
你能说说Spring框架中Bean的生命周期吗?
前言
俗话说:金三银四,到了这种季节,有一种叫做程序员的生物就开始活跃了起来。
这俩天,同事出去面试,她回来就问我:为啥这些面试官老爱问Spring,特别是Bean的生命周期,到底啥是Bean的生命周期呀,跟我说说呗。
那咱就来聊聊这个话题,本文主要分为两点进行阐述:
1、什么是Bean的生命周期?
2、Bean的生命周期是怎样的?
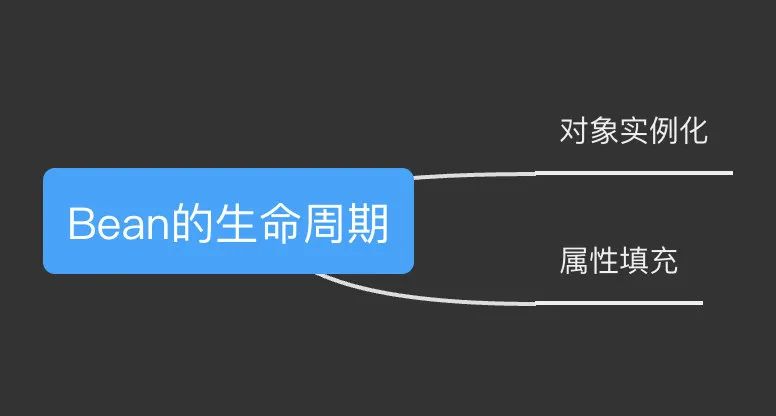
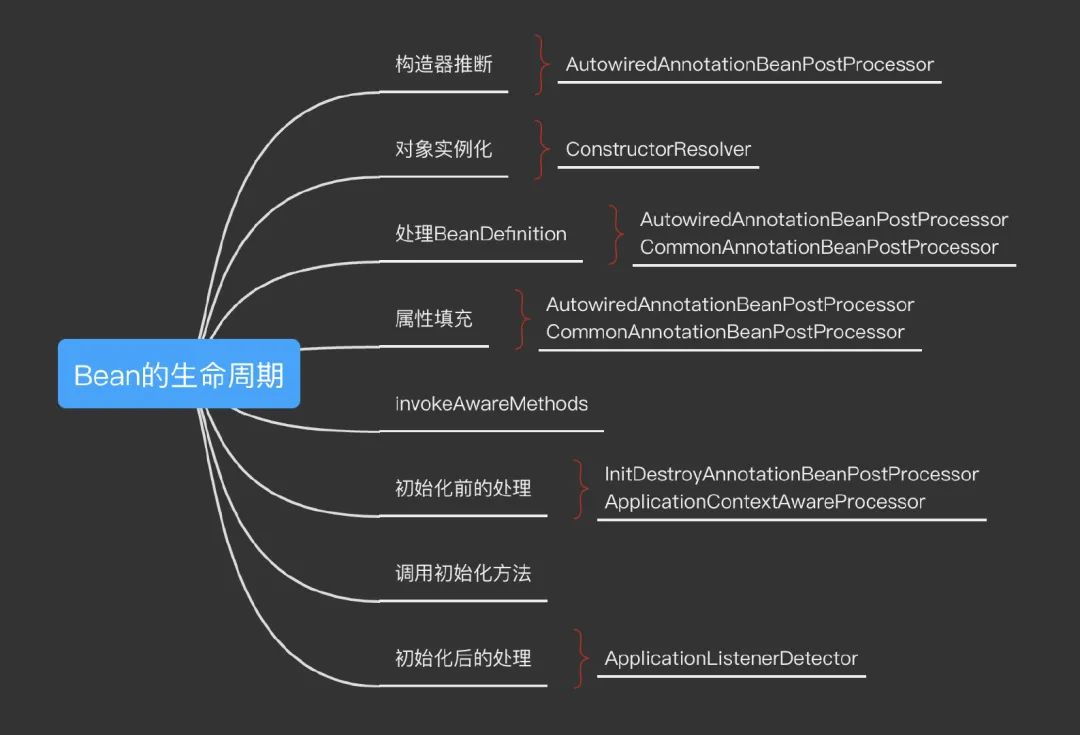
先给大家看一下完整的bean生命周期,不懂没关系后面会讲。

什么是Bean的生命周期
我们知道,在Java中,万物皆对象,这些对象有生命周期:实例化 -> gc回收
而Bean同样也是Java中的对象,只是在这同时,Spring又赋予了它更多的意义。
于是乎,我们将Bean从在Spring中创建开始,到Bean被销毁结束,这一过程称之为Bean的生命周期
那到底Bean在Spring中的创建过程是怎样的呢?
Bean的生命周期是怎样的
在Spring中,Bean的创建过程看起来复杂,但实际上逻辑分明。
如果我们将所有扩展性流程抛开,你会发现只剩下两个流程:对象的实例化和属性填充
我们在《深入浅出Spring架构设计》文中手写的Spring,也只是完成了这两个流程,这足以说明只需要这两个流程就能完成一个简单的Spring框架,那其他的流程又是什么呢?他们又有什么作用?
