抖音二面:为什么模块循环依赖不会死循环?CommonJS和ES Module的处理有什么不同?
大家好,我是年年。如果被问到“CommonJS和ES Module的差异”,大概每个前端都都背出几条:一个是导出值的拷贝,一个是导出值的引用;一个是运行时加载,一个是静态编译...
这篇文章会聚焦于遇到“循环引入”时,两者的处理方式有什么不同,这篇文章会讲清:
CommonJS和ES Module对于循环引用的解决原理是什么? CommonJS的module.exports和exports有什么不同? 引入模块时的路径解析规则是什么。
JavaScript的模块化
首先说说为什么会有两种模块化规范。众所周知,早期的JavaScript是没有模块的概念,引用第三方包时都是把变量直接绑定在全局环境下。
以axios为例,以script标签引入时,实际是在window对象上绑定了一个axios属性。

这种全局引入的方式会导致两个问题,变量污染和依赖混乱。
变量污染:所有脚本都在全局上下文中绑定变量,如果出现重名时,后面的变量就会覆盖前面的 依赖混乱:当多个脚本有相互依赖时,彼此之间的关系不明朗
所以需要使用“模块化”来对不同代码进行隔离。其实模块化规范远不止这两种,JavaScript官方迟迟没有给出解法,所以社区实现了很多不同的模块化规范,按照出现的时间前后有CommonJS、AMD、CMD、UMD。最后才是JavaScript官方在ES6提出的ES Module。
听着很多,但其实只用重点了解CommonJS和ES Module,一是面试基本只会问这两个,二是实际使用时用得多的也就是这两个。
CommonJS
CommonJS的发明者希望它能让服务端和客户端通用(Common)。但如果一直从事纯前端开发,应该对它不太熟悉,因为它原本是叫ServerJS,它主要被应用于Node服务端。
该规范把每一个文件看作一个模块,首先看它的基本使用:
// index.js 导入
const a = require("./a.js")
console.log('运行入口模块')
console.log(a)
// a.js 导出
exports.a = 'a模块'
console.log('运行a模块');
我们使用require函数作模块的引入,使用exports对象来做模块的导出,这里的require exports正是CommmonJS规范提供给我们的,使用断点调试,可以看到这几个核心变量:
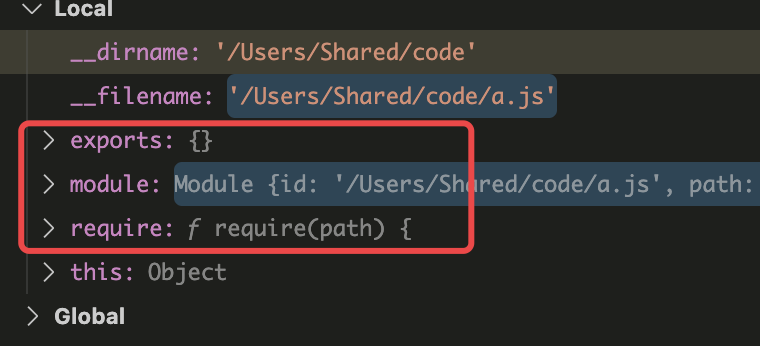
exports 记录当前模块导出的变量 module 记录当前模块的详细信息 require 进行模块的导入
exports 导出
首先来看exports导出,面试经常会问的一个题目是exports和module.exports区别是什么。两者指向同一块内存,但是使用并不是完全等价的。
当绑定一个属性时,两者相同
exports.propA = 'A';
module.exports.propB = 'B';
不能直接赋值给exports,也就是不能直接使用exports={}这种语法
// 失败
exports = {propA:'A'};
// 成功
module.exports = {propB:'B'};
虽然两者指向同一块内存,但最后被导出的是module.exports,所以不能直接赋值给exports。
同样的道理,只要最后直接给module.exports赋值了,之前绑定的属性都会被覆盖掉。
exports.propA = 'A';
module.exports.propB = 'B';
module.exports = {propC:'C'};
用上面的例子所示,先是绑定了两个属性propA和propB,接着给module.exports赋值,最后能成功导出的只有propC。
require 导入
CommonJS的引入特点是值的拷贝,简单来说就是把导出值复制一份,放到一块新的内存中。
循环引入
接下来进入正题,CommonJS如何处理循环引入。
首先来看一个例子:入口文件引用了a模块,a模块引用了b模块,b模块却又引用了a模块。可以思考一下会输出什么.
