
Nacos源码中为什么使用了String.intern方法?
前言
面试的时候经常被问到String的intern方法的调用及内存结构发生的变化。但在实际生产中真正用到过了吗,看到过别人如何使用了吗?
最近阅读Nacos的源码,还真看到代码中使用String类的intern方法,NamingUtils类中有这样一个方法:
public static String getGroupedName(final String serviceName, final String groupName) {
// ...省略参数校验部分
final String resultGroupedName = groupName + Constants.SERVICE_INFO_SPLITER + serviceName;
return resultGroupedName.intern();
}
方法操作很简单,就是拼接一个GrouedName的字符串,但为什么在最后调用了一下intern方法呢?本篇文章我们就来分析一下。
intern方法的基本定义
先来看一下String中intern方法的定义:
public native String intern();
发现是native的方法,暂时我们无法更进一步看到它的具体实现。很多朋友至此便浅尝辄止了,其实我们还可以通过文档说明及一些工具来验证intern方法的作用及运作原理。
在intern方法上有一段注释来介绍它的功能,大意是:当调用intern方法时,如果字符串常量池中不存在对应的字符串(通过equals方法比较),则将该字符串添加到常量池中;如果存在则直接返回对应地址。
我们都知道字符串常量池的功能类似缓存,它可以让程序在运行的过程中速度更快、更节省内存。而上述代码之所以调用intern方法想必便是为了此目的。
字符串及常量池内存结构
要了解intern的作用,不得不先了解一下String字符串的内存结构。