那么我们现在就基于这两个核心流程出发,尝试完善整个Spring的Bean生命周期。
推导过程
开始时,我们只有两个流程:对象的实例化和属性填充
我们知道,对象的实例化就是在Java里使用类构造器进行创建对象。而一个类中可能有很多的构造器,那么我们怎么才能知道使用哪个构造器进行实例化对象呢?
所以说,在实例化之前,还得先做一件事情:确定候选的构造器,也称之为构造器推断
构造器推断
功能描述:找寻beanClass中所有符合候选条件的构造器。
负责角色:AutowiredAnnotationBeanPostProcessor
候选条件:构造器上添加了@Autowired注解
推断流程:
1、获取beanClass中的所有构造器进行遍历,判断构造器上是否标识@Autowired注解,是则将构造器添加到候选构造器集合中
2、并进一步判断Autowired注解中required属性是否为true(默认为true),是则表示该beanClass已存在指定实例化的构造器,不可再有其他加了@Autowired注解的构造器,如果有则抛出异常。
3、如果Autowired注解中required属性为false,则可继续添加其他@Autowired(required=false)标识的构造器
4、如果候选构造器集合不为空(有Autowired标识的构造器),并且beanClass中还有个空构造器,那么同样将空构造器也加入候选构造器集合中。
5、如果候选构造器集合为空,但是beanClass中只有一个构造器且该构造器有参,那么将该构造器加入候选构造器集合中。
流程图:

当构造器遍历完毕之后,还有些许逻辑

以上判断条件很多,但始终是围绕这一个逻辑:这个beanClass中有没有被Autowired标识的构造器,有的话required是true还是false,如果是true, 那其他的构造器都不要了。如果是false,那想加多少个构造器就加多少个。
咦,那要是没有Autowired标识的构造器呢?
框架嘛,都是要兜底的,这里就是看beanClass中是不是只有一个构造器且是有参的。
那我要是只有个无参的构造器呢?
那确实就是没有候选的构造器了,但是Spring最后又兜底了一次,在没有候选构造器时默认使用无参构造器
那我要是有很多个构造器呢?
Spring表示那我也不知道用哪个呀,同样进入兜底策略:使用无参构造器(没有将抛出异常)
那么这就是构造器推断流程了,我们将它加入到流程图中

在得到候选的构造器之后,就可以对对象进行实例化了,那么实例化的过程是怎样的呢?
对象实例化
功能描述:根据候选构造器集合中的构造器优先级对beanClass进行实例化。