//index.js
var a = require('./a')
console.log('入口模块引用a模块:',a)
// a.js
exports.a = '原始值-a模块内变量'
var b = require('./b')
console.log('a模块引用b模块:',b)
exports.a = '修改值-a模块内变量'
// b.js
exports.b ='原始值-b模块内变量'
var a = require('./a')
console.log('b模块引用a模块',a)
exports.b = '修改值-b模块内变量'
输出结果如下:

这种AB模块间的互相引用,本应是个死循环,但是实际并没有,因为CommonJS做了特殊处理——模块缓存。
依旧使用断点调试,可以看到变量require上有一个属性cache,这就是模块缓存
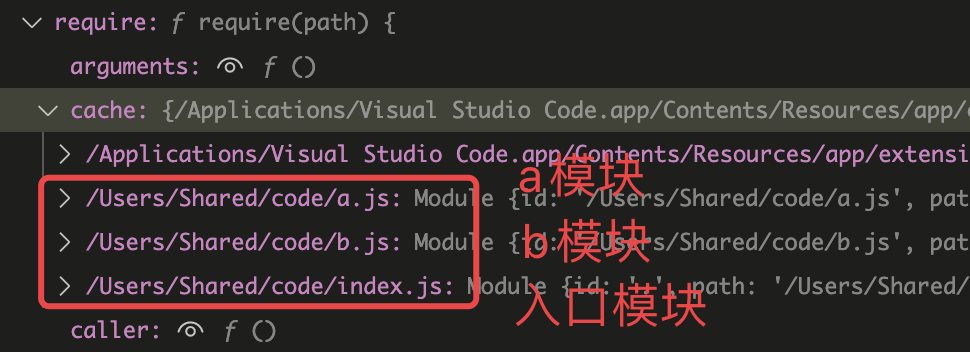
一行行来看执行过程,
【入口模块】开始执行,把入口模块加入缓存, var a = require('./a') 执行 将a模块加入缓存,进入a模块, 【a模块】exports.a = '原始值-a模块内变量'执行,a模块的缓存中给变量a初始化,为原始值, 执行var b = require('./b'),将b模块加入缓存,进入b模块 【b模块】exports.b ='原始值-b模块内变量',b模块的缓存中给变量b初始化,为原始值, var a = require('./a'),尝试导入a模块,发现已有a模块的缓存,所以不会进入执行,而是直接取a模块的缓存,此时打印 { a: '原始值-a模块内变量' },exports.b = '修改值-b模块内变量 执行,将b模块的缓存中变量b替换成修改值, 【a模块】console.log('a模块引用b模块:',b) 执行,取缓存中的值,打印 { b: '修改值-b模块内变量' }exports.a = '修改值-a模块内变量' 执行,将a模块缓存中的变量a替换成修改值, 【入口模块】console.log('入口模块引用a模块:',a) 执行,取缓存中的值,打印 { a: '修改值-a模块内变量' }
上面就是对循环引用的处理过程,循环引用无非是要解决两个问题,怎么避免死循环以及输出的值是什么。CommonJS通过模块缓存来解决:每一个模块都先加入缓存再执行,每次遇到require都先检查缓存,这样就不会出现死循环;借助缓存,输出的值也很简单就能找到了。
多次引入
同样由于缓存,一个模块不会被多次执行,来看下面这个例子:入口模块引用了a、b两个模块,a、b这两个模块又分别引用了c模块,此时并不存在循环引用,但是c模块被引用了两次。
//index.js
var a = require('./a')
var b= require('./b')
// a.js
module.exports.a = '原始值-a模块内变量'
console.log('a模块执行')
var c = require('./c')
// b.js
module.exports.b = '原始值-b模块内变量'
console.log('b模块执行')
var c = require('./c')
// c.js
module.exports.c = '原始值-c模块内变量'
console.log('c模块执行')
执行结果如下:

可以看到,c模块只被执行了一次,当第二次引用c模块时,发现已经有缓存,则直接读取,而不会再去执行一次。
路径解析规则
路径解析规则也是面试常考的一个点,或者说,为什么我们导入时直接简单写一个'react'就正确找到包的位置。
仔细观察module这个变量,可以看到还有一个属性paths
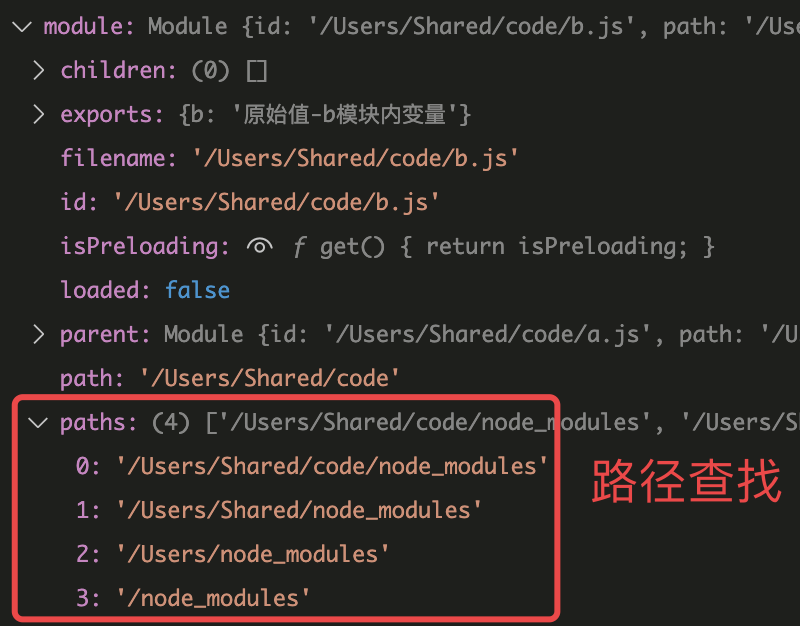
首先把路径作一个简单分类:内置的核心模块、本地的文件模块和第三方模块。
对于核心模块,node将其已经编译成二进制代码,直接书写标识符fs、http就可以 对于自己写的文件模块,需要用‘./’'../'开头,require会将这种相对路径转化为真实路径,找到模块 对于第三方模块,也就是使用npm下载的包,就会用到 paths这个变量,会依次查找当前路径下的node_modules文件夹,如果没有,则在父级目录查找no_modules,一直到根目录下,找到为止。