字符串的创建通常有两种形式,通过new关键字创建和通过引号直接赋值的形式。这两种形式的字符串创建在内存分布上是有区别的。
直接使用双引号创建字符串时,会先去常量池查找该字符串是否已经存在,如果不存在的话先在常量池创建常量对象,然后返回引用地址;如果存在,则直接返回。
JDK6及以前的内存结构:
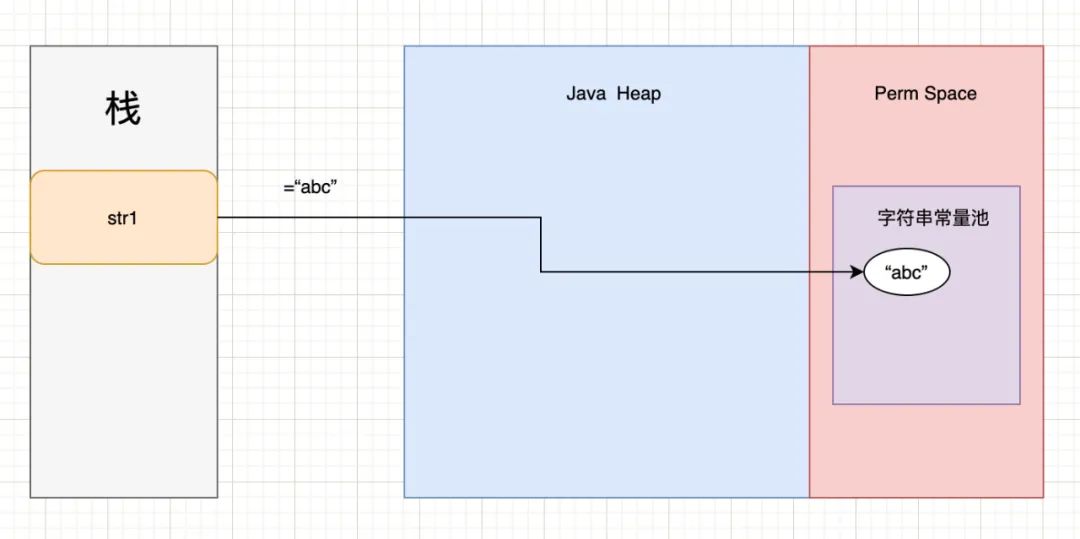
JDK7及以后的内存结构:
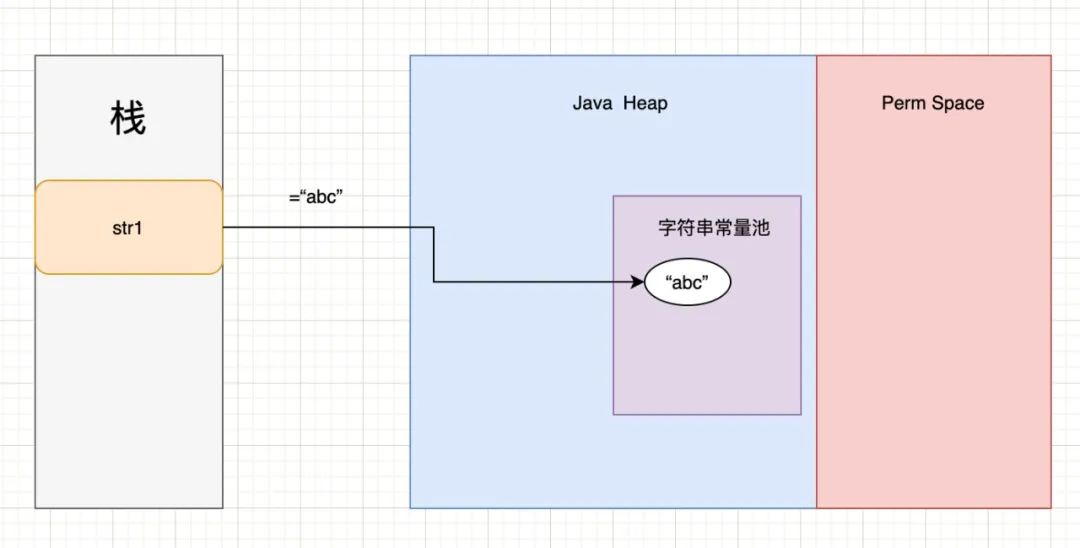
PS:JDK8及以后Perm Space改为元空间了,这就不画图展示了。
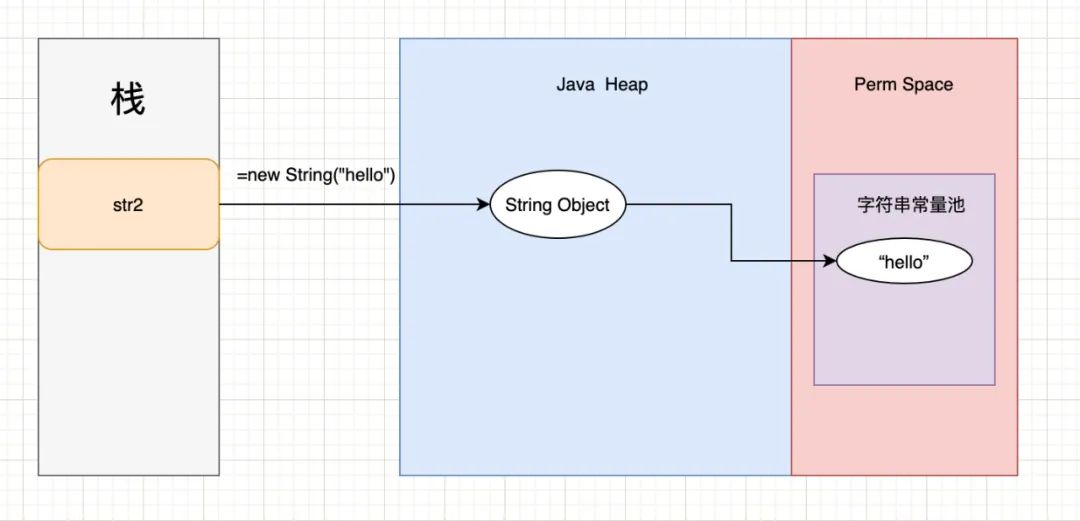
而使用new关键字创建字符串时,创建的对象是分配在堆中的,栈中的引用指向该对象。
String str2 = new String("hello");
而双引号中的字面值有两种情况,当常量池中不存在字面值“hello”时,会在常量池中生成这样一个常量;如果存在,则堆中的对象直接指向该字面值。
JDK6及以前的内存结构:
JDK7及以后的内存结构:
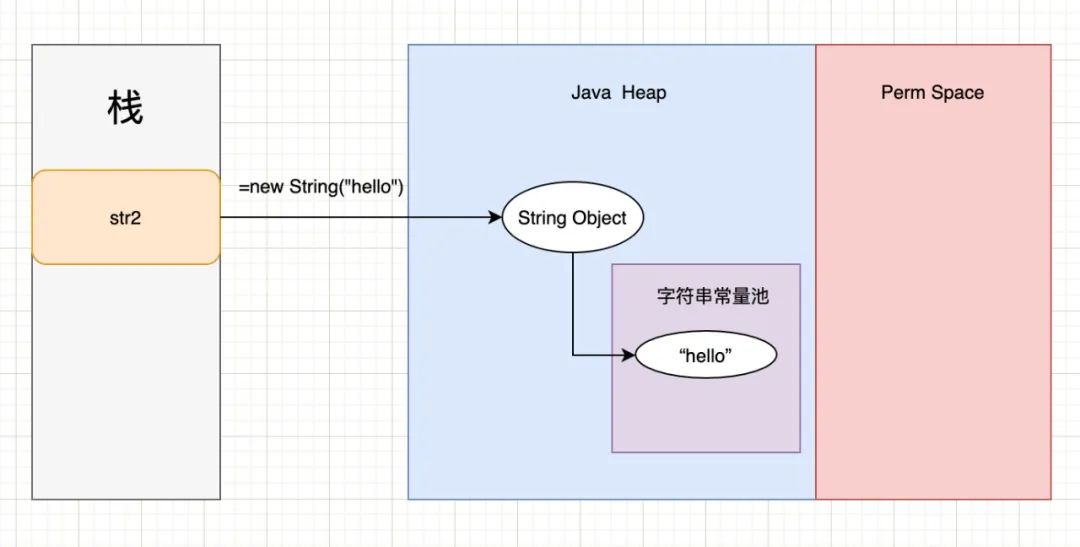
通常面试题中会问到通过new关键字创建String,内存中创建了几个对象,就是基于上面的原理来说的。很显然,如果常量池中已经存在“hello”了,那么只会在堆中创建一个对象,如果常量池中不存在,那就需要现在常量池中存储字符串对象了。因此,答案可能是1个,也可能是2个。
了解了这两个基础的内存逻辑与分布,基本延伸出来的情况(面试题)都可以应答了。
比如:
String str1 = "hello";
String str2 = "hello";
System.out.println(str1 == str2);//true
两个对象都是直接存放在常量池的,所以引用地址都一样。
再比如:
String s1 = new String("hello");
String s2 = "hello";
String s3 = new String("hello");
System.out.println(s1 == s2);// false
System.out.println(s1.equals(s2));// true
System.out.println(s1 == s3);//false
其中第一个输出为false是因为s1指向的是堆中的对象地址,s2指向的是常量池的地址;第二个比较的是常量池中存储的字符串,它们共用一个,所以为true;第三个s1和s3虽然共用常量池中的“hello”字面值,但是它们分别在堆中有自己的对象,所以为false。
字符串的拼接
字符串的拼接分两种情况,先看直接加号拼接:
String s1 = "hello" + "word";
String s2 = "helloword";
System.out,println(s1 == s2);//true
这种情况,针对s1,Java编译器是会进行编译期的优化的,编译器会进行字符串的拼接,然后存入常量池的为“helloword”。所以s1和s2都指向常量池中同样的地址。
另外一种情况就是非纯字符串常量的拼接:
String s1 = new String("he") + new String("llo");
针对这种情况,Java编译器同样会进行优化,优化为基于StringBuilder的字符串拼接。
基本流程,先创建一个StringBuilder,然后调用append的方法进行拼接,最后再调用toString方法生成字符串对象。最后通过toString方法生成的这个字符串“hello”,在常量池中是并不存在的。
最终的内存结构为:
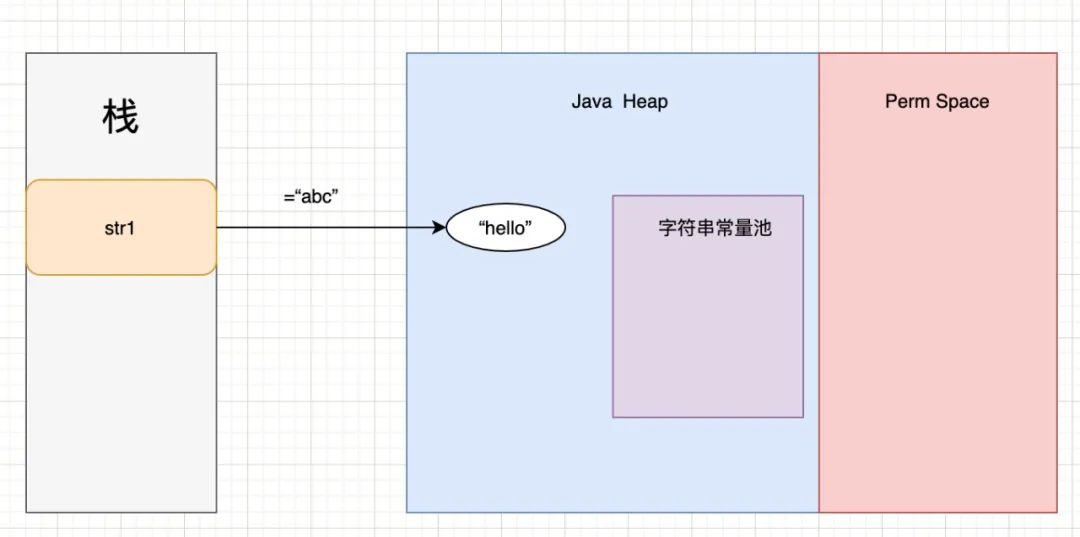