负责角色:ConstructorResolver
对象实例化的过程主要有两个方面需要关注:
1、构造器的优先级是怎样的?
2、如果有多个构造器,但是有部分构造器的需要的bean并不存在于Spring容器中会发生什么?也就是出现了异常怎么处理?
1. 构造器的优先级是怎样的?
在Java中,多个构造器称之为构造器重载,重载的方式有两种:参数的数量不同,参数的类型不同。
在Spring中,优先级则是由构造器的修饰符(public or private)和参数的数量决定。
规则如下:
1、public修饰的构造器 > private修饰的构造器
2、修饰符相同的情况下参数数量更多的优先
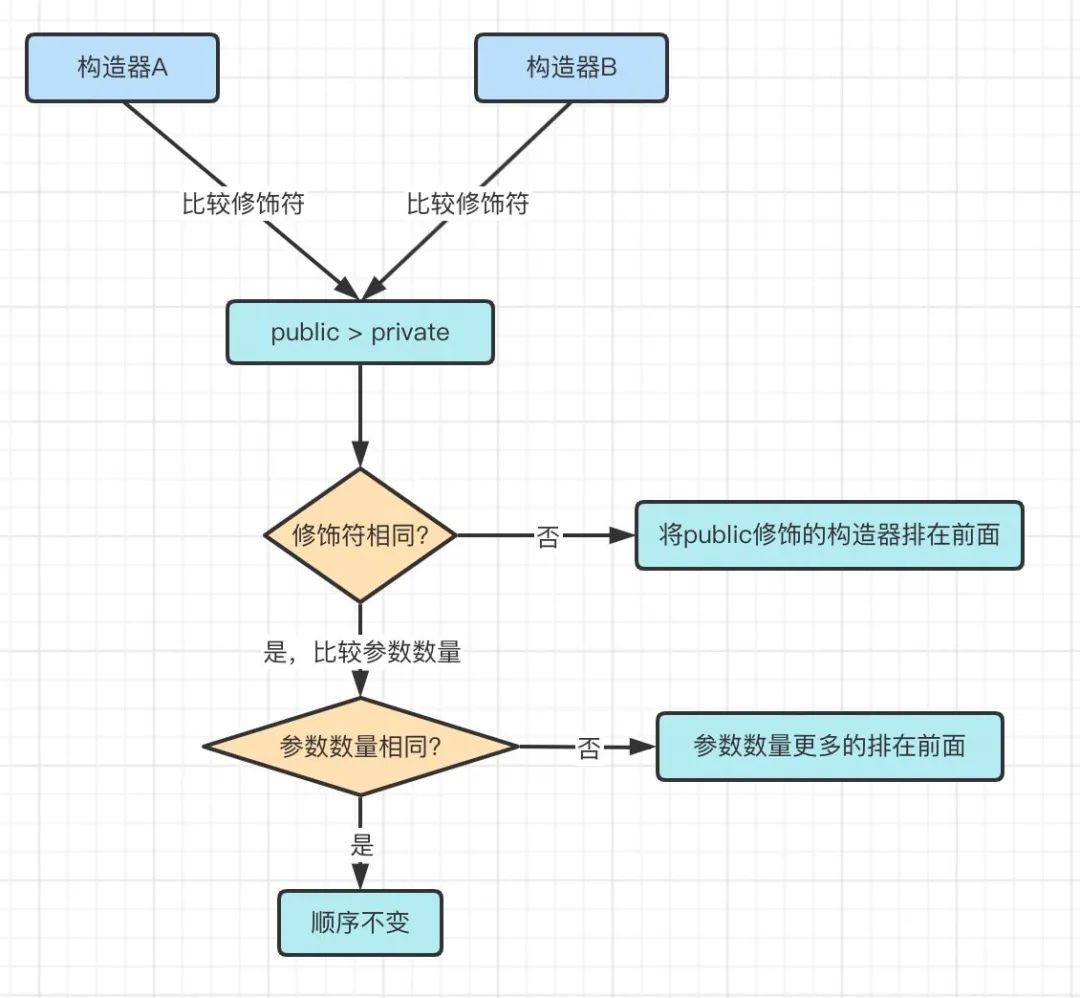
这段流程很简单,代码只有两行:
// 如果一个是public,一个不是,那么public优先
int result = Boolean.compare(Modifier.isPublic(e2.getModifiers()), Modifier.isPublic(e1.getModifiers()));
// 都是public,参数多的优先
return result != 0 ? result : Integer.compare(e2.getParameterCount(), e1.getParameterCount());
文中描述的规则是public > private, 只是为了更好的理解,实际上比较的是public和非public
2. Spring是如何处理实例化异常的?
当一个beanClass中出现多个构造器,但是有部分构造器的需要的bean并不存在于Spring容器中,此时会发生什么呢?
比如以下案例中,InstanceA具有三个构造方法,其中InstanceB并未注入到Spring中
@Component
public class InstanceA {
@Autowired(required = false)
public InstanceA(InstanceB instanceB){
System.out.println("instance B ...");
}
@Autowired(required = false)
public InstanceA(InstanceC instanceC){
System.out.println("instance C ...");
}
@Autowired(required = false)
public InstanceA(InstanceB instanceB, InstanceC instanceC, InstanceD InstanceD){
System.out.println("instance B C D...");
}
}
那么启动时是报错呢?还是选择只有InstanceC的构造器进行实例化?
运行结果会告诉你:Spring最终使用了只有InstanceC的构造器
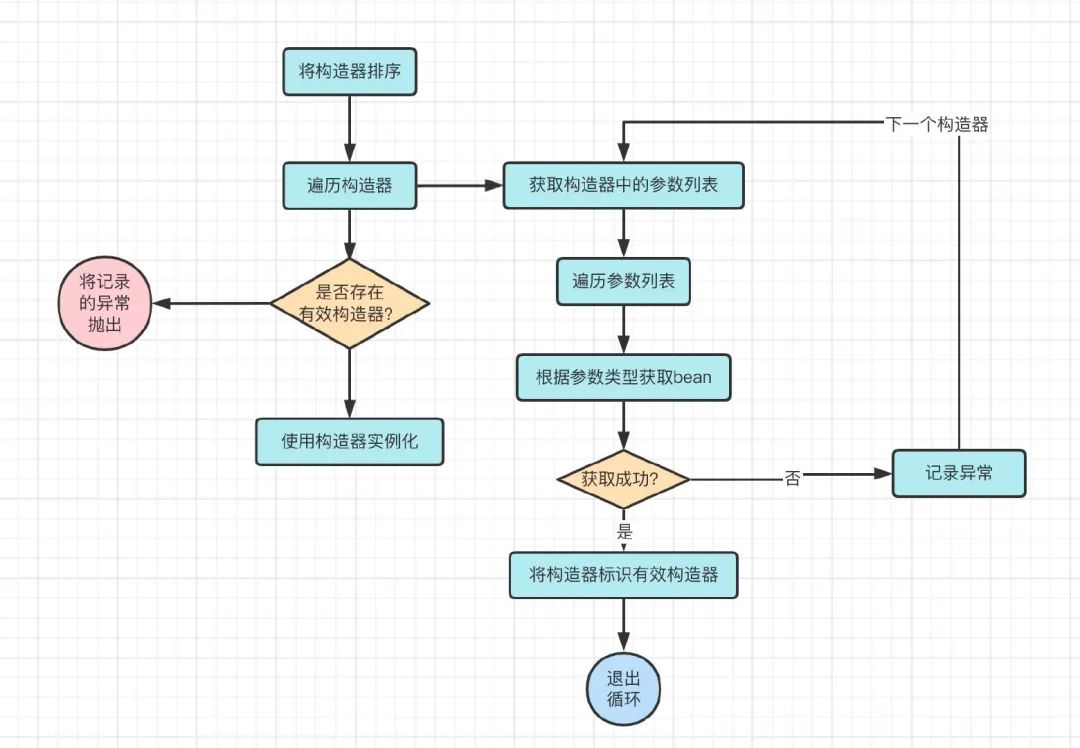
这一部分的具体过程如下:
1、将根据优先级规则排序好的构造器进行遍历
2、逐个进行尝试查找构造器中的需要的bean是否都在Spring容器中,如果成功找到将该构造器标记为有效构造器,并立即退出遍历
3、否则记录异常继续尝试使用下一个构造器
4、当所有构造器都遍历完毕仍未找到有效的构造器,抛出记录的异常
5、使用有效构造器进行实例化
推导过程
到这里,beanClass实例化了一个bean,接下来需要做的便是对bean进行赋值,但我们知道,Spring中可以进行赋值的对象不仅有通过@Autowired标识的属性,还可以是@Value,@Resource,@Inject等等。
为此,Spring为了达到可扩展性,将获取被注解标识的属性的过程与实际赋值的过程进行了分离。
该过程在Spring中被称为处理beanDefinition
处理beanDefinition
功能描述:处理BeanDefintion的元数据信息
负责角色:
1、AutowiredAnnotationBeanPostProcessor:处理@Autowird,@Value,@Inject注解
2、CommonAnnotationBeanPostProcessor:处理@PostConstruct,@PreDestroy,@Resource注解
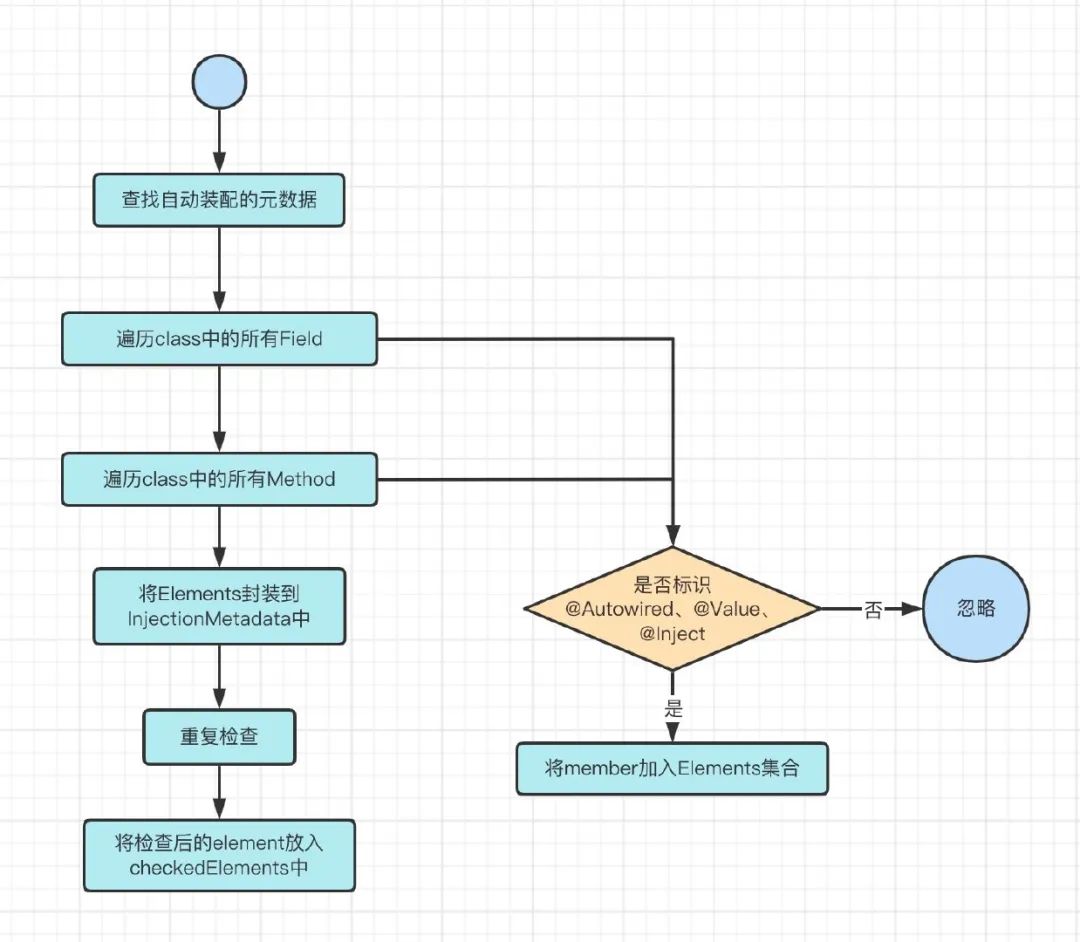
这两个后置处理器的处理过程十分类似, 我们以AutowiredAnnotationBeanPostProcessor为例:
1、遍历beanClass中的所有Field、Method(java中统称为Member)
2、判断Member是否标识@Autowird,@Value,@Inject注解
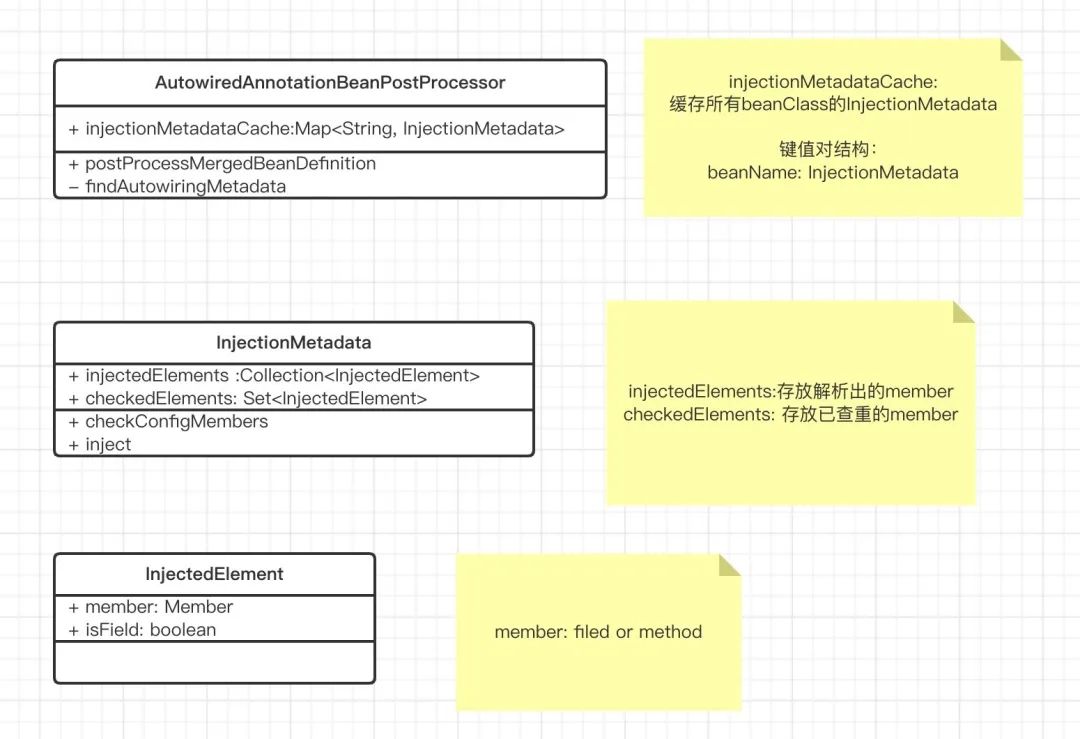
3、是则将该Member保存,封装到一个叫做InjectionMetadata的类中
4、判断Member是否已经被解析过,比如一个Member同时标识了@Autowired和@Resource注解,那么这个Member就会被这两个后置处理器都处理一遍,就会造成重复保存
5、如果没被解析过就将该Member放置到已检查的元素集合中,用于后续填充属性时从这里直接拿到所有要注入的Member
其中,AutowiredAnnotationBeanPostProcessor和InjectionMetadata的结构如下
同样,我们将这一部分流程也加入到流程图中
现在,beanClass中的可注入属性都找出来了,接下来就真的要进行属性填充了
属性填充
功能:对bean中需要自动装配的属性进行填充
角色:
1、AutowiredAnnotationBeanPostProcessor
2、CommonAnnotationBeanPostProcessor
在上一个流程中,我们已经找到了所有需要自动装配的Member,所以这一部流程就显得非常简单了
我们同样以AutowiredAnnotationBeanPostProcessor为例
1、使用beanName为key,从缓存中取出InjectionMetadata
2、遍历InjectionMetadata中的checkedElements集合
3、取出Element中的Member,根据Member的类型在Spring中获取Bean
4、使用反射将获取到的Bean设值到属性中

推导过程
在Spring中,Bean填充属性之后还可以做一些初始化的逻辑,比如Spring的线程池ThreadPoolTaskExecutor在填充属性之后的创建线程池逻辑,RedisTemplate的设置默认值。
Spring的初始化逻辑共分为4个部分:
1、invokeAwareMethods:调用实现特定Aware接口的方法
2、applyBeanPostProcessorsBeforeInitialization:初始化前的处理
3、invokeInitMethods:调用初始化方法
4、applyBeanPostProcessorsAfterInitialization:初始化后的处理
invokeAwareMethods
这块逻辑非常简单,我直接把源码粘出来给大家看看就明白了
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
初始化前的处理
功能:调用初始化方法前的一些操作
角色:
1、InitDestroyAnnotationBeanPostProcessor:处理@PostContrust注解
2、ApplicationContextAwareProcessor:处理一系列Aware接口的回调方法
这一步骤的功能没有太大的关联性,完全按照使用者自己的意愿决定想在初始化方法前做些什么,我们一个一个来过
