
BBAug: 一个用于PyTorch的物体检测包围框数据增强包

极市导读
谷歌的大脑团队提出了一项工作:Learning Data Augmentation Strategies for Object Detection。作者确定了一组增强称为策略,它对目标检测问题表现良好,该策略通过增强搜索获得,提高了通用模型的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

像许多神经网络模型一样,目标检测模型在训练大量数据时效果最好。通常情况下,可用的数据有限,世界各地的许多研究人员正在研究增强策略,以增加可用的数据量。谷歌的大脑团队进行了一项这样的研究,并发表在了一篇论文中,名为Learning Data Augmentation Strategies for Object Detection。在这篇论文中,作者确定了一组增强称为策略,它对目标检测问题表现良好。该策略通过增强搜索获得,提高了通用模型的性能。
作者将增强策略定义为一组子策略。在模型进行训练时,随机选择其中一个子策略用于增强图像。在每个子策略中都有要依次应用于图像的增强。每个转换也有两个超参数:概率和幅度。概率表示该增强将被应用的可能性,而幅度表示该增强的程度。下面的代码显示了本文中使用的策略:
在这个策略中有5个子策略,如果我们取第一个子策略,它就包含了TranslateX_BBox和Equalize增强。TranslateX_BBox操作在x轴上转换图像的幅度为4。在本例中,大小并不直接转换为像素,而是根据大小缩放为像素值。该增强的概率也为0.6,这意味着如果该增强被选中,则应用该增强的概率为60%。随着每个增强都有一个相关的概率,引入了一个随机的概念,给训练增加了一定程度的随机性。总的来说,Brain Team已经提出了4个策略: v0, v1, v2和v3。本文中显示了v0策略,其他三个策略包含更多的子策略,这些子策略具有几种不同的转换。总的来说,增加分为三类,作者定义为:
颜色操作: 扭曲颜色通道,不影响边界框的位置。
几何操作:几何扭曲图像,这相应地改变了边界框的位置和大小。
包围框操作:只会扭曲包围框中包含的像素内容。
BBAug
那么BBAug)在这方面有什么贡献呢?BBAug是一个python包,它实现了谷歌Brain Team的所有策略。这个包是一个包装器,可以更容易地使用这些策略。实际的扩展是由优秀的imgaug包完成的。
上面显示的策略应用于一个示例图像,如下所示。每一行是一个不同的子策略,每一列是该子策略的不同运行。





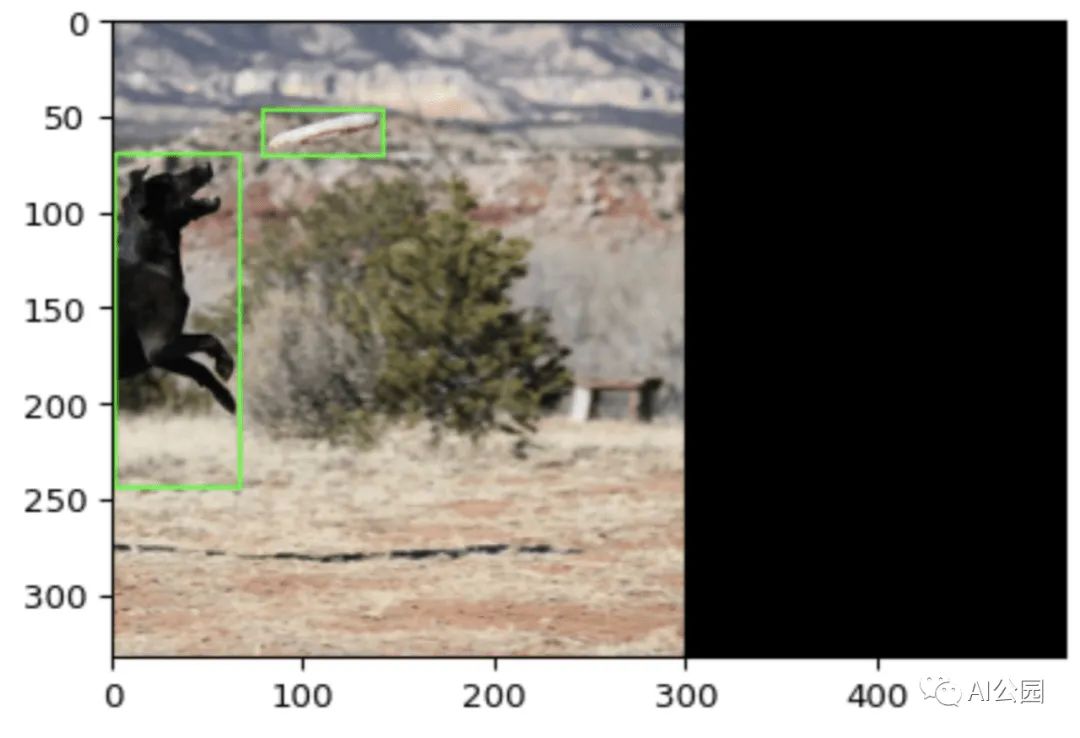
正如你所看到的,在子策略的运行之间有一定程度的变化,因此给训练增加了一定程度的随机性。这只是BBAug实施的4个策略之一。要查看所有4个策略的完整可视化,请查看包的GitHub页面:https://github.com/harpalsahota/bbaug。该包还提供了一些有用的功能,比如定制策略的可能性,以及位于图像外部的边界框,如果它们部分位于图像外部,则会被自动删除或剪切。例如,在下面的图像中,应用了平移增强,将边界框部分推到图像外部。你可以看到新的边界框已经缩小以适应这一点。
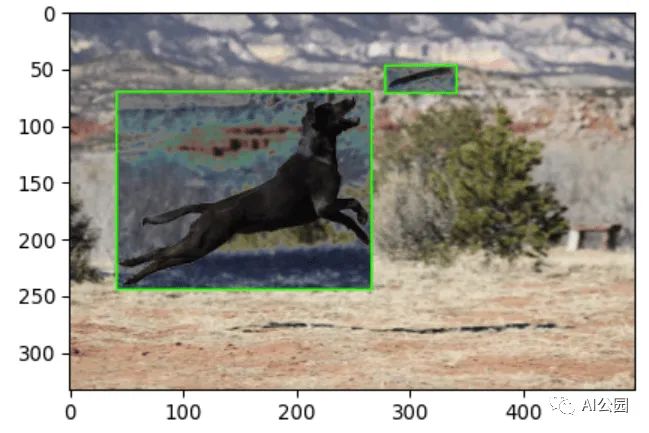
也可以创建只影响边界框区域的增强。在下图中,solarisaugmentation只应用于边界框区域:
用随机策略增加单个图像有多容易?就像这样简单:
总结
该包实现了谷歌Brain Team推导出的增强策略。目前,已经实现了所有4个策略,该包还附带了notebooks,以帮助用户将这些策略集成到他们的PyTorch训练pipeline中。
—END—
英文原文:https://towardsdatascience.com/bbaug-a-package-for-bounding-box-augmentation-in-pytorch-e9b9fbf1504b
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