而最开始讲到的Nacos中的源码,之所以拼接之后调用intern方法的目的就是将上面这种形式拼接的堆中的字符串存储到常量池中。然后直接访问常量池中的对象,从而提升性能。
那么,当String类调用intern之后发生了什么呢?我们下面来看一下。
String的intern()方法
String.intern()方法的功能前面我们已经说过了,下面我们来看一下不同的JDK版本中使用intern方法的效果有何不同。
JDK1.6的实现
在JDK1.6及以前版本中,常量池在永久代分配内存,永久代和Java堆的内存是物理隔离的,执行intern方法时,如果常量池不存在该字符串,虚拟机会在常量池中复制该字符串,并返回引用。
如果已经存在该字符串了,则直接返回这个常量池中的这个常量对象的引用。所以需要谨慎使用intern方法,避免常量池中字符串过多,导致性能变慢,甚至发生PermGen内存溢出。
String str1 = new String("abc");
String str1Pool = str1.intern();
System.out.println(str1Pool == str1);
上述代码,在JDK1.6中打印结果为false。先看一下内存结构图:
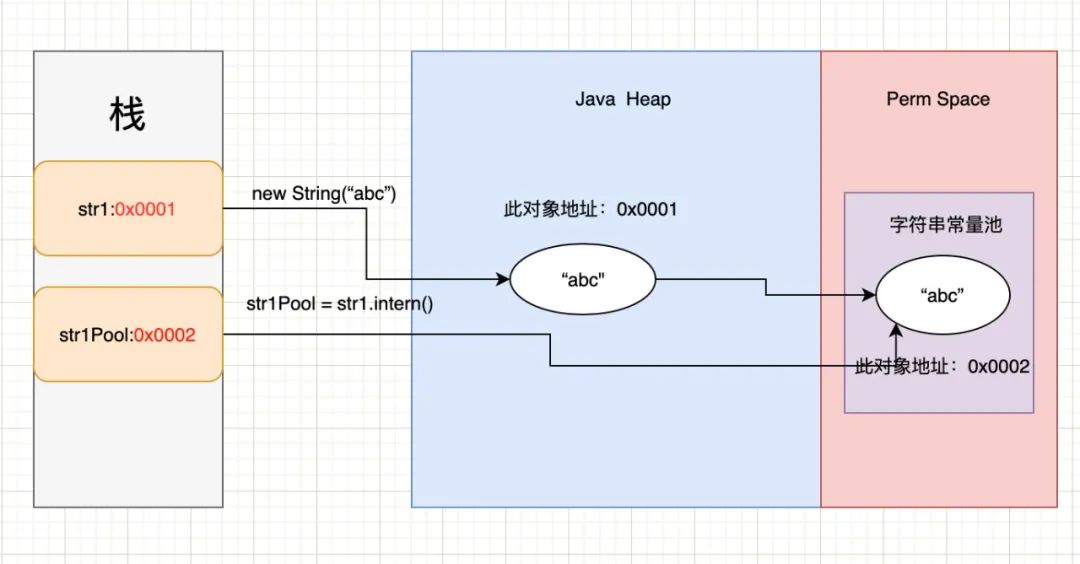
在上述代码中,当new String时与前面分析的内存结果一样,会在常量池和堆中创建两个对象。当str1调用intern方法时,发现常量池中已经存在对应的对象了,则该方法返回常量池中对象的地址。此时,str1指向堆中对象地址,str1Pool指向常量池中地址,因此不相等。
还有一种情况是常量池中本来不存在字符串常量:
String str1 = new String("a") + new String("bc");