在node_modules下找到对应包后,会以package.json文件下的main字段为准,找到包的入口,如果没有main字段,则查找index.js/index.json/index.node
ES Module
尽管名为CommonJS,但并不Comomn(通用),它的影响范围还是仅仅在于服务端。前端开发更常用的是ES Module。
ES Module使用import命令来做导入,使用export来做导出,语法相对比较复杂,熟悉可以先跳过这一部分
普通导入、导出
// index.mjs
import {propA, propB,propC, propD} from './a.mjs'
// a.mjs
const propA = 'a';
let propB = () => {console.log('b')};
var propC = 'c';
export { propA, propB, propC };
export const propD = 'd'
使用export导出可以写成一个对象合集,也可以是一个单独的变量,需要和import导入的变量名字一一对应
默认导入、导出
// 导入函数
import anyName from './a.mjs'
export default function () {
console.log(123)
}
// 导入对象
import anyName from './a.mjs'
export default {
name:'niannian';
location:'guangdong'
}
// 导入常量
import anyName from './a.mjs'
export default 1
使用export default语法可以实现默认导出,可以是一个函数、一个对象,或者仅一个常量。默认的意思是,使用import导入时可以使用任意名称,
混合导入、导出
// index.mjs
import anyName, { propA, propB, propC, propD } from './a.mjs'
console.log(anyName,propA,propB,propC,propD)
// a.mjs
const propA = 'a';
let propB = () => {console.log('b')};
var propC = 'c';
// 普通导出
export { propA, propB, propC };
export const propD = 'd'
// 默认导出
export default function sayHello() {
console.log('hello')
}
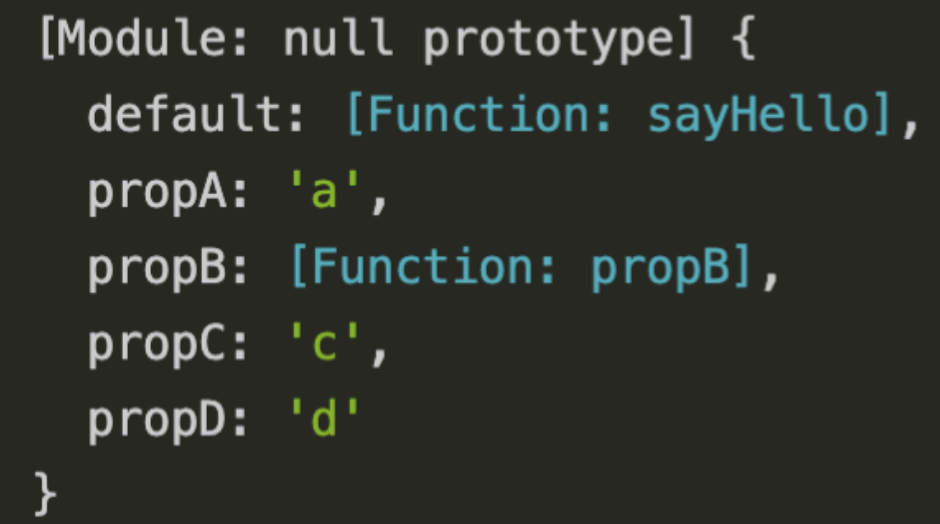
全部导入
// index.mjs
import * as resName from './a.mjs'
console.log(resName)
// a.mjs
const propA = 'a';
let propB = () => {console.log('b')};
var propC = 'c';
// 普通导出
export { propA, propB, propC };
export const propD = 'd'
// 默认导出
export default function sayHello() {
console.log('hello')
}
结果如下
重命名导入
// index.mjs
import { propA as renameA, propB as renameB, propC as renameC , propD as renameD } from './a.mjs'
const propA = 'a';
let propB = () => {console.log('b')};
var propC = 'c';
// a.mjs
export { propA, propB, propC };
export const propD = 'd'
重定向导出
export * from './a.mjs' // 第一种
export { propA, propB, propC } from './a.mjs' // 第二种
export { propA as renameA, propB as renameB, propC as renameC } from './a.mjs' //第三种
第一种方式:重定向导出所有导出属性, 但是不包括模块的默认导出。 第二种方式:以相同的属性名再次导出。 第三种方式:从模块中导入propA,重命名为renameA导出
只运行模块
import './a.mjs'
export 导出
ES Module导出的是一份值的引用,CommonJS则是一份值的拷贝。也就是说,CommonJS是把暴露的对象拷贝一份,放在新的一块内存中,每次直接在新的内存中取值,所以对变量修改没有办法同步;而ES Module则是指向同一块内存,模块实际导出的是这块内存的地址,每当用到时根据地址找到对应的内存空间,这样就实现了所谓的“动态绑定”。
可以看下面这个例子,使用ES Module导出一个变量1和一个给变量加1的方法
// b.mjs
export let count = 1;
export function add() {
count++;
}
export function get() {
return count;
}
// a.mjs
import { count, add, get } from './b.mjs';
console.log(count); // 1
add();
console.log(count); // 2
console.log(get()); // 2
可以看到,调用add后,导出的数字同步增加了。
但使用CommonJS实现这个逻辑:
// a.js
let count = 1;
module.exports = {
count,
add() {
count++;
},
get() {
return count;
}
};
// index.js
const { count, add, get } = require('./a.js');
console.log(count); // 1
add();
console.log(count); // 1
console.log(get()); // 2
可以看到,在调用add对变量count增加后,导出count没有改变,因为CommonJS基于缓存实现,入口模块中拿到的是放在新内存中的一份拷贝,调用add修改的是模块a中这块内存,新内存没有被修改到,所以还是原始值,只有将其改写成方法才能获取最新值。
import 导入
ES module会根据import关系构建一棵依赖树,遍历到树的叶子模块后,然后根据依赖关系,反向找到父模块,将export/import指向同一地址。
循环引入
和CommonJS一样,发生循环引用时并不会导致死循环,但两者的处理方式大有不同。如果阅读了上文,应该还记得CommonJS对循环引用的处理基于他的缓存,即:将导出值拷贝一份,放在一块新的内存,用到的时候直接读取这块内存。
但ES module导出的是一个索引——内存地址,没有办法这样处理。它依赖的是“模块地图”和“模块记录”,模块地图在下面会解释,而模块记录是好比每个模块的“身份证”,记录着一些关键信息——这个模块导出值的的内存地址,加载状态,在其他模块导入时,会做一个“连接”——根据模块记录,把导入的变量指向同一块内存,这样就是实现了动态绑定,
来看下面这个例子,和之前的demo逻辑一样:入口模块引用a模块,a模块引用b模块,b模块又引用a模块,这种ab模块相互引用就形成了循环
// index.mjs
import * as a from './a.mjs'
console.log('入口模块引用a模块:',a)
// a.mjs
let a = "原始值-a模块内变量"
export { a }
import * as b from "./b.mjs"
console.log("a模块引用b模块:", b)
a = "修改值-a模块内变量"
// b.mjs
let b = "原始值-b模块内变量"
export { b }
import * as a from "./a.mjs"
console.log("b模块引用a模块:", a)
b = "修改值-b模块内变量"
运行代码,结果如下。