1.InitDestroyAnnotationBeanPostProcessor
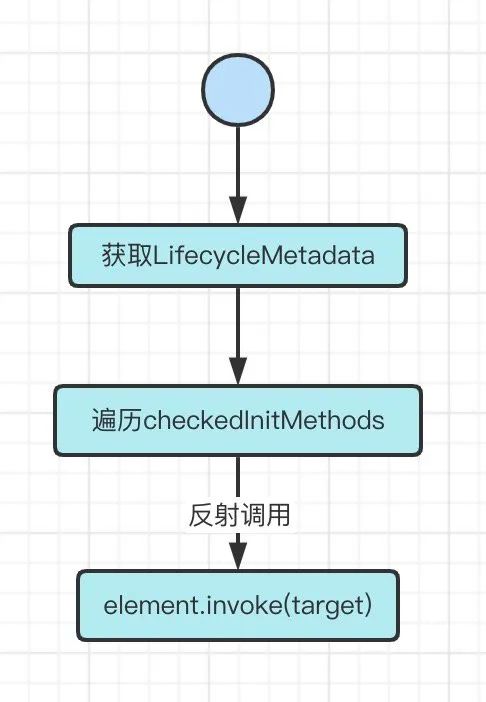
这里的逻辑与属性填充过程非常相似,属性填充过程是取出自动装配相关的InjectionMetadata进行处理,而这一步则是取@PostContrust相关的Metadata进行处理,这个Metadata同样也是在处理BeanDefinition过程解析缓存的
1、取出处理BeanDefinition过程解析的LifecycleMetadata
2、遍历LifecycleMetadata中的checkedInitMethods集合
3、使用反射进行调用
2.ApplicationContextAwareProcessor
这一步与invokeAwareMethods大同小异,只不过是其他的一些Aware接口,同样直接粘上代码
private void invokeAwareInterfaces(Object bean) {
if (bean instanceof EnvironmentAware) {
((EnvironmentAware) bean).setEnvironment(this.applicationContext.getEnvironment());
}
if (bean instanceof EmbeddedValueResolverAware) {
((EmbeddedValueResolverAware) bean).setEmbeddedValueResolver(this.embeddedValueResolver);
}
if (bean instanceof ResourceLoaderAware) {
((ResourceLoaderAware) bean).setResourceLoader(this.applicationContext);
}
if (bean instanceof ApplicationEventPublisherAware) {
((ApplicationEventPublisherAware) bean).setApplicationEventPublisher(this.applicationContext);
}
if (bean instanceof MessageSourceAware) {
((MessageSourceAware) bean).setMessageSource(this.applicationContext);
}
if (bean instanceof ApplicationContextAware) {