String str1Pool = str1.intern();
System.out.println(str1Pool == str1);
对应内存结构图如下:
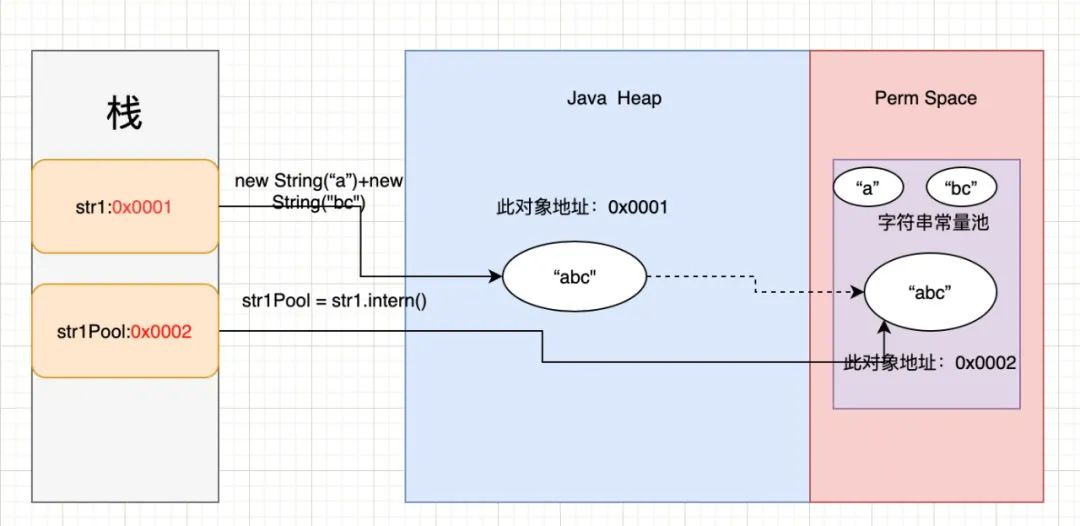
上述代码中,字符串str1生成的对象在常量池中并不存在,完全存在于堆中。当然,字符串“a”和“bc”会在创建对象时存入常量池。而当调用intern方法之后,会检查常量池中是否有“abc”,发现没有,于是将“abc”复制到常量池中,intern返回的结果为常量池的地址。此时,很显然,str1Pool和str1一个指向常量池,一个指向堆地址,因此不相等。
但在JDK1.7及以后,事情就发生了变化。
JDK1.7的实现
JDK1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,与之前没有区别。但如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
简单的说,就是往常量池放的内容变了。原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将堆上的地址引用复制到常量池,也就是常量池存放的是堆中字符串的引用地址。
1.7及以后,常量池已经从方法区中移出来到了堆中。
已经存在的场景我们就不演示了,与JDK1.6一致。下面来看一下常量池不存在对应字符串的情况。
String str1 = new String("a") + new String("bc");
String str1Pool = str1.intern();
System.out.println(str1Pool == str1);
对应的内存结构变化如下:
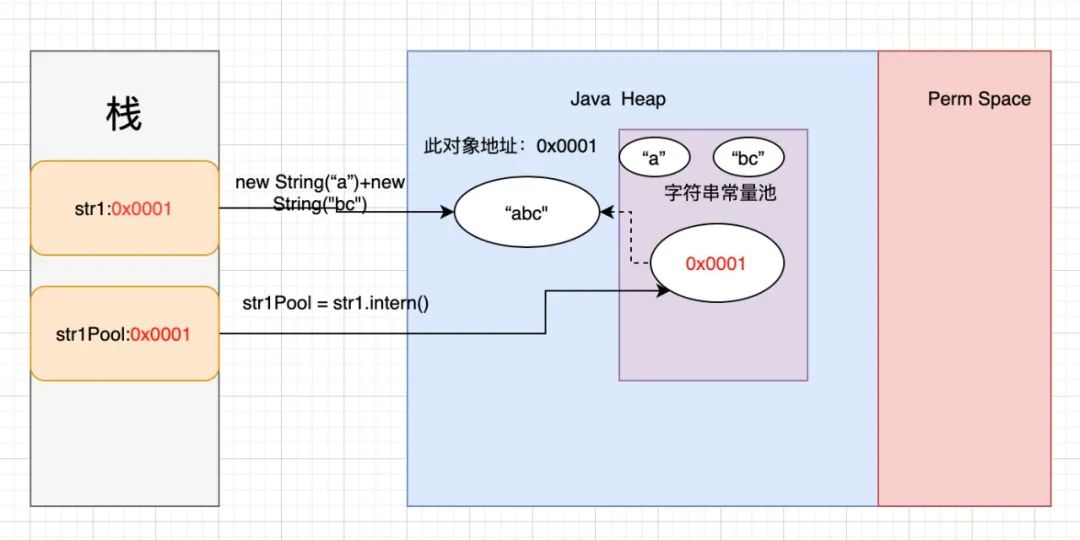
最开始创建“abc”对象时与JDK1.6一样,在堆中创建一个对象,常量池中并不存在“abc”。