值得一提的是,import语句有提升的效果,实际执行可以看作这样:
// index.mjs
import * as a from './a.mjs'
console.log('入口模块引用a模块:',a)
// a.mjs
import * as b from "./b.mjs"
let a = "原始值-a模块内变量"
export { a }
console.log("a模块引用b模块:", b)
a = "修改值-a模块内变量"
// b.mjs
import * as a from "./a.mjs"
let b = "原始值-b模块内变量"
export { b }
console.log("b模块引用a模块:", a)
b = "修改值-b模块内变量"
可以看到,在b模块中引用a模块时,得到的值是uninitialized,接下来一步步分析代码的执行。
在代码执行前,首先要进行预处理,这一步会根据import和export来构建模块地图(Module Map),它类似于一颗树,树中的每一个“节点”就是一个模块记录,这个记录上会标注导出变量的内存地址,将导入的变量和导出的变量连接,即把他们指向同一块内存地址。不过此时这些内存都是空的,也就是看到的uninitialized。
接下来就是代码的一行行执行,import和export语句都是只能放在代码的顶层,也就是说不能写在函数或者if代码块中。
【入口模块】首先进入入口模块,在模块地图中把入口模块的模块记录标记为“获取中”(Fetching),表示已经进入,但没执行完毕, import * as a from './a.mjs' 执行,进入a模块,此时模块地图中a的模块记录标记为“获取中” 【a模块】import * as b from './b.mjs' 执行,进入b模块,此时模块地图中b的模块记录标记为“获取中”, 【b模块】import * as a from './a.mjs' 执行,检查模块地图,模块a已经是Fetching态,不再进去, let b = '原始值-b模块内变量' 模块记录中,存储b的内存块初始化, console.log('b模块引用a模块:', a) 根据模块记录到指向的内存中取值,是{ a: } b = '修改值-b模块内变量' 模块记录中,存储b的内存块值修改 【a模块】let a = '原始值-a模块内变量' 模块记录中,存储a的内存块初始化, console.log('a模块引用b模块:', b) 根据模块记录到指向的内存中取值,是{ b: '修改值-b模块内变量' } a = '修改值-a模块内变量' 模块记录中,存储a的内存块值修改 【入口模块】console.log('入口模块引用a模块:',a) 根据模块记录,到指向的内存中取值,是{ a: '修改值-a模块内变量' }
总结一下:和上面一样,循环引用要解决的无非是两个问题,保证不进入死循环以及输出什么值。ES Module来处理循环使用一张模块间的依赖地图来解决死循环问题,标记进入过的模块为“获取中”,所以循环引用时不会再次进入;使用模块记录,标注要去哪块内存中取值,将导入导出做连接,解决了要输出什么值。
结语
回到开头的三个问题,答案在文中不难找到:
CommonJS和ES Module都对循环引入做了处理,不会进入死循环,但方式不同:
CommonJS借助模块缓存,遇到require函数会先检查是否有缓存,已经有的则不会进入执行,在模块缓存中还记录着导出的变量的拷贝值; ES Module借助模块地图,已经进入过的模块标注为获取中,遇到import语句会去检查这个地图,已经标注为获取中的则不会进入,地图中的每一个节点是一个模块记录,上面有导出变量的内存地址,导入时会做一个连接——即指向同一块内存。 CommonJS的export和module.export指向同一块内存,但由于最后导出的是module.export,所以不能直接给export赋值,会导致指向丢失。
查找模块时,核心模块和文件模块的查找都比较简单,对于react/vue这种第三方模块,会从当前目录下的node_module文件下开始,递归往上查找,找到该包后,根据package.json的main字段找到入口文件。

往期推荐


最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...