((ApplicationContextAware) bean).setApplicationContext(this.applicationContext);
}
}
初始化方法
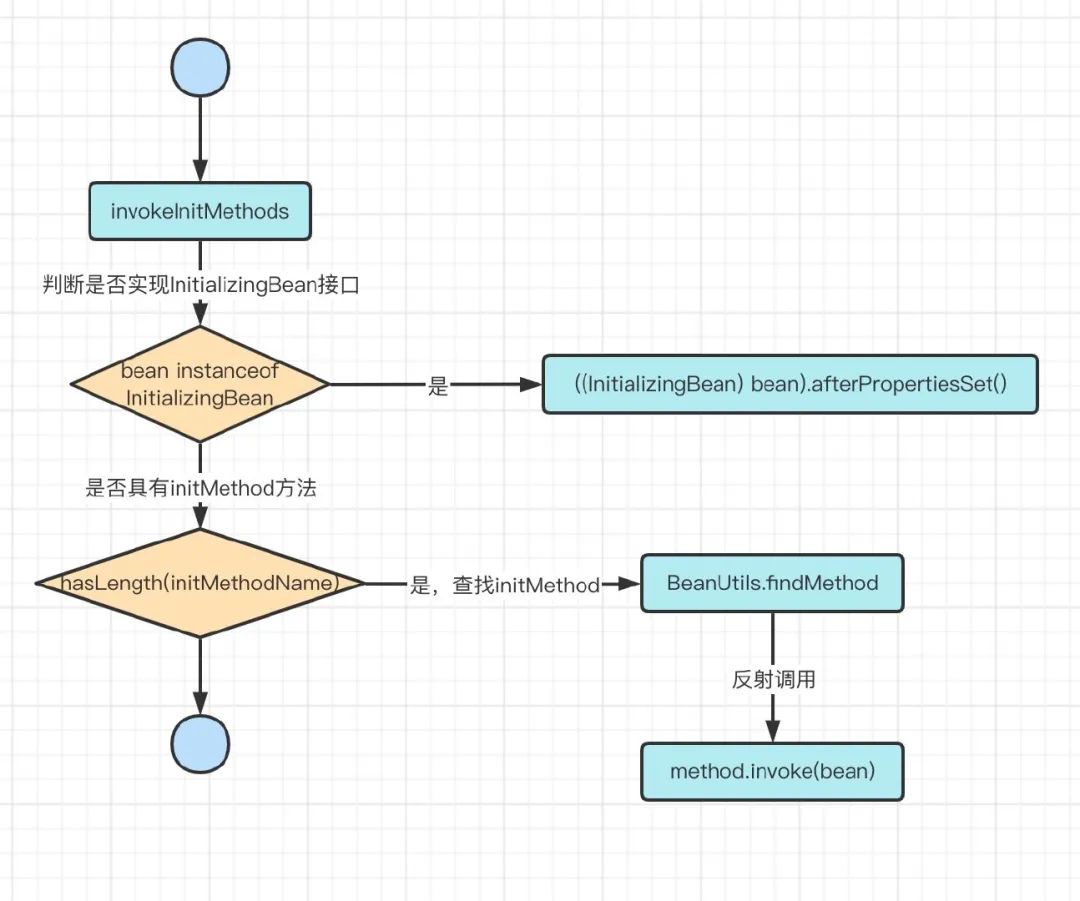
在Spring中的初始化方法有两种
1、实现InitializingBean接口的afterPropertiesSet方法
2、@Bean注解中的initMethod属性
调用顺序是先调用afterPropertiesSet再initMethod
1、判断Bean是否实现InitializingBean接口
2、是则将Bean强转成InitializingBean,调用afterPropertiesSet方法
3、判断BeanDefinition中是否有initMethod
4、是则找到对应的initMethod,通过反射进行调用
初始化后的处理
在Spring的内置的后置处理器中,该步骤只有ApplicationListenerDetector有相应处理逻辑:将实现了ApplicationListener接口的bean添加到事件监听器列表中
如果使用了Aop相关功能,则会使用到
AbstractAutoProxyCreator,进行创建代理对象。
ApplicationListenerDetector的流程如下
1、判断Bean是否是个ApplicationListener
2、是则将bean存放到applicationContext的监听器列表中
补充流程图
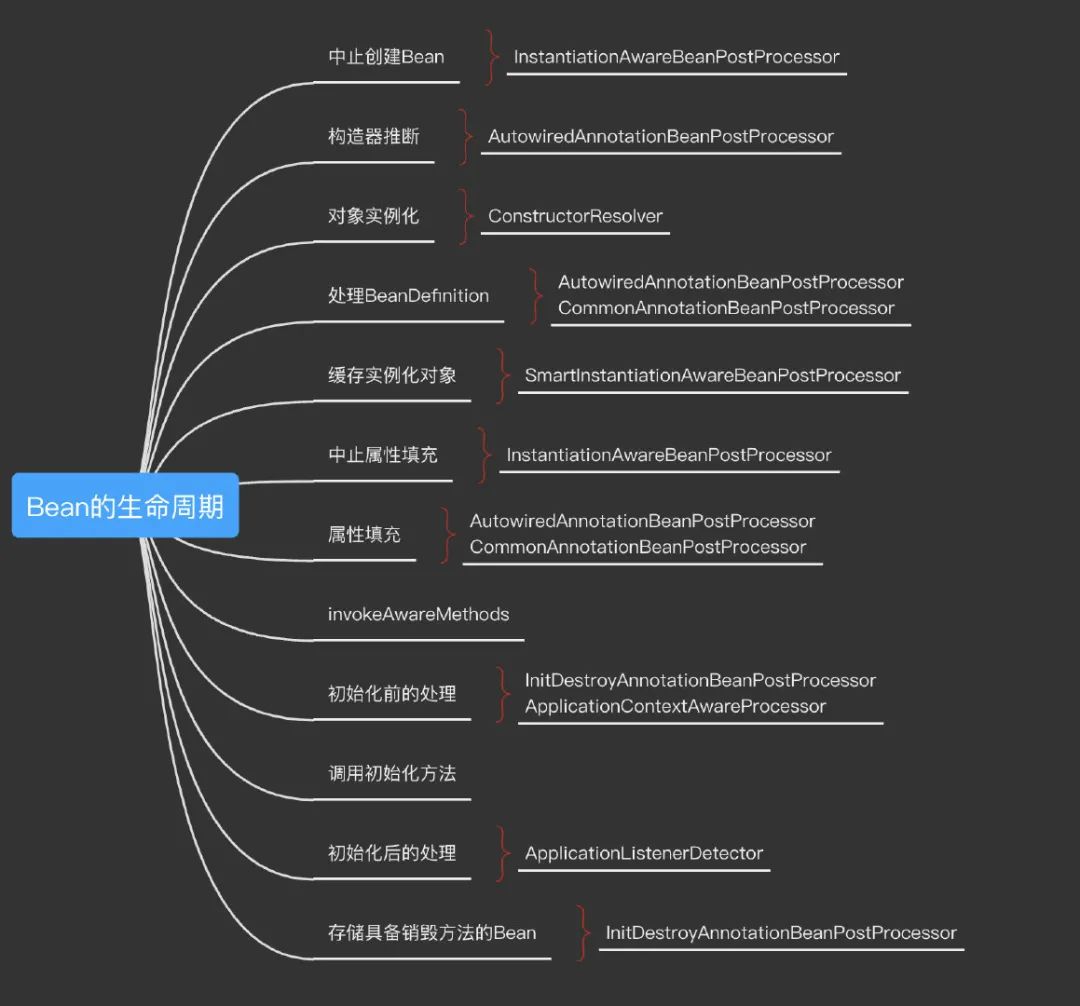
到这里,Bean的生命周期主要部分已经介绍完了,我们将流程图补充一下
同样还有其他的一些逻辑
1、中止创建Bean的过程
该过程处于Bean生命周期的最开始部分。
功能:由后置处理器返回Bean,达到中止创建Bean的效果
角色:无,Spring的内置后置处理器中,无实现。
Bean的生命周期十分复杂,Spring允许你直接拦截,即在创建Bean之前由自定义的后置处理器直接返回一个Bean给Spring,那么Spring就会使用你给的Bean,不会再走Bean生命周期流程。
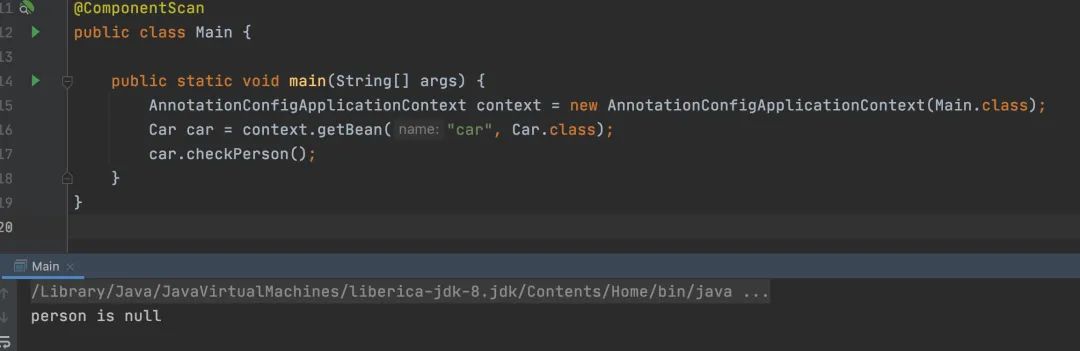
案例演示:
@Component
public class Car {
@Autowired
private Person person;
public void checkPerson(){
if(person == null){