当调用intern方法时,常量池不是复制“abc”字面值进行存储,而是直接将堆中“abc”的地址存储在常量池中,并且intern方法返回了堆中对象的地址。
此时会发现str1和str1Pool存储的引用地址都是堆中“abc”的地址。因此上述方法执行的结果为true。
线程池的实现结构
Java使用jni调用c++实现的StringTable的intern方法,StringTable的intern方法跟Java中的HashMap的实现是差不多的,但不能自动扩容,默认大小是1009。
也就是说String的字符串常量池是一个固定大小的Hashtable。如果常量池的String非常多,就会造成Hash冲突严重,导致链表很长,直接后果是会造成当调用String.intern时性能大幅下降。
在JDK1.6中StringTable的长度是固定不变的1009。在JDK1.7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
所以,在使用intern方法时需要慎重。那么,什么场景下适合使用intern方法呢?
就是对应的字符串被大量重复使用的情况下。比如最开始我们讲的Nacos代码,它是服务的名称基本上不会变化,而且会被重复的使用,放在常量池里面就比较合适了。
同时,我们要知道,虽然intern方法可以减少内存占用率,但由于多了一步操作,会导致程序耗时增加。但这与JVM的垃圾回收耗时相比,增加的时间可以忽略不计。
小结
本篇文章的写作的思路纯粹来源于阅读开源框架源码中的一行代码,但如果仔细想一下为什么会如此使用,发掘背后的原理和相关的知识点,也是很有意思的。
往期推荐
如果你觉得这篇文章不错,那么,下篇通常会更好。添加微信好友,可备注“加群”(微信号:zhuan2quan)。
和花一辈子都看不清的人,
注定是截然不同的搬砖生涯。
