问题,是通过什么方法将内存写入文件的?
很简单的,就是通过大家都知道的 write() 系统调用将内存数据写入到文件呀。
好了,这次就暂时回答这么多问题了。
你们觉得小林答的够详细吗?
觉得不错的,给小林个三连呀!
我们下次见啦~