System.out.println("person is null");
}
}
}
由于在Person属性上加了@Autowired,所以正常来说person必然不能为空,因为这是必须要注入的。
现在我们自定义一个BeanPostProcessor进行拦截
@Component
public class InterruptBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInstantiation(Class beanClass, String beanName) throws BeansException {
if("car".equals(beanName)){
try {
return beanClass.newInstance();
} catch (InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
}
return null;
}
}
测试结果如下
2、提前缓存刚实例化的对象
该步骤跟随在Spring实例化bean之后,将bean进行缓存,其目的是为了解决循环依赖问题。
该过程暂时按下不表,单独提出放于循环依赖章节。
3、中止填充属性操作
与中止创建Bean逻辑相同,Spring同样也允许你在属性填充前进行拦截。在Spring的内置处理器中同样无该实现。
实现手段为实现InstantiationAwareBeanPostProcessor接口,在postProcessAfterInstantiation方法中返回false
@Component
public class InterruptBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
if(beanName.equals("car")){
return false;
}
return true;
}
}
4、注册Bean的销毁方法
Spring中不仅有@PostContrust、afterProperties、initMethod这些bean创建时的初始化方法,同样也有bean销毁时的@PreDestory、destroy,destroyMethod。
所以在Bean的生命周期最后一步,Spring会将具备这些销毁方法的Bean注册到销毁集合中,用于系统关闭时进行回调。
比如线程池的关闭,连接池的关闭,注册中心的取消注册,都是通过它来实现的。
完整流程图
最后,附上开头的Bean生命周期的完整流程图,是不是就清晰了很多?
我是敖丙,你知道的越多,你不知道的越多,感谢各位人才的:点赞、收藏和评论,我们下期见!