全新HuggingFace数据集库发布!带来467种语言的611个文本数据集

新智元报道
新智元报道
来源:Huggingface
编辑:Q
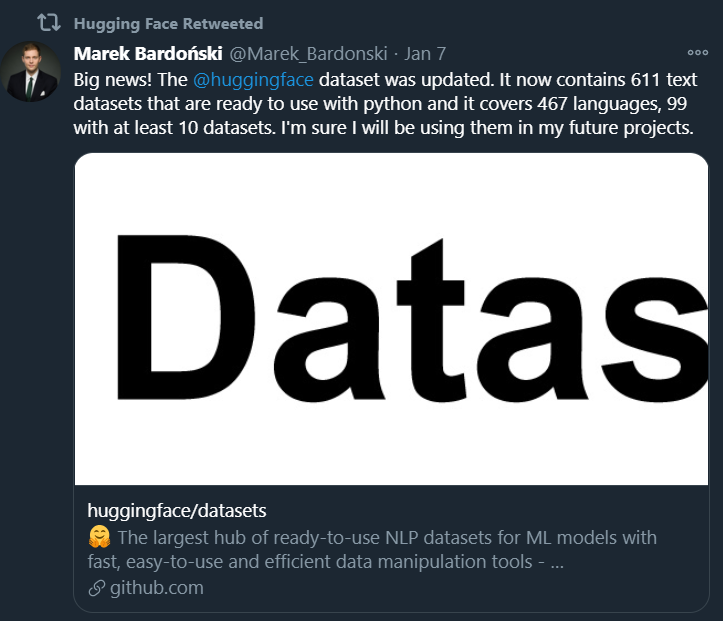
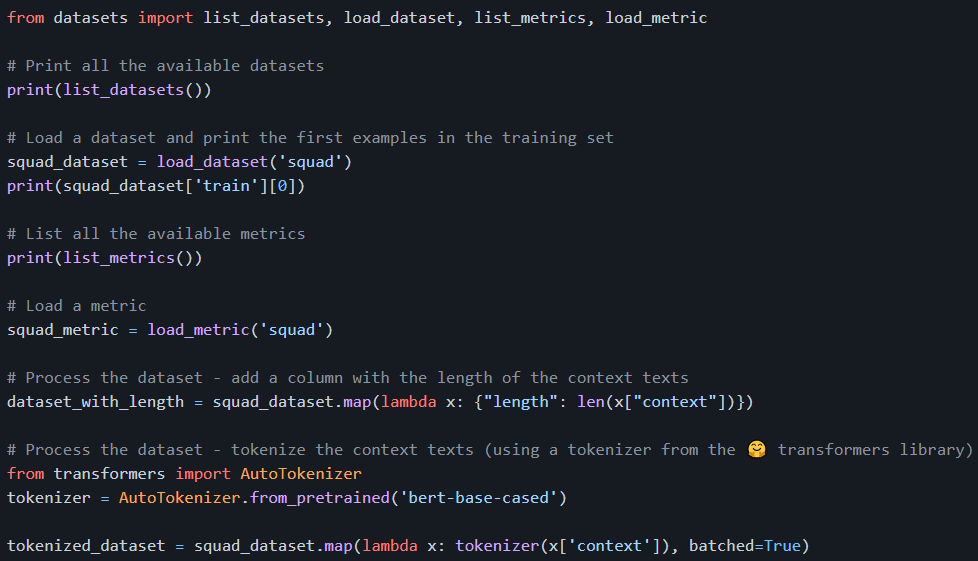
【新智元导读】NLP初创公司 HuggingFace 近日发布新版其Datasets库 v1.2,包括611 个文本数据集,可以下载以准备在一行 python 中使用;涵盖 467 种语言,其中 99 种包含至少 10 个数据集;当使用非常大的数据集时(默认情况下是内存映射),高效的预处理可以使用户摆脱内存限制。

推荐阅读:


评论
 下载APP
下载APP
新智元报道
来源:Huggingface
编辑:Q
推荐阅